알고리즘이론
1.이진탐색트리BinarySearchTree

알고리즘 이론 공부 하면서 구현해봄
2.스택stack
알고리즘 이론 공부하면서 스택을 구현해봄
3.큐Queue
알고리즘 공부하면서 구현해본 큐
4.해시테이블Hashtable
자바로 해시테이블 구현해봄... c++ 로 구현해본지가 7년전이네;;중복된 해시나왔을때 해결방법은 구현하지 않았다
5.힙Heap
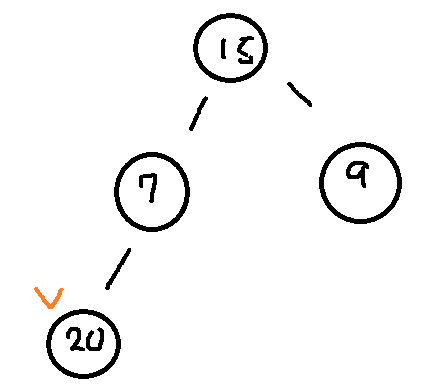
완전이진트리이다노드를 추가할때 최하단 왼쪽 노드부터 차례대로 추가한다최소값 최대값을 빠르게 찾기 위해 고안되었다우선순위큐(우선순위가 높은 데이터를 먼저 꺼내는 것)를 구현할때 활용된다공통점: 이진트리차이점\-힙은 각 노드의 값이 자식 노드보다 크거나 같음(Max Hea
6.공간복잡도
공간복잡도 Space Complexity알고리즘 수행에 필요한 저장공간의 양공간 복잡도 예제위의 반복문을 활용한 팩토리얼 함수에서는 int n, int fac, int idx 변수들이 사용됨n의 값이 변해도 추가로 더필요한 메모리가 없다. 따라서 공간복잡도는 항상 일정
7.버블정렬BubbleSort
8.선택정렬(Selection Sort)
배열이 있을때 배열을 순회하면서 가장 작은 값을 찾고 앞의 값과 스왑하는 방식. 가장 작은 값을 선택한다고 해서 선택정렬이라고 한다.
9.삽입 정렬(insertion sort)
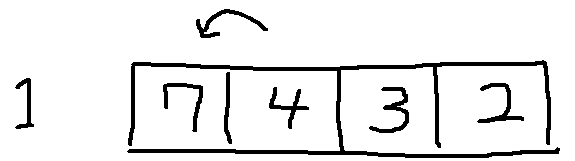
버블정렬을 거꾸로 하는거 같다..1회차 순회1번인덱스의 값을 0번인덱스와 비교후 1번이더 작으면 스왑 아니면 break;2회차 순회2번인덱스의 값을 1번인덱스와 비교후 2번이 더 작으면 스왑 아니면 break;1번인덱스의 값을 0번인덱스와 비교후 1번이더 작으면 스왑
10.동적 계획법(Dynamic Programming)과 분할 정복(Divide and Conquer)
동적계획법은 문제를 풀기위한 알고리즘이 아닌 전략이다동적계획법: 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘상향식 접근법으로, 가장 최하위 해답을 구한 후,
11.병합 정렬merge sort
https://visualgo.net/en/sorting재귀를 활용한 정렬 알고리즘리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다재귀함수
12.퀵정렬
https://visualgo.net/en/sorting기준점(pivot)을 정한다기준점보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 모은다.나뉘어진 왼쪽, 오른쪽은 다시 각각 기준점을 정하고 기준점보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 모은다비
