강남3구 범죄현황 데이터 개요 및 읽어오기
목표: 강남 3구의 범죄 현황
데이터 읽어오기(서울시 5대 범죄에 대한 데이터)
crime_raw_data = pd.read_csv(
'../파일 이름', thousands=',', encoding='euc-kr'
)
crime_raw_data.head(3)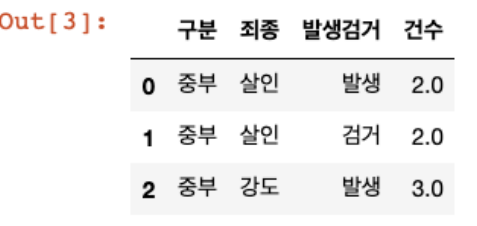
- 숫자들이 콤마를 사용하고 있어서 문자로 인식될 수 있다
- 천단위 구분(thousands=',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽는다
crime_raw_data.info()
- RangeIndex는 65534인데 데이터들이 310개??
crime_raw_data['죄종'].unique()
- NaN이 포함되어 있다
- NaN이 아닌 데이터만 다시 가져오자
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()]
crime_raw_data.info()
사용할 모듈 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
# 마이너스 부호 때문에 한글이 깨질 수 있기 때문에 설정
plt.rcParams["axes.unicode_minus"] = False
rc('font', family='Malgun Gothic')
%matplotlib inline
import seaborn as sns
import googlemaps
import folium
import jsonPandas의 pivot_table
pivot_table 기초
