📋 목차
- 상속 관계 매핑
- 객체의 상속 관계를 데이터베이스에 어떻게 매핑하는지 다룬다.
- @MappedSuperclass
- 등록일, 수정일 같이 여러 엔티티에서 공통으로 사용하는 매핑 정보만 상속받고 싶으면 이 기능을 사용하면 된다.
상속관계 매핑
- 관계형 데이터베이스에는 객체지향 언어에서 다루는 상속이라는 개념이 없다.
- 대신 디비의 슈퍼타입 서브타입 관계(Super-Type Sub-Type Relationship)라는 모델링 기법이 객체의 상속 개념과 가장 유사하다.
- ORM에서 이야기하는 상속관계 매핑은 객체의 상속구조와 데이터베이스의 슈퍼타입 서브타입 관계를 매핑하는 것이다.
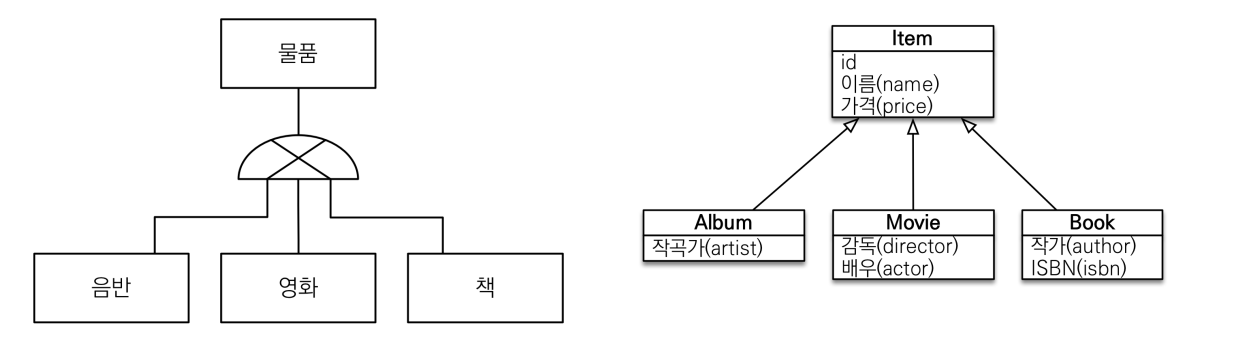
3가지 변환 방식
- 슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 것에는 3가지 방법이 있다.
- 각각의 테이블로 변환하기. (조인 전략)
- 각각의 자식들을 모두 테이블로 만들고 조회할 때 조인을 사용한다.
- 통합 테이블로 변환 (단인 테이블 전략)
- 자식들을 모두 합쳐 하나의 테이블에 둔다.
- 서브타입 테이블로 변환 (구현 클래스마다 테이블 전략)
- 각 서브타입마다 하나의 테이블을 만든다.
- 각각의 테이블로 변환하기. (조인 전략)
주요 애노테이션
@Inheritance(strategy = InheritanceType.XXX)JOINED: 조인 전략SIGNLE_TABLE: 단일 테이블 전략TABLE_PER_CLASS: 구현 클래스마다 테이블 전략
@DiscriminatorColumn(name = "DTYPE")@DiscriminatorValue("XXX")
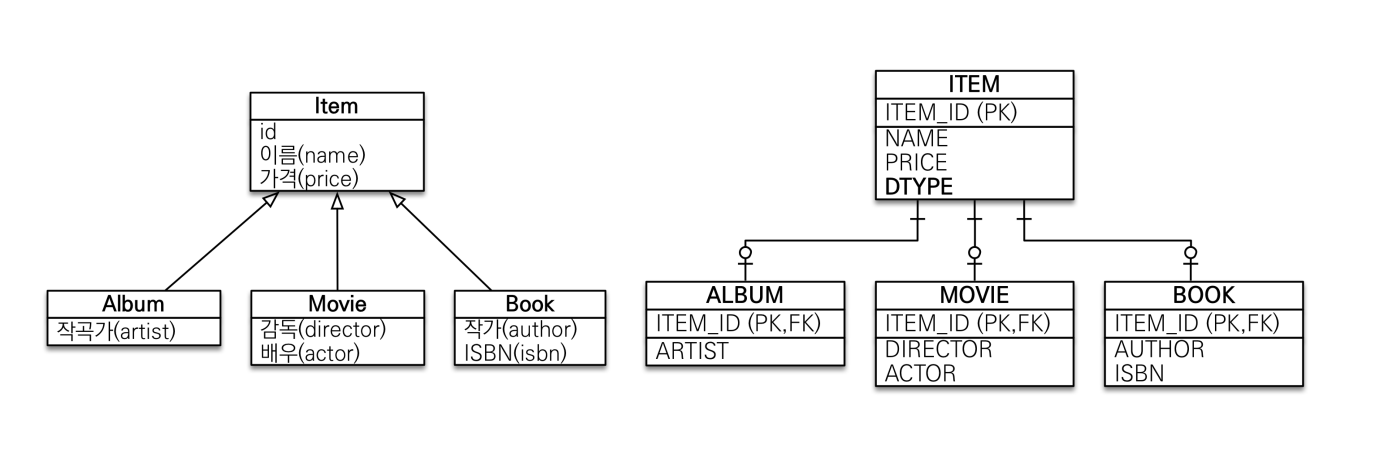
1. 조인 전략 (Joined Strategy)
- 엔티티 각각을 모두 테이블로 만들고 자식 테이블이 부모 테이블의 기본 키를 받아 기몬키 + 외래키로 사용하는 전략.
- 기본적으로 조인전략이 정석이라고 보면 좋다.
- 객체와도 잘 맞고, 정교화도 잘 되어있고, 설계가 깔끔하게 떨어진다.
