- 이 글은 무료 OS 관련 책인 Operating Systems: Three Easy Pieces의 41단원, Locality and The Fast File System을 정리한 것입니다. 책의 내용을 잘못 이해한 정보가 있을 수도 있으니 의심되면 원본 내용을 확인해주세요.
- 이미 OS에 대해 전반적인 지식이 있는 분들을 위한 정리 글이라 처음이면 이해가 힘들 수도 있습니다. 이 경우 책을 정독하는걸 강력 추천합니다.
Poor Performance
-
처음 나온 UNIX file system은 구조가 이전 글이랑 비슷하게 단순하면서도 이전의 record 기반 저장공간 시스템 대비 비약적인 발전이었지만 여전히 성능이 별로였다. 디스크 bandwidth의 2%만 활용했다나.
-
이유는 다루는 저장장치가 디스크임에도 메모리처럼 다뤘기 때문이다. 이것의 문제는 데이터를 아무데나 저장을 했기에 inode랑 연관된 실제 데이터가 멀리 떨어져 있는 경우가 많았고, 그게 메모리랑 다르게 bottleneck에 해당되었다는 것.
-
위랑 더불어 동일 파일에 해당하는 block들이 이곳저곳에 분포되는 현상 (external fragmentation)도 발생했다. 이것도 논리적으로는 근접한 파일이 물리적으로 멀리 떨어지도록 유발해 디스크 특성상 심각한 bottleneck의 원인이 됨.
-
마지막으로 그냥 당시에 사용한 block의 크기가 너무 작았다. block은 크기가 작을 수록 internal fragmentation이 줄어드는 효과를 주지만, 반대로 파일이 커질수록 그만큼 여러 block으로 쪼개져 이곳저곳으로 이동을 해야 하는 문제가 되었고 이것이 bottleneck의 원인이 되기도 했다.
-
위의 모든 문제점은 하나로 요약이 가능하다. 디스크의 특징을 당시 파일 시스템이 제대로 인지를 못했다는 것. 그러면 어떻게 해결해야 할까?
FFS
-
Fast File System은 disk의 특징을 활용하는 파일 시스템이다.
-
파일 접근에 필요한 인터페이스는 (
open,read,write등의 시스템 콜 등) 동일하게 유지하면서 관련 구현만 바꾼 것이다.
Cylinder Group
- 먼저 disk를 단순히 block으로 나누는게 아니라 cylinder group으로 나눴다. 디스크가 하나의 큰 원기둥이라고 생각했을 때
- track : 디스크 중심으로부터 특정 반지름만큼 떨어져 있는 원.
- cylinder : 각기 다른 평면에서 동일한 반지름을 가지는 track들의 모임.
- cylinder group : 연속된 cylinder들의 모임.

-
예시로 위의 경우, 원 하나하나가 track이고, 동일한 색깔의 원들을 모은 것이 cylinder이고, 가장 외각에 있는 cylinder 3개를 모아서 cylinder group으로 생각하면 된다. (cylinder group마다 cylinder을 3개씩 가진다고 가정 했을 때)
-
다만 현대의 경우, 위와 같은 구조로 구별하는데 필요한 충분한 정보를 device driver에서 제공하지 않을 수 있다. 이 경우 file system에서는 disk drive를 block group의 형태로 관리를 한다. 다만 이래도 각 block은 실제 disk 주소 영역의 연속된 공간을 나타내고 동일 group 내에서의 접근은 효율적으로 이루어지는 것이 보장된다.
-
이 경우 접근을 할 때 file system에서 block group 기반 시스템 상에서의 logical address를 device driver에 전달하면 driver은 이를 cylinder 구조 하의 실제 주소로 변환해서 접근을 해준다.
-
결론은 위와 같은 block group을 사용하는 file system이든 cylinder group을 사용하는 file system이든 같은 group안에 있는 block의 접근은 효율적으로 이루어지는 것이 보장된다는 것이다. 그 이유는 디스크 자체 구조랑 관련된 내용이라 생략. 그래서 둘이 사실상 동일한걸 나타낸다고 생각해도 되며 책에서는 cylinder group이라는 용어를 주로 사용한다.
