
1. Introduction
The ability to learn effectively from raw text is crucial to alleviating the depedence on supervised learning in natural language precessing(NLP). Most deep learning methods require substantial amounts of manually labeled data, which restricts their applicability in many domains that suffer from a dearth of annotated resources.
raw text에서 효과적으로 학습할 수 있는 방법은 자연어 처리에서 지도 학습의 의존성을 완화하는데 필수적이다. 대부분의 딥러닝 방법은 많은 양의 손으로 만든 labeled data를 요구하는데, 이는 주석 자원의 부족 현상을 겪고 있는 도메인에서 적용하는데 어려움을 준다.
- annotated resources : POS tags, syntactic or semantic features를 의미합니다. (http://www.cs.cmu.edu/~ytsvetko/jsalt-part1.pdf)
- 제가 지금 텍스트를 쓰는 것처럼 텍스트 만을 이용하면 비지도 데이터를 많이 얻을 수 있지만, 작성하고 있는 데이터가 “논문 정리” 라는 지도 데이터로 학습되기 위해선 제가 이 텍스트에 대해 “논문 정리”라고 태깅 작업을 해야 합니다. 이는 매우 오랜 시간을 필요로 하는 것은 당연합니다.
In these situations, models that can leverage linguistic information from unlabeled data provide a valuable alternative to gathering more annotation, which can be time-consuming and expensive. Further, even in cases where considerable supervision is available, learning good representations in an unsupervised fashion can provide a significant performance boost. The most compelling evidence for this so far has been the extensive use of pretrained word embeddings to improve performance on a range of NLP tasks.
이러한 상황에서, 비지도 데이터의 언어학 정보를 이용하는 모델은 많은 많은 시간과 비용이 드는 주석(annotation) 수집에서 유용한 대안을 제공한다. 더욱이, 지도 학습이 가능한 경우에서도 비지도 방식을 이용하여 좋은 파라미터를 학습하는 것은 상당한 성능 향상을 제공할 수 있다. 지금까지 이에 대한 설득력 있는 증거는 자연어 처리 분야에서 성능 개선을 위해 사전 훈련된 단어 임베딩을 광범위하게 사용한 것이다.
- 예를 들어, word2vec의 경우 레이블을 필요로 하지 않고, target word와 context를 이용하여 임베딩을 이용합니다. 즉, word2vec와 같은 임베딩도 일종의 비지도 학습입니다. 우리는 비지도 학습을 이용하여 학습 훈련의 성능을 높여왔습니다.
Leveraging more than word-level information from unlabeled text, however, is challenging for two main reasons. First, it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer. Recent research has looked at various objectives such as language modeling, machine translation, and discourse coherence, with each method outperforming the others on different tasks.
하지만 비지도 데이터에서 단어 수준 정보 이상으로 이용하는 것은 두 가지 이유 때문에 문제가 있다. 첫 번째는 어떤 타입의 최적화 목표(optimization objective)가 전이 하는데 효율적인 텍스트 표현을 학습하는데 효율적인지 알 수 없다는 점이다. 최근 연구는 언어 모델링, 기계 번역, 담화 추론 등의 각각의 방법은 다른 방법에서 보다 높은 성능을 보여줬다.
.
Second, there is no consensus on the most effective way to transfer these learned representations to the target task. Existing techniques involve a combination of making task-specific changes to the model architecture, using intricate learning schemes and adding auxiliary learning objectives. These uncertainties have made it difficult to develop effective semi-supervised learning approaches for language processing.
두 번째는 학습된 표현을 target task로 전이하는데 가장 최적화된 방법에 대한 일치된 의견이 없다는 것이다. 현존하는 기술들은 모델 구조에 목표에 특성화된 변화의 조합을 이용하는데, 이는 복잡한 학습 전략이나 보조 학습 목표를 사용해야 한다. 이러한 불확실성은 언어 처리를 위한 효율적인 준지도 학습 접근의 발전을 방해한다.
In this paper, we explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning. Our goal is to learn a universal
representation that transfers with little adaptation to a wide range of tasks. We assume access to a large corpus of unlabeled text and several datasets with manually annotated training examples(target tasks).
본 논문에서는 언어 이해 임무(language understanding tasks)를 위한 준지도 학습 접근 방법을 탐색하는데, 비지도 학습의 사전 훈련과 지도 학습의 fine-tuning을 이용한다. 본 논문의 목표는 보편적인 표현을 얻어서 다양한 태스크에서 활용할 때 약간의 변화만으로 전이가 가능하도록 하는 것이다. 이를 위해 큰 비지도 데이터의 말뭉치와 여러개의 손수 태깅된 훈련 예시를 이용한다.
- 저희가 아는 비지도 학습을 이용한다는 것입니다. 단, 여기서 주목할 점은 “큰” 비지도 데이터 말뭉치와 “여러개”의 직접 태깅된 훈련 데이터셋입니다.
Our setup does not require these target tasks to be in the same domain as the unlabeled corpus. We employ a two-stage training procedure. First, we use a language modeling objective on the unlabeled data to learn the initial parameters of a neural network model. Subsequently, we adapt these parameters to a target task using the corresponding supervised objective.
우리의 셋업은 비지도 말뭉치를 이용함으로써 target task가 같은 도메인일 필요가 없다는 것이다. 우리는 two-stage 훈련 절차를 가진다. 첫 째로, 우리는 비지도 데이터를 이용한 언어 모델링 목표(language modeling objective)를 이용하여 신경망 모델의 파라미터 초기값을 얻는 것이다. 그 다음 우리는 이 파라미터를 target task에 전이하여 일지하는 지도 목표에 사용한다.
- 매우 큰 비지도 데이터를 이용하여 보편적인 모델을 만드는 것입니다. 현재 KoGPT-2처럼 매우 큰 모델을 이용하여 대본, 위키피디아, 챗봇 등에 활용될 수 있는데 KoGPT-2의 경우 40GB 이상의 텍스트로 학습된 한국어 디코터(decoder) 모델입니다.(https://github.com/SKT-AI/KoGPT2) 뒤에서 후술되지만 GPT의 경우 트랜스포머에서의 인코더-디코더에서 디코더 파트만 이용합니다.
트랜스포머 내용의 경우 이전에 다루었기 때문에 생략했습니다.
We evaluate our approach on four types of language understanding tasks – natural language inference, question answering, semantic similarity, and text classification. Our general task-agnostic model
outperforms discriminatively trained models that employ architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. (중략). We also analyzed zero-shot behaviors of the pre-trained model on four different settings and demonstrate that it acquires useful linguistic knowledge for downstream tasks.
