게을러터진 은영이... 지금 3주차 수요일인데 module4 이제야 봄 심지어 다 보지도 않고 절반만 봄
포스팅 내용에 대한 저작권은 모두 LG Aimers에 있습니다.
딥러닝이란?
입력 <-> 출력 사이 관계를 본 따 학습 모델을 만드는 머신러닝 중, 두뇌 신경 세포 모습을 모방한 기술로 뉴런 네트워크를 여러 층 쌓은 모델을 말한다.
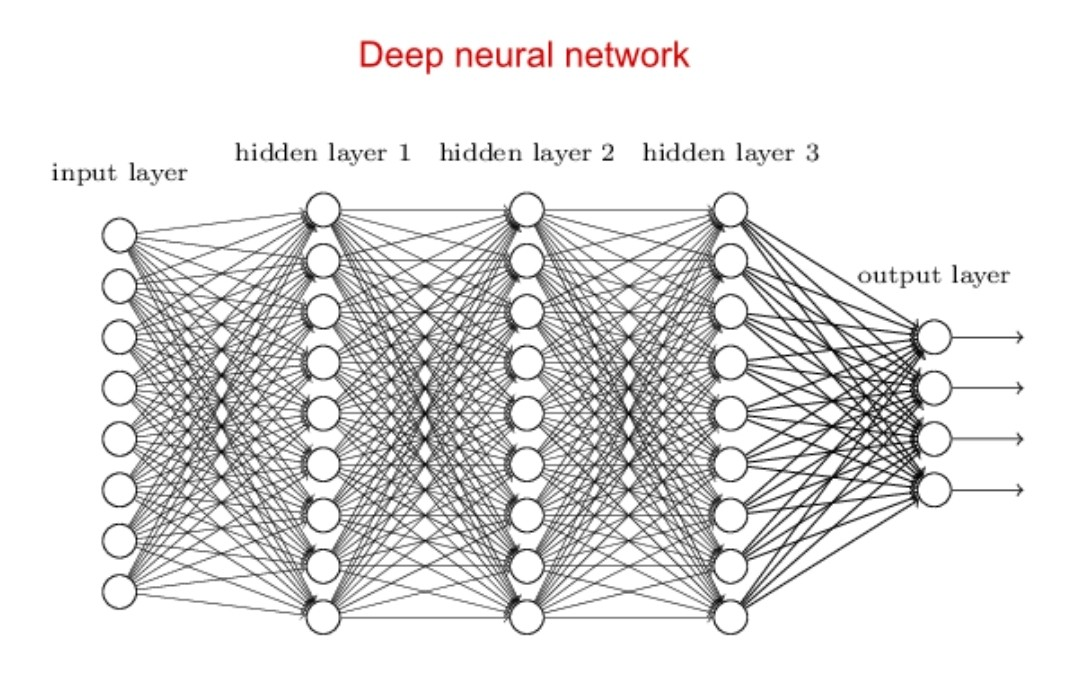
출처:LGAimers module4 딥러닝 강의 자료
딥러닝을 성공적으로 학습시키기 위해서 필요한 요소
- 빅데이터
- GPU
- 개선된 알고리즘
퍼셉트론이란?
신경망 중 하나로 다수의 입력을 받아 하나의 출력을 갖는 알고리즘 , 뉴런의 구조와 유사하다.