-
그러면 어떤 파일을 접근할 때 가능하면 처음 접근한 group에서 벗어나지 않는걸 원할거고, 그럴려면 각 group마다 file system 운용에 필요한 모든 자료 구조 (superblock, inode bitmap, data bitmap, inode, data block)을 보유하는 것이 좋을거고 실제로도 그렇다. 이것의 배치는 기존의 vsfs랑 동일하게 해도 된다.

Policies : How To Allocate Files and Directories
-
기존 파일시스템처럼 빈 공간이 발견된다고 바로 파일과 디렉토리를 할당하는건 이제 안된다. 연관된 파일은 같은 group안에 있도록 하고 싶기 때문이다. 안 그러면 이렇게 애써서 만든 구조가 의미가 없기 때문.
-
새로운 디렉토리를 생성하는 경우, 가장 디렉토리 개수가 적고 inode 여유가 많은 group을 선택한다. 최대한 group별 디렉토리가 고르게 분포하면서, 만일 파일을 여러개 만들어야 하는 경우 이에 대비할 수 있도록 하기 위해서다. 뭐 꼭 이 방식을 택할 필요는 없지만 말이다.
-
파일의 경우 일반적으로 2가지를 고려한다. 보면 알겠지만 이러는 이유는 같은 group 안에서만 효율적인 접근이 보장되기 때문이다.
- 가급적 파일의 inode랑 data block이 같은 group에 있도록 한다.
- 특정 디렉토리 내 모든 파일들이, 그 디렉토리가 있는 group이랑 동일한 group에 있도록 한다. (inode든, data block이든)
-
예시로
/,/a,/b라는 directory가 있고/a/c,/a/d,/a/e,/b/f라는 파일이 있고, 각 파일이 data block을 2개를 차지한다고 가정시 앞에 정한 규칙에 따르면 밑과 같이 배치될 것이다. 이러면 특정 디렉토리 안의 파일을 접근하는 과정에서 생기는 탐색 과정이 효율적으로 이루어질 수 있게 된다. (단/에서/a나/b로 이동하는 것은 여전히 비효율적으로 이루어진다.)

- 단순히 각
inode가 group별로 고르게 분포하도록 정책을 정할 경우 밑과 같이 되는데 이러면 앞에서 언급한 단점과 더불어 특정 디렉토리 내 파일을 탐색하는 과정도 매우 비효율적으로 이루어지게 된다.

- 그러나 이것만을 고려한 정책이 아니다. 바로 같은 디렉토리 안의 파일들을 전부 탐색할 때 둘러봐야 하는 group의 수도 크게 달라진다. '보통'은 특정 디렉토리 안의 파일을 접근하면 다른 파일들도 같이 접근하는 경우가 흔하기 때문에 이와 같은 구조를 선택했다. 이것에 해당하는 대표적인 예시는 executable을 만들 때 파일들을 linking하는 과정에서 특정 디렉토리 안의 파일을 전부 읽는 경우.
Measuing File Locality
- 이 직관이 납득이 안되면 이랑 연관된 통계를 보는 것이 좋다. File Locality라는 수치가 있는데, 특정 파일 open 후의 다음 file의 공통조상을 찾는데 몇번의 directory 이동이 필요한지를 나타낸 수치다. 동일 파일을 열었으면 0, 동일 directory 안의 파일을 열었으면 1, 그 위 조상 directory 안의 파일을 열었으면 2와 같은 형식.
