File System Implementation
OS related
- 이 글은 무료 OS 관련 책인 Operating Systems: Three Easy Pieces의 40단원, File System Implementation을 정리한 것입니다. 책의 내용을 잘못 이해한 정보가 있을 수도 있으니 의심되면 원본 내용을 확인해주세요.
- 이미 OS에 대해 전반적인 지식이 있는 분들을 위한 정리 글이라 처음이면 이해가 힘들 수도 있습니다. 이 경우 책을 정독하는걸 강력 추천합니다.
-
현실에서 File system 구현은 어떻게 이루어지는지 가장 간단한 형태부터 알아가는 단원이다. 이후의 몇몇 단원들도 이에 관한 내용이다.
-
File System 구현시에 주목해야할 두가지 요소는 다음과 같다. 기억하도록 하자.
- file system에서 data(file)/metadata를 관리하는데 사용할 자료 구조를 무엇으로 하는지
- 시스템 콜을 프로세스가 호출할시 file system 내 자료구조 중 어떤 녀석들이 읽히고 조작되는지
-
이 단원에서는 vsfs (very simple file system)의 구현 방식에 대해 알아볼 것이다.
Overall Organization
-
먼저 디스크 내 데이터들을 특정 단위로 나눈다. 이를 block이라고 한다. 좀 더 자세한 내용은 이걸 참고. block의 크기는 file I/O 관련 성능에 직접적인 영향을 많이 미치며 무슨 file system을 쓰는지, I/O pattern이 어떤지 등의 상황에 따라 최적의 크기가 다르나 보통 4KB를 쓴다. 구체적인 동작 방식이 궁금하면 이걸 참고
-
책에서 간단하게 예시로 든 file system은 다음과 같은 구조를 가진다. (disk를 64개의 block으로 나눴다고 가정)

- data region : 파일 보관 공간
- inode table : 파일 관련 메타데이터(inode) 보관 공간. 이전 단원에서 봤듯이 inode는 보통 block 하나를 통째로 차지할 만큼의 공간이 필요 없고, 여기서는 256byte를 쓴다고 가정해서 위의 경우 총 80개의 inode 보관이 가능하다고 생각하면 된다.
- allocation structure : data region / inode table의 occupation 확인 공간. linked list 등 여러 형태로 구현이 가능한데 여기서는 bitmap으로 구현했다. block이 4KB이므로, 저렇게 할당시 각각 32K개의 공간에 대해 occupation 확인이 가능하다.
좀 과하지만 - superblock : 파일 시스템 관련 메타 데이터 보관 공간. (inode/data block 개수, inode table 시작 위치, data block 시작 위치, file system 종류 등) OS에서 마운트를 할 때 제일 먼저 읽는 block이기도 하다.
File Organization: The Inode
-
index node의 줄임말. 역사적인 이름인데, 원래 이 node들이 배열 형태로 존재를 했고 특정 메타데이터 접근을 할 때 배열에 '인덱싱'을 해야 했기 때문에 그렇다고... 이 때 인덱싱하는데 사용되는 숫자가 inode number(i-number, low level name)이다.
-
앞에서 간단하게 만든 파일 시스템의 경우 inode table이 밑과 같은 구조를 가진다.
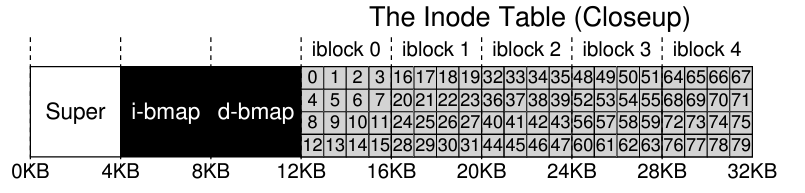
-
유의할게 file system에서 읽을 위치가 판별이 되어도 해당 디스크에 요청을 할 때는 그 주소의 위치만 딱 읽는 것이 아니라, 디스크에서 관리하는 sector 단위로 읽어야 한다. (이는 file system에서 관리하는 logical block이랑 또 다른 단위다.) 책에 나온 밑의 계산식 참고

- 간략화된 Inode 보유 data는 밑의 그림 참고

- 사실 여기서 우리가 집중하고 싶은것은
block이라는 요소다. 이건 해당 inode가 나타내는 파일이 디스크 어디에 위치하는지를 가리키는 pointer들의 모임으로 위의 경우 총 15개의 pointer을 보유가 가능하다. 각각은 특정 data block의 위치를 가리킬 것이다. 하지만 만약 파일의 크기가 15 * 4KB의 크기보다 크다면? 어떻게 접근을 할 수 있을까?