우리는 4개의 언어 이해 태스크로 접근한다. 자연어 추론, QA, 텍스트 유사도, 텍스트 분류이다. 우리의 일반적인 태스크와 관련없는 모델은 각각의 태스크에 특별히 맞추어진 구조를 이용한 모델보다 분명하게 더 높은 성능을 보여준다. 이는 연구된 12개의 태스크 중 9개에서 SOTA를 보였다. 또한 각기 다른 4개의 세팅에서 사전 훈련된 모델의 zero-shot behavior를 분석했는데, 하위 태스크에서 유용한 언어 지식을 획득한다는 것을 입증했다.
- 자연어 추론: 자연어 이해를 기반으로 모델의 추론 능력을 평가하는 작업으로 두 문장의 의미 관계를 함의(Entailment), 모순(Contradiction), 중립(Neutral)으로 분류하는 문장 쌍 분류의 일종이다. 두 문장은 전제와 가설로 나누어지는데, 전제를 참이라고 가정할 때 가설의 내용이 참인지, 거짓(모순)인지, 혹은 알 수 없는지(중립)에 따라 두 문장의 관계가 분류된다. (https://www.koreascience.or.kr/article/CFKO202130060562801.pdf, 의존 구문 분석을 활용한 자연어 추론)
- 텍스트 유사도 : 각기 다른 두 텍스트가 얼마나 유사한지를 나타내는지 나타내는 표현. ex) “이 요리를 누가 만들었지?” 와 “이 볶음밥 누가 만들었어?”는 같은 의미이지만 데이터 상으로는 다른 데이터가 되는데, 텍스트의 “의미”를 파악해서 두 텍스트의 유사도를 확인한다. (https://wiserloner.tistory.com/931)
- Zero-shot behavior를 자세히 참고하기 위해선 다음의 논문을 참조하면 됩니다.(https://arxiv.org/abs/2011.08641, **A Review of Generalized Zero-Shot Learning Methods**).
- 요약 부분 번역 Zero-shot behavior은 전이 학습에서 발전된 기계학습의 한 종류이다. 각기 다른 특징을 가지고 있는 A와 B로 학습된 모델이 A와 B의 특징을 모두 가지고 있는 C를 만났을 때 새로운 클래스인 C로 예측되도록 학습하는 방법을 말합니다. 즉, seen(source) data로 학습된 모델이 unseen(target) data를 만났을 때 unseen label로 분류되도록 하는 것을 목표로 합니다. 참고: https://deep-learning-study.tistory.com/873, https://m.blog.naver.com/with_msip/221886769247
- 요약 부분 번역 Zero-shot behavior은 전이 학습에서 발전된 기계학습의 한 종류이다. 각기 다른 특징을 가지고 있는 A와 B로 학습된 모델이 A와 B의 특징을 모두 가지고 있는 C를 만났을 때 새로운 클래스인 C로 예측되도록 학습하는 방법을 말합니다. 즉, seen(source) data로 학습된 모델이 unseen(target) data를 만났을 때 unseen label로 분류되도록 하는 것을 목표로 합니다. 참고: https://deep-learning-study.tistory.com/873, https://m.blog.naver.com/with_msip/221886769247
2. Related Works
Semi-supervised learning for NLP
Our work broadly falls under the category of semi-supervised learning for natural language. This paradigm has attracted significant interest, with applications to tasks like sequence labeling or text classification. The earliest approaches used unlabeled data to compute word-level or phrase-level statistics, which were then used as features in a supervised model.
우리의 작업은 자연어에서 준지도 학습의 분야에 영향을 받았다. 이 파라다임은 sequence labeling, text classification와 같은 태스크에 적용하는데 상당히 많은 관심을 이끌었다. 이전 작업들은 단어 수준이나 구문 수준의 통계학을 계산하기 위해 unlabeled data를 이용하였는데, 이는 이후 비지도 모델에서 feature에서 사용되었다.
- sequence labeling : 인공 신경망을 이용하여 태깅 작업하는 분야
Over the last few years, researchers have demonstrated the benefits of using word embeddings, which are trained on unlabeled corpora, to improve performance on a variety of tasks. These approaches, however, mainly transfer word-level information, whereas we aim to capture higher-level semantics. Recent approaches have investigated learning and utilizing more than word-level semantics from unlabeled data. Phrase-level or sentence-level embeddings, which can be trained using an unlabeled corpus, have been used to encode text into suitable vector representations for various target tasks.
과거 몇 년 동안 연구자들은 비지도 말뭉치를 이용한 워드 임베딩에의 유효성을 입증했는데, 이는 다양한 태스크에서 성능 향상을 보였다. 하지만 이 접근은 주로 단어 수준의 정보를 전이하는 것이고 본 논문에선 단어보다 높은 의미를 획득하는 것을 목표로 한다. 최근 접근은 비지도 데이터로부터 단어 수준의 의미 이상으로 학습하고 활용하는 것을 조사했다. 비지도 말뭉치를 이용하여 학습될 수 있는 구문 단위 또는 문장 단위 임베딩은 다양한 target task를 위해 적합한 벡터 표현으로 부호화되어 사용된다.
- 대부분의 워드 임베딩이 단어를 잘 표현하는데 목표를 두고 접근했다면, GPT는 위에 언급한 자연어 추론, 텍스트 유사도 등 더 높은 수준의 의미를 파악하는데 중점을 둔다는 의미입니다.
Unsupervised pre-training
Unsupervised pre-training is a special case of semi-supervised learning where the goal is to find a good initialization point instead of modifying the supervised learning objective. Early works explored the use of the technique in image classification and regression tasks. Subsequent research [15] demonstrated that pre-training acts as a regularization scheme, enabling better generalization in deep neural networks. In recent work, the method has been used to help train deep neural networks on various tasks like image classification [69], speech recognition [68], entity disambiguation [17] and machine translation [48].
비지도 사전훈련은 준지도 학습의 특별한 케이스이다. 목표는 지도 학습의 목표를 변경하지 않고 좋은 초기 값을 얻는 것이다. 초기 연구는 이미지 분류나 회귀 작업에서 사용되었다. 이후 연구에서 사전 훈련이 규제로 사용되어 신경망에서 좋은 일반화를 얻는데 사용할 수 있다는 것을 입증했다. 최근 연구에선 비지도 사전 훈련이 이미지 분류, 음성 인식, 엔티티 연결, 기계 번역 등에 사용되었다.
- 이를 설명하기 위한 일종의 예시입니다. https://proceedings.neurips.cc/paper/2018/file/2a38a4a9316c49e5a833517c45d31070-Paper.pdf(Supervised autoencoders: Improving generalization
performance with unsupervised regularizers)요약하면, autoencoder에서 reconstruction loss를 classifer loss와 연결한다면 두 loss의 balancing을 잡아주는 과정에서 autoencoder의 manifold learning에서 효율을 높여줍니다.