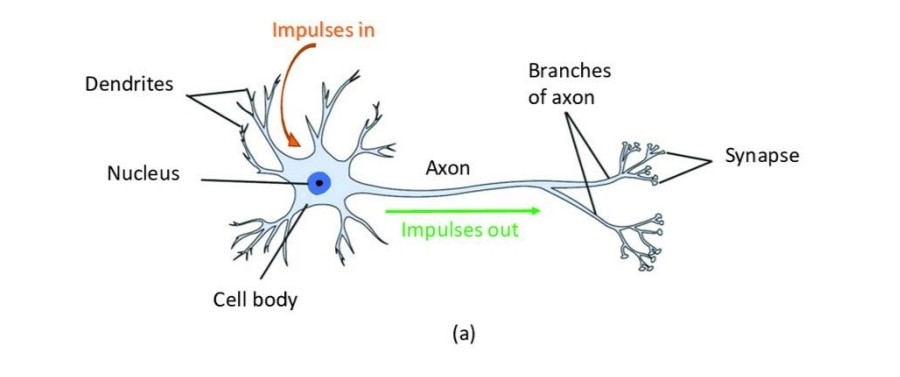
사람의 뉴런 구조
출처:LGAimers module4 딥러닝 강의 자료
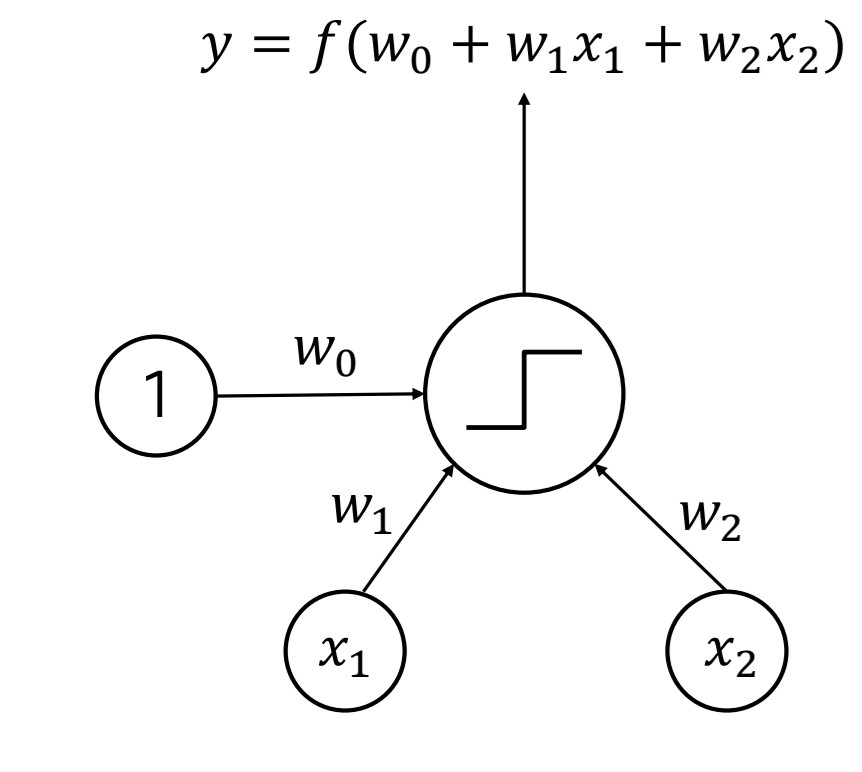
출처:LGAimers module4 딥러닝 강의 자료
위 이미지는 퍼셉트론 동작 과정으로
x1, x2는 각각 input, w0,w1,w2는 각각의 가중치이다. 여기서 w0은 바이어스 역할. 그리고 가중치와 입력데이터들의 합을 활성함수(여기서는 계단 함수)에 넣어 출력 값 y를 결정한다.
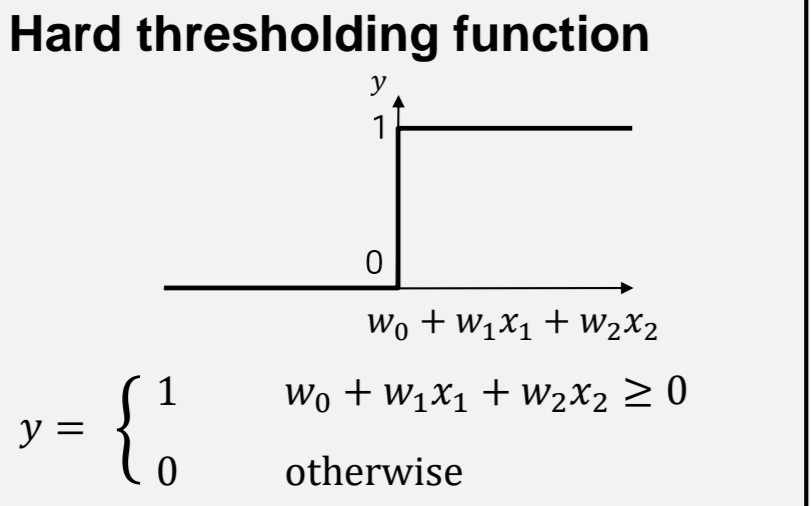
출처:LGAimers module4 딥러닝 강의 자료
계단 함수의 경우 입력된 값이 0보다 같거나 클 경우 모두 1, 0보다 작을 경우는 모두 0을 출력한다.