- 단일 테이블과 비교해 조금 더 복잡하고 성능이 안나올 확률이 높아, 해당 부분을 단일 테이블과 비교해 트레이드 오프 하는 방식으로 선택하면 좋다.
- 주의사항:
- 객체는 타입으로 구분 가능하나 테이블은 타입의 개념이 없다.
- 따라서 타입을 구분하는 컬럼을 추가해야 하는데, DTYPE 컬럼을 구분 컬럼으로 사용한다.
장단점
- 장점
- 테이블 정규화
- 외래키 참조 무결성 제약조건 활용 가능
- 다른 테이블에서 Item 테이블을 참고해야 할때, 그 자식 테이블인 Album, Movie, book과 상관없이 Item만 조회하는 것이 가능하다.
- 저장공간 효율화
- 정교화가 깔끔하게 이루어져 있어 저장공간을 효율적으로 사용할 수 있다.
- 단점: 테이블이 많아져 전반적으로 복잡해진다.
- 조회 시 조인을 많이 사용, 성능 저하
- 어떤 작업을 수행하든 Item과 그 자식 테이블들 간의 조인이 요구된다.
- 조회 쿼리가 복잡함
- 데이터 저장시 INSERT SQL 2번 호출
- 조회 시 조인을 많이 사용, 성능 저하
예시코드: 엔티티 생성
Item
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
public class Item {
@Id
@GeneratedValue
private Long id;
private String name; // 이름
private int price; // 가격
}@Inheritance(strategy = InheritanceType.JOINED)- 상속 매핑은 부모 클래스에
@Inheritance를 사용해야 한다. - 매핑 전략을 지정해야 하는데, 여기서는
InheritanceType.JOINED를 사용했다.
- 상속 매핑은 부모 클래스에
@DiscriminatorColumn(name = "DTYPE")- 부모 클래스의 구분 컬럼을 지정한다. 이 컬럼을 통해 자식 테이블을 구분할 수 있다.
- 기본값이 DTYPE이므로
@DiscriminatorColumn로 줄여 사용할 수 있다. - DTYPE이라는 컬럼 자체가 반드시 필수적으로 필요한 것은 아니지만 (뭘 조인해야 하는지 이미 알고있으므로), db를 사용할 때 DTYPE이 있는 편이 작업이 훨씬 용이해 사용이 권장된다.
