XLNet: Generalized Autoregressive Pretraining for Language Understanding(by 안재혁)
paper reading

- factorize 또는 factorization order를 인수 분해라고 해석했는데, 오류일 경우 이 부분을 감안하여 봐주시길 바랍니다.
Extra. Transformer-XL
XLNet은 Transformer-XL의 후속 모델이기 때문에, transformer-XL이 가진 고유한 특징을 이해해야 XLNet을 보다 쉽게 이해할 수 있습니다.
https://www.youtube.com/watch?v=lSTljZy8ag4
다음의 영상을 참고하여 작성했습니다.
- attention is not recurrenet, is can only deal with fixed-length context.
만약 고정된 길이보다 더 큰 길이의 context가 들어오게 되면, 작은 단위로 나누거나 seqeunce의 뒷 부분을 무시하기 위해 짤라서 사용되어야 한다.
- Context fragmentation: if context is long, it should be split up to segments.
언어 모델에서 큰 데이터셋으로 학습할 때, 한번에 속해 있는 모든 토큰들을 넣을 수 없다. 따라서 더 작은 단위로 sequence로 쪼개서 사용하게 된다. 이로 인해 한 segment의 정보가 다른 segment의 정보로 활용될 수 없다는 점이다. 사람과 다르게 각 segment를 독립적으로 사용될 수 밖에 없다는 것이다.
1,2 번이라는 transformer의 단점을 해결하기 위해선, 긴 길이의 context를 사용하고 이전 sequence의 문맥 정보를 활용할 수 있어야 한다.
Transformer-XL에선 트랜스포머를 활용하되, 1. Segment-level의 Recurrence를 활용하고, 2. Relative Positional Embedding을 활용하였다.
Segment-level Recurrence
Transformer-XL에선 하나의 Segment를 활용하여, 새로운 segment에 대한 모든 예측값을 한번에 사용한다.
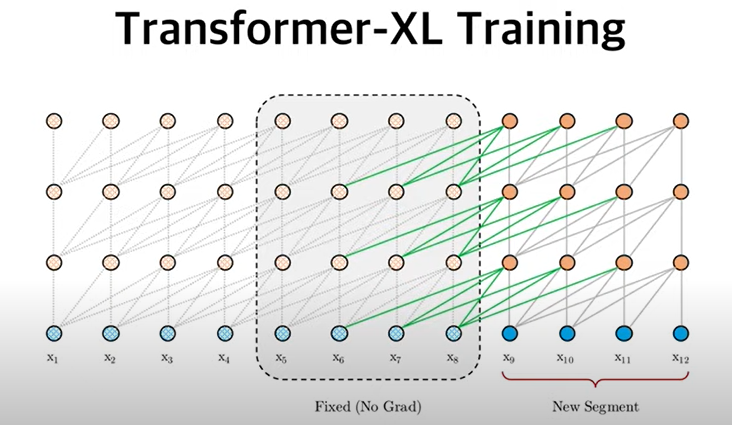
이전의 semgent에 대한 파라미터 값을 일종의 cache로 사용한다. 메모리 공간이 충분히 크다면 이 정보를 충분히 활용할 수 있을 것이고, 다음 예측값은 기존의 문맥 정보를 활용하기 때문에 더 높은 성능을 보장받을 수 있다.
만약 메모리가 더 크다면 n-1이 아닌, n-4, n-3, n-2, n-1에 대한 정보를 concatenate하여 활용할 수 있을 것이다.
Relative Positional Embedding
단, 이 때 positional embedding에서 문제가 발생한다. 여러 segment에 대한 정보를 넣어준다는 것은 각각의 segment에 대해서 정보가 겹쳐진다는 것이다. 3개의 토큰에 대해서 3개의 0번 째 토큰이 있을 것인데, 이 토큰들이 겹쳐질 것이다.
이를 해결하기 위해 Transformer-XL에선 절대적인 위치가 아니라 query vector, key vector에 대한 상대적인 위치를 계산하여 이를 position으로 정의한다. 그 다음에는 기존의 Transformer에서 positional sinusoid하게 바꿔서 -1~1 값으로 변경한다.
Prediction
During evaluation, vanilla model consumes a segment to make only one prediction at the last position, which is extremely expensive.