The Multi-Level Index
-
앞의 문제에 대한 여러 해결책이 있으나 여기서는 indirect pointer을 활용한 해결책에 대해 알아보자.
-
먼저, 작은 크기의 파일에 대해서는 굳이 여러개의 pointer을 보유할 필요가 없다. 저 15개의 pointer로도 충분할거다. 대신 파일의 크기가 커지는 경우 더 많은 pointer을 보유하도록 하고 싶다. 이 경우 저 15개의 pointer 중 일부가 가리키는 data block에 또 pointer들만을 보관하는 것이다. pointer을 보관하는 data block을 가리키는 pointer을 indirect pointer이라고 한다.
-
현재 block의 크기가 4096이므로 이 경우 1024개의 pointer을 추가로 보유하는 것이 가능하다.
-
앞에 말했듯 작은 크기의 파일은 굳이 여러개의 pointer을 보유할 필요가 없어서 보통 처음 몇개의 pointer이 사용되면 그 후의 pointer들이 indirect pointer이 되도록 구현을 한다. 책의 경우 처음 12개. 그러면 1036개의 pointer이 있다고 가정시 가능한 최대 파일 크기는 4144KB (대략 4MB)
-
double/triple indirect pointer도 있다. pointer이 가리키는 data block이 pointer들 보관하는 곳이었는데, 거기의 pointer이 가리키는 dta block도 pointer들을 보관하는 곳인거지. 이를 multi-level index라고 한다.
-
앞에서 처음 12개는 일반 pointer이고, 그 후 하나의 pointer이 double indirect pointer이라면 파일 하나의 최대 크기는 (12+1024+1024^2) * 4KB로 대략 4GB가 된다.
-
triple이라면 (12+1024+1024^2+1024^3)*4KB로 대략 4TB가 된다.
-
보통 file system 내 파일들의 크기가 대체로 작기에 대부분의 시스템에서 차용하는 구조는 아까 말했듯 처음 몇개는 direct pointer이고 그 이후가 indirect pointer의 형태를 가지도록 하는 것이다. 최근 경향성은 밑의 표 참고

Extent-Based Approach
-
포인터를 사용하지 말고 extent를 사용해도 된다. (포인터 + block 길이. 해당 위치를 시작으로 몇개의 block이 inode 관련 data인가)
-
다만 연속해서 block을 찾는 것이 언제나 쉽진 않으므로 하나의 extent만으로 충분하진 않아 이것도 여러개의 extent가 필요하다.
-
장점 : pointer 대비 metadata 양이 적음.
-
단점 : 덜 유연한 파일 할당.
Linked-Based Approach
-
linked list를 사용한다. inode에 하나의 pointer만을 보유, 거기가 inode 관련 파일의 첫번째 data block을 가리키고 각 data block마다 다음 data block의 pointer을 보유하게 하는 것이다.
-
단 마지막 block의 접근, 혹은 랜덤 접근에 쥐약인 성능을 보여준다. 이 때문에 data block에서 다음 pointer을 보유하는게 아니라 각 block의 주소를 기반으로 indexing하는 in-memory table을 따로 만드는 방법이 있다. 그러면 시작 block의 주소를 기반으로 메모리에서 다음 주소를 계속 찾다가 원하는 block이 나오면 그걸 가져오면 된다. 이를 활용하는 file system을 file allocation table (FAT) file system이라고 한다.
-
참고로 FAT file system의 또다른 큰 차이점은 inode가 없고, 대신 directory entry에서 파일에 대한 정보 뿐만이 아니라 각 파일의 첫번째 block 주소를 보유한다. 이는 hard link를 구조적으로 불가능하게 만들기도 함.
Direcotry Organization
- 디렉토리 구조는 그렇게 복잡하진 않다.

-
reclen은 현 record의 크기를 나타낸다. 파일을 삭제시 각 record가 비게 될 수 있고, 그 후에 추가로 또 파일이 들어갈 수 있는데 얼만큼 삭제가 된건지, 또 새로 들어온 파일이 사용할 수 있는 공간이 얼마나 되는지를 표기하는데 사용되는 attribute다. -
inum은 inode number,strlen은 하위 파일 이름 길이,name은 하위 파일 이름 -
이전 글에서 봤듯이 디렉토리를 일반 파일과는 다른 특별한 파일로 취급하지만, 보관은 data block에서 하며 이와 연결된 inode file도 존재를 한다. 추적 자체도 일반 파일이랑 크게 다르지 않음.