The closest line of work to ours involves pre-training a neural network using a language modeling objective and then fine-tuning it on a target task with supervision. Dai et al. [13] and Howard and
Ruder [21] follow this method to improve text classification. However, although the pre-training phase helps capture some linguistic information, their usage of LSTM models restricts their prediction
ability to a short range. In contrast, our choice of transformer networks allows us to capture longer range linguistic structure, as demonstrated in our experiments. Further, we also demonstrate the
effectiveness of our model on a wider range of tasks including natural language inference, paraphrase detection and story completion.
우리의 연구와 가장 비슷한 연구는 언어 모델링 목표를 신경망을 사전 훈련하고 지도를 이용한 target task로 fine-tuning하는 것이다. Dai et al., Howard, Ruder는 이 방법을 이용해 텍스트 분류에서 개선을 보였다. 하지만 사전 훈련이 언어학 정보를 획득하는데 도움을 줄지라도, LSTM model의 사용은 모델의 예측 능력을 작은 분야로 한정하는 것이다. 반면, 트랜스포머는 더 긴 범위로 언어학 구조를 파악할 수 있고 이는 우리의 실험으로 입증되었다. 더욱이, 우리는 우리의 모델의 효율성을 자연어 추론, 구문 탐색, 이야기 완성을 포함한 넓은 범위의 task에서 확인하였다.
Other approaches [43, 44, 38] use hidden representations from a pre-trained language or machine translation model as auxiliary features while training a supervised model on the target task. This involves a substantial amount of new parameters for each separate target task, whereas we require minimal changes to our model architecture during transfer.
다른 접근으로는 target task에서 지도 모델을 훈련하면서 사전 훈련된 언어나 기계 번역에서의 hidden representation을 보조 기능으로서 사용하는 것이다. 이는 각 target task를 위해 상당한 양의 새로운 파라미터를 필요하는 반면, GPT는 전이 과정에서 기존 구조에 약간의 변경만을 이용하는 장점을 가진다.
Auxiliary training objectives
Adding auxiliary unsupervised training objectives is an alternative form of semi-supervised learning. Early work by Collobert and Weston [10] used a wide variety of auxiliary NLP tasks such as POS tagging, chunking, named entity recognition, and language modeling to improve semantic role labeling. More recently, Rei [50] added an auxiliary language modeling objective to their target task objective and demonstrated performance gains on sequence labeling tasks. Our experiments also use an auxiliary objective, but as we show, unsupervised pre-training already learns several linguistic aspects relevant to target tasks.
보조 비지도 학습 목표를 추가하는 것은 준지도 학습의 대안이다. Collobert and Weston에 의한 초기 작업은 POS tagging, chunking, 엔티티 인식, 모델링와 같은 보조적인 NLP task를 사용하여 semantic role labeling을 향상했다. 최근 Rei는 보조 언어 모델링 목표를 target task에 붙였는데 sequence labeling task에서 성능 향상을 입증했다. 우리의 실험은 보조 목표를 사용하지만, 비지도 사전 학습은 미리 target task와 관련된 다양한 언어적 aspect를 배운다.
3. Framework
Our training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to
a discriminative task with labeled data.
우리의 훈련 과정은 두 개의 스테이지로 구성된다. 첫 스테이지는 큰 텍스트 말뭉치로 높은 가능성을 가진 언어 모델을 학습하는 것이다. 그 다음 fine-tuning 스테이지에선 labeled data로 각각의 task를 모델에 적응시킨다.
Unsupervised pre-training
Given an unsupervised corpus of tokens , we use a standard language modeling objective to maximize the following likelihood:
비지도 말뭉치 토큰 U가 주어졌을 때, 다음의 가능도를 최대화하기 위하여 표준 언어 모델링 목표를 사용한다.
. —- Eq. 1
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ. These parameters are trained using stochastic gradient descent [51].
In our experiments, we use a multi-layer Transformer decoder [34] for the language model, which is a variant of the transformer [62]. This model applies a multi-headed self-attention operation over the
input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:
여기서 k는 맥락 윈도우(context window)의 크기고, 조건부 확률 P는 파라미터 의 신경망을 이용하여 모델링 되었다. 이 파라미터는 SGD를 이용해 훈련된다. 논문의 실험에서, 우리는 다중 레이어 트랜스포머 디코더를 이용하는데, 이는 트랜스포머의 변형 형태이다. 이 모델은 input context에 tokemulti-head self-attention를 적용하고, position-wise feedforward layers를 통과하여 target token에 대한 output distribution을 생성한다.
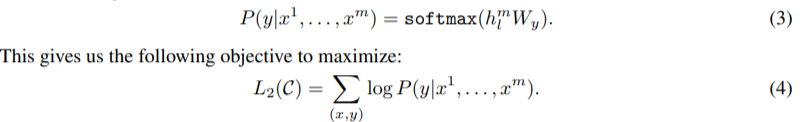
where is the context vector of tokens, n is the number of layers, is the token embedding matrix, and is the position embedding matrix.
여기서 U는 token의 맥락 벡터이고, n은 레이어의 개수, 는 token의 임베딩 매트릭스, 는 position embedding matrix이다.
Supervised fine-tuning
After training the model with the objective in Eq. 1, we adapt the parameters to the supervised target task. We assume a labeled dataset , where each instance consists of a sequence of input tokens,
along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation , which is then fed into an added linear output layer with
parameters to predict y:
방정식 1에서 objective의 모델을 훈련한 뒤에, 우리는 이 파라미터를 지도 target task로 전이시킨다. 우리는 레이블된 dataset C를 추정하는데, 각 instance는 input token sequence x1 ~ xm과 레이블 y로 구성된다. 입력은 사전 훈련된 모델을 통과하여 마지막 트랜스포머의 활성화값 을 얻는다. 이는 를 가진 linear output layer을 통과하여 y를 예측한다.

We additionally found that including language modeling as an auxiliary objective to the fine-tuning helped learning by (a) improving generalization of the supervised model, and (b) accelerating
convergence. This is in line with prior work [50, 43], who also observed improved performance with such an auxiliary objective. Specifically, we optimize the following objective (with weight λ):
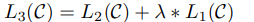 )
)
우리는 언어 모델링을 fine-tuning의 보조적인 목표로 포함시키는 것은 도움을 주는데, (a)로 지도 모델의 일반화를 증가시키고, (b) 수렴을 가속화한다. 이에 대해 이전에도 관찰한 논문들이 있다. 특히, 가중치 람다를 최적화한다.