Transformer-XL uses representation(memory) from previous segments instead of computing from scratch.
Transformer-XL은 이전 segment의 값들을 segment로 재활용한다는 장점이 있기 때문에 한번 계산할 때, 하나의 token 값에 대한 결과a가 아니라 한 segment에 대한 결과값을 도출시킬 수 있다.
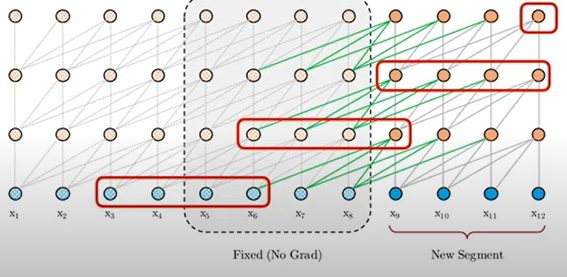
마지막 빨간색을 계산하기 위해 이전 segment에 대한 정보를 계산하는 것이 아니라, 사용했던 segment의 hidden state를 불러오는 과정이다. 따라서 scratch에서보다 계산 과정이 빠르게 된다.
>> current segment에 대한 계산 과정이 있는 것은 동일하지만, 한번 계산에 하나의 token에 대한 결과를 내는 것이 아니라 한 segment에 대한 결과를 내는 것이 가장 큰 차이이다.
0. Abstract
다 쓴 다음에 맨 마지막에 요약하는 것도 한 가지 방법이다. 일부 컨퍼런스의 경우 Abstract를 먼저 쓰고 일주일 뒤 본문을 내기도 한다. 한 문장으로 autoencoding과 autoregressive에 대한 내용을 요약하고, 동시에 논문 작성시 화두였던 BERT에 대한 내용도 언급하고 있다.
그 뒤에 “However”이 나와서 BERT에 대해서 부정적으로 표현한다.(corrupting) [MASK]에 대해 부정적으로 표현한다.(discrepency) [MASK] 사이에서도 dependency가 있는데, 서로 독립적이라고 가정하기 때문에 상관관계를 무시한다. 또한, fine-tuning할 때 [MASK]를 사용하지 않으므로 사전 훈련과 파인 튜닝 간의 불일치가 발생한다는 것이다.
이에 XLNet를 제안한다. 이 모델 이름이 쌩뚱맞기 때문에 자세하게 설명하고 있다. XLNet은 autoregressive한 pre-tranining modeling으로, (1)maximizing the expected likelihhod over all permutations of the factorization order. 여기서 키워드는 permutation(순열)으로 factorization order로 기존의 단점을 극복했다는 것을 밝히고 있다. (2) BERT는 autoencoding method인데, AE 방법의 단점을 AR의 접근으로 극복하고 있음을 알리고 있다.
또한, Transformer-XL이라는 autoregressive model을 차용했다. 이는 기존의 sota였던 AR model인데, 이를 pretraining 과정에서 사용했다.
좋은 얘기를 했으면 마지막에 한 문장으로 정리해줘야 한다. (자랑) 다양한 실험 환경에서 BERT를 단순하게 이기는 것이 아니라 20개의 task에서 outperforming해주고 있다.
여기서 margin이라는 말은 기존의 격차보다 큰 차이가 있을 때만 쓸 수 있는 단어이다. 표 3.2에서 보면 가장 성능이 좋은 곳에 bold를 함으로써 한 눈에 볼 수 있게 한다. 마지막에 풋노트를 추가하여 코드를 남기기도 한다. 데이비드 블라이(https://ko.wikipedia.org/wiki/데이비드_블라이)은 글을 유려하게 잘 쓰는데, 이 사람은 Abstract 마지막에 링크를 추가한다. (따라하는 것은 표절이 아니다.)
1. Introduction
Unsupervised representation learning has been highly successful in the domain of natural language processing [7, 22, 27, 28, 10]. Typically, these methods first pretrain neural networks on large-scale
unlabeled text corpora, and then finetune the models or representations on downstream tasks. Under this shared high-level idea, different unsupervised pretraining objectives have been explored in
literature. Among them, autoregressive (AR) language modeling and autoencoding (AE) have been the two most successful pretraining objectives.