위 모델에서 가중치 값을 어떻게 주냐에 따라 and, or게이트 만들 수 있다. 그렇다면 1개의 선형 모델로는 분류가 어려운 xor 게이트는?
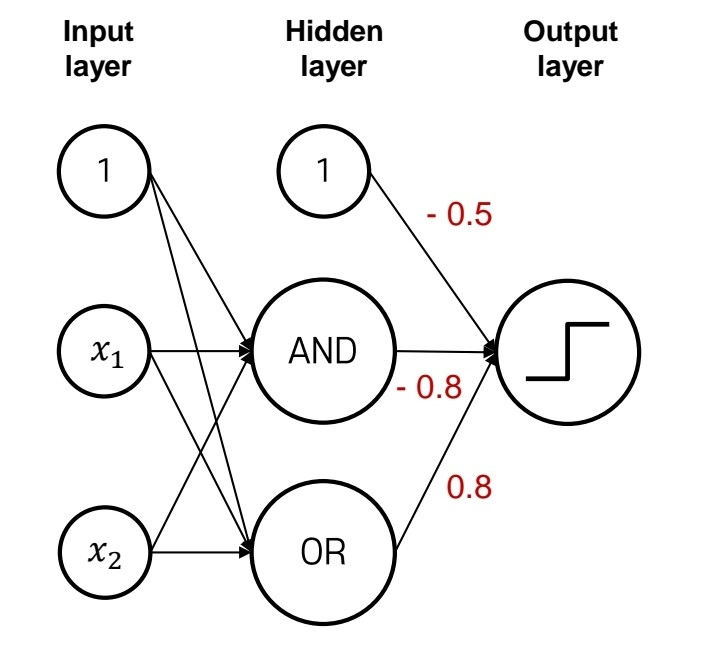
출처:LGAimers module4 딥러닝 강의 자료
위 그림처럼 히든 레이어 안에 and게이트, or게이트 역할을 하는 뉴런을 포함시키고 위와 같은 가중치와 활성함수를 줄 경우 xor게이트를 만들어낼 수 있다. 즉 퍼셉트론을 여러 개 붙여서 학습시킬 경우 비선형 분류도 가능하다.
층이 여러 개인 딥러닝을 학습하기 위해 필요한 과정인 Forward Propagation에 대해 알아보자.

출처:LGAimers module4 딥러닝 강의 자료
위 그림과 같이 각 입력 feature에 대한 가중치를 행 벡터로, 입력 데이터는 열 벡터로 두어 행렬 곱을 수행한 후, 활성 함수에 넣는다.
위의 경우 input 데이터가 3개인 뉴런 하나에 대한 식이다. 그렇다면 뉴런 수와 계층 수가 늘어날 경우는 어떤 모습을 할까?
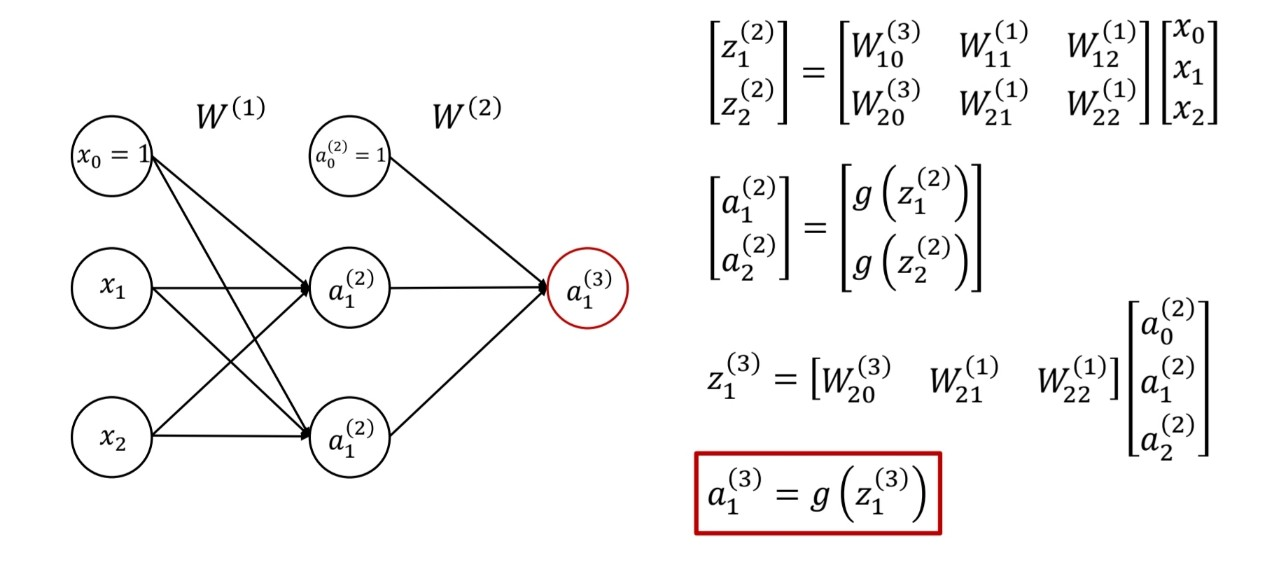
출처:LGAimers module4 딥러닝 강의 자료
여기서 쓰이는 활성 함수 g(x)는 어떻게 생겼나?