- Related work의 unsupervised learning에서 언급한 것처럼 두 개의 loss를 밸런싱함으로써 (a)와 (b)를 얻을 수 있습니다. 논문에 “prior work”라고 언급한 논문에서는 이 람다를 0.1로 설정하였습니다. (https://arxiv.org/pdf/1704.07156.pdf, Semi-supervised Multitask Learning for Sequence Labeling)
Overall, the only extra parameters we require during fine-tuning are Wy, and embeddings for delimiter tokens (described below in Section 3.3).
종합적으로 fine-tuning 과정에서 추가한 파라미터는 Wy와 delimiter token을 위한 임베딩입니다.
Task-specific input transformations
For some tasks, like text classification, we can directly fine-tune our model as described above. Certain other tasks, like question answering or textual entailment, have structured inputs such as
ordered sentence pairs, or triplets of document, question, and answers. Since our pre-trained model was trained on contiguous sequences of text, we require some modifications to apply it to these tasks.
텍스트 분류와 같은 몇몇 태스크에선 위에서 말한 것처럼 직접적으로 모델을 fine-tuning한다. 하지만 QA, textual entailment와 같은 몇몇 다른 태스크는 순서를 가진 문장 쌍, 문서의 세 쌍, 질문과 대답 같은 인풋을 가진다. 우리의 사전 훈련된 모델은 인접한 텍스트의 문장에서 훈련되므로, 이러한 태스크에 적용하기 위해 변경이 요구된다.
- contiguous : sequence를 계속 주면서, 그 다음 sequence를 예측하는 방식을 이야기한다. BERT라면 MASK를 이용하여 중간의 단어를 예측하는 거였다면, GPT의 경우 그 뒤의 문장을 해석할 수 있도록 모델이 훈련된다.
Previous work proposed learning task specific architectures on top of transferred representations [44]. Such an approach re-introduces a significant amount of task-specific customization and does not
use transfer learning for these additional architectural components. Instead, we use a traversal-style approach [52], where we convert structured inputs into an ordered sequence that our pre-trained
model can process.
이전 연구들은 전이된 표현 위에 태스크에 특화된 구조를 배우는 것을 제시했다. 이러한 접근은 task-specific customization에 상당한 양을 재도입하고, 추가적인 구조 요소를 위해 전이 학습을 사용하지 않는다. 대신에, 우리는 구조적인 input을 순서를 가진 문장으로 변환하는데 이 문장은 우리의 사전 훈련된 모델이 처리할 수 있다.
- 전이된 표현이 전이 학습을 의미하는 것이 아닙니다. previous work가 말하는 추가적인 customization이 의미하는 것은 ELMo입니다. ELMo는 양방향 LSTM을 이용하는데, 딥러닝 모델을 이용한 단어 임베딩을 말합니다. 즉, ELMo를 통해서 표현된 학습 데이터가 신경망으로 전이되어 추가적인 계산을 진행하므로 이는 많은 양의 계산이 오버헤드가 발생합니다. 하지만 GPT의 경우 추가적인 모델 없이, 전이 학습을 이용하여 추가적인 계산을 방지하는 것입니다. (https://arxiv.org/pdf/1802.05365.pdf, Deep contextualized word representations)
<< discussion : ELMo또한 pre-trained model로 이해하고 있었는데, does not use transfer learning이라고 말한 이유가 무엇인지 >>
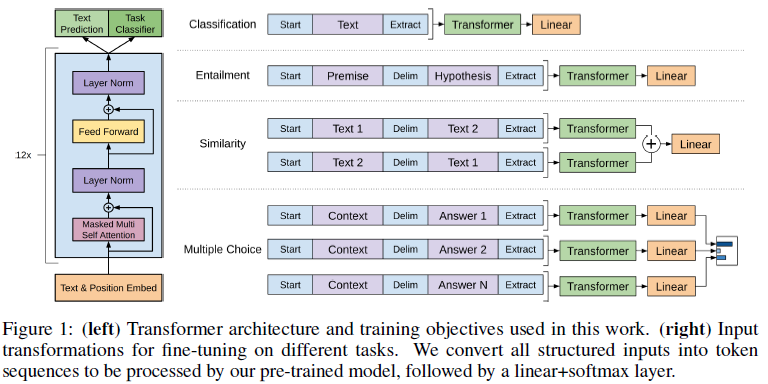
These input transformations allow us to avoid making extensive changes to thearchitecture across tasks. We provide a brief description of these input transformations below and Figure 1 provides a visual illustration. All transformations include adding randomly initialized start and end tokens .
Textual entailment
For entailment tasks, we concatenate the premise p and hypothesis h token sequences, with a delimiter token ($) in between.
전제 p와 가설 h의 token seqeunce를 concat했고, 이는 delimiter $로 나누어진다.
- Textual entailment는 주어진 두 문장에 대한 추론으로, natural language inference입니다. 두 문장이 주어졌을 때 첫 번째 문장이 두 번째 문장을 수반하는가 혹은 위배되는가를 해결함으로써 모델을 학습한다.
Similiarity
For similarity tasks, there is no inherent ordering of the two sentences being compared. To reflect this, we modify the input sequence to contain both possible sentence orderings (with a
delimiter in between) and process each independently to produce two sequence representations which are added element-wise before being fed into the linear output layer.
similiarity task에선, 비교되는 두 문장에 대한 고유한 순서가 없다. 이를 반영하기 위하여 우리는 input sequence가 가능한 문장 순서를 갖도록 변경하는데, entailment와 마찬가지고 delimiter를 이용한다. 그리고 각각을 독립적으로 처리하여 두 문장의 표현 을 생성하는데, 이는 linear layer로 가기 전에 element-wise에 추가된다.
Question Answering and Commonsense Reasoning
For these tasks, we are given a context document z, a question q, and a set of possible answers {}. We concatenate the document context and question with each possible answer, adding a delimiter token in between to get . Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.
QA에서, 문서 z, 질문 q, 가능한 답변 ak가 주어졌다. 문서 문맥과 질문을 가능한 답변과 concatenate하고, [z; q; $; ak]을 얻기 위해 사이 사이에 delimiter를 추가한다. 각 sequence는 모델에서 독립적으로 처리되고 softmax layer로 정규화되어 가능한 답변 사이의 output에 대한 확률 분포를 생성한다.
4. Experiments
4.1 Setup
Unsupervised pre-training
We use the BooksCorpus dataset [71] for training the language model. It contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance. Crucially, it contains long stretches of contiguous text, which allows the generative model to learn to condition on long-range information. An alternative dataset, the 1B Word Benchmark, which is used by a similar approach, ELMo [44], is approximately the same size but is shuffled at a sentence level - destroying long-range structure. Our language model achieves a very low token level perplexity of 18.4 on this corpus.
