요약
GPT 탄생 배경
- labeled 데이터 부족
- unlabeled 데이터 충분
- unlabled text corpus(말뭉치)에서 language model pre-training하고 task 맞게 fine-tuning
unlabeled text 문제(semi supervised learning 어려움)
- world level이상 정보 얻기 어려움
- 어떤 optmization objective가 효과적인지 불분명
- 학습된 표현을 target task에 효과적으로 전달하는 consensus 없음
GPT에서 사용한 방법
- unsupervised pre training + supervised fine tuning → semi supervise
- 약간의 조정으로 적용 가능한 generative representation 학습
- unlabeled data에 language modeling objective → target task에 적용
- transformer 사용
배경
Unlabeled Data
- word level이상 정보 얻기 어려움
- 어떤 optmization objective가 효과적인지 불분명
- 학습된 표현을 target task에 효과적으로 전달하는 consensus 없음
- → semi supervised 어려움
GPT-1 사용 방식
- wide range 약간의 변형으로 적용 가능하게 범용 representation 학습
- unlabeled data에 language modeling objective
- target task에 적용
- transfromer 사용
- long term dependency에 robust 한 결과
Related work
semi supervised learning
- 기존 - unlabeled data to word or phrase level
- 최근 - word embedding
- sentence level
unsupervised pre training
- goal is 좋은 initialization point 찾기
- LSTM은 좁은 범위
- transformer 사용으로 해결 가능
Auxiliary training objectives
- semi supervised 대체 방안
- gpt에서 사용
- unsupervised pre training으로 먼저 target 관련 linguistic aspect 미리 학습