13.이진탐색(BinarySearch)
14.그래프
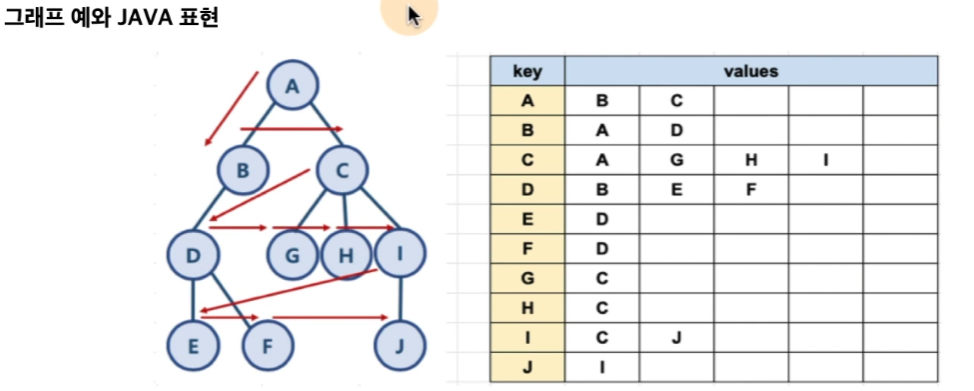
자바에서 그래프 표현 방법Hashmap 과 ArrayList 로 표현가능
15.탐욕알고리즘GreedyAlgorithm
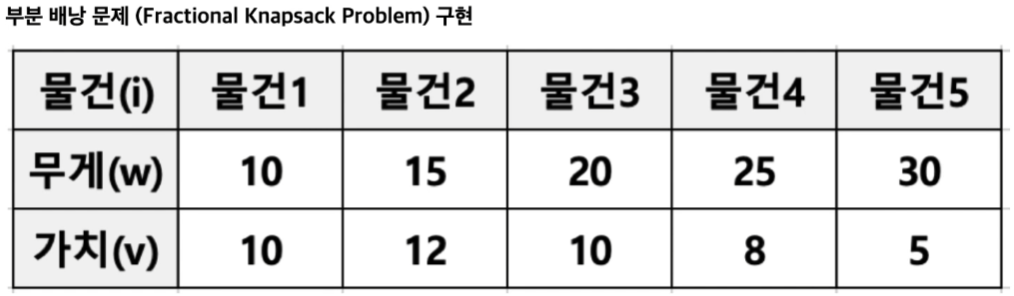
최적의 해에 가까운 값을 구하기 위해 사용됨여러 경우중 매순간 최적이라고 생각되는 경우를 선택하는 방식동전문제4720 원을 지불해야함1, 50, 100, 500 원짜리 동전을 사용함동전의 수가 가장 적게 지불하시오부분 배낭 문제9(Fractional Knapsack P
16.다익스트라
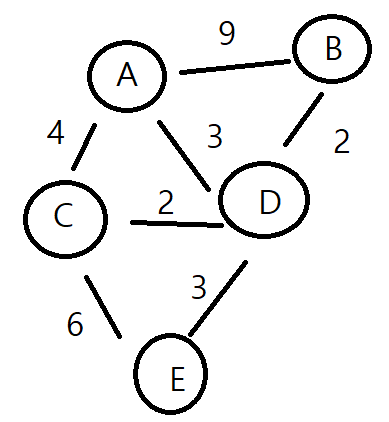
그래프가 있다버텍스(정점)와 엣지(간선)가 있고 엣지에는 가중치가 있다이때 특정 버텍스와 버텍스간에 엣지의 가중치 합이 최소가 되는 경로를 찾는 알고리즘이다.1단일출발 최단경로 문제특정 노드에서 출발하여 모든 다른 노드에 도착하는 가장 짧은 경로를 찾는 문제2단일 도착
17.신장트리
Spanning Tree, 또는 신장 트리라고 불리움그래프가 있다고 하자이 그래프의 연결을 끊어버려그리고 트리가 되도록 연결한다(사이클이 없이 모든 노드 연결되야함)경우의 수가 더 있을것이다. 어쨋든 이것을 신장트리라고 한다Minimum Spanning Tree, MS
18.프림 알고리즘 Prim's algorithm
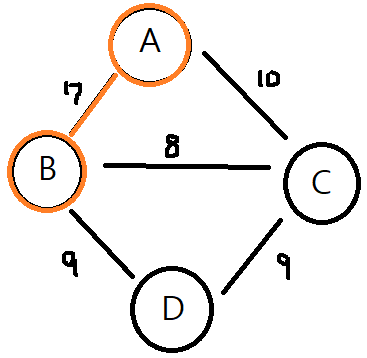
앞서 봤던 크루스칼알고리즘은 모든 엣지들을 최소부터 오름차순으로 정렬한다(기준은 엣지의 가중치) 그리고 최소가중치를 지닌 엣지부터 탐색을 시작하는 반면에 프림은 시작버텍스를(노드)선택하고 시작버텍스와 인접한 엣지중 최소(가중치)엣지를 선택하고 연결된 버텍스(노드)를 선
19.백트랙킹backtracking
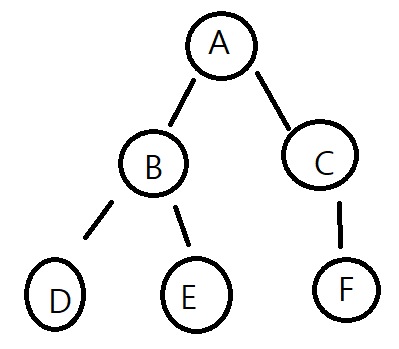
제약조건 만족 문제에서 해를 찾기 위한 전략해를 찾기 위해 후보군에 제약조건을 체크하고 실패한 대상은 체크하고 다른 후보 찾는다상태공간트리 사용해서 고려할 수 있는 경우의 수 표현DFS 방식으로 탐색뭔말을 이렇게 어렵게 설명하는지백트랙킹은 개념적으로 트리구조를 사용한다
20.삽입정렬에 관하여..chatgpt를 사용해봤다
삽입정렬 Insertion sort 에 대해 발표하려고 준비하다가 chatgpt 를 사용해보았다처음에 배열기반 삽입정렬이 링크드리스트 기반 삽입정렬보다 느릴거라고 생각하였다왜냐면 특정 원소를 뺄때 그 원소의 뒤에있는 원소들이 앞으로 땡겨지고삽일할때 그 원소뒤로 원소들이