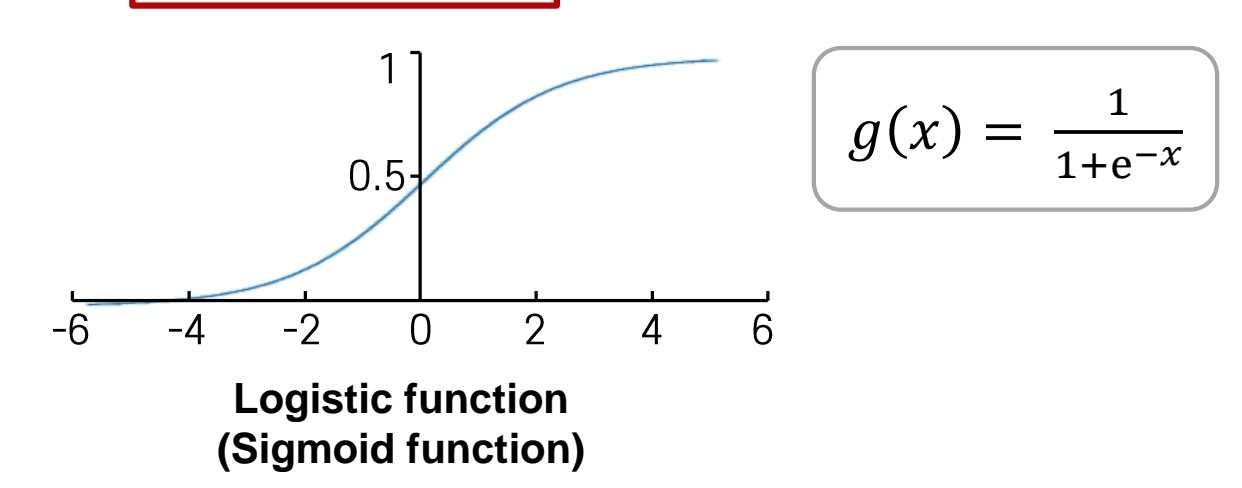
출처:LGAimers module4 딥러닝 강의 자료
대표적인 시계열 데이터인 mnist 데이터를 학습한다고 할 때, 활성 함수로 시그모이드 함수, 손실 함수로 MSE(Mean Squared Error) 방식을 쓸 경우 학습에 문제가 발생한다.
여기서 mnist 데이터란 0부터 9까지 숫자 손글씨 데이터를 말한다. 이미지 사이즈는 28x28

출처:LGAimers module4 딥러닝 강의 자료
활성 함수로 시그모이드 함수, 손실 함수로 MSE(Mean Squared Error) 방식을 쓸 때의 문제점 : 손실함수가 항상 1보다 작기 때문에, gradient descent방식으로 가중치를 업데이트 할 때, 기울기가 계속해서 작아져 학습 속도가 느려진다.
이런 문제를 해결하기 위해 출력 값들을 다 합쳤을 때 값이 1이 되게끔 하면 더 좋은 결과를 나타낼 수 있다...?!
그러기 위해서 필요한 것은 softmax layer?