-
다만 directory 내용물이 든 data block의 구조가 꼭 linear list일 필요는 없다. B-tree 형태일 수도 있음.
Free Space Management
-
사용안되는 inode/data block을 추적 및 관리하는 것도 매우 중요하다. vsfs의 경우 bitmap을 활용하며 초기 파일 시스템은 첫번째 free block을 가리키는 pointer을 superblock에 집어넣어서 linked list 형태로 관리하는 free list를, 현대 파일 시스템은 B-tree 형태로 관리하는 등 file system에 따라 방식이 다양하다.
-
단순히 free block이 어디 있는지를 탐지하고 이를 allocate, 혹은 free 시킬 block을 추적해 이를 free하고 갱신하는것 뿐만 아니라 다른 다양한 정책을 가질 수도 있다. 예를 들어 pre-allocation이라고, 처음 파일이 생성 될 때 최소 몇개의 연속된 block이 free되어 있는 부분을 찾아서 그 부분을 통째로 할당해 생성되는 모든 파일이 처음 몇개의 block 크기는 디스크상에 연속으로 존재하는 것을 보장하는 것이 있다. 이러면 성능에 도움이 많이 된다.
Access Paths : Reading and Writing
-
read/write를 할 때 접근이 어떻게 이루어지는지에 대한 과정을 Access path라고 한다.
-
/foo/bar을 읽을 때 일어나는 접근 과정은 밑과 같다. (open에서O_RDONLY를 썼다고 가정)
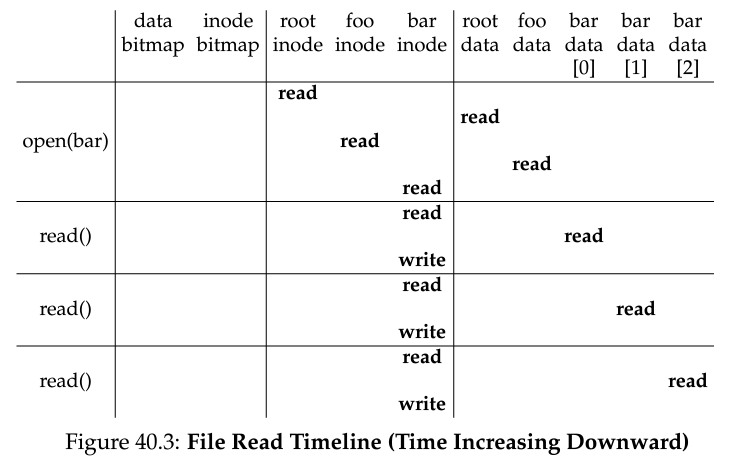
-
직관적이기에 자세한 설명은 생략. 단,
read마다 마지막에bar관련 inode에 write를 하는 이유는 마지막 접근 시간을 갱신하기 위해서다. -
/foo/bar에 무언가를 작성할 때 일어나는 접근 과정은 밑과 같다.
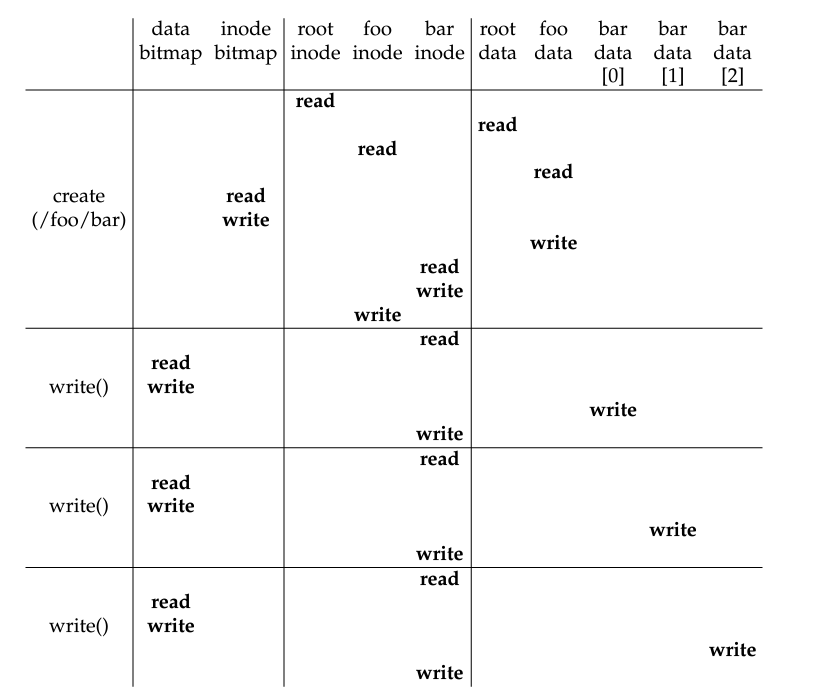
-
write의 경우 overwriting을 하는 경우가 아니면 덧붙이거나 아예 파일을 새로 생성하는 과정에서 allocation이 필요할 수 있으며, 위의 경우
/foo/bar이 애초에 존재하지 않는 경우를 가정해서 단계를 설명한 것이다. 일단foodata를 읽어야 이 파일이 존재하지 않는걸 알 수 있으니 거기까진/foo/bar을 읽는 경우와 동일. 이후inode bitmap을 read (free인 block을 찾기 위해) 및 write (allocate 정보를 입력)한다. -
이후
foo data에 write를 하는 이유는foodirectory file에다가bar관련 directory entry를 기입하기 위해서다. 이후barinode를 read 후 write하는 이유는barinode의 initialization을 위해서다. 마지막으로fooinode에 write를 하는 이유는foodirectory file 관련 메타데이터도 바꿔졌기 때문에 이에 대해서도 업데이트를 해야 하기 때문. 심지어 만일foodirectory file 자체도 확장이 필요하면 그만큼 추가적인 I/O가 data bitmap이랑 새로운 directory block에 대해 필요하게 된다... -