21.자연수를 인자로 받아 소수 판별하는 함수
소수: 1보다 큰 자연수 중 1과 자기 자신만을 약수로 가지는 수인자로 9를 받았다면 2부터 \~~ 제곱근(9) 까지 loop 하면서 9를 나눈 나머지가 0이 아니면 소수이다즉 2, 3 으로만 나눠보고 나눠떨어지지 않으면 소수이다인자로 17을 받았다면 2,3,4 로만
22.Collections.sort()
TimSort 알고리즘을 사용합니다. TimSort는 안정적이며, 적응형 정렬 알고리즘입니다. 이 알고리즘은 최악의 경우 시간 복잡도가 O(N \* logN)이고, 이미 부분적으로 정렬된 입력에 대해서는 선형 시간에 가까운 성능을 보입니다.TimSort는 합병 정렬(M
23.정렬인터페이스
ComparableComparable은 객체 자체에 정렬 메커니즘이 포함되어 있어야 할 때 사용합니다.클래스가 Comparable 인터페이스를 구현하면, 그 클래스의 인스턴스들은 자연적인 순서로 정렬될 수 있습니다.compareTo 메서드를 오버라이드하여 구현합니다.예
24.ArrayList 기억해야할 함수들
ArrayList arr = new ArrayList<>();// 예시 데이터 추가arr.add("A");arr.add("B");arr.add("C");String\[] strArray = arr.toArray(new String0);
25.StringBuilder 함수 기억할거 정리
StringBuilder뒤에 글자추가 append(내용)원하는 위치에 넣기 insert(index, 내용)원하는 위치 삭제 deleteCharAt(index)
26.최대공약수 구하기GCD 최소공배수LCM
27.BST, HEAP
BST (Binary Search Tree)속성: 각 노드의 왼쪽 서브트리에는 노드의 값보다 작은 값들이, 오른쪽 서브트리에는 노드의 값보다 큰 값들이 위치합니다.탐색 유용: BST는 탐색과 정렬에 유용합니다.시간 복잡도: 일반적으로 O(logn)의 시간 복잡도를 가지
28.퀵소트 최악의 경우와 개선방안
이미 정렬된 배열피벗 선택이 첫 번째 또는 마지막 원소: 이 경우, 분할이 매우 불균형적으로 일어나므로 시간복잡도는 O(n^2)이 됩니다중복된 값이 많은 배열어떤 피벗 선택 기준을 사용하더라도: 중복된 값이 많을 경우, 피벗을 어떻게 선택하더라도 분할이 불균형적으로 일
29.정렬할때 어떤 sort 알고리즘
정렬 알고리즘의 선택은 여러 요인에 따라 달라집니다. 여기 몇 가지 고려할 점들과 그에 따라 선호할 수 있는 정렬 알고리즘을 소개합니다:고려할 요인데이터의 크기: 작은 데이터셋에는 단순한 알고리즘이 빠를 수 있습니다.데이터의 특성: 이미 정렬되어 있는지, 무작위인지,