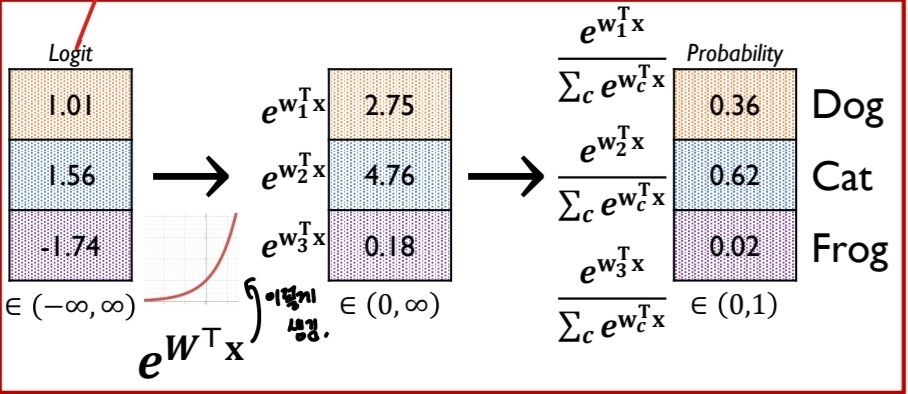
출처:LGAimers module4 딥러닝 강의 자료
활성함수를 통해 나온 값을 다른 출력값들의 합으로 나눠 확률 값을 출력하는 것. 이렇게 나온 값을 토대로 손실함수를 구하는 것이 cross entropy 함수이다.
그리고 아래는 cross entropy 손실함수에 대한 설명이다.
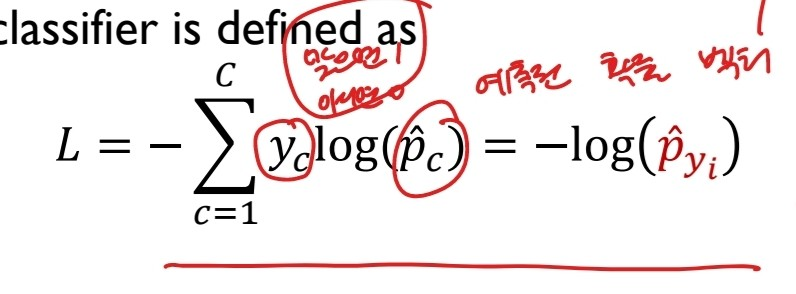
출처:LGAimers module4 딥러닝 강의 자료
저기서 yc는 정답인 클래스는 1, 아닌 클래스는 0으로 정답이 아닌 클래스는 고려하지 않는다.
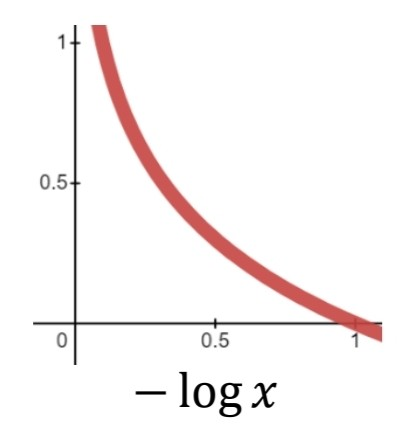
출처:LGAimers module4 딥러닝 강의 자료
위와 같은 형태를 띠어 정답인 1에 가까우면 손실함수가 작고, 정답과 거리가 먼 0에 가까우면 손실함수가 크게 나타난다.
fully-connected layer이란?
두 계층 사이에 퍼셉트론이 완전히 연결된 레이어, 즉 계층의 모든 뉴런들이 이전 계층의 모든 뉴런과 완전히 연결되어 있는 계층
출처:LGAimers module4 딥러닝 강의 자료
이런 신경망을 학습할 때, 손실함수를 줄이기 위해 가중치를 계속해서 개선하는 gradient descent 방식을 사용한다.