Album
@Entity
@DiscriminatorValue("A")
public class Album extends Item {
private String artist;
}@DiscriminatorValue("A")- 엔티티를 저장할 때 구분 컬럼에 입력할 값을 지정한다. (기본값: 엔티티명)
- 만약 앨범 엔티티를 저장하면 구분 컬럼인 DTYPE에 A가 저장된다.
Movie
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
}Book
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
private String isbn;
}DB 테이블 생성 결과
CREATE TABLE Item (
id BIGINT NOT NULL,
name VARCHAR(255),
price INTEGER,
DTYPE VARCHAR(31), // 부모(Item)쪽에 DTYPE 생성
PRIMARY KEY (id)
);
CREATE TABLE Album (
artist VARCHAR(255),
id BIGINT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (id) REFERENCES Item (id)
);
CREATE TABLE Movie (
director VARCHAR(255),
actor VARCHAR(255),
id BIGINT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (id) REFERENCES Item (id)
);
CREATE TABLE Book (
author VARCHAR(255),
isbn VARCHAR(255),
id BIGINT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (id) REFERENCES Item (id)
);- 각 자식 테이블(Album, Move, Book)이 부모 테이블(Item)의 기본키를 외래키로 참조하고 있다.
예시코드: 저장
// ...
Movie movie = new Movie();
movie.setDreictor("aaa");
movie.setActor("bbb");
movie.setName("바람과함께사라지다");
movie.setPrice(10000);INSERT INTO Item (neme, price, id) VALUES (?, ?, ?)
INSERT INTO Movie (actor, director id) VALUES (?, ?, ?)결과
SELECT * FROM item
SELECT * FROM movie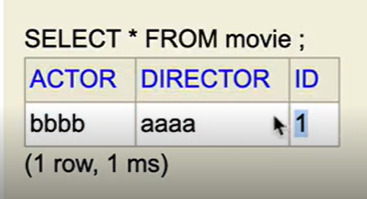
- 양쪽 테이블의 id가 동일하다.
- item 쪽에서는 id가 pk이고, 자식테비을 입장에서는 id가 pk이면서 동시에 fk여야 한다.
예시코드: 조회
// ...
Movie movie = new Movie();
movie.setDreictor("aaa");
movie.setActor("bbb");
movie.setName("바람과함께사라지다");
movie.setPrice(10000);
em.persist(movie);
em.flush(); // flush, clear을 통해
em.clear(); // 1차 캐시에 아무것도 남지 않는다.
em.find(Movie.class, movie.getId());
System.out.println("fiindMovie = " + findMovie);결과
SELECT
movie.id as id
item.name as name
item.price as price
movie.actor as actor
movie.director as director
FROM
movie movie
INNER JOIN
Item item
ON item.id = movie.id
WHERE
movie.id = ?- jpa에서 자동 생성하는 alias를 보기 편하게 변경했다.
- Movie와 INNER JOIN으로 데이터를 가져온다. (상속 시 이런 부분을 JPA가 대신해준다.)
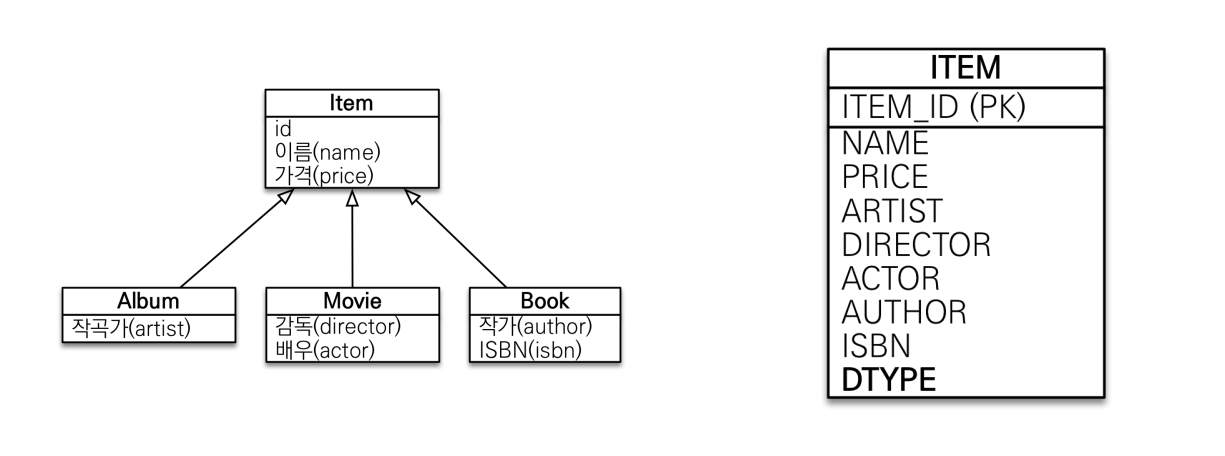
2. 단일 테이블 전략 (Single-Table strategy)
- 테이블을 하나만 사용한다.
