개요
자료구조와 알고리즘에 대해서 예전부터 공부해왔지만 당시에 제대로 이해하지 못한 것들도 많고, 단순히 시험을 위해서 암기한 내용들이 많아서 이번에 제대로 정리해보고자 합니다.
첫 자료구조 정리로는 배열과 연결 리스트에 대해서 정리 해보려고 합니다.
배열 (Array)
배열의 특성

- 같은 자료형의 데이터들이 연속된 메모리 공간에 저장된 자료구조
- 특정 원소 조회 시 → 인덱스를 통해 시간 복잡도 O(1)으로 접근 가능
- 특정 인덱스에 삽입 시 → 그 뒤의 요소를 한칸 씩 뒤로 이동시켜야 하기 때문에 시간 복잡도 O(N) 소요
- 특정 인덱스에 삭제 시 → 그 뒤의 요소를 한칸 씩 앞으로 이동시켜야 하기 때문에 시간 복잡도 O(N) 소요
파이썬의 리스트와 비교
- 연속된 메모리 공간에 저장하지만 C언어의 배열과 다르게 직접 데이터를 저장하지 않고, 객체에 대한 참조를 저장하기 때문에 한 리스트에 다양한 자료형을 저장할 수 있음
- 동적으로 배열을 확장하며 현재 크기의 1.125배 비율로 배열의 크기를 확장 [출처: 위키피디아]
연결 리스트 (Linked List)

연결 리스트는 기관차를 상상하면 이해하기 쉽다.
기관차는 맨 앞에 조종실이 있고, 그 뒤로 객실 / 화물칸 등이 연결기를 통해서 연결되어 있다.
연결 리스트도 이와 유사하게 조종실 → 헤드 노드, 객실 / 화물칸 → 노드, 연결기 → 포인터로 구성되어 있다.
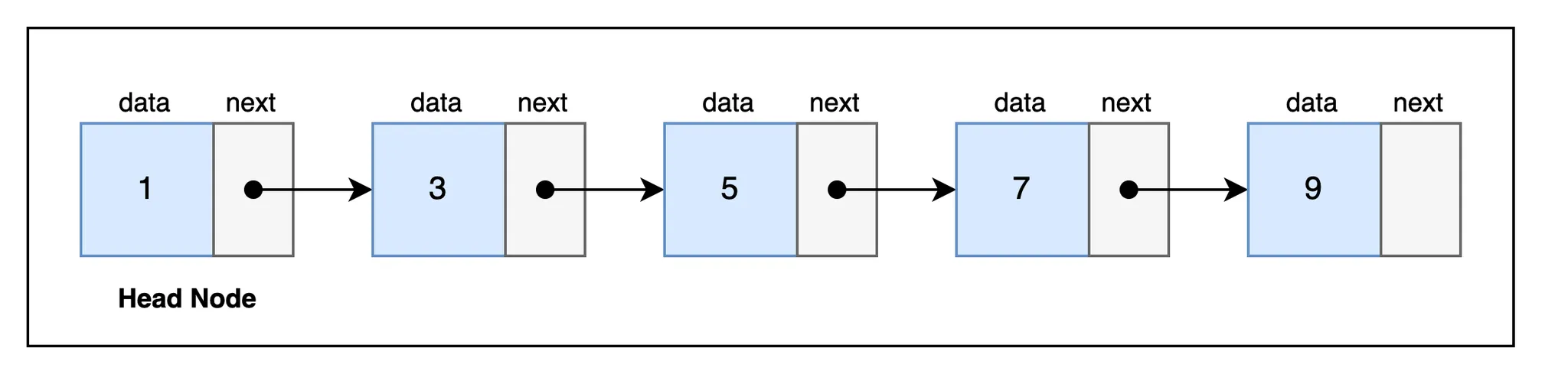
노드는 값을 저장하는 data와 다음 노드를 가리키는 next 포인터로 구성된다.