언어 모델을 훈련하기 위해 BooksCorpus dataset을 이용한다. 이 데이터셋은 어드벤쳐, 판타지, 로맨스 등의 다양한 장르를 가진 7000개의 출판되지 않는 책을 포함한다. 특히, 이는 긴 길이의 이어지는 텍스트를 포함하는데 생성 모델이 긴 범위의 정보에 대한 조건을 배울 수 있게 한다. 유사한 접근으로 사용되는 ELMo는 거의 같은 크기이지만 문장 수준에서 섞이게 되어 긴 범위의 구조를 파괴시킨다. 우리의 언어 모델은 이 말뭉치에서 18.4의 perplexity를 달성하였다.
- perplexity는 낮을수록 좋은 것이고, GPT는 낮은 perplexity를 달성했음을 논문에서 밝혔다.
Model specifications
Our model largely follows the original transformer work [62]. We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads). For the position-wise feed-forward networks, we used 3072 dimensional inner states. We used the Adam optimization scheme [27] with a max learning rate of 2.5e-4. The learning rate was increased linearly from zero over the first 2000 updates and annealed to 0 using a cosine schedule. We train for 100 epochs on minibatches of 64 randomly sampled, contiguous sequences of 512 tokens.
우리 모델은 기존의 트랜스포머 방식을 따른다. 12개의 디코더만을 가지는 트랜스포머는 768 차원, 12개의 attention head인 self-attention heads를 가진다. position-wise feed-forward networks를 위해 3072개의 리니어 크기를 가진다. Adam optimization의 learning rate는 2.5e-4이다. warmup scheduler처럼 0부터 시작하여 선형적으로 2000 까지 증가하고, cosine scheduler를 이용하여 0으로 무효화시킨다. 우리는 64개의 랜덤한 샘플을 가진 미니배치로 100 에포크 동안 학습하였고, 이 샘플은 512개의 연속된 문장을 가진다.
Since layernorm [2] is used extensively throughout the model, a simple weight initialization of N(0; 0:02) was sufficient. We used a bytepair encoding (BPE) vocabulary with 40,000 merges [53] and residual, embedding, and attention dropouts with a rate of 0.1 for regularization. We also employed a modified version of L2 regularization proposed in [37], with w = 0:01 on all non bias or gain weights. For the activation function, we used the Gaussian Error Linear Unit (GELU) [18]. We used learned position embeddings instead of the sinusoidal version proposed in the original work. We use the ftfy library2 to clean the raw text in BooksCorpus, standardize some punctuation and whitespace, and use the spaCy tokenizer.3.
layer normalization은 모델 전체에서 사용되므로 N(0, 0.02)의 간단한 가중치 초기값으로 충분하다. 우리는 40,000의 집합을 가진 BPE와 residual embedding, 규제를 위해 0.1의 dropout을 사용한다. 우리는 L2 규제를 사용하는데 bias가 없거나 gain weight가 없는 상태에서 w=0:01이다. 활성화 함수에서 GELU 함수를 사용한다. 기존 연구에서 사용된 sinosoidal version 대신 학습된 poistion embeddings을 사용한다. BooksCorpus의 raw text를 깨끗하게 하기 위해 ftfy library2를 사용하고 구두점, 공백을 표준화(제외)하고 spaCy tokenizer3을 사용한다.
Fine-tuning details
Unless specified, we reuse the hyperparameter settings from unsupervised pre-training. We add dropout to the classifier with a rate of 0.1. For most tasks, we use a learning rate of 6.25e-5 and a batchsize of 32. Our model finetunes quickly and 3 epochs of training was sufficient for most cases. We use a linear learning rate decay schedule with warmup over 0.2% of training. was set to 0.5.
명시되지 않은 경우, 우리는 비지도 사전 훈련으로부터 얻은 하이퍼파라미터 세팅을 재사용한다. classifier에 0.1의 dropout을 추가한다. 대부분의 task에서 6.25e-5의 learning rate를 설정하고, 32의 배치 사이즈를 이용한다. 우리의 모델은 빠르게 fine-tunes되고 3 에포크의 훈련은 대부분의 경우에서 유효하다. 우리는 선형적인 learning rate decay schedule에 0.2%의 warmup scheduler를 사용한다. 이 때 람다는 0.5로 설정된다.
4.2 Supervised fine-tuning
We perform experiments on a variety of supervised tasks including natural language inference, question answering, semantic similarity, and text classification. Some of these tasks are available as part of the recently released GLUE multi-task benchmark [64], which we make use of. Figure 1 provides an overview of all the tasks and datasets.
우리는 다양한 지도 task를 수행하는 실험하는데 자연어 추론, QA, 의미 유사도, 텍스트 분류이다. 몇몇 task는 최근 발표된 GLUE multi-task benchmark의 일부로써 사용 가능하다. Figure1은 논문에서 진행되는 task와 dataset의 개요를 보여준다.
Natural Language Inference
The task of natural language inference (NLI), also known as recognizing textual entailment, involves reading a pair of sentences and judging the relationship between them from one of entailment, contradiction or neutral. Although there has been a lot of recent interest [58, 35, 44], the task remains challenging due to the presence of a wide variety of phenomena like lexical entailment, coreference, and lexical and syntactic ambiguity.
자연어 추론(NLI) task는 textual entailment로 알려져 있다. NLI는 두 개의 문장이 주어지고 두 문장이 사이에 관계에서 수반된 문장인지, 모순된 문장인지, 중립된 문장인지 판단한다. NLI 분야는 많은 관심이 있었지만, task는 매우 아직 까지 어려운 분야로 남아있는데 lexical entailment, conference and lexical and syntactic ambiguity 같은 다양한 현상 때문이다.
- lexical entailment : Lexical Entailment is concerned with identifying the semantic relation, if any, holding between two words, as in (pigeon, hyponym, animal).(https://paperswithcode.com/task/lexical-entailment)
- 문장 간의 관계를 파악하는데 있어, 단어 사이에도 관계의 모호성에 대한 문제로 인해 NLI 분야에 어려움이 많다는 내용으로 해석했습니다.
We evaluate on five datasets with diverse sources, including image captions (SNLI), transcribed speech, popular fiction, and government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail) or news
articles (RTE).
우리는 다양한 source를 가지고 있는 다섯 개의 데이터셋으로 평가한다. 데이터셋에는 이미지 캡션, 대본, 유명 소설, 정부 발표, 위키피디아 기사, 과학 시험, 뉴스 기사로 이루어져 있다.
