- 졸업 연구 전 과제로 알아보라고 해서 알아본 것들을 정리
File Indexing
-
기존의 파일 시스템 내에서 파일을 찾는 방법은
- 경로가 주어지고
- File system과 관련된 superblock을 먼저 참고해 최상위 경로와 관련된 inode의 위치를 파악하고
- 그 inode를 기반으로 data block을 읽어내서 다음 하위 경로에 해당하는 inode의 위치를 파악
- 이 과정을 재귀적으로 반복하다 원하는 파일의 inode에 도달했을 때, 이를 기반으로 파일 관련 data block을 전부 취득.
-
위의 과정을 매 파일 접근마다 수행하는 것은 매우 느리다. 그래서 읽기의 경우 스토리지로 가는 I/O 회수 자체를 줄이려고 애쓰고(캐싱), 쓰기의 경우 스토리지로 가는 I/O 한번마다 수행하는 작업을 극대화하려고 한다.(버퍼링)
-
여기까진 좋다. 그런데 위 탐색을 수행하려면 파일의 절대 경로를 알아야 한다. 아니면 현 작업경로 기준 상대 경로라도 정확히 알아야 한다. 개발자나 컴퓨터 지식이 어느정도 있는 사람들이라면 이를 정확히 파악할 수 있을 것이다.
-
하지만 숙련된 개발자라도 파일 시스템의 계층 구조가 복잡해지면 절대 경로 파악이 힘들 수 있다. 하물며 별다른 지식이 없는 일반적인 PC 사용자라면 절대경로/상대경로를 외울 확률이 매우 적다. 이런 상황에서 파일 이름 전체 혹은 일부분만 알고 있다면 어떻게 해야 할까? 아니면 안 사용하는 파일을 삭제하기 위해 특정 시점 이후로 수정되지 않은 파일들을 전부 찾고 싶으면? 동영상만 찾고 싶다면?
-
이외에도 이 글의 초반 부분을 보면 특정 조건을 만족하는 파일들을 찾는 기능을 많이 필요로 했고, 파일 시스템 차원에서 이를 지원하기 전에 프로그램 차원에서 제한적으로 이 기능을 제공했다는 것도 알 수 있다.
-
이처럼 특정 조건을 만족하는 파일들을 찾는 것을 file indexing이라고 할 수 있고, 위의 글에서 제안한 것처럼 파일 시스템에서 이 기능을 제공하는 시도가 많이 이루어졌다.
구현시 고려해야할 부분
-
가장 단순하게 이를 구현하는 방법은 파일 시스템 전체를 탐색해서 조건을 만족하는 파일들을 제시하는 것이다. 이는 매우 느릴거다.
-
이 방식을 약간 개선하면 파일 시스템 내 파일들의 메타 데이터(inode)들만 전부 탐색해도 된다. 메타 데이터를 전부 메모리에 로드하고 일일이 탐색을 하는 것인데, 여기서 생각할 수 있는 문제점은
- indexing에 도움이 되지 않는 메타데이터들도 전부 load를 하게 된다.
- 기존에 inode에 저장한 데이터들만이 검색에 도움이 된다고 볼 순 없다. inode에 저장하지 않았던 또다른 메타데이터를 가지고 indexing을 해야 할 수도 있다.
- 특정 자료 구조 없이 단순 메모리에 load 후 순차적으로 탐색을 하면 시간이 비효율적이다. (O(N), N은 메타데이터 개수/파일 개수)
-
그래서 만일 파일 시스템에서 indexing 기능을 추가할거면
- indexing에 활용할 수 있는 field(key)들을 파일 시스템 차원에서 미리 지정하고
- 각 field(key)들을 파일이 생성될 때마다 특정 값으로 채우고
- 각 field들을 특정 자료구조의 형태로 관리를 해서 추후 indexing을 할 때 빨리 찾을 수 있는 환경을 만들어야 할 것이다.
-
그 외에도
- field(key)값들을 수정할 권한이 누가 있고 없는지를 관리해야 할 것이다.
- 파일을 생성/수정한 측에서 명시하지 않았을 때 각 field(key) 값들을 무엇으로 설정할지에 대한 기본 규칙을 파일 시스템이 가져야 할 것이다.
- 파일이 수정된 후에 해당 파일과 관련된 field(key) 값들 중 일부가 수정되었을 경우 이를 즉시 반영해야 할 것이다.
- 사용자가 indexing을 쉽게 활용할 수 있는 UI/명령어 구조도 생각해 봐야 한다.