첫 번째 노드를 헤드 노드(Head Node)라고 하며, 탐색은 항상 헤드 노드에서 시작된다. 특정 데이터를 찾기 위해서는 헤드 노드부터 차례대로 데이터를 비교하면서 next 포인터를 따라가며 탐색한다.
예를 들어서 data가 3인 노드를 찾고 싶다면 아래와 같은 과정을 거치게 된다.
- 헤드 노드부터 탐색을 시작하며, 헤드 노드의 값인 1과 찾으려는 값인 3을 비교한다.
- 값이 다르기 때문에 헤드 노드의 next 포인터를 따라서 다음 노드로 넘어간다.
- 다음 노드의 값인 3과 찾으려는 값인 3을 비교했을 때 동일하기 때문에 탐색이 완료된다.
이처럼 연결 리스트는 헤드 노드부터 순차적으로 접근해야 하므로 탐색 속도가 느리다.
하지만 맨 앞과 뒤에 노드를 추가할 때는 포인터만 연결해주면 되기 때문에 배열에 비해서 삽입 / 삭제가 용이하다.
연결 리스트의 특성
- 특정 노드 탐색 시 → 헤드 노드부터 순차적으로 접근해야 하므로 시간 복잡도 O(N) 소요
- 특정 노드의 인덱스를 알고 있을 때 삽입 / 삭제 → 포인터의 위치만 변경하면 되므로 시간 복잡도 O(1) 소요
- 특정 노드의 인덱스를 모를 때 삽입 / 삭제 → 노드를 탐색하고 삽입 / 삭제해야 하므로 시간 복잡도 O(N) 소요
연결 리스트 종류
위에서 설명한 내용은 단일 연결 리스트(Singly Linked List)에 대한 설명이다.
단일 연결 리스트는 다른 노드에 접근할 수 있는 방법이 next 밖에 없어서 한 쪽으로만 접근할 수 있다. 이러한 구조는 이전 요소로 접근하기 위해서는 다시 탐색해야 하는 문제점이 있다.
만약 크기가 10000인 연결 리스트가 있을 때, 9999번 인덱스의 노드에 접근하기 위해서는 9999번 이동해야 하는데 이러한 문제점을 극복한 연결 리스트가 양방향 연결 리스트(Doubly Linked List) 이다.
양방향 연결 리스트(Doubly Linked List)
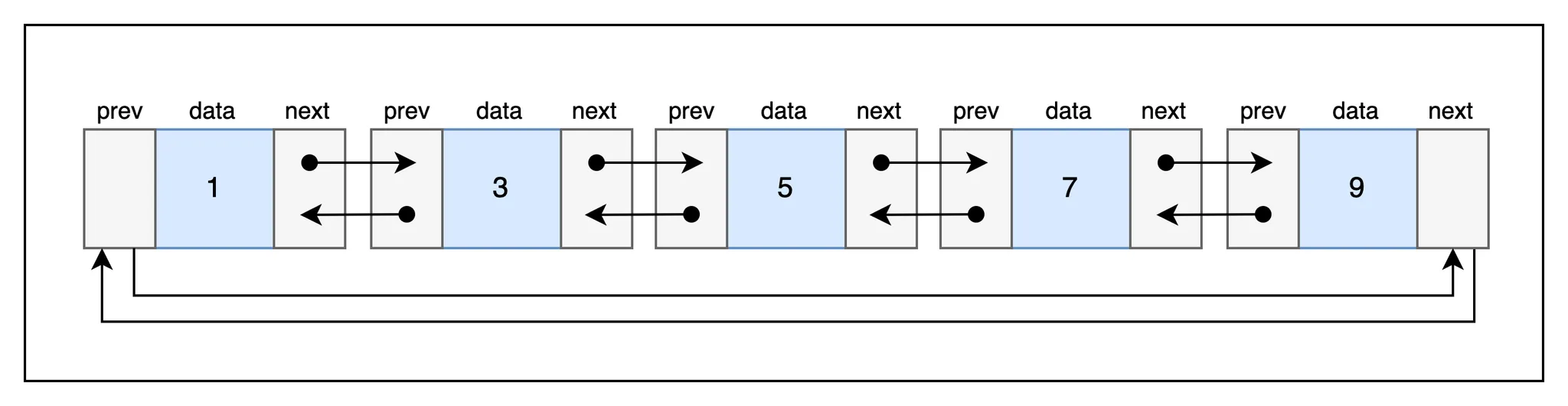
양방향 연결 리스트는 prev 포인터를 추가해서 이전 노드로 접근할 수 있도록 한 연결 리스트이다.