비지도 학습 표현은 자연어 처리 분야에서 매우 성공적이었다. 일반적으로, large-scale의 비지도 text corpora를 이용하여 신경망을 사전 훈련하고, 이후 downstream task에 맞게 모델이나 파라미터를 파인튜닝한다. high-level의 방식 하에, 다른 비지도 사전 훈련 목표들에 사용된다. 이 중에서, autoregressive(AR) 언어 모델링과 autoencoding(AE) 언어 모델링 방식이 성공적인 사전 훈련 방식이다.
AR language modeling seeks to estimate the probability distribution of a text corpus with an autoregressive model [7, 27, 28]. Specifically, given a text sequence x = (x1, · · · , xT ), AR language modeling factorizes the likelihood into a forward product p(x) = QT t=1 p(xt | x<t) or a backward one p(x) = Q1 t=T p(xt | x>t). A parametric model (e.g. a neural network) is trained to model each conditional distribution. Since an AR language model is only trained to encode a uni-directional context (either forward or backward), it is not effective at modeling deep bidirectional contexts. On the contrary, downstream language understanding tasks often require bidirectional context information. This results in a gap between AR language modeling and effective pretraining.
AR 언어 모델링은 autoregressive model을 이용하여 text corpus의 확률 분포를 추정하는 방법이다. 특히, 주어진 text 문장에서 AR 언어 모델링은 순전파와 역전파로 확률을 factorizing한다.. 파라미터 모델은 각 지도 분포를 모델링하기 위해 훈련된ㄷ. AR 언어 모델링은 단방향 context를 인코딩하여 훈련하기 때문에, 깊은 양방향 contexts에서 효과적이지 못하다. 반면, downstream language understading task는 양방향 context 정보를 요구하므로 이는 AR 언어 모델링과 효과적인 사전 훈련에서의 차이를 발생시킨다.
In comparison, AE based pretraining does not perform explicit density estimation but instead aims to reconstruct the original data from corrupted input. A notable example is BERT [10], which has been the state-of-the-art pretraining approach. Given the input token sequence, a certain portion of tokens are replaced by a special symbol [MASK], and the model is trained to recover the original tokens from the corrupted version. Since density estimation is not part of the objective, BERT is allowed to utilize bidirectional contexts for reconstruction. As an immediate benefit, this closes the aforementioned bidirectional information gap in AR language modeling, leading to improved performance. However, the artificial symbols like [MASK] used by BERT during pretraining are absent from real data at finetuning time, resulting in a pretrain-finetune discrepancy. Moreover, since the predicted tokens are masked in the input, BERT is not able to model the joint probability using the product rule as in AR language modeling. In other words, BERT assumes the predicted tokens are independent of each other given the unmasked tokens, which is oversimplified as high-order, long-range dependency is prevalent in natural language [9].
대조적으로 AE 기반 사전 훈련은 density 추정을 수행하지 않고, 붕괴된 input(corrupted input)으로부터 오리지널 데이터를 복원하는 것을 목표로 한다. 대표적인 예시는 BERT로 현재 SOTA를 보여주는 사전 훈련 방식이다. 주어진 input token sequence에서 특별한 symbol인 [MASK]로 token의 일부분이 변경되고, 이 모델은 corrputed version에서 original token을 알아내기 위해 훈련된다. density estimation은 목표의 일부분은 아니지만, BERT는 복원을 위해 양방향 context를 활용한다. 즉각적인 이득으로 이는 앞서 AR 언어 모델링에서 보여주는 양방향 information gap을 줄여줘서 더 높은 향상을 이끌어낸다. 하지만, BERT에서 사전 훈련 동안 사용되는 [MASK]라는 특별한 심볼은 파인튜닝에는 존재하지 않는다. 이는 사전 훈련-파인 튜닝 간의 불일치를 만든다. 더욱이 예측되는 token은 input에서 가려지는데, BERT는 AR 언어 모델링에서 처럼 결과물을 이용하여 joint probability를 모델링할 수 없다. 즉, BERT는 마스크되지 않은 토큰이 주어졌을 때 예측되는 토큰은 다른 토큰과 독립적이라고 가정하며, 이는 high-order, long-range 의존성이 자연어에서 만연함에 따라 지나치게 단순화 된다.(무시하는 경향이 짙어진다.)