pivot_table: index, columns, values, aggfunc 등의 옵션으로 데이터 정리, 재정렬index: 원하는 기준 선택columns: 원하는 열 선택values: 원하는 출력 선택aggfunc: 중복값을 처리할 방법 선택으로 다중 선택도 가능, 기본값 평균-np.meannp.sum, np.mean, len등fill_value: NaN 데이터 처리margins: 합계 지정(aggfunc에 따라 각 행을 계산)
pivot_table 연습
1
df = pd.read_excel('../data/파일 이름')
df.head()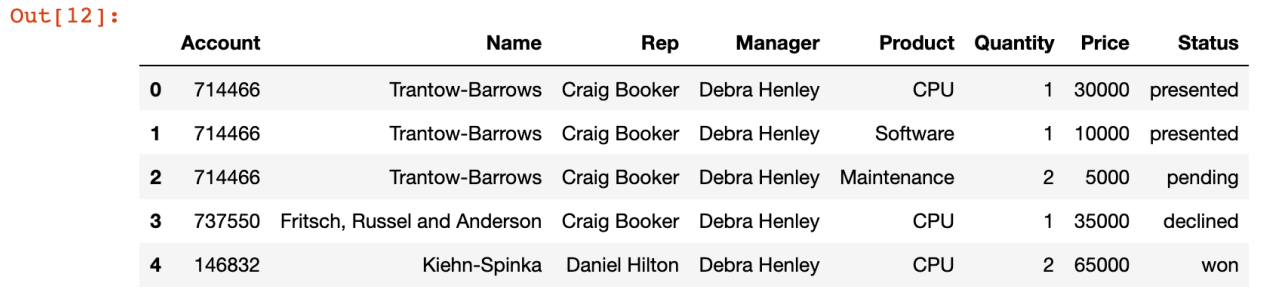
- 파일 기본 형태
2
pd.pivot_table(df, index=['Name'])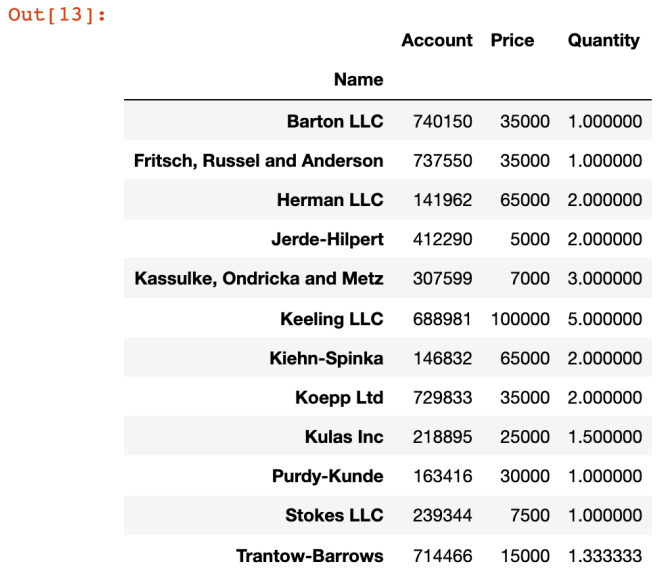
- index를 Name을 기준으로 정렬
3
pd.pivot_table(df,index=['Name','Rep','Manager'])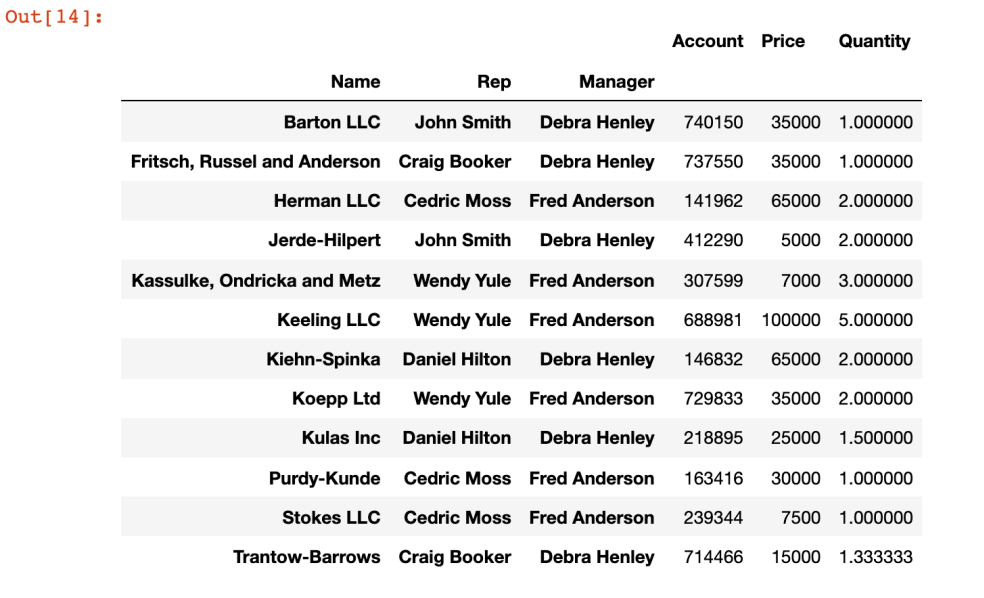
- index 여러개 지정할 수 있다
4
pd.pivot_table(df,index=['Manager','Rep'], values=['Price'])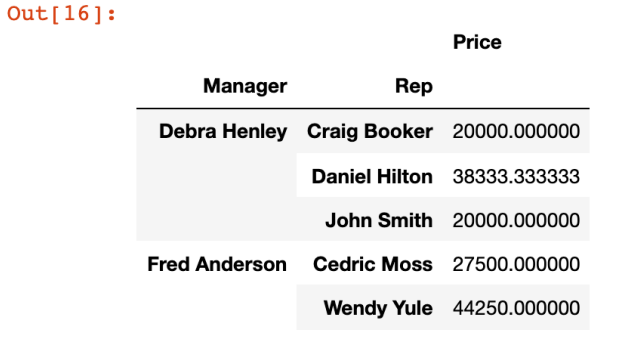
- 아무것도 적지 않으면 디폴트로 평균을 구한다
5
pd.pivot_table(df,index=['Manager','Rep'], values=['Price'], aggfunc=np.sum)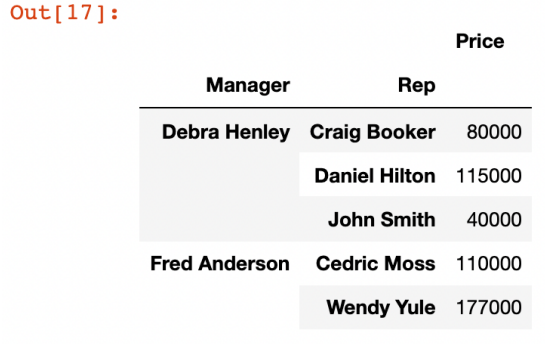
aggfunc옵션으로 values에 함수 적용가능- default는 평균