- 구분 컬럼(DTYPE)으로 어떤 자식 데이터가 저장되었는지 구분한다.
- 조회할 때 조인을 사용하지 않으므로 가장 빠르다.
- 구분 컬럼을 꼭 사용 해야한다. (단일 테이블이므로 구분 컬럼없이 어떤 자식 엔티티인지 구분할 수 없다.)
@DiscriminatorColumn을 반드시 설정해야 한다. 생략 시 기본으로 엔티티이름을 사용한다.
장단점
- 장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
- 조회 쿼리가 단순함
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 치명적인 단점일 수 있다.
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라 조회 성능이 오히려 느려질 수 있다.
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
예시코드: 엔티티
Item
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public class Item {- Inheritance의 stratege 타입을
SINGLE_TABLE로만 변경하면 끝난다! @DiscriminatorColumn을 생략해도 DTYPE이 무조건 생긴다.- 조인 전략은 테이블이 분리되어 있어 DB를 살펴보다 보면 어떤 테이블의 데이터인지가 조회가 가능하다. 그러나 단일 테이블 전략은 DTYPE컬럼이 없으면 해당 데이터가 어떤 객체(Member인지 Album인지) 알 방법이 전혀 없다.
DB 테이블 생성 결과
CREATE TABLE Item (
DTYPE VARCHAR(31) not null,
id INT NOT NULL,
name VARCHAR(255),
price INT,
artist VARCHAR(255),
actor VARCHAR(255),
author VARCHAR(255),
isbn VARCHAR(255),
director VARCHAR(255),
PRIMARY KEY (id)
);결과

저장 및 조회 결과
- 코드는 위의 저장, 조회 코드와 동일하다.
- 전반적으로 쿼리가 굉장히 단순하게 날아간다. (성능상에도 이점이 있다.)
INSERT INTO item (name, price, actor, director, DTYPE, id) VALUES(?, ?, ?, ?, 'M', ?)
SELECT
item.id as id
item.name as name
item.price as price
item.actor as actor
item.director as director
FROM
Item item
WHERE
item.id = ?
and item.DTYPE = 'M'3. 구현 클래스마다 테이블 전략(Table-per-Concrete-Class Strategy)
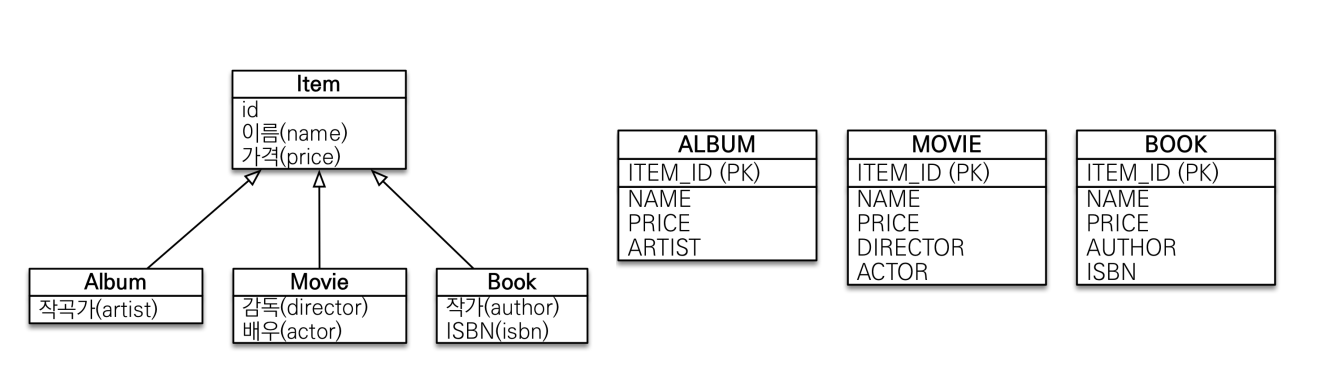
- 자식 엔티티 마다 테이블을 만든다. 그리고 자식 테이블에 각각에 필요한 컬럼이 모두 있다.