단순 파일 생성에만 이정도의 작업이 필요하며, write작업을 할 때마다 먼저
bar의 inode를 읽고, append를 하는 경우라면data bitmap를 읽어서 갱신하고 (read/write), 실제로 data를 쓴 다음에bar의 inode를 갱신하면서 총 5번의 I/O 작업을 하는 것을 볼 수 있다. write 작업을 할 때마다.
Caching
-
여러번 disk를 왔다 갔다하는 것을 방지하기 위해 중요 block들은 보통 DRAM에다가 캐싱한다.
-
고정된 공간이 있으며, LRU와 같은 알고리즘을 통해 꽉 차면 어떤 block을 제거하고 다른 애를 캐싱할지도 정한다.
-
옛날 파일 시스템의 경우에는 고정적으로 총 메모리의 10%를 캐싱에 썼지만, 사실 파일 시스템이 그만큼의 캐싱을 필요로 하지 않으면 오히려 손해다. 그래서 요즘은 dynamic partitioning을 쓴다. 정확히는 VM의 page와 file system의 page를 위한 page cache를 통합해서 운영한다. 그리고 둘 중 누가 더 필요한지에 따라 사용률을 조절.
-
static 장점 : 보장된 성능, 구현이 어렵지 않음, 단점 : 유동적이지 않음
-
dynamic 장점 : 뛰어난 유동성, 단점 : 성능이 일정하지 않을 수 있음, 구현이 복잡함.
-
자주 접근하는 inode 및 파일(data block)의 경우에는 caching된 data를 통해 여러번의 disk I/O를 하는 것을 방지하는게 가능하다.
Buffering
-
write의 경우 buffering을 통해 무차별적인 I/O를 방지한다.
-
write 호출이 있을 때마다 내용물을 disk에다가 작성하는게 아니라 모아놓았다가 한번의 I/O로 작성을 하는 것이다. 이 때 같은 파일에 대해서 여러번의 조작이 있을 때 생길 수 있는 I/O 낭비를 장지하는 것도 가능하다.
-
buffer 된 data가 일정 임계점을 넘을 때 본격적으로 disk에 접근을 해서 작성을 하게 된다.
-
일부 무의미한 작업의 경우 (파일 작성 직후에 다시 삭제) 애초에 파일 생성된 것이 디스크에 반영되지 않는 형태로 무의미한 disk I/O가 발생하지 않도록 방지한다.
-
물론 이 버퍼링이 장점만 있는 것은 아니다. 메모리에 임시로 저장해놓는 것이라서 만일 디스크에 반영되기 전에 컴퓨터가 갑자기 꺼져버리면 저장해놓은 내용물들이 다 날라가는 불상사가 생긴다. 메모리에 두는 시간이 길어질수록 I/O 효율이 좋아질 수 있지만 이 위험성이 더 커지게 된다. (durability/performance trade-off)
-
만약 어떤 애플리케이션에서 위와 같은 도박을 하길 원하지 않으면
fsync()를 호출하면 된다. DB에서 보통 이런다.