Faced with the pros and cons of existing language pretraining objectives, in this work, we propose XLNet, a generalized autoregressive method that leverages the best of both AR language modeling and AE while avoiding their limitations.
- Firstly, instead of using a fixed forward or backward factorization order as in conventional AR models, XLNet maximizes the expected log likelihood of a sequence w.r.t. all possible permutations of the factorization order. Thanks to the permutation operation, the context for each position can consist of tokens from both left and right. In expectation, each position learns to utilize contextual information from all positions, i.e., capturing bidirectional context.
- Secondly, as a generalized AR language model, XLNet does not rely on data corruption. Hence, XLNet does not suffer from the pretrain-finetune discrepancy that BERT is subject to. Meanwhile, the autoregressive objective also provides a natural way to use the product rule for factorizing the joint probability of the predicted tokens, eliminating the independence assumption made in BERT.
현존하는 언어 모델링의 찬반양론에 대해, 이번 논문에선 우리는 XLNet을 제안한다. XLNet은 일반화된 AR 방법이지만 AR의 장점과 AE의 장점만을 사용하여 그들의 한계를 회피한다.
- 첫 째, 전통적인 AR 모델링에서처럼 고정된 순전파 또는 역전파 인수분해 차수를 사용하는 것 대신에, XLNet은 인수 분해 차수의 모든 가능한 순열을 이용하여 예측된 log likelihood을 극대화한다. 순열 방법 덕분에, 각 포지션의 context은 양방향에서의 token으로 구성된다. 예측 과정에서 각 포지션은 모든 포지션으로부터 contextual information을 활용하기 위하여 학습되고, 결국 양방향 context에 대한 정보를 습득한다.
- 둘 째, 일반적인 AR 언어 모델링처럼, XLNet은 data corruption에 의존하지 않는다. 그러므로, XLNet은 BERT의 취약점인 사전 훈련-파인 튜닝의 불일치라는 단점을 겪지 않게 된다. autoregressive objective는 또한 product rule을 사용하는 자연적인 방법을 제공하는데, 예측된 토큰의 joint probability를 인수분해한다. 이를 통해 BERT에서 만들어진 독립 가정을 제거한다.
product rule : 곱셈 규칙
In addition to a novel pretraining objective, XLNet improves architectural designs for pretraining.
- Inspired by the latest advancements in AR language modeling, XLNet integrates the segment recurrence mechanism and relative encoding scheme of Transformer-XL [9] into pretraining, which empirically improves the performance especially for tasks involving a longer text sequence.
- Naively applying a Transformer(-XL) architecture to permutation-based language modeling does not work because the factorization order is arbitrary and the target is ambiguous. As a solution, we propose to reparameterize the Transformer(-XL) network to remove the ambiguity.
Empirically, under comparable experiment setting, XLNet consistently outperforms BERT [10] on a wide spectrum of problems including GLUE language understanding tasks, reading comprehension tasks like SQuAD and RACE, text classification tasks such as Yelp and IMDB, and the ClueWeb09-B document ranking task.
새로운 사전훈련 목표에 더하여, XLNet은 사전 훈련을 위한 구조적 디자인도 증진시킨다.
- AR 언어 모델링에의 최근 발전에 영감을 받았다. XLNet은 segment recurrence mechnasism과 Transformer-XL의 인코딩 방법을 사전 훈련 방법에 통합시켜서 킨 text 문장을 포함하는 task에서 성능 향상을 제안한다.
- 단순하게 Transformer(-XL)을 순열 기반 언어 모델링에 적용하는 것은 동작하지 않는다. 왜냐하면 인수분해 차수는 랜덤이고, target은 모호하기 때문이다. 이에 대한 해결방법으로, 우리는 모호함을 없애기 위해 Transformer(-XL)의 파라미터를 다시 만든다.
실증적으로, 비교가능한 실험 세팅 아래에서, XLNet은 BERT보다 높은 성능을 지속적으로 보여주었는데, GLUE language understanding task, SQuAD, RACE와 같은 reading comprehension task, 텍스트 분류, document ranking task등의 포함한 넓은 영억의 task에서 동작한다.