Table 2 details various results on the different NLI tasks for our model and previous state-of-the-art approaches. Our method significantly outperforms the baselines on four of the five datasets, achieving
absolute improvements of upto 1.5% on MNLI, 5% on SciTail, 5.8% on QNLI and 0.6% on SNLI over the previous best results. This demonstrates our model’s ability to better reason over multiple sentences, and handle aspects of linguistic ambiguity. On RTE, one of the smaller datasets we evaluate on (2490 examples), we achieve an accuracy of 56%, which is below the 61.7% reported by a multi-task biLSTM model. Given the strong performance of our approach on larger NLI datasets, it is likely our model will benefit from multi-task training as well but we have not explored this currently.
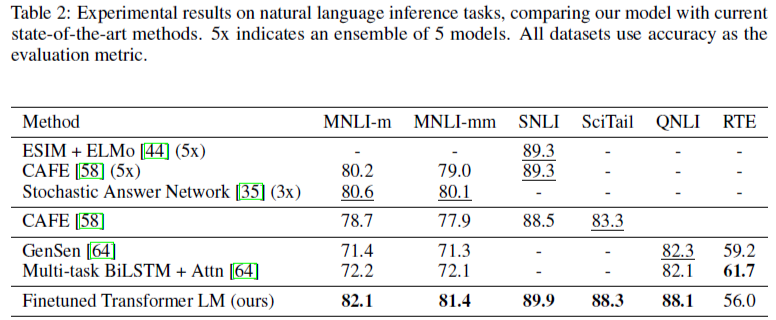
Table2는 NLI task에서 우리의 모델과 SOTA 모델의 결과이다. 우리의 방법은 분명히 다섯 개 중 네 개의 데이터셋에서 SOTA를 보였다. MNLI에선 1.5%, SciTail 에선 5%, QNLI에선 5.8%, SNLI에선 0.6%의 성능 향상을 보였다. 이는 우리의 모델이 여러개의 문장에서 더 좋은 추론 결과를 보여주고, 언어의 모호함을 더 좋게 다룸을 입증한다. RTE은 2490개의 예제를 가진 작은 데이터셋인데, 우리의 모델은 56%를 달성했고, SOTA 모델인 multi-task biLSTM model은 61.7%이였다. 큰 NLI dataset에서 좋은 성능을 보여주는 우리의 모델을 비추어봤을 때, 이는 우리의 모델이 multi-task training에서 더 좋은 성능을 보여줄 수 있을 것이다. 이는 입증되진 않았다.
Question answering and commonsense reasoning
Another task that requires aspects of single and multi-sentence reasoning is question answering. We use the recently released RACE dataset [30], consisting of English passages with associated questions from middle and high school exams. This corpus has been shown to contain more reasoning type questions that other datasets like CNN [19] or SQuaD [47], providing the perfect evaluation for our model which is trained to handle long-range contexts. In addition, we evaluate on the Story Cloze Test [40], which involves selecting the correct ending to multi-sentence stories from two options. On these tasks, our model again outperforms the previous best results by significant margins - up to 8.9% on Story Cloze, and 5.7% overall on RACE. This demonstrates the ability of our model to handle long-range contexts effectively.
단일, 다중 문장을 추론을 요구하는 task는 QA이다. 우리는 RACE dataset을 사용한다. 이 데이터셋은 중, 고등학교에서 문제와 관련된 영어 passage로 이루어져 있다. 이 데이터셋은 CNN 이나 SQuaD와 같은 데이터셋과 달리 많은 추론 유형 문제를 포함하고 있다. 그래서 이는 긴 범위의 맥락을 다룰 수 있도록 훈련된 우리의 모델을 평가하는데 완벽한 데이터셋이다. 더하여, 우리는 Story Cloze Test를 평가하는데, 두 개의 옵션으로부터 여러개의 문장 스토리 중 정확한 결말을 선택하는 것이다. 이 문제에서 우리의 모델은 다시 이전의 가장 좋은 모델의 성능보다 더 높은 성능을 보여주었다. Story Cloze에서 8.9%, RACE에서 5.7%이다. 이는 우리의 모델의 능력이 길이가 긴 문맥을 효과적으로 다룸을 입증한다.
- passage : a short piece of writing or music that is part of a larget piece of work(https://dictionary.cambridge.org/ko/사전/영어/passage). 지문으로 해석하면 될 것 같습니다.
Semantic Similarity
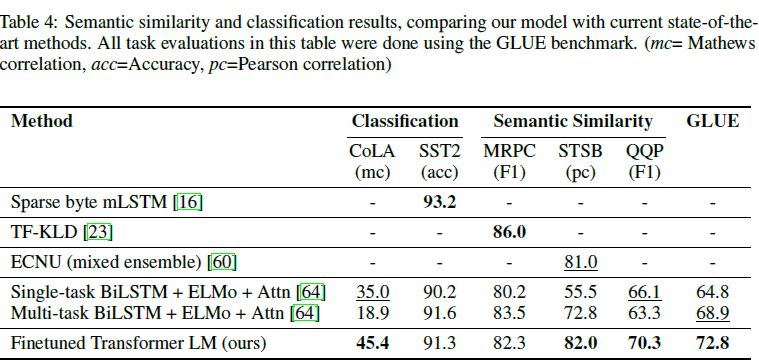
Semantic similarity (or paraphrase detection) tasks involve predicting whether two sentences are semantically equivalent or not. The challenges lie in recognizing rephrasing of concepts, understanding negation, and handling syntactic ambiguity. We use three datasets for this task – the Microsoft Paraphrase corpus (MRPC) [14] (collected from news sources), the Quora Question Pairs (QQP) dataset [9], and the Semantic Textual Similarity benchmark (STS-B) [6]. We obtain state-of-the-art results on two of the three semantic similarity tasks (Table 4) with a 1 point absolute gain on STS-B. The performance delta on QQP is significant, with a 4.2% absolute improvement over Single-task BiLSTM + ELMo + Attn.
의미 유사도(또는 패러프레이징 탐색)은 두 문장이 의미적으로 얼마나 동등한지 예측하는 문제이다. 이 문제는 개념을 다시 바꾸어 말하는 것인데, 부정을 이해하고 의미의 모호함을 다룬다. 우리는 이 문제를 위해 세 개의 데이터셋을 이용한다. Microsoft Paraphrase, Quora Question Pairs(QQP), 그리고 Semantic Textual Similiarity benchmark이다. 우리는 이 중 2개에서 SOTA를 달성했다.