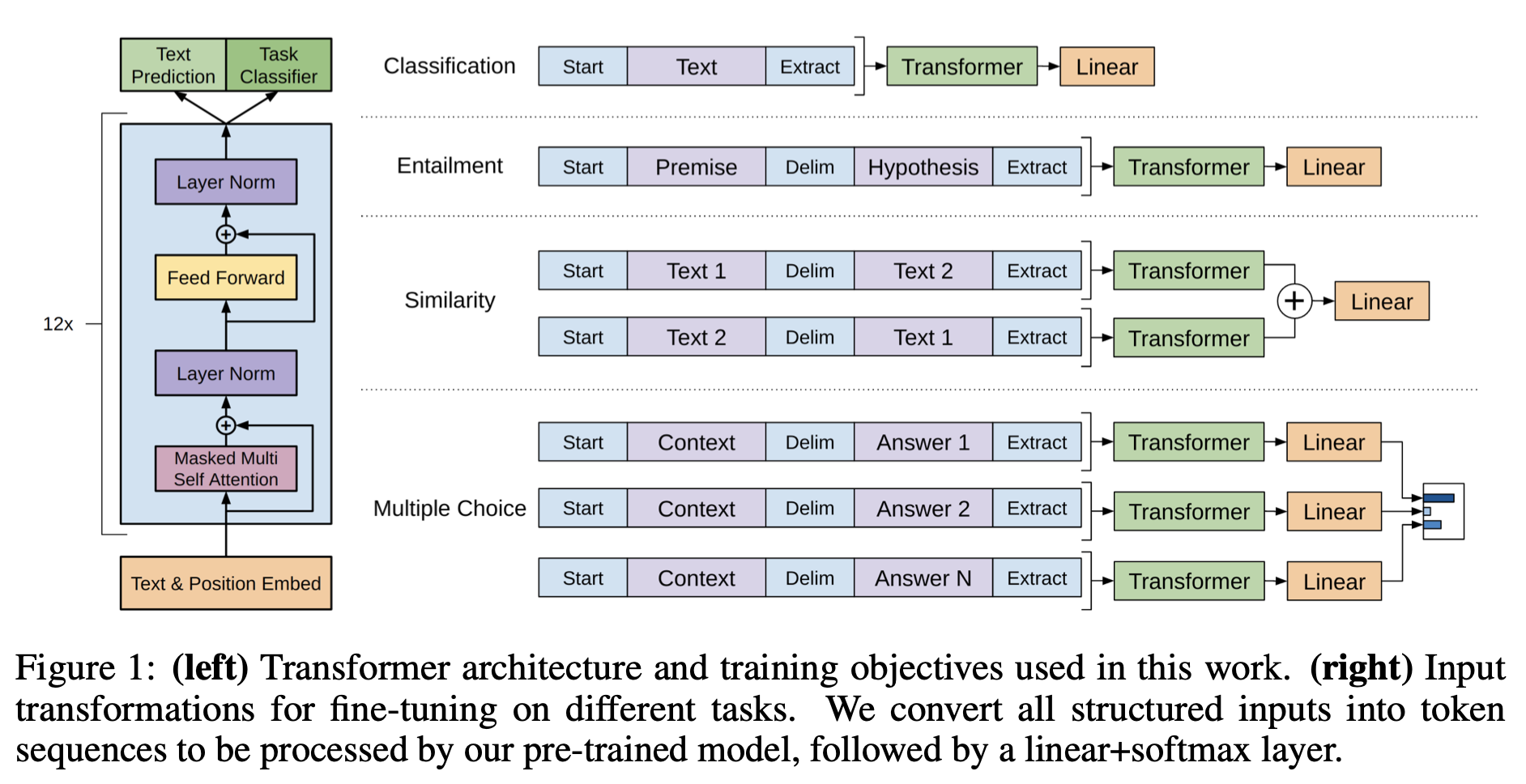
Framework
high capacity language model → fine-tuning
-
unsupervised pre-training

- maxmizing likelihood
- k : size of context window
- trained using stochastic gradient descent

- multi layer transformer decoder
-
Supervised fine-tuning
- pre training에서 만든 language model도 fine tuning task에 맞게 보조 목표로 추가
- convergence 가속화
- improving generalization of supervised model
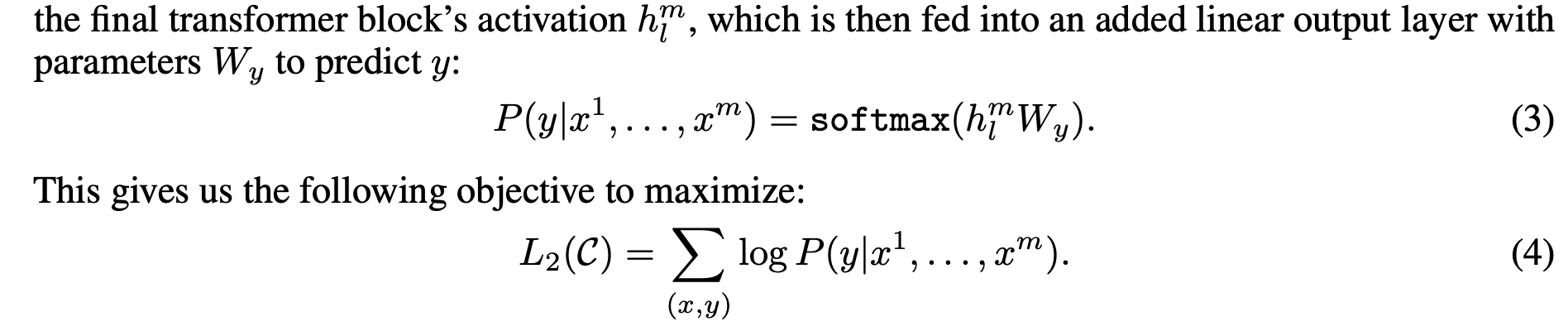

- optimize (5)
- pre training에서 만든 language model도 fine tuning task에 맞게 보조 목표로 추가
-
Task specific input transformation
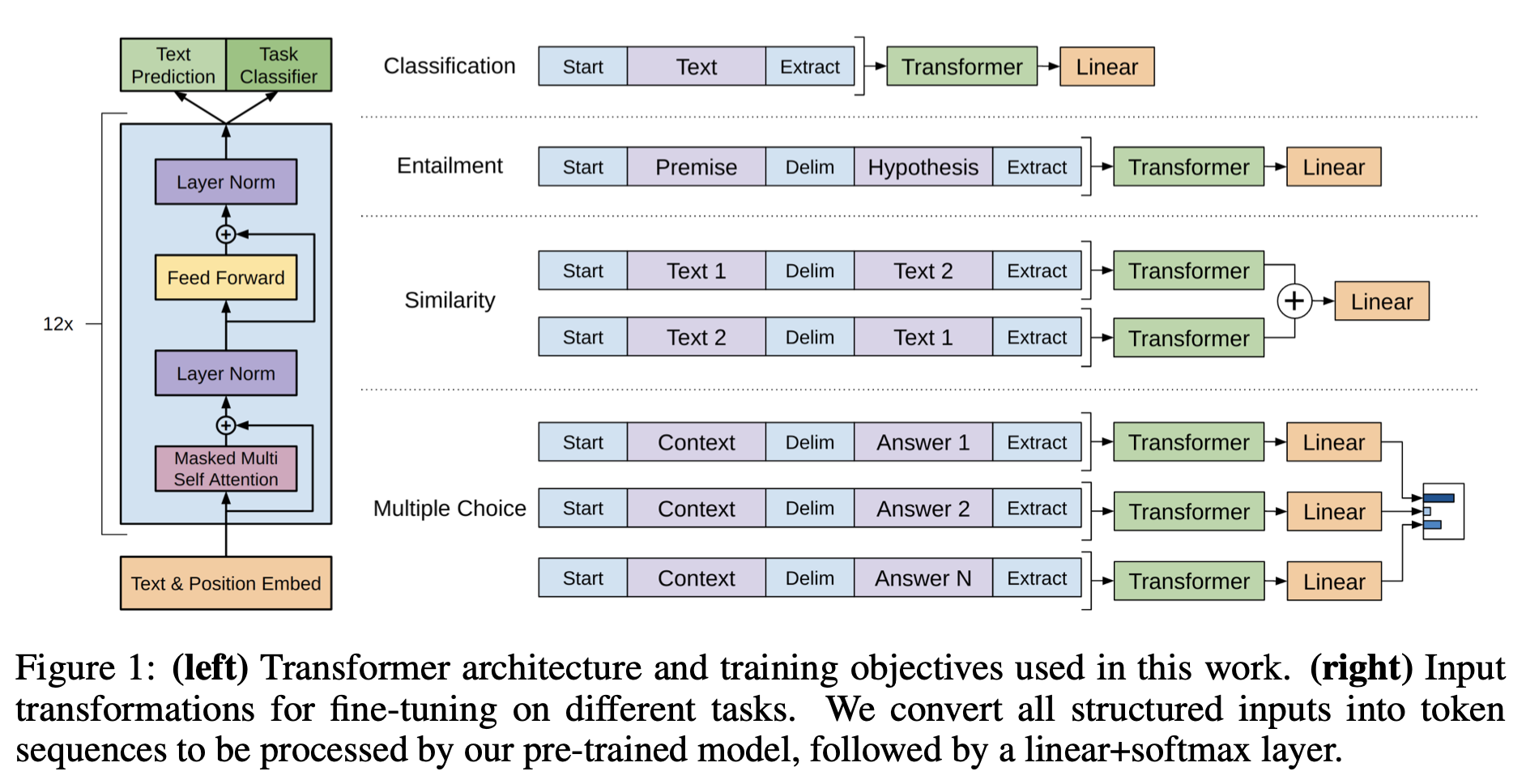