일반적으로 pretraninig할 때 large unlabeled data를 이용하고, downstream task를 위해 fine-tuning한다. 이러한 high-level은 같지만, 여기서 “in lierature” 라는 분야에서 연구가 되어왔다.
언어 모델링을 objectives하는데 있어서 두 가지의 방식인 AE와 AR이 있다. 여기서 objective라는 말을 단순히 “목표”라는 뜻으로 해석하기는 어렵다. 포괄적으로 해석해야 하며, 앞으로 나아가면서 무언가를 이룬다는 개념으로 봐야한다. 그래서 objective function이라면 주어진 모델에 대해서 모델을 만들기 위한 function으로 해석하게 된다. 단순히 목표 함수라고 해석하기에는 말이 맞지 않는다.
vector에 bold 체로 하여 scalar와 vector를 구별한다.
AR은 순전파 방향으로 factorize likelihood(분해한다). ~ to model each conditional distribution. : neural network modeling하는데 있어서 지도 데이터로 학습한다. AR 언어 모델링은 단방향으로 학습한다. forward는 forward대로 학습하고, backward는 backward만으로 학습한다는 뜻이다. 이는 bidirectional context를 학습하기에는 효과적이지 않다. 문제는 fine-tuning과정에선 양방향 정보가 필요하다는 것이다. 그래서 단방향으로 학습하는데 양방향 정보가 필요하다는 gap이 발생하는 결과를 낳게 된다.
In comparison으로 AE model에 대해 설명하고 있다. AR의 probability distribution과 AE의 density estimation에 대한 차이가 무엇인가? >> 크게 차이가 있다기 보단 용어의 차이로 보는 것이 편하긴 하다.
논문을 제대로 이해하기 위해선 논문 내의 citation도 보는 것이 중요하다.
has been the state-of-the-art pretraining apporach: 지금은 SOTA가 아니라는 뜻이다.
BERT에 대한 설명을 Abstract에서 설명하였다. (1), (2) [MASK]에 대해서 관계를 무시한다는 것이다. [MASK]가 연속되어 있다면 두 단어 간에 관계가 분명히 있다는 것인데, 이를 무시한다는 것이다. [MASK]를 억지로 만들었다는 뉘앙스로 설명한다.(훈련하기 위해서 억지로 만들었다.) AR의 경우 앞서 연관된 결과를 chain rule을 이용해 뒤의 확률을 계산하는데(joint probability), BERT는 이를 이용할 수 없다는 것이다. 단점을 설명해줘야 내가 만드는 모델에 당위성이 부여된다. 단, 이렇게 표현하기 위해서 내 모델에 대한 자신감이 있어야 한다.
simplified는 좋은 것이다. 단순하게 하여 성능을 높이는 것은 한 가지 방법이지만, 그 방법이 oversimplified되었다는 것이다. 자연어에서 high-order, long-range dependency를 단순화 시킨다고 언급한다.
즉, 현존하는 AR과 AE에 대하여 장단점이 있음을 정리하고 있다. 따라서 AR과 AE의 장점 만을 합한(avoiding their limitations, 단점을 극복한) 새로운 모델인 XLNet을 알린다. 더하여, XLNet은 사전 훈련에 부수적인 장점 두 개를 추가하였다.
먼저, 기존의 AR 모델의 경우 순방향 또는 역방향으로 고정하여 진행했는데, 이 대신에 all possible permutation of the factorization order을 이용하였다. 이를 통해 모든 방향에서 정보를 해석할 수 있게 된다.
저자는 BERT에서 reconstruction을 이용하는 것을 단점으로 여겼고, AR은 data corruption을 이용하지 않는 것을 장점으로 꼽았다. 즉, BERT가 가질 수 밖에 없는 discrepency에 대한 단점을 AR은 가지지 않는다는 것이다. 저자는 product를 chain rule하여 얻음으로써 독립적이라는 BERT의 단점을 해결하였다. 제일 중요한 것은 BERT의 두 개의 주요 단점을 극복했다는 것이다.