Classification
Finally, we also evaluate on two different text classification tasks. The Corpus of Linguistic Acceptability (CoLA) [65] contains expert judgements on whether a sentence is grammatical or not, and tests the innate linguistic bias of trained models. The Stanford Sentiment Treebank (SST-2) [54], on the other hand, is a standard binary classification task. Our model obtains an score of 45.4 on CoLA, which is an especially big jump over the previous best result of 35.0, showcasing the innate linguistic bias learned by our model. The model also achieves 91.3% accuracy on SST-2, which is competitive with the state-of-the-art results. We also achieve an overall score of 72.8 on the GLUE benchmark, which is significantly better than the previous best of 68.9.
마지막으로 우리는 텍스트 분류 문제를 평가한다. CoLA의 말뭉치는 문장이 문법적인지 expert judgements를 포함하고, 훈련된 모델에 고유한 언어 편향을 테스트한다. SST-2는 반면에 표준 binary classification task이다. 우리의 모델은 CoLA에서 45.4의 점수를 받았는데 이는 이전의 가장 좋은 결과인 35.0보다 뛰어넘은 결과이다. 이 모델은 SST-2에서 91.3%의 결과를 보여줬고 마찬가지로 SOTA result이다. 우리는 GLUE benchmark에서 72.8의 종합 점수를 성취했고 이는 기존의 68.9보다 높은 점수이다.
Overall, our approach achieves new state-of-the-art results in 9 out of the 12 datasets we evaluate on, outperforming ensembles in many cases. Our results also indicate that our approach works well
across datasets of different sizes, from smaller datasets such as STS-B (5.7k training examples) – to the largest one – SNLI (550k training examples).
종합적으로, 우리의 접근은 12개의 데이터셋 중에서 9개의 SOTA를 보였다. 우리의 결과는 우리의 접근이 다른 사이즈, 작은 데이터셋부터 큰 데이터셋까지 좋은 결과를 보여주었다.
5. Analysis
Impact of number of layers transferred
We observed the impact of transferring a variable number of layers from unsupervised pre-training to the supervised target task. Figure 2(left) illustrates the performance of our approach on MultiNLI and RACE as a function of the number of layers transferred. We observe the standard result that transferring embeddings improves performance and that each transformer layer provides further benefits up to 9% for full transfer on MultiNLI. This indicates that each layer in the pre-trained model contains useful functionality for solving target tasks.
우리는 비지도 사전 훈련에서 지도 target task로 갈 때 레이어의 개수에 따른 전이의 영향을 관찰했다. Figure 2는 전이된 레이어의 개수의 기능으로써 MultiNLI 과 RACE에서 우리의 접근의 성능을 나타낸다. 우리는 transferring embeddings이 성능을 향상시키고, (의역) MultiNLI에서 트랜스포머 레이어의 개수가 12개가 됐을 때 최대 9%의 향상을 보여준다. 이는 사전 훈련된 모델에서 각각의 레이어가 target task를 해결하는데 유효한 기능을 수행함을 가리킨다.
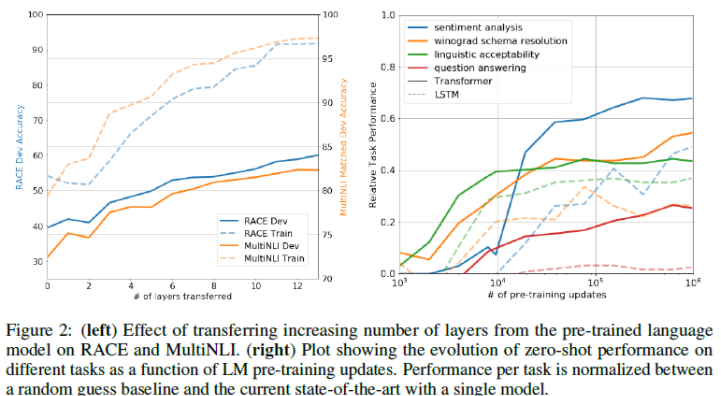
- 오른쪽은 zero-shot behavior에 대한 그래프입니다.
Zero-shot Behaviors
We’d like to better understand why language model pre-training of transformers is effective. A hypothesis is that the underlying generative model learns to perform many of the tasks we evaluate on in order to improve its language modeling capability and that the more structured attentional memory of the transformer assists in transfer compared to LSTMs. We designed a series of heuristic solutions that use the underlying generative model to perform tasks without supervised finetuning. We visualize the effectiveness of these heuristic solutions over the course of generative pre-training in Fig 2(right).
왜 언어 모델을 사전 훈련 하는 것이 효과적인지 이해하고자 한다. 가설은 다음과 같다. 먼저 근원적인 생성 모델은 우리가 수행하려고 하는 많은 문제를 수행하고자 학습시켜, 언어 모델링의 수용력을 향상시켰다. 또한 LSTM에 비해 전이 하는데 있어 트랜스포머의 structured attentional memory가 도움을 준다는 것이다. 우리는 fine-tuning없이 문제를 해결하는 근원적인 생성 모델을 사용하여 경험적인 해결을 디자인하였다. Fig2의 오른쪽의 generative pre-training 과정에 걸쳐 경험적인 솔루션의 효율성을 제공한다.
We observe the performance of these heuristics is stable and steadily increases over training suggesting that generative pretraining supports the learning of a wide variety of task relevant functionality. We also observe the LSTM exhibits higher variance in its zero-shot performance suggesting that the inductive bias of the Transformer architecture assists in transfer.
우리는 훈련 과정을 거칠수록 성능이 안정적이고 꾸준히 증가함을 관찰한다. 이는 생성 사전 훈련이 다양한 task 관련 기능의 학습을 지지함을 암시한다. 또한 우리는 LSTM이 zero-shot 성능에서 높은 분산을 보여주는데 이는 트랜스포머의 inductive bias가 전이에 도움을 줌을 암시한다.
- inductive bias : 학습 모델이 만나지 못한 상황에 대해 대처하기 위해 추가적인 가정을 도입하는 것을 의미합니다. 예를 들어 CNN의 경우 locality에 대한 가정이 추가됩니다. entities 간의 Relation이 지역성, 즉 서로 가까운(Proximity) Element 간에만 존재한다고 가정하는 것으로 볼 수 있으며, 결과적으로 어떤 특성을 가지는 Element들이 서로 뭉쳐있는지 중요한 경우에 탁월한 구조가 됩니다. 마찬가지로 RNN에서도 시계열 데이터에서 더 좋은 성능을 보여준다는 것을 가정하게 됩니다. 이 모두 inductive bias입니다. 반면, 트랜스포머의 경우 전체 데이터를 한번에 사용하므로 추가적인 가정을 세울 수 없다, 즉 inductive bias가 부족하다는 것입니다. 그래서 Robust하게 동작할 수 있지만 많은 양의 데이터가 필요하다는 것입니다. (https://velog.io/@euisuk-chung/Inductive-Bias란, https://robot-vision-develop-story.tistory.com/29, https://enfow.github.io/paper-review/graph-neural-network/2021/01/11/relational_inductive_biases_deep_learning_and_graph_netowrks/)
<< RNN과 CNN의 inductive bias가 transformer보다 크다는 것인데, 왜 transformer의 inductive bias가 전이에 도움이 되는지? >>
For CoLA (linguistic acceptability), examples are scored as the average token log-probability the generative model assigns and predictions are made by thresholding. For SST-2 (sentiment analysis), we append the token very to each example and restrict the language model’s output distribution to only the words positive and negative and guess the token it assigns higher probability to as the prediction. For RACE (question answering), we pick the answer the generative model assigns the highest average token log-probability when conditioned on the document and question. For DPRD [46] (winograd schemas), we replace the definite pronoun with the two possible referrents and predict the resolution that the generative model assigns higher average token log-probability to the rest of the sequence after the substitution.