- 합산 등의 다른 함수를 적용할 때에 aggfunc 옵션을 지정
6
pd.pivot_table(df,index=['Manager','Rep'], valeus=['Price'], aggfunc=[np.mean,len])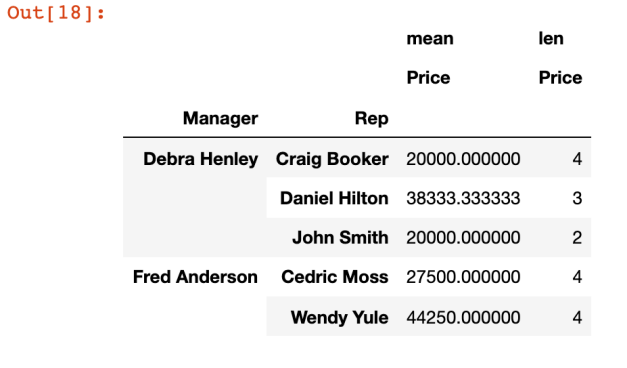
7
pd.pivot_table(df, index=['Manager','Rep'], values=['Price'], columns=['Products'], aggfunc=[np.sum])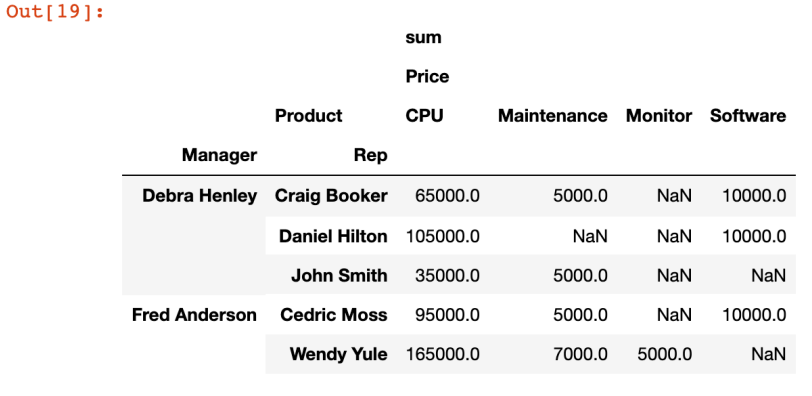
- 분류를 지정
- 없는 데이터는 NaN 처리
8
pd.pivot_table(
df,
index=['Manager','Rep'],
values=['Price'],
columns=['Products'],
aggfunc=[np.sum],
fill_value=0
)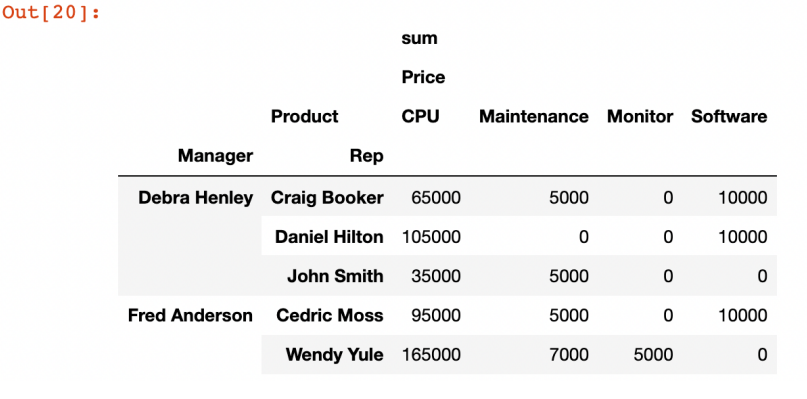
- NaN에 대한 처리를 지정
9
pd.pivot_table(
df,
index=['Manager','Rep','Product'],
values=['Price','Quantity'],
aggfunc=[np.sum,np.mean],
fill_value=0,
margins=True
)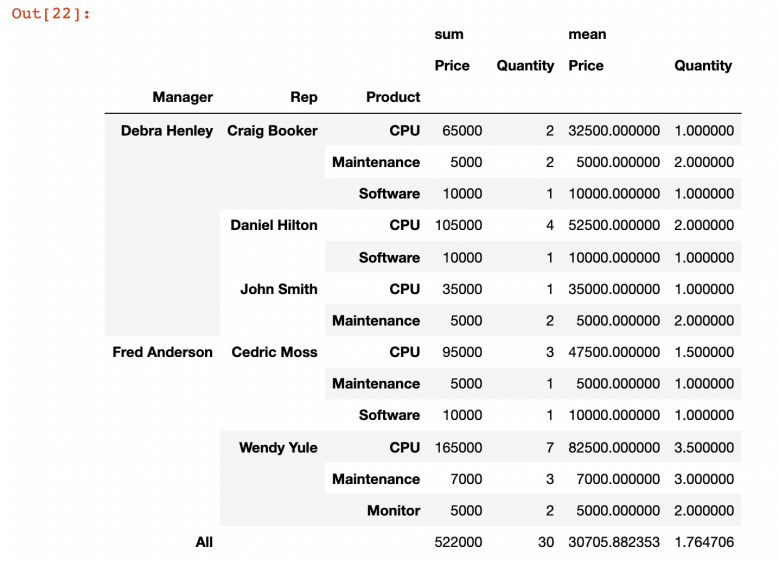
- 합계를 지정할 수 있다
서울시 범죄현황 데이터 정리
구별 혹은 경찰서별 데이터가 필요한데 이를 위한 명령어
pivot_table 적용
crime_station = pd.pivot_table(
crime_raw_data,