2. Paper Review
대부분의 Task에서 SOTA를 달성한 BERT를 몰아낸 것이, XLNet이다. QA Task에서 XLNet은 높은 위치를 보여준다. XLNet은 introduction에서 모델에 대한 설명 전에, AR과 AE에 대한 자세한 설명을 기록하였다. AR에서 높은 성능을 보여준 것이 GPT, ELMo이다. 이는 representation을 활용하는 방식이 조금 다른데, pretraining 방식을 사용하되 직접 활용하지 않는다. 반면, BERT는 pretraining 이후 fine-tuning 방식을 사용한다. GPT는 zero-shot learning을 목표로하는 모델이다. AR 모델들은 language model의 학습 방법을 사용해서, 이전 토큰을 이용하여 다음 토큰을 예측하는 방법이다.
vanilla AR model에서 확률을 조건부 확률의 곱으로 표현하고 있다. conditional distribution은 forward나 backward에 대한 조건부 확률이다. x_t보다 작은 값들이 주어졌을 때 다음 토큰을 예측하도록 되어 있다. 이전 토큰들로 다음 토큰들을 예측하기 때문에 문장에 대한 깊은 이해를 포함할 수 없다. → 이를 해결하기 위해 ELMo나 Autoencoding 방식을 이용해야 한다.
ELMo는 BiLSTM을 기반으로 만들어진 모델이다. Input token이 forward language model과 backward language model을 각각 학습하고, 이후에 linear를 concatenate하여 최종 학습을 진행한다. ELMo의 경우 양방향 문맥을 이용하여 context를 추출하지만, 왼쪽에서 오른쪽을 학습하고, 오른쪽에서 왼쪽을 학습하기 때문에 이 조차 깊은 이해를 하고 있지 않다고 볼 수 있다.
autoencoding의 경우 분포를 기반으로 추정하여 다음 task를 진행하는 것이 아니라, 모든 정보에 대해 학습한 것을 기존의 정보에서 가져온 것이다. autoencoding의 경우 [MASK]를 예측하는 것이기 때문에, [MASK]라는 noising을 없애는 denoising model이다. AE는 independency assumption을 하기 때문에 정답 간에 의존성이 있음에도 불구하고 없다고 가정한다.
XLNet’s Objective
요약하면 다음과 같다.
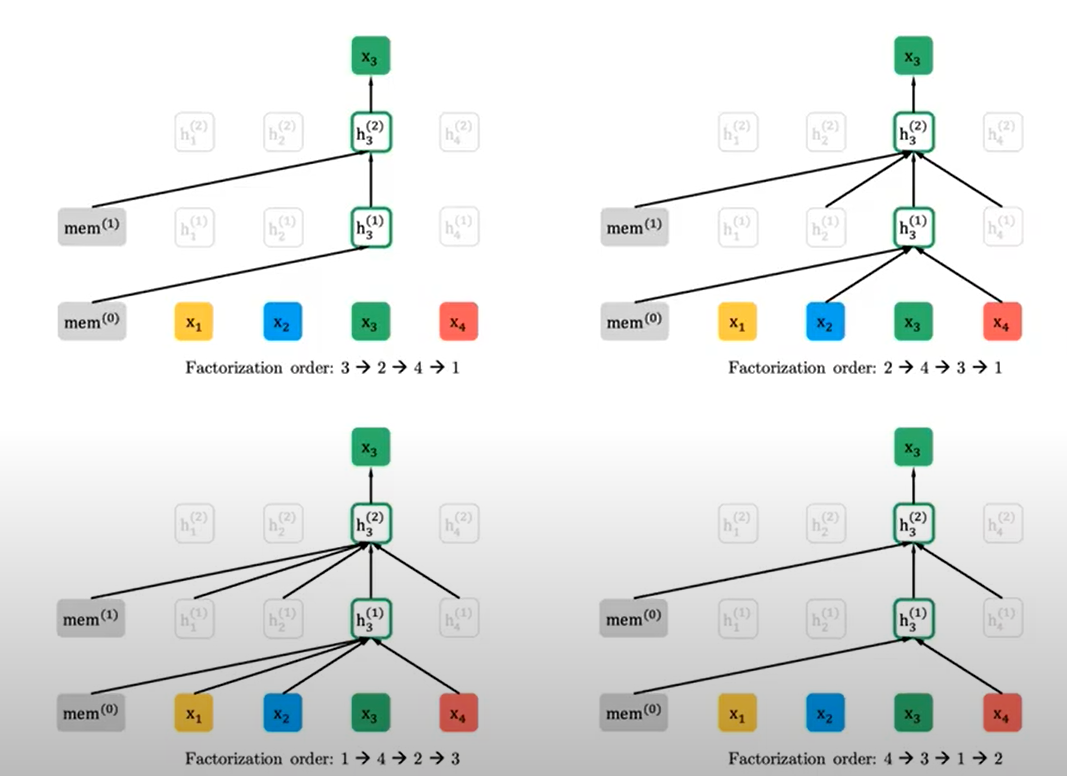
기존의 토큰이 [1,2,3,4]의 순서로 이루어질 때, permutation으로 각각 랜덤하게 위치가 바뀌었다고 생각한다.