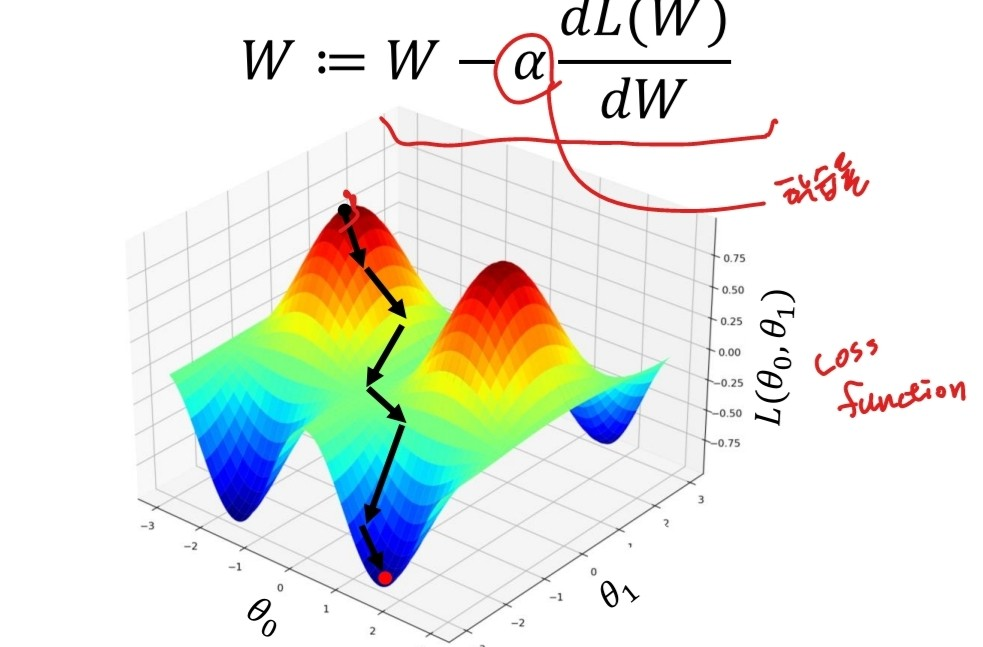
출처:LGAimers module4 딥러닝 강의 자료
여러 계층이 쌓여있는 딥러닝의 경우 backpropagation으로 기울기를 계산한다. 여기서 backpropagation이란 출력층에서부터 입력층까지 역순으로 계산하여 편미분 값을 구하는 과정.
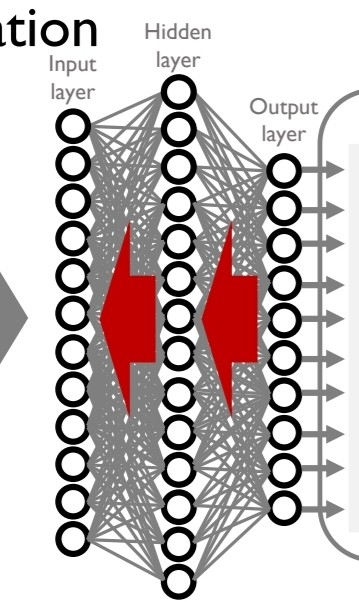
출처:LGAimers module4 딥러닝 강의 자료
그런데 이때 활성함수로 시그모이드 함수를 쓸 경우, 계층이 많을 때 학습을 시킬수록 기울기 값이 너무 작아져 학습이 어려운 gradient vanishing 문제가 발생한다. 그래서 tanh 함수를 쓰기도 하나 이도 여전히 gradient vanishing 문제를 가지고 있어 ReLu 함수를 쓰기도 한다.
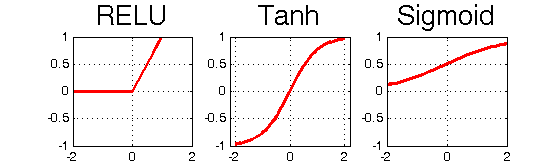
출처:https://www.researchgate.net/figure/Activation-Functions-ReLU-Tanh-Sigmoid_fig4_327435257
시그모이드, tanh 함수를 사용할 때 gradient vanishing 문제가 발생하지 않게 하려면 어떻게 할 수 있을까?