- 구분 컬럼이 필요가 없다. (테이블 자체가 전부 분리되어 있기 때문)
- 이 경우에는
@DiscriminatorColumn이 적용되지 않는다.
- 이 경우에는
- 얼핏 깔끔하고 좋아보이지만 item으로 검색할때 3개의 테이블을 UNION 으로 조회해야 해 성능이 좋지 않아 권장되지 않는다.
장단점
- 이 전략은 디비 설계자와 ORM 전문가 둘 다에게 추천하지 않는다. (쓰지마라)
- 장점
- 서브 타입을 명확하게 구분해서 처리할 때 효과적
- not null 제약조건 사용 가능
- 단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느림 (UNION SQL이 필요)
- 자식 테이블을 통합해서 쿼리하기 어려움
- 통합의 어려움으로 상속을 통해 얻을 수 있는 모든 장점을 얻을 수 없게 된다. Item이라는 공통 요소를 부모로 사용해 추가를 용이하게 하거나, 정산등의 처리를 용이하게 하는 등의 기능을 db 측면에서는 전혀 이용할 수 없게 된다.
- 데이터를 통합해서 다룰 때에도 어려움이 크고, 새로운 타입 추가라는 변화에도 불리하다.
예시코드: 엔티티
Item
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn
public abstract class Item {- 부모 엔티티를 추상 클래스(abstract)로 생성해 줘야 한다.
- 그냥 클래스로 생성하는 경우, (JPA가 인식하기에) 해당 테이블을 독단적으로 사용하는 경우도 존재한다는 의미가 된다. (그래서 Item 테이블도 생성한다.)
DB 테이블 생성결과
CREATE TABLE Album (
id INT NOT NULL,
name VARCHAR(255),
price INT,
artist VARCHAR(255),
PRIMARY KEY (id)
);
CREATE TABLE Movie (
id INT NOT NULL,
name VARCHAR(255),
price INT,
director VARCHAR(255),
actor VARCHAR(255),
PRIMARY KEY (id)
);
CREATE TABLE Book (
id INT NOT NULL,
name VARCHAR(255),
price INT,
author VARCHAR(255),
isbn VARCHAR(255),
PRIMARY KEY (id)
);저장 및 조회 결과
INSERT INTO movie(name, price, actor, director, id) VALUES(?, ?, ?, ?, ?)
SELECT
movie.id as id,
movie.name as name,
movie.price as price,
movie.actor as actor,
movie.director as director
FROM
Movie movie
WHERE
movie.id = ?📌 결론
- 기본으로 조인 전략을 가져가야 한다.
- 조인 전략의 장단점과 단일 테이블 전략의 장단점을 비교해 트레이드 오프 할 생각으로 고민해보면 된다.
- 영한쌤: 그냥 기본으로 조인 전략 가져가고, 너무 간단해서 일이 없을거 같을때 단일 테이블 전략을 가져간다.
Mapped Superclass - 매핑 정보 상속
앞서 학습한 상속 관계 매핑은 부모 클래스와 자식 클래스 모두 데이터베이스의 테이블과 매핑했다. 부모클래스는 테이블과 매핑하지 않고 부모 클래스를 상속 받는 자식 클래스에게 매핑 정보만 제공하고 싶으면 @MappedSuperclass를 사용하면 된다.