- 왼쪽 위는 [3, 2, 4, 1] 순서로 AR modeling을 진행한다. AR modeling은 왼쪽에서 부터 예측을 진행하는데, 3이 맨 앞이므로 정보를 그대로 가져오는데 이 때 정보를 각 레이어의 의 정보를 가져온다. 이 때, 은 Transformer-XL에서 말한 이전 segment에 대한 정보를 의미한다.
- 오른쪽 위는 [2, 4, 3, 1] 순서 일 때, 3을 예측하는 과정이다. AR을 forwarding으로 예측할 때, 3을 예측하기 위해 2,4의 정보를 가져와야 한다. 뿐만 아니라 Transformer-XL의 방식도 사용하기 때문에 에 대한 정보도 추가로 가져온다.
- 왼쪽 아래는 [1,4,2,3]일 때 3을 예측한다. 3을 예측하기 위해 1,2,4의 정보와 의 정보를 가져온다.
- 오른쪽 아래는 [4,3,1,2]에서 3을 예측한다. 3번과 같은 방식으로 진행한다.
정리하면, Permutation language model은 [New, Work, is, a, city]가 주어졌을 때, 먼저 [is, a, city, New, York]으로 permutation을 진행한다. 이후, [is, a, city]를 이용하여 ‘New’를 예측하고, [is, a, city, New]를 이용하여 ‘York’를 예측한다.
기존의 방식을 개선하기 위해 3가지의 방식을 도입하였다.
- 첫 번째는 가 길이, 는 순열 들의 조합이다. 여기서 XLNet은 input sequence의 모든 경우의 수를 고려한 모델이기 때문이다. 단, 모든 순열을 고려하는 것은 waste of cost이기 때문에 전부 고려하지 않는다. 하지만, 훈련이 끝날 때 마다 파라미터가 공유되고 데이터의 길이가 많아지고 훈련이 계속 될수록 순열의 일부 조합이 결국 전체 순열의 조합으로 근사될 수 있음을 이용하는 것이다. 다음 토큰의 분포를 예측하기 위해, 기존의 AR에선 context의 시점이 고정되었다. 하지만, XLNet에선 순열로 인하여 시점이 변경된다. 단, 이 경우 고정이 되지 않아 예측 위치에 대한 정보가 필요하다.
GPT의 경우 단순하게 [x1, x2, x3, x4]를 이용하여 [x5]를 예측한다. 하지만, Permutation LM의 경우 [x2, x1, x4, x3]의 순서를 이용하는데, 다음에 오는 토큰이 [x5]인지, [x6]인지, [x7]인지 모델에선 알 수 없다는 점이다. 즉, 사전에 미리 입력할 수가 없다는 것이다. 이를 해결 하기 위해서 사용하는 방법이 Two-Stream Self Attention이다.