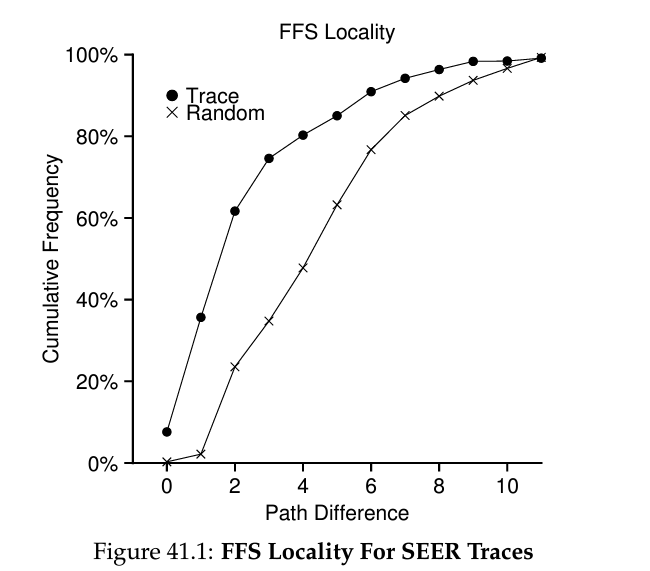
- 보다시피 Trace(SEER Trace)의 경우 1의 비중이 크고, 2의 비중도 꽤 크며 (그 이유에 대한 분석은 책 참고) 둘이 전체의 60% 초반의 비중을 가진다. Random access의 경우에는 이보다 locality가 덜한 편.
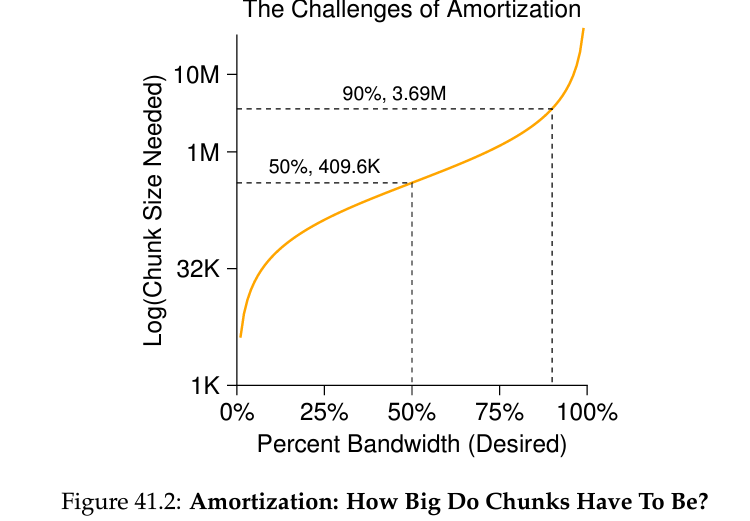
The Large-File Exception
- 큰 파일은 하나의 group을 통째로 차지할 확률이 높고, 이 때문에 관련된 파일들을 같은 group에 넣지 못하게 만들 수도 있다. 이 경우 파일을 좀 큰 단위로 쪼개가지고 각기 다른 그룹에다가 배당한다.

-
당연히 이러면 단점이 있다. 파일을 읽는데 필요로 하는 seeking 시간이 늘어날 수 있다는 것. 때문에 어느 단위로 파일을 나눠서 group에 배정해야 할지에 대한 고민이 필요하다. 그 크기에 따라 전체 I/O 시간 중 어느 비중이 파일 전송에 사용되는지 (= disk bandwidth를 활용하는지), 그리고 어느 비중이 단순 탐색 시간에 사용되는지 정해지게 된다. 구체적인 계산은 책 참고.
-
여기서 유의해야할것은 추구하는 bandwidth 효율이 늘어날수록 나누는 단위의 크기가 커져야 하고, 그렇게 커진 단위의 크기가 같은 directory 내 파일들이 같은 group에 배정되는것을 방해할 수 있다는 것이다.
-
이처럼 overhead 대비 더 많은 일을 함으로써 overhead를 줄이는 것을 amortization이라고 한다.