CoLA(text classification task에서 사용된 데이터셋)에서 예제는 생성 모델이 할당하고 임계값에 의해 예측되는 평균 토큰 로그 확률로 채점된다. SST-2는 토큰을 예시에 더하고, 모델의 결과 분포를 단어의 긍정과 부정으로만 제한하고, 예측으로 더 높은 확률을 할당한 토큰을 추측한다. For RACE에선 조건이 주어졌을 때 생성 모델이 가장 높은 로그 확률을 부여한 토큰으로 할당한 정답을 고른다. DPRD에선, 우리는 정관사를 두 개의 가능한 referrents(one that refers or is referred to especially)로 교체하고 생성 모델이 대체 후 시퀀스의 나머지에서 더 높은 로그 확률을 보여주는 토큰에 할당한 해상도를 예측한다.
Ablation studies
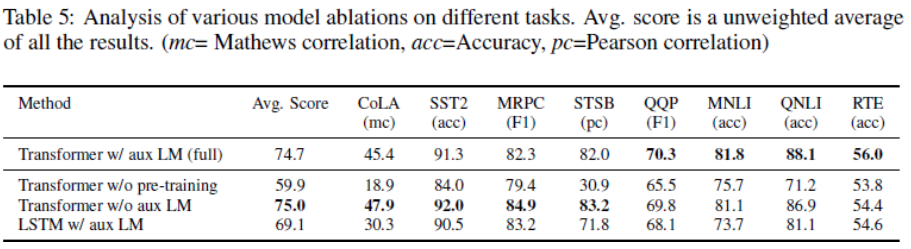
We perform three different ablation studies (Table 5). First, we examine the performance of our method without the auxiliary LM objective during fine-tuning. We observe that the auxiliary objective helps on the NLI tasks and QQP. Overall, the trend suggests that larger datasets benefit from the auxiliary objective but smaller datasets do not. Second, we analyze the effect of the Transformer by comparing it with a single layer 2048 unit LSTM using the same framework. We observe a 5.6 average score drop when using the LSTM instead of the Transformer. The LSTM only outperforms the Transformer on one dataset – MRPC. Finally, we also compare with our transformer architecture directly trained on supervised target tasks, without pre-training. We observe that the lack of pre-training hurts performance across all the tasks, resulting in a 14.8% decrease compared to our full model.
우리는 3개의 ablation studies를 수행했다. 먼저 fine-tuning 과정에서 보조적인 언어 모델 목표 없이 우리의 과제를 수행했을 때를 조사한다. 우리는 보조 목표가 자연어 추론과 QQP(의미 유사도에서 사용된 데이터셋)에 도움이 됨을 관찰한다. 종합적으로 큰 데이터셋은 보조 목표에서 도움이 되지만 작은 데이터셋에서 도움이 되지 않음을 보여준다. 두 번째, 우리는 2048개의 유닛을 가진 싱글 레이어 LSTM을 트랜스포머와 비교하여 트랜스포머의 효과를 분석한다. 우리는 트랜스포머 대신에 LSTM을 사용했을 때 5.6점의 점수 하락을 관측했다. LSTM만 사용하면 MRPC에선 트랜스포머보다 성능이 뛰어났다. 또한 우리의 트랜스포머와 사전 훈련 없이 지도 target task로 훈련된 트랜스포머 아키텍쳐를 비교하였다. 그 결과 사전 훈련의 부족이 전체 task에서 성능을 하락시킴을 관측한다. 이 하락은 전체 우리의 모델에 비해 약 14.8% 감소하였다.
- Ablation studies : machine learning system의 building blocks을 제거해서 전체 성능에 미치는 효과에 대한 통찰력을 얻기 위한 과학적 실험입니다. 예를 들어, 모델에서 n개의 레이어가 있을 때 n-1번째 레이어를 삭제하며 나타나는 변화를 관측합니다.(https://cumulu-s.tistory.com/8)
6. Conclusion
We introduced a framework for achieving strong natural language understanding with a single task-agnostic model through generative pre-training and discriminative fine-tuning. By pre-training on a diverse corpus with long stretches of contiguous text our model acquires significant world knowledge and ability to process long-range dependencies which are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification, improving the state of the art on 9 of the 12 datasets we study. Using unsupervised (pre-)training to boost performance on discriminative tasks has long been an important goal of Machine Learning research. Our work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach. We hope that this will help enable new research into unsupervised learning, for both natural language understanding and other domains, further improving our understanding of how and when unsupervised learning works.
우리는 생성 사전 훈련 및 차별적인 fine-tuning을 활용한 목적-불가지적인(목적과 관계없이 활용가능한) 모델을 이용하여 강력한 자연어 이해가 가능한 프레임워크를 도입했다. 긴 길이의 인접한 텍스트의 말뭉치로 사전훈련하여, 우리의 모델은 상당한 지식을 습득하였고 QA, 의미 유사성, 수반 결정, 텍스트 분류를 해결할 수 있도록 성공적으로 전이 되었다. 이를 통해 장기간 의존성을 처리할 수 있는 능력을 획득 하였고, 그 결과 12개의 데이터셋 중 9개에서 SOTA를 얻었다. 개별 목표에 대한 성능을 향상시키기 위해 비지도 사전 훈련을 진행하는 것은 머신 러닝 연구에서 주요 목표였다. 우리의 결과물은 다음을 제시한다. 상당한 성능 획득이 가능하고, 모델에 관한 힌트와 데이터셋이 우리의 접근에 도움이 된다. 우리의 연구가 자연어 이해과 다른 도메인에서 비지도 학습에 새로운 연구가 가능하도록 해줄 것이고, 넘어서 어떻게, 언제 비지도 학습이 가능한지에 대한 이해를 발전시킬 것이다.