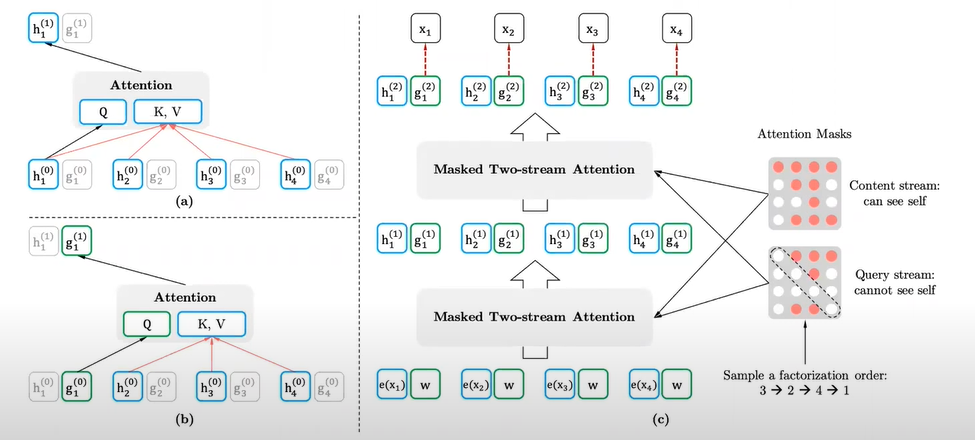
two stream은 Query Stream과 Content Stream이다.** content stream은 예측하고자 하는 token의 정보를 같이 사용한다. 예측할 때 예측하려는 정보를 사용하는 것은 모순적이다. 이를 해결하기 위해 query stream을 사용한다. Query stream은 전의 sequence 정보를 활용하되, 위치 토큰 embedding만을 활용해서 가져오는 것이다. query stream이 사용하는 은 random initialization에 위치 정보를 가지고 있는 vector이다.
즉, query stream을 이용하여 positional embedding을 추가하는 것이다. 가 기존에 사용되는 파라미터였다면, 는 positional embedding이 붙어있는 파라미터로 변경되었다. 가 context와 attention으로 정보를 획득하는데, 두 가지의 제약이 있다. 1. 시점 t에서 context 와 만으로 정보를 획득해야 한다. 2. 시점이 t+1일 때 g(t)이다.
여기서 은 시점 전체에 대한 x를 의미한다.
- 두 번째: 첫 번째 attention은 훈련이 안되므로 랜덤으로 초기화되고, 마지막 층을 이용하여 t 시점에 대한 context를 예측한다. context Representation은 vanilla에서 hidden state에서 transformer을 의미한다. 시점 t이후의 context를 masking하여 치팅을 방지해야 한다. (이후 시점으로 이전 시점을 예측하면 안되므로) Partial Prediction: 1→3→2라면 마지막 몇개 만을 사용하여 cost를 줄였다? —> 왜 좋은 지에 대한 설명이 논문에서 부족하다. (성능에 변함이 없기 때문에 사용한 듯)
- Transformer-XL에서 사용한 technique를 이용한다. Relative Positional Encoding: CNN이나 RNN에는 시점에 대한 직접적인 정보를 이용하지 않고, Transformer의 경우 절대적인 위치에 대한 정보를 추가하여 진행하였다. 하지만, relative positional encoding은 segment에서 위치에 대한 정보를 표현할 수 있지만, 순열이 여러개가 된다면 여러 g_t에 대해서 recurrent되는 단점이 있다. 예를 들어, i meet you로 학습되어야 할 정보가 i you meet로 학습되면 혼동을 줄 수 있다는 것이다. 절대적인 위치를 사용하는 것이 좋지만, 상대적인 위치를 이용함으로써 cost의 낭비를 막는다. 번째 segment에 대한 위치 정보를 번 째 segment 위치에 대한 정보를 같다고 취급하는 것이다. 하지만, 순열로 섞어 버렸는데 같다고 취급되버리면 문제가 되는 것이 아닌가? → 상대적인 정보만을 이용할 수 있는 모델을 이용하여 이를 해결한다. Segment Recurrence Mechanism: 이전 segment로 얻은 hidden state를 어떻게 활용할지에 대한 내용이다.
multiple segment에서 XLNet은 어떻게 학습시키는가 → BERT와 비슷하게, A segment [SEP] B Segment [CLS]를 이용한다. 이 때 두 문장을 랜덤으로 샘플링하고, 한 개의 문장으로 concat을 진행한다. 이후 다시 permutation을 수행한다. 결론적으로 비슷한 위치에 대한 학습 정보를 사용하는 것은 indcutive bias를 이용한다는 것인데 이를 통해 improving generalization을 얻는다.
위키피디아 데이터를 이용하여 500,000 에포크 동안 학습을 진행하였다. 문제는 underift이 발생하였는데 더 진행하더라도 정확도 향상에 도움이 안되었고, 모델의 크기를 더 크게 하면 downstream task에서 오히려 정확도가 떨어지는 결과를 낳게 된다.