-
또 이 기능을 구현하면서 생길 수 있는 단점도 고려해야 한다.
- indexing을 위한 자료 구조를 구축하기 때문에 메모리를 좀 더 사용해야 한다.
- close된 파일에 대한 처리 과정에서 해야 하는 일이 늘어나게 된다.(computation overhead) close된 파일의 새로운 내용 및 상태 변화를 기준으로 indexing에 사용되는 자료 구조를 갱신해야 하기 때문. 파일 탐색보다 파일 수정이 더 많이 이루어지는 경우 이 단점이 장점 이상으로 큰 문제를 일으킬 수 있다.
활용 자료 구조
- DB에서의 indexing에서 사용하는 자료구조들을 여기서도 많이 사용한다.
B-tree
-
Balanced Tree의 약자.
-
자료 구조의 성향을 결정하는 변수로 각 node당 최대 children 개수가 있다. 그 외에도 여러 제약 조건이 있으며 자료가 삽입 및 삭제가 될 때 수행해야 할 단계까지 세부적으로 설정해 가급적 자료들이 잘 '분포'되어 tree의 높이가 너무 깊어지는 것을 방지, 이를 통해 삽입/삭제/탐색 등의 작업이 O(logN)의 작업을 가지도록 유지하는데 특화된 자료구조다.
-
활용하는 File System으로 Windows의 NTFS가 있다.
-
자료구조에 대한 더 자세한 내용은 다음 문서 참고
B+tree
-
B-tree의 각 node는 key에 대응되는 value들도 node에서 보관하고 있다. (File system의 경우, 해당되는 파일 이름이 여기에 해당할 수 있음)
-
하지만 B+tree의 경우 internal node에서는 key들만을 보유하며, value를 보관하는 node가 leaf node라고 따로 존재한다. 이 leaf node들은 또 single linked list 형태로 서로 연결되어 있다.
-
자료구조에 대한 더 자세한 내용은 다음 문서 참고
DB Indexing과의 비교
공통점 (비슷한점)
-
먼저 둘이 추구하는 목표는 비슷하다. 특정 조건을 만족하는 파일 / 특정 조건을 만족하는 record를 빠르게 찾는 기능을 제공하는 것.
-
이를 현실적으로 구현하기 위한 대략적인 구상도 비슷하다. 각 파일/record에 특정 key를 붙이고, 이 key를 기준으로 자료구조를 형성해서 빠르게 탐색할 수 있는 환경을 만드는 것.
차이점
-
파일의 빠른 탐색을 위한 key를 지정할 때는 보통 파일의 내용물보다는 파일과 관련된 메타데이터가 사용된다. (파일 이름, 파일 마지막으로 편집된 시간, 파일 형식 등) 반면 record를 위한 key는 보통 record의 내용물인 field 중 하나를 가지고 사용한다.
-
File Indexing의 경우 탐색 범위가 file system 전체, working directory, 혹은 working directory 및 하위 directory가 된다. 반면 DB Indexing의 경우 특정 테이블이 탐색 범위가 된다. 특정 테이블 내의 일부분이나 DB 전체가 탐색 범위가 되는 일이 없다.
-
앞에서 두 indexing의 목적이 비슷하다고는 했지만 그 활용이 약간 다른데, file indexing은 특정 조건의 파일을 찾는 것 자체가 목적인데 DB indexing은 이를 기반으로 query 처리를 효율적으로 하는 것을 목표로 가지고 있다.
-
File indexing은 Windows의 경우처럼 OS에서 key를 제공하는 경우 제공하는 key들 중 무엇을 indexing에 사용할지/안할지는 지정이 가능하나 사용자가 OS에서 활용할 key를 직접 추가하거나 제거하는 것은 힘들어 제약이 좀 더 있다. 그래도 제3자 프로그램에서 제공하는 경우에는 key를 무엇으로 설정할지를 좀 더 자유롭게 조절하는 것이 가능하다. (Linux의
mlocate,updatedb의 경우/etc/updatedb.conf이라는 configuration 파일을 통해 지정)
DB의 indexing에 활용할 key는 DB 관리자가 직접 지정하는 것이 가능하다. 대신 조심해야 하는 것이 table 내 어떤 field를 key로 지정했는지, 해당 table에서의 read/write 작업의 비중이 어떤지 및 사용하는 DBMS에서 indexing에 활용하는 자료구조에 따라 관련 성능(query)이 좋아지거나 안 좋아질 수 있다. 궁극적인 목표가 효율적인 query 처리라는 점을 생각할 때 key의 선정에 신중해야 함을 알 수 있다.