index=['구분'],
columns=['죄종','발생검거'],
aggfunc=[np.sum]
)
crime_station.head()- 경찰서 이름이 index로
- 사건의 합을 기록하기 위해 aggfunc=[np.sum]
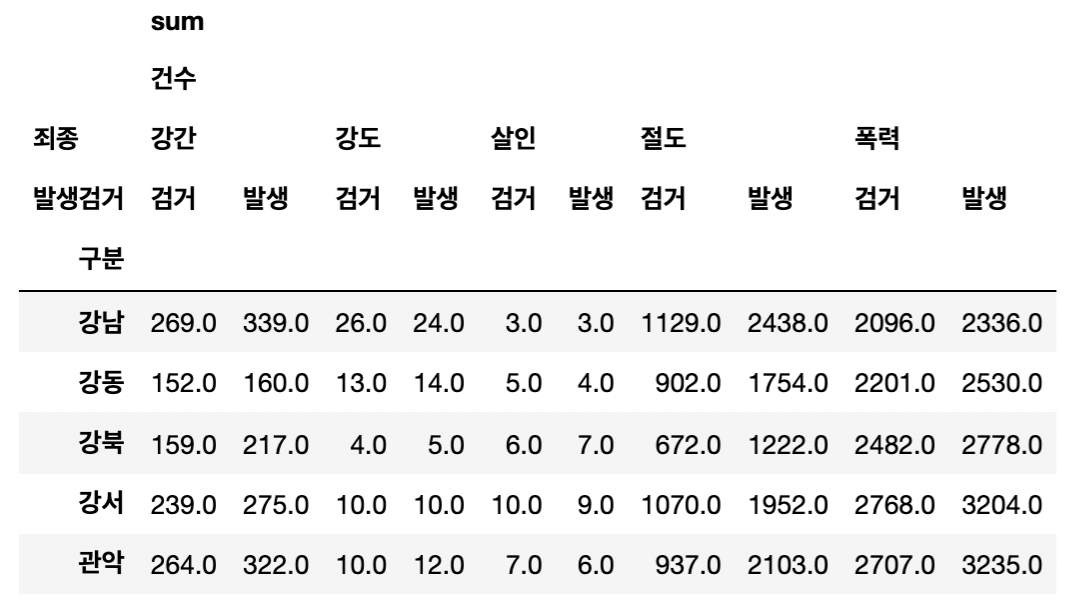
- 그러나 column이 multi로 잡힌다
- sum과 건수가 하나만 보이지만 사실 생략되어 보이지 않을 뿐 존재한다
column 조회
crime_station.columns
특정 컬럼 제거
crime_station.columns = crime_station.columns.droplevel([0,1])
crime_station.columns
droplevel: 다중 컬럼에서 특정 컬럼 제거
crime_station.head()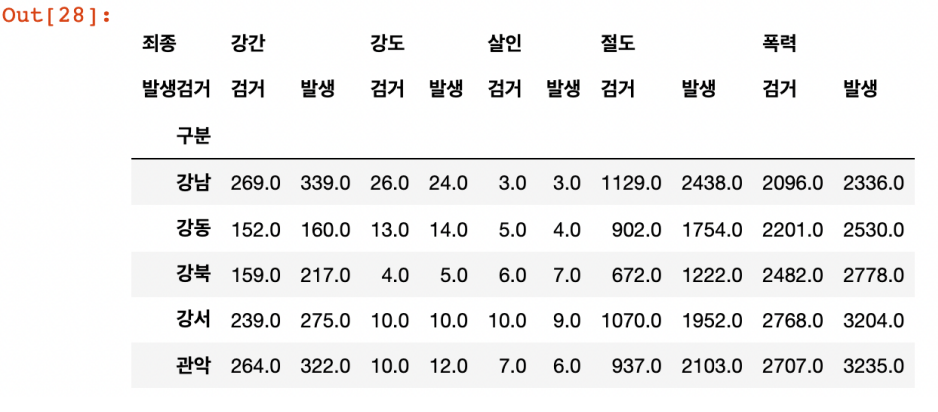
index 조회
crime_station.index
- 현재 index는 경찰서 이름으로 되어 있다
- 경찰서 이름으로 구 이름을 알아야 한다
google maps api 사용 준비하기
- 경찰서 이름을 가지고 해당 경찰서가 속해 있는 구를 알아내자
- 이때 구글 검색처럼 경찰서 이름을 검색해서 해당 구를 알아낼 수 있으면 좋겠는데
모듈 설치
conda install -c conda-forge googlemaps
- 이때 Google Map API Key도 필요하다
import googlemaps
gmaps_key = 'API Key'
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode('서울영등포경찰서', langeuage='ko')python의 for문
Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어진다
- Pandas 데이터 프레임으로 반복문을 만들 때
iterrows()라는 옵션을 사용하면 편하다 - 받을 때, index와 내용으로 나누어 받는 것만 주의
google maps에서 구별 정보를 얻어서 데이터를 정리
주소와 위치 정보 얻기
import googlemaps
gmaps_key = 'API Key'
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode('서울영등포경찰서', langeuage='ko')
tmp = gmaps.geocode('서울영등포경찰서', langeuage='ko')
print(tmp[0].get('geometry')['location']['lat'])
print(tmp[0].get('geometry')['location']['lng'])
print(tmp[0].get('formatted_address'))
- 전체 결과 크기가 1인 list형이라서
tmp[0]으로 접근 - 내부는 dict형이므로
get으로 접근(dict형에서 데이터를 얻는 get명령을 사용)
tmp = tmp[0].get('formatted_address')
tmp.split()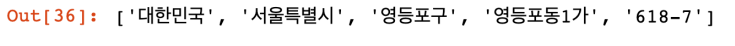
서울시 범죄 데이터에 데이터 추가
crime_station['구별'] = np.nan
crime_station['lat'] = np.nan
crime_station['lng'] = np.nan
crime_station.head()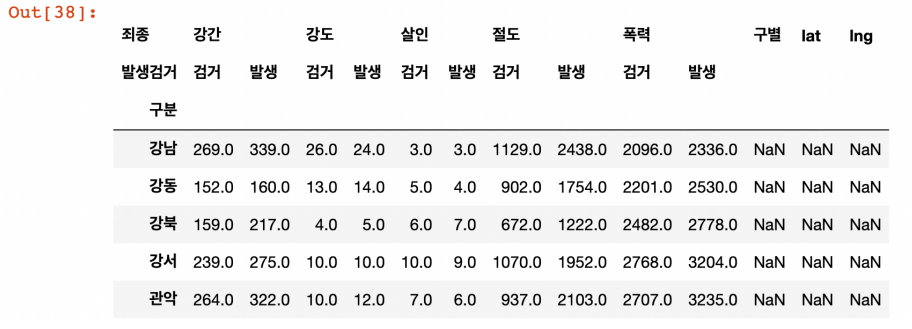
- 경찰서 이름에서 소속된 구 이름 얻기
- 구이름과 위도, 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채우자
for idx, rows in crime_station.iterrows():
station_name = '서울' + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language='ko')
tmp_gu = tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat'])
lng = tmp[0].get('geometry')['location']['lng'])
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
crime_station.loc[idx, '구별'] = tmp_gu.split()[2]- station_name : 구글 검색을 용이하게 하기 위해 검색어를 가급적 상세하게 잡아준다
loc옵션을 사용- 행(idx)과 열('lat','lng','구별')을 지정해서 구글 검색에서 얻은 정보를 기록
crime_station.head()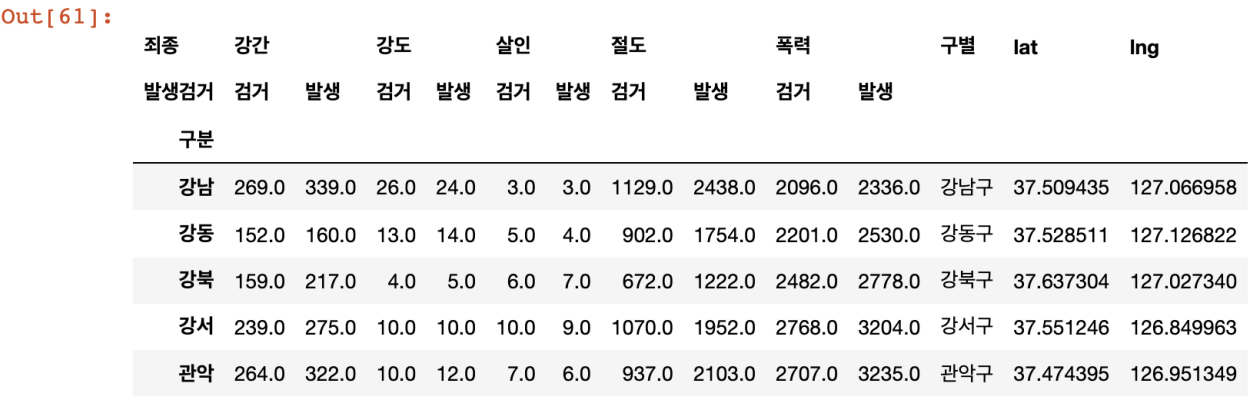
데이터 컬럼 정리
# 레벨0, 레벨1의 컬럼명을 합쳐 컬럼명 변경
tmp = [
crime_station.columns.get_level_values(0)[n]
+ crime_station.columns.get_level_values(1)[n]
for n in range(len(crime_station.columns.get_level_values(0)))