@MappedSuperclass는 비유하자면 추상 클래스와 유사한데 @Entity는 실제 테이블과 매핑되지만 @MappedSuperclass는 실제 테이블과는 매핑되지 않는다. 이것은 단순히 매핑 정보를 상속할 목적으로만 사용된다.
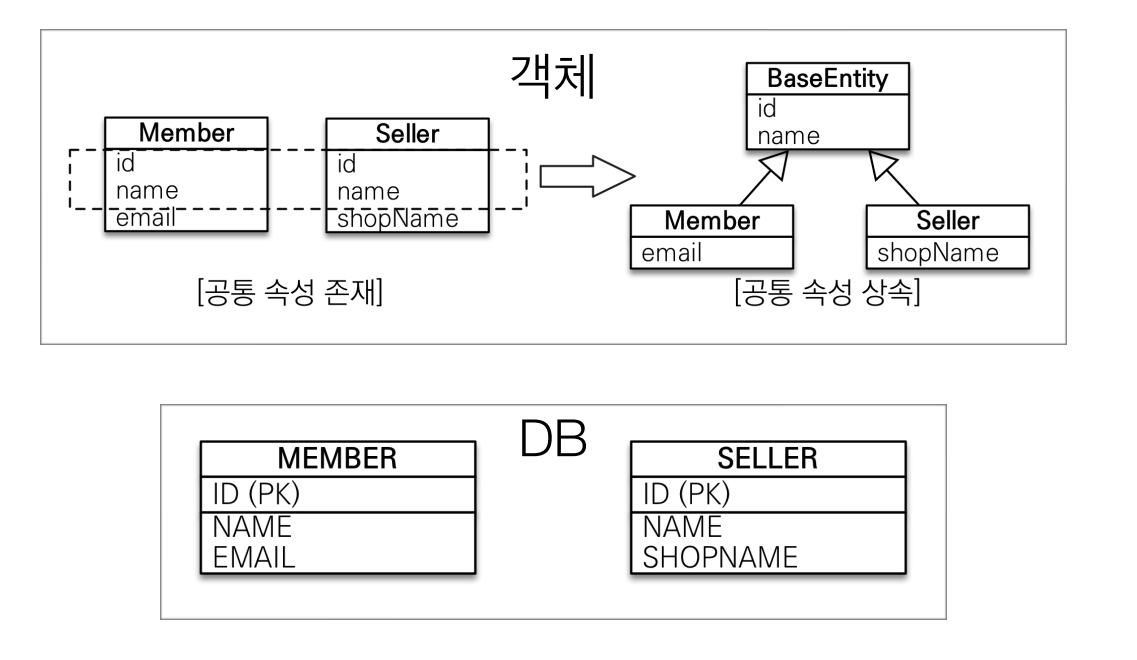
- 공통 매핑 정보가 필요할 때 사용 (id, name)
예시 코드
BaseEntity
@MappedSuperclass
public abstract class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}Member
@Entity
@Getter
@Setter
@Table(name = "member")
public class Member extends BaseEntity {sql 결과
CREATE TABLE member (
id INT NOT NULL,
createdBy VARCHAR(255),
createdDate TIMESTAMP,
lastModifiedBy VARCHAR(255),
lastModifiedDate TIMESTAMP,
PRIMARY KEY (id)
);- Member 테이블에 BaseEntity에 추가한 매핑 정보들이 추가된다.
로직
Member member = new Member();
member.setUsername("user");
member.setCreatedBy("kim");
member.setCreatedDate(LocalDateTime.now());@MappedSuperclass
- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통으로 적용하는 정보를 모을 때 사용한다.
- 특징
- 상속관계 매핑이 아니다.
- 엔티티가 아니므로, 테이블과 매핑되지 않은다.
- 부모 클래스를 상속받는 자식클래스에 매핑 정보만 제공한다.
- 조회, 검색 불가(em.fiind(BaseEntity) 불가)
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 사용을 권장한다.
참고
@Entity 클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속할 수 있다.
Reference

Good Luck!