일반적인 File 탐색에 활용될 수 있는지에 대한 여부
-
조사를 하다보니 든 생각은 특정 조건을 만족하는 file을 찾기 위해 indexing을 활용하는것을 넘어 해당 자료구조를 활용해 절대 경로가 주어진 경우에 파일을 찾는데도 활용할 수는 없는지 궁금해졌다.
-
실제로 위키피디아의 B+tree의 활용 예시를 보면 file system의 메타데이터 indexing, 디렉토리 indexing에 활용된다고 하며 APFS (Apple File System)의 경우 아예 filesystem 내 객체의 ID와 그 객체가 디스크 상에 있는 위치를 저장할 때 B+tree(다만 reference에서는 B-tree로 표현하고 있다)를 활용한다고 한다.
-
이것이 학계에서 얘기하는 file indexing에 해당되는지는 개인적으로 애매하다. 하지만 해석에 따라 가능하다고 보는데, 파일의 절대 경로를 key로 생각해서 indexing을 해 파일 위치를 찾는다면 이것도 file indexing으로 볼 수 있다고 생각한다. 다만 file indexing의 원래 목표(?)로 제시된 파일의 일부 이름 혹은 편집 시간 등을 가지고 파일을 찾는거랑은 거리가 있다고 생각한다. 여하튼 file indexing을 활용해서 파일 탐색을 할 순 있다고 본다.
extent tree
-
Ext4 file system에서 활용하는 자료 구조다. Extent에 대한 tree여서 extent tree라고 한다.
-
Extent는 실제 물리적인 disk에서 연속해있는 block들의 모임이다. 이것의 장점은 첫 block 기준 일정 범위가 같은 파일의 내용물을 가진다는것을 보장해서 하나의 block마다 mapping을 할 필요가 없어서 mapping 개수가 더 줄어든다는 것이다.
-
사실 이 자료구조가 file indexing이랑 관련있어 보이진 않지만나 파일 탐색과 관련된 자료구조를 찾다보니 알게 되어서 잠깐 언급. 더 자세한 내용은 이 링크 참고
File Indexing 대표 활용처
1. Windows Search (NTFS, Windows)
-
$INDEX_ROOT와$INDEX_ALLOCATION이라는 attribute를 활용한 B-tree 구조를 통해 file indexing을 구현한다. -
이 attribute로 이루어진 B-tree의 depth는 추상적으로 2층까지만 가능하며, 첫번째 층인 root는 고정된 node 개수만 보유가 가능, 그 이후의 node들은 전부 Non-Resident Attribute의 형태로 B-tree의 추상적인 두번째 층에다가 보관을 한다.
-
구체적인 형식은 이 링크 참고
-
윈도우에서 제공하는 이 File Indexing은 UI상으로는 Windows Search 및 파일 탐색기에서의 검색 도구가 해당된다. 해당 UI들은 일반 사용자가 활용하기 매우 직관적인 UI를 가지고 있다. 또 여러 종류의 key들을 제공한다. (수정 날짜, 파일 종류, 파일 크기, 파일 태그 등)

-
다만 OS에서 지정한 indexing에 사용할 key 외의 key들을 지정하는 것이 불가능하고 세부적인 동작 방식을 조절하는게 힘들다. File indexing 기능을 끄는 기능은 있지만, 이럴 경우 추후 파일 탐색 기능을 사용할 때 시간이 엄청 오래 걸리는 단점이 있다.
-
File indexing을 위한 index structure을 구성하는데 초기 시간이 좀 오래 걸린다는 단점도 있으나, 이후 수행할 파일 탐색 기능의 유용성을 생각하면 감당할만한 단점이라고 생각한다. 개선의 여지는 있을 수 있지만 말이다. 다른 파일 시스템의 file indexing도 처음에 이 자료구조를 구축하는데 시간이 오래걸려서 이 파일 시스템만의 단점이라고 보기도 힘들다.
-
또 다른 단점은 NTFS의 file managing 방식이랑도 연관이 있다. NTFS은 MFT (Master File Table) 이라는 파일을 통해 디스크 내 파일들을 관리한다. 하나의 MFT 파일마다 MFT entry 및 data area가 존재하는데, 여기서 각 Entry마다 Attribute라는 영역이 존재한다. 이 Attribute들 중 가능한 것이 앞에 말한
$INDEX_ROOT와$INDEX_ALLOCATION이다. 자세한 구현 설명은 이 글 참고. 여기서 중요한건 NTFS에서 file indexing에 핵심적인 자료구조인 index root와 을 이와 같이 구현했기 때문에 file system에서 관리하는 파일들의 양이 많아질수록 indexing과 관련된 파일들이 파편화가 심해지고 관리가 복잡해질 확률이 높아진다는 것이다.