- 기존에는 task specific한 목표에 따라 학습
- 많은 customize 필요, transfer learning 사용 안 함
- So, traversal style approach
- convert structured input into ordered sequence
실험
BooksCorpus dataset 사용
- long range
- 다양한 장르
1B Word Benchmark 사용

SOTA 달성
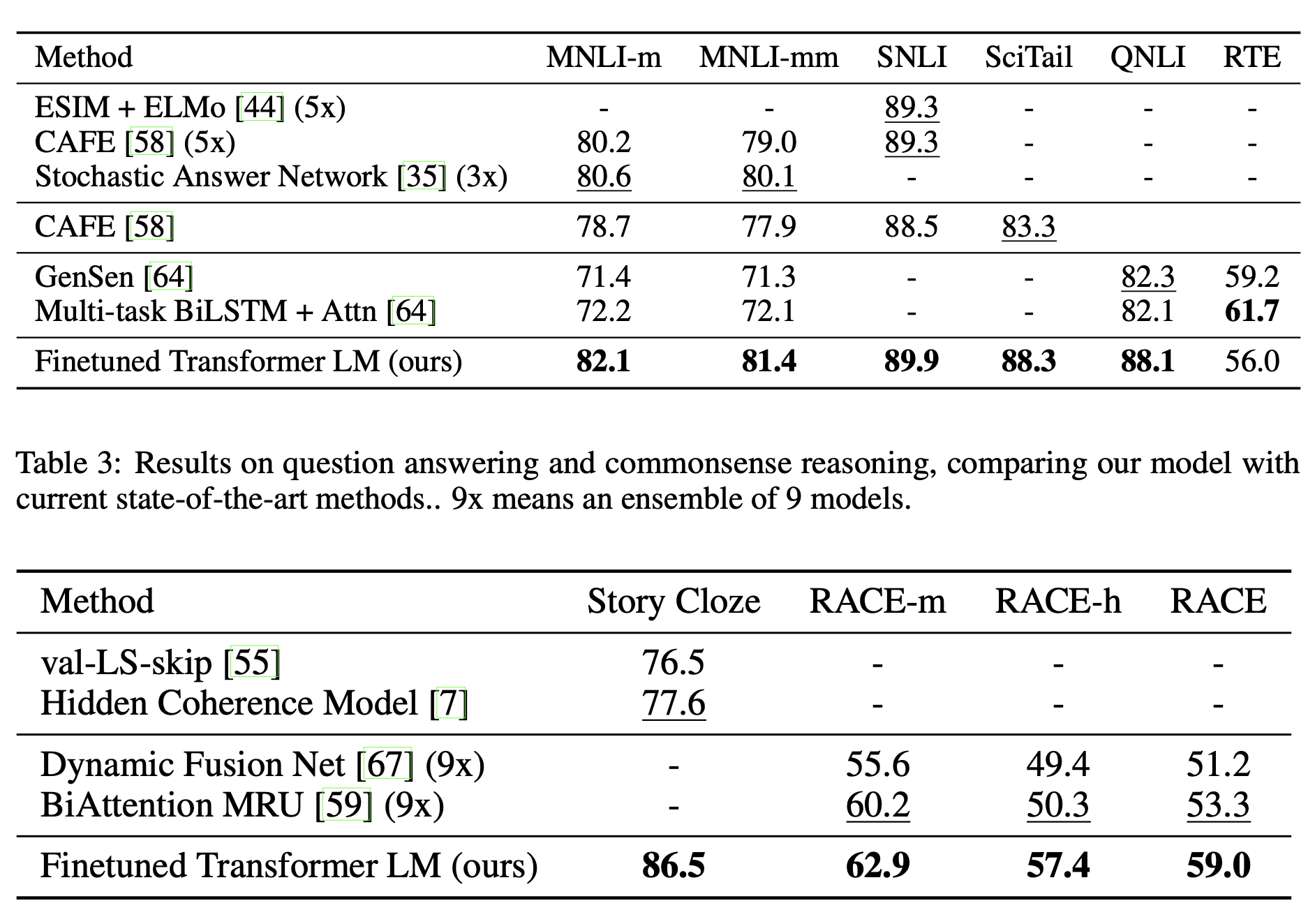
Analysis
- transfer시 layer 개수에 따라 성능 향상 경향

- pre trained 없을 때 약 15% 하락
- fine tuning시 LM 목적함수 제외시 큰 dataset에서 성능 떨어지고 작은 것은 성능 향상
- Transformer 대신 LSTM 쓰면 약 6% 하락
결론
- BERT보다 언어 생성에 유리
- LSTM 대신 transformer 구조를 활용
- pre training 사용 → fine tuning
- sota 달성
삽입 사진 출처: 원본 논문

중앙대학교 Data Science Lab입니다.