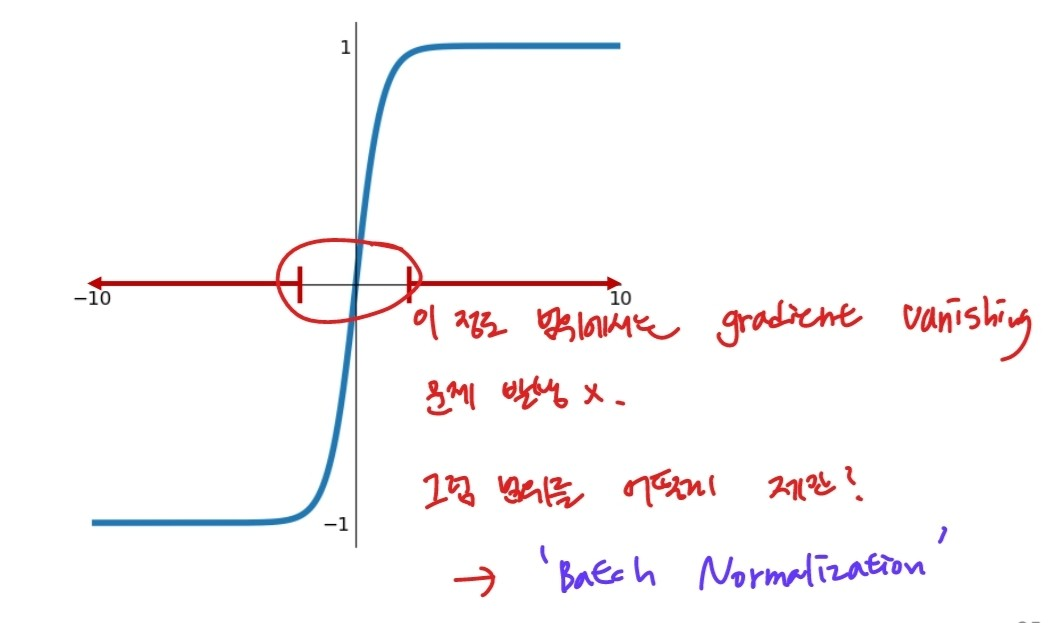
출처:LGAimers module4 딥러닝 강의 자료
input 데이터 범위를 제한하는 것이다. 이 과정을 batch normalization이라 한다.
활성함수에 들어가기 전 미니배치의 값을 아래의 식과 같이 정규화 가정을 거친 후 활성함수에 입력한다.
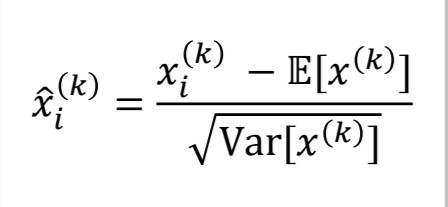
출처:LGAimers module4 딥러닝 강의 자료
하지만 이때 정규화 과정을 거치면서 잃게 되는 정보도 있으므로 원래 분포와 같은 형태로 복구시켜주는 과정도 필요하다.
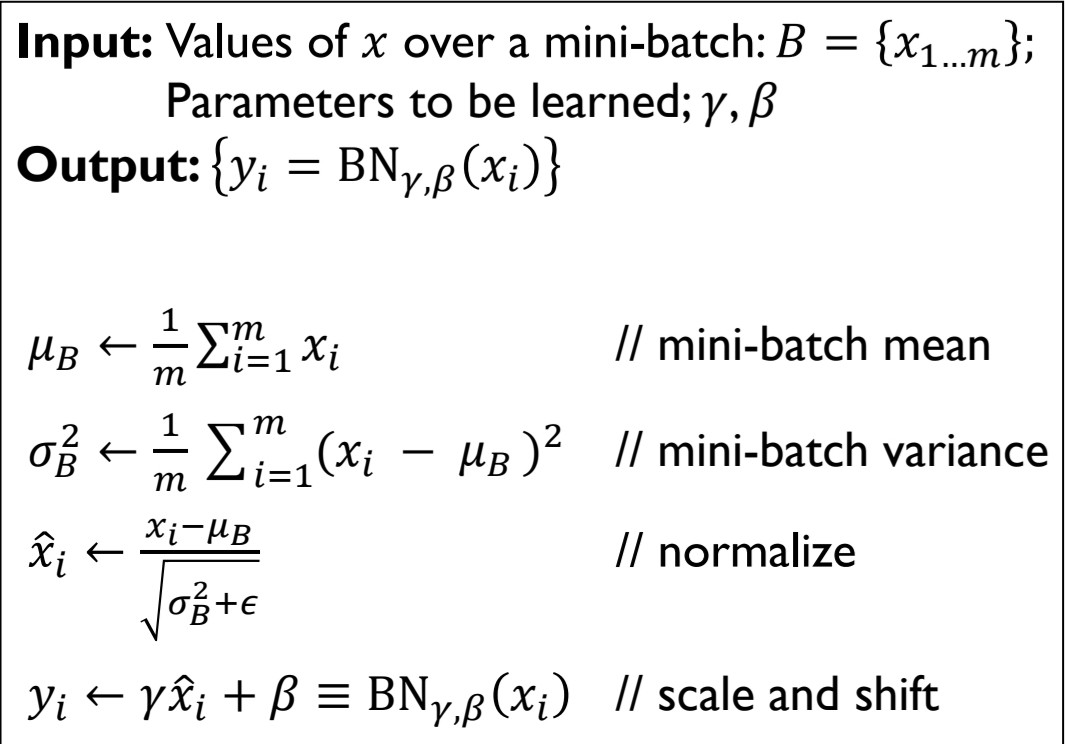
출처:LGAimers module4 딥러닝 강의 자료
사실 이 부분은 이해가 어려운데 그럼 그냥 기존 input데이터 그대로가 되는 것 아닌가... >>> 아니다. 정규화를 통해 분산이 1,평균이 0이었던 값이 back propagation을 통해 학습하면서 얻게 된 감마의 값이 새로운 분산, 베타 값이 새로운 평균이 되는 것이다.