2. Spotlight (APFS, Apple)
- 맥의 경우
Spotlight가 일반 사용자를 위한 file indexing 기능으로 작용한다.
필자가 맥을 사용한적이 없어서 (...) 직접 사용해보면서 장단점을 파악하기 힘들어 부정확할 수 있다는 점 참고 바랍니다.
-
관련된 파일 시스템은 APFS인데, APFS Reference 122pg에 따르면 B+tree가 변형된 형태의 구조를 구현해놓았다. B+tree의 변형인 이유는 leaf node들을 서로 연결하는 pointer이 존재하지 않기 때문. 이는 개인적으로 DB에서 순차적으로 data를 탐색하는데에나 의미있는 구조고 파일 시스템에서는 상대적으로 얻는 이득이 적어서 그러는 것이라고 개인적으로 생각하고 있다.
-
다만 디렉토리 내용물이나 메타데이터를 찾는데 B+tree를 활용한다는 내용을 위키백과에서 출처로 밝힌 책에서만 찾을 수 있었고 구체적으로 Spotlight에서 indexing을 어떻게 하는지에 대한 정보를 찾을 수는 없었다.
-
앞에 소개한 Windows에서의 indexing 대비 가지는 특징중 하나로 특정 영역에 대한 indexing을 아예 구성하지 않는게 가능하다. 물론 Windows에도 숨김 파일 등이 존재는 하나 이거는 일반적인 접근에서도 보이지 않게 막는 것인 반면, 소개한 기능은 Spotlight에서의 검색으로만 나오지 않도록 방지한다는 특징이 있다. 사용자 입장에서 더 세부적인 조작을 가능하게 해주는 것이다.
-
그리고 Windows에서 파일 탐색기에 있는 '파일'에 대해서만 탐색하는 것이 가능한것과 달리 앱 안에 있는 내용물들에 대해서도 indexing이 가능하다는 특징이 있다.
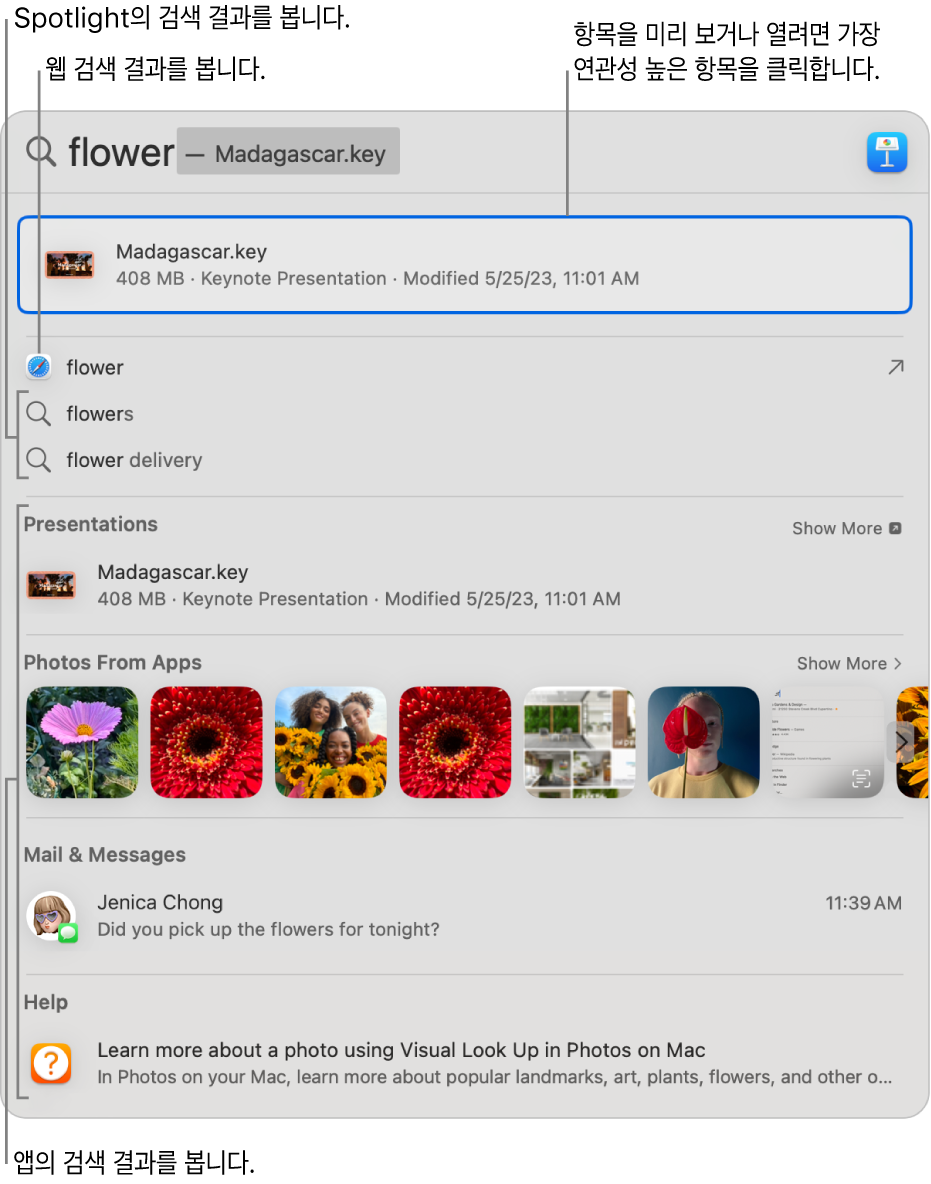
- 단점으로는 파일 시스템 자체의 문제점으로 SSD에 최적화되어 있고 HDD에서는 성능이 그렇게 좋지 않다는 것이다. 하지만 이건 파일 시스템 자체의 문제고... Spotlight indexing 자체의 문제점은 찾지를 못했다.
3. find (Linux)
-
Linux에는 파일 탐색과 관련된 기본 명령어인