이러한 방식이 각 요소에 대한 접근이 단일 연결 리스트 방식보다 용이하기 때문에 기본적으로 많이 사용되는 방식이다. 실제로 파이썬의 collections 모듈의 deque나 자바의 LinkedList 자료형이 양방향 연결 리스트로 구현되어있다.
단일 연결 리스트 구현
from typing import Any
class Node:
def __init__(self, value: Any) -> None:
self.data = value
self.next = None
class SinglyLinkedList:
def __init__(self):
self.head = None
def add_node(self, value: Any) -> None:
new_node = Node(value)
if not self.head:
self.head = new_node
return
cur_node = self.head
while cur_node.next:
cur_node = cur_node.next
cur_node.next = new_node
def get_node(self, index: int) -> Node:
cur_idx = 0
cur_node = self.head
while cur_idx < index:
cur_node = cur_node.next
cur_idx += 1
if not cur_node:
raise Exception("노드가 존재하지 않습니다.")
return cur_node
def delete_node(self, index: int) -> None:
if self.is_empty():
raise Exception("리스트가 비어있습니다.")
if index == 0:
self.head = self.head.next
return
node = self.get_node(index - 1)
node.next = node.next.next
def is_empty(self) -> None:
return self.head is None
시간 복잡도 비교 (정적 배열 vs 동적 배열 vs 연결 리스트)
| 특정 요소 조회 | 맨 앞 삽입 / 삭제 | 맨 뒤 삽입 / 삭제 | 중간 삽입 / 삭제 | |
|---|---|---|---|---|
| 정적 배열 | O(1) | O(N) | O(N) | O(N) |
| 동적 배열 (리스트) | O(1) | O(N) | O(1) | O(N) |
| 연결 리스트 | O(N) | O(1) | O(1) | O(1) |
- 정적 배열의 경우 크기가 고정적이기 때문에 삽입 / 삭제 시 새로운 배열을 선언해서 요소들을 이동시켜야 하므로 시간 복잡도 O(N)이 소요
- 반면에 동적 배열의 경우 맨 앞 삽입 / 삭제는 마찬가지로 요소들의 이동이 필요하기 때문에 시간 복잡도 O(N)이 소요되지만, 맨 뒤에 삽입 / 삭제할 때는 여유 공간이 동적으로 추가되기 때문에 요소들의 이동이 일어나지 않기 때문에 시간 복잡도가 O(1)만 소요
- 연결 리스트의 경우 삽입 / 삭제 대상의 이전 노드를 알고 있으면 포인터만 변경 해주면 되기 때문에 시간 복잡도가 O(1)만 소요되지만, 모르는 경우 위치를 탐색해야 하므로 시간 복잡도 O(N) 만큼이 소요
마치며
이렇게 배열, 연결 리스트에 대해서 정리 해보았습니다.
연결 리스트의 경우 어렴풋하게 알고 있었는데 이번에 정리하면서 명확하게 알게 되어서 좋았습니다.
특히 파이썬에서는 리스트 맨 앞 요소를 pop 할 때 시간 복잡도가 O(N)이나 소요되는데 덱(deque)에서는 왜 시간 복잡도가 O(1) 밖에 소요되지 않는지에 대해서 잘 모르고 있었는데, 이번에 배열의 연속된 메모리 구조와 양방향 리스트의 특성을 알게 되면서 제대로 이해하게 된 것 같습니다.
이어서 자료구조 개념정리2로 스택, 큐, 해시 테이블을 정리해보도록 하겠습니다.
긴 글 읽어주셔서 감사합니다 :)

항상 글 잘 보고있습니다