]
crime_station.columns = tmp
crime_station.columns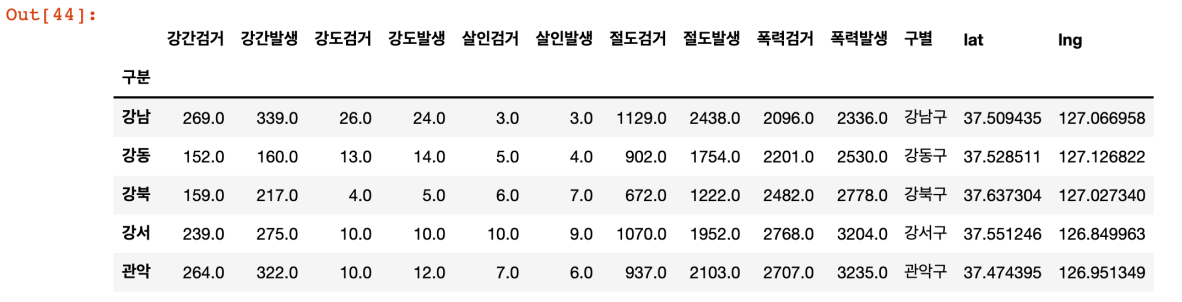
- 다중컬럼 합치기
get_level_values(N): 각 레벨의 컬럼명 추출
crime_station.to_csv('../data/파일 이름',sep=',', encoding='utf-8')- 저장
구별데이터로 변경하기
- 경찰서별 데이터로 정리되어 있다
- 서울은 한 구에 경찰서가 2 곳인 구가 있다
- 그러므로 구의 이름으로 다시 재정렬해야 한다
- pivot_table 활용
데이터 불러오기
crime_anal_station = pd.read_csv(
'../data/파일 이름', index_col=0, encoding='utf-8'
)
crime_anal_station.head()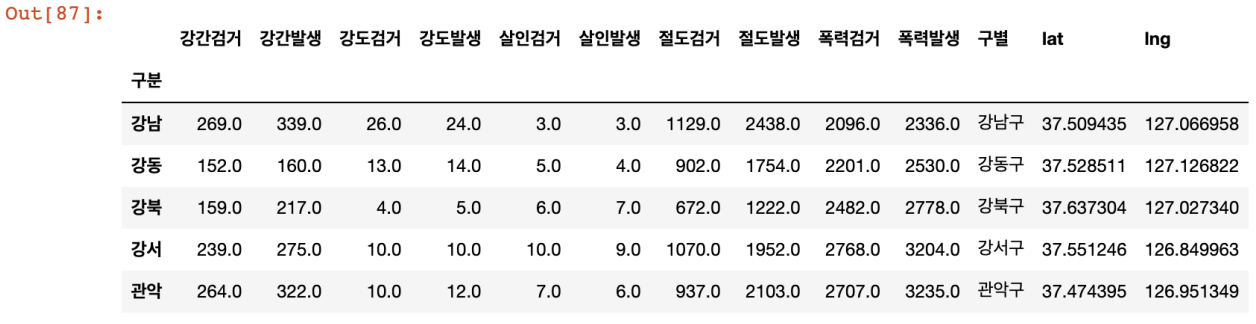
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
# 위도와 경도를 필요없으므로 삭제
del crime_anal_gu["lat"]
del crime_anal_gu["lng"]
# crime_anal_gu.drop("lng", axis=1, inplace=True)
crime_anal_gu.head()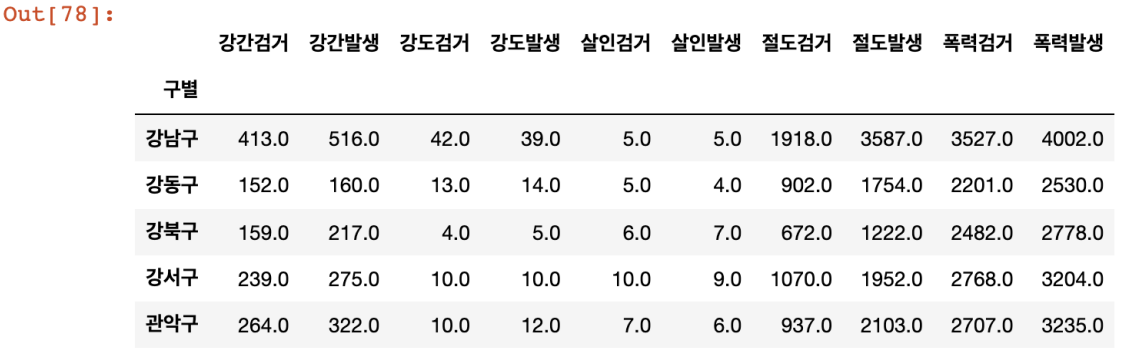
검거율 데이터 추가
- 다수의 컬럼을 다수의 컬럼으로 각각 나누고 싶다면?
target = ['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율']