find가 있다. 문제는 이게 기본 설정으로는 재귀적으로 DFS 형태로 파일을 탐색한다는 것이다. 하위 디렉토리에서 디렉토리를 만나면 그 디렉토리를 따르는 형식으로. 물론 여러 설정을 통해 시작 지점을 지정하거나 세부 설정을 하는 것이 가능하지만 이게 앞에서 본 file indexing 관련 기능 대비 UI가 엄청 좋다고 보기도 힘들고, 속도 또한 indexing을 위한 자료 구조를 따로 설정한 것도 아니라서 별로다. -
하지만 file system에서 운용하는 파일이 적은 경우, 아니면 애초에 검색을 시작하는 directory의 하위 구조가 그렇게 복잡하지 않은 경우에는 속도 문제가 크게 없고 오히려 따로 indexing 관련 자료 구조를 보관하지 않아 용량 측면에서의 overhead가 없다는 이점이 있다. 특히 속도가 너무 걱정이라면 미리 최대로 탐색할 깊이를
-maxdepthoption을 통해 설정하는 것도 가능하다. -
그리고 UI가 별로라고는 하지만 명령어를 잘 활용할 줄 알면 별의 별 검색 조건을 가지고 파일을 찾는 것이 가능하다. 특정 이름을 가진 파일은 물론 권한, 접근 시간, 편집 시간, 아무것도 안 적혀 있는 파일/디렉토리, 확장자 등등.
4. mlocate / updatedb (Linux)
- 또다른 indexing 관련 명령어로는
mlocate(locate)와updatedb가 있다.
-
위 링크에 소스코드도 함께 나와 있는데, B-tree/B+tree를 활용하지 않고 경로를 압축해가지고 순서를 가지는 list 형태로 저장을 한다.
updatedb의 호출을 통해 파일 시스템에 있는 모든 파일 정보들을 읽어서 index를 형성해야mlocate사용이 가능해진다. -
파일 시스템 구조에 변동이 생기면 다시
updatedb를 통해 index를 형성해야 한다. 이 때문에mlocate를 설치하면 바로 cron daemon에 특정 주기로updatedb를 호출하도록 예약이 걸린다. 이것이 앞의find는 물론 다른 file index와 비교 했을 때 많이 번거로움을 일으킨다. -
대신
find대비 더 빠른 탐색이 가능하다. indexing용 자료 구조를 형성했기 때문. 하지만 그만큼 용량을 먹는것도 마찬가지.
글에 언급 안 된 출처
1. File system Indexing, and Backup - Jerome H. Saltzer
2. [Database] 인덱스(index)란? - 망나니개발자
3. File System Forensic Analysis : Indexes - Brain Carrier