-
그러나 FFS는 사실 이 방식 말고 inode 구조를 직접 활용하는 형태로 large-file exception을 해결했다. 바로 inode에서 가리키는 첫 몇개의 data block은 같은 group에 넣고, 이후의 indirect block 및 거기서 가리키는 실제 data block들은 전부 다른 group에 넣는 형태로 말이다(...)
-
현재 디스크의 용량 자체는 빠르게 늘어나고 있으나 seeking 과정에서 발생하는 overhead에 대한 구조적인 문제에 대한 발전은 더뎌서 (disk driver 기준) 가능하면 seek 대비 transfer 하는 data 비중을 극대화하는 것이 효율적인 amortization 전략이라고 한다.
A Few Other Things About FFS
-
이전 글의 block에 관한 링크를 봤으면 알겠지만 sub-block이라는 개념이 있는데 이것도 FFS에서 등장했다. internal fragmentation을 줄이기 위해 등장한 개념인데, internal fragmentation이 자주 일어난 이유는 4KB 단위의 block을 사용함에도 불구하고 대부분의 파일이 2KB보다 작은 경우가 대부분이었기 때문.
-
용도는 이렇다. 512byte 단위로 sub-block을 만들고 작은 파일을 만들었으면 sub-block 2개를 할당해 거기에 집어넣고, 추가 data를 넣을 대마다 sub-block을 추가로 할당하다가 모여서 4KB block이 된다면 4KB block을 찾아서 할당, sub-block의 내용물을 거기에 다 옮기고 sub-block을 미할당한다.
-
이 복사 과정이 꽤 비효율적이기 때문에... 애초에
libc의 경우 가급적이면 write를 buffering해가지고 4KB 단위가 되도록 한 다음에 I/O request를 한다. 이럴거면 왜 만든거냐고? 뭐 언제나 4KB나 write가 buffer되는 것은 아니니까... -
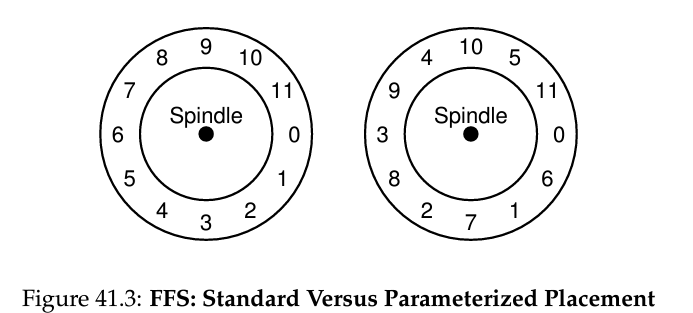
또 디스크의 물리적인 읽는 방식 때문에 disk layout상에 연속된 block을 연속해서 배치를 하면 연속된 read를 할 때 오래 기다려야 하는 불상사가 발생하게 된다. (0 읽은 후 1을 읽으려고 할 때 이미 지나가는 중이어서 다시 한바퀴를 돌아 1의 시작 지점으로 돌아야하기 때문) 그래서 이를 고려해 연속된 block들이 disk layout 상에서 띄엄 띄엄 있도록 배치한다. 아니 심지어 디스크별로 어느정도 간격을 둬서 배치해야 이를 방지할 수 있는지 파악하는것도 가능하다. (parameterization)
-
물론 이러면 결국 아무리 좋아도 전체의 50%정도의 시간만을 유의미한 읽는 시간으로 취급할 수 있는 문제점이 있다. 하지만 그것도 걱정마시라, 사실 현대 디스크는 그냥 미리 track을 통째로 읽어서 캐싱한다음에 (track buffer이라고 불린다) 나중에 file system 측에서 요구하면 이를 제공해준다. 굳이 file system 측에서 이러한 low level detail을 신경 쓸 필요가 없어졌다는 뜻 (추상화의 좋은 예시)
-
긴 파일 이름도 FFS부터 가능해졌다. 원래는 파일 이름 길이가 제한이 있었는데 이를 없앰.
-
이전 글에 설명한 symbolic link와 atomic rename도 여기서 생겼다.