num = ['강간검거','강도검거','살인검거','절도검거','폭력검거']
den = ['강간발생','강도발생','살인발생','절도발생','폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()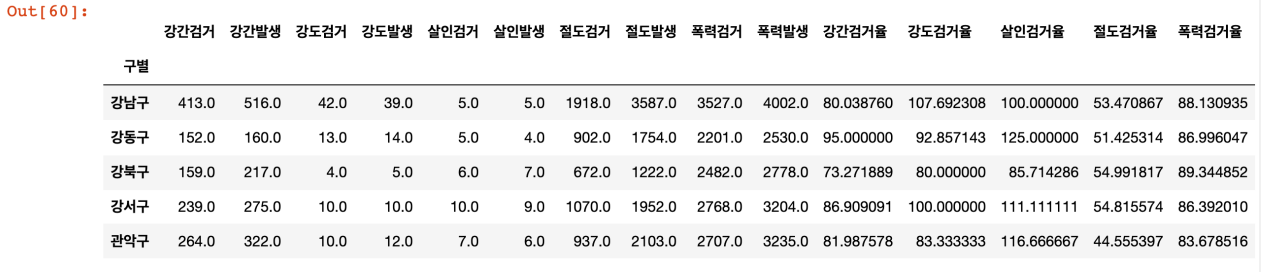
- 불필요 컬럼 삭제
del crime_anal_gu['강간검거']
del crime_anal_gu['강도검거']
del crime_anal_gu['살인검거']
del crime_anal_gu['절도검거']
del crime_anal_gu['폭력검거']
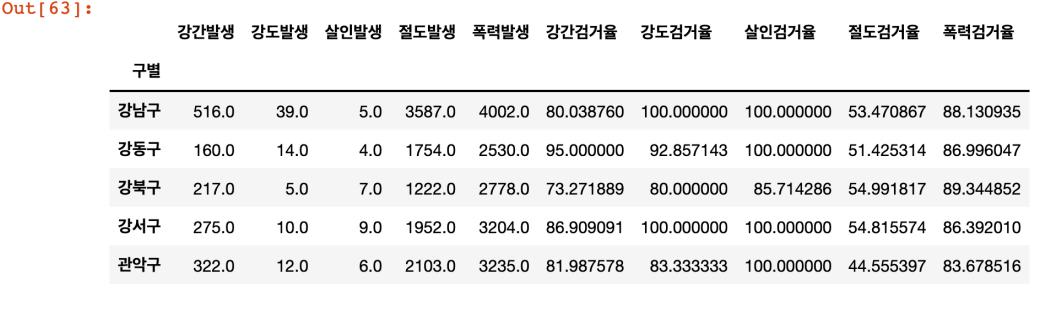
crime_anal_gu.head()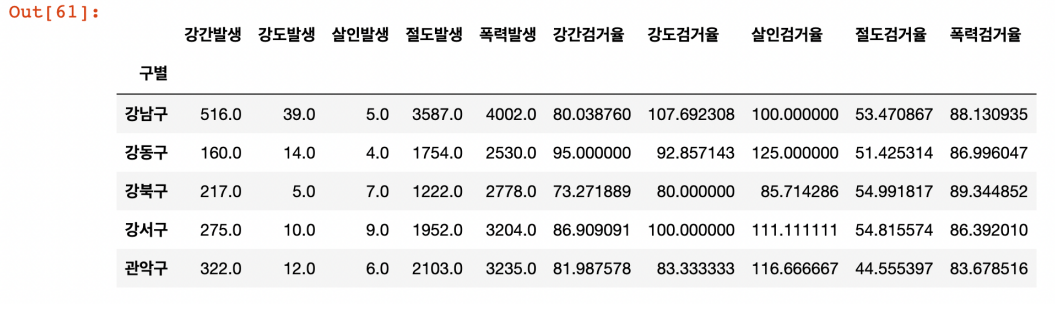
- 검거율이 100이 넘는 경우가 발생
- 발생 연도와 검거 연도를 구분하고 분석해야하지만
- 아직 그런 디테일까지는 목표가 아니므로
- 강제로 100 이상의 수치는 100으로 만든다
- 나중에 heatmap등의 그래프에서 문제가 될 수 있기 때문에
crime_anal_gu[crime_anal_gu[target] > 100] = 100
crime_anal_gu.head()
- 컬럼 이름 변경
crime_anal_gu.rename(
columns={
'강간발생':'강간',
'강도발생':'강도',
'살인발생':'살인',
'절도발생':'절도',
'폭력발생':'폭력'
}, inplace=True
)
crime_anal_gu.head()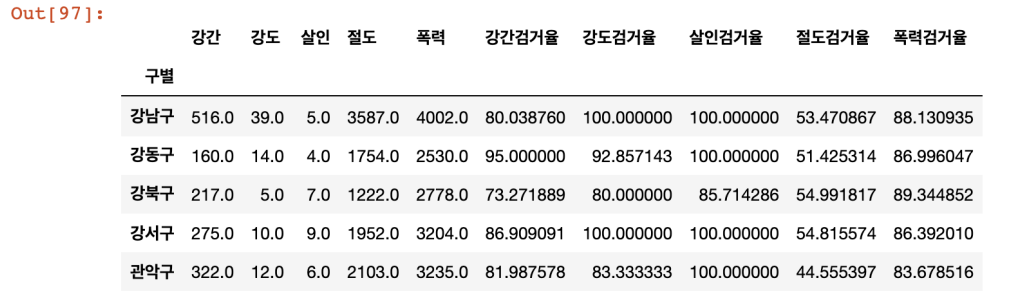

+database