CNN(Convolutional Neural Networks)
시각적 영상을 분석하는데 사용하는 인공 신경망 중의 하나
기존의 컴퓨터 비전은 이미지의 밝기나 대상이 여러 개라서 분석이 어려운 경우가 있었으나 CNN에서는 해결 가능하다.
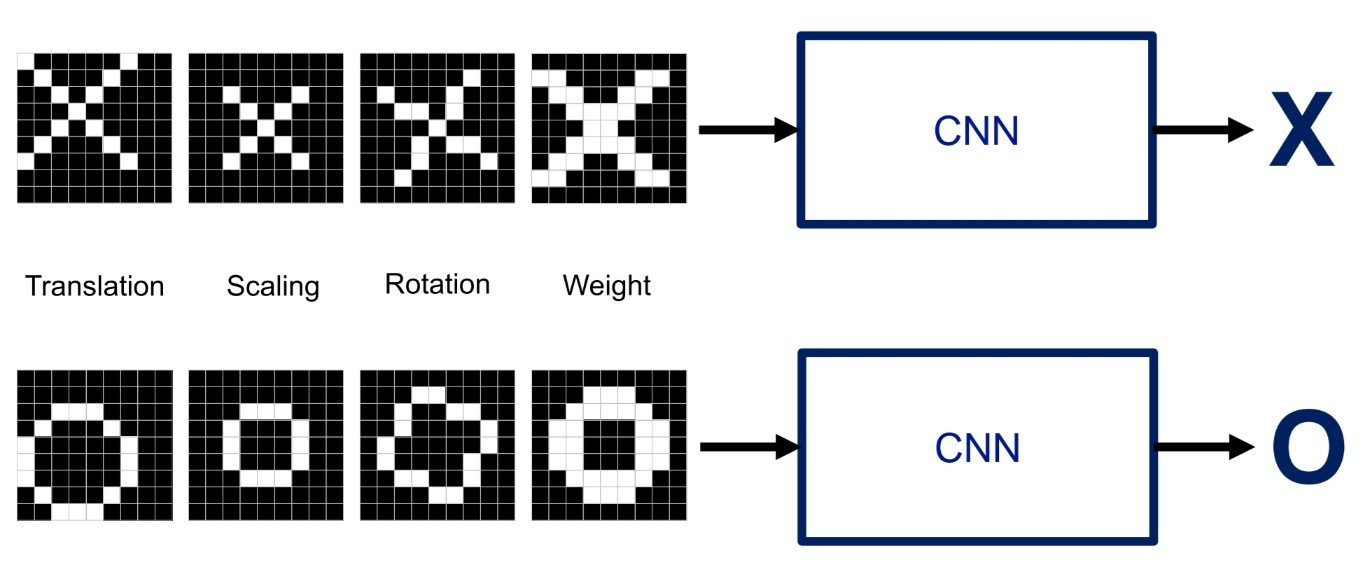
출처:LGAimers module4 딥러닝 강의 자료
위 그림과 같이 위치가 조금 어긋나거나 크기가 다르거나 회전한 이미지도 CNN을 통해 사람의 눈과 가깝게 올바르게 분류될 수 있다. 위처럼 x,o를 구분하는 이미지 분류 문제를 생각해보자.

출처:LGAimers module4 딥러닝 강의 자료
해당 이미지가 x를 가리킨다는 것을 컴퓨터가 어떻게 이해할 수 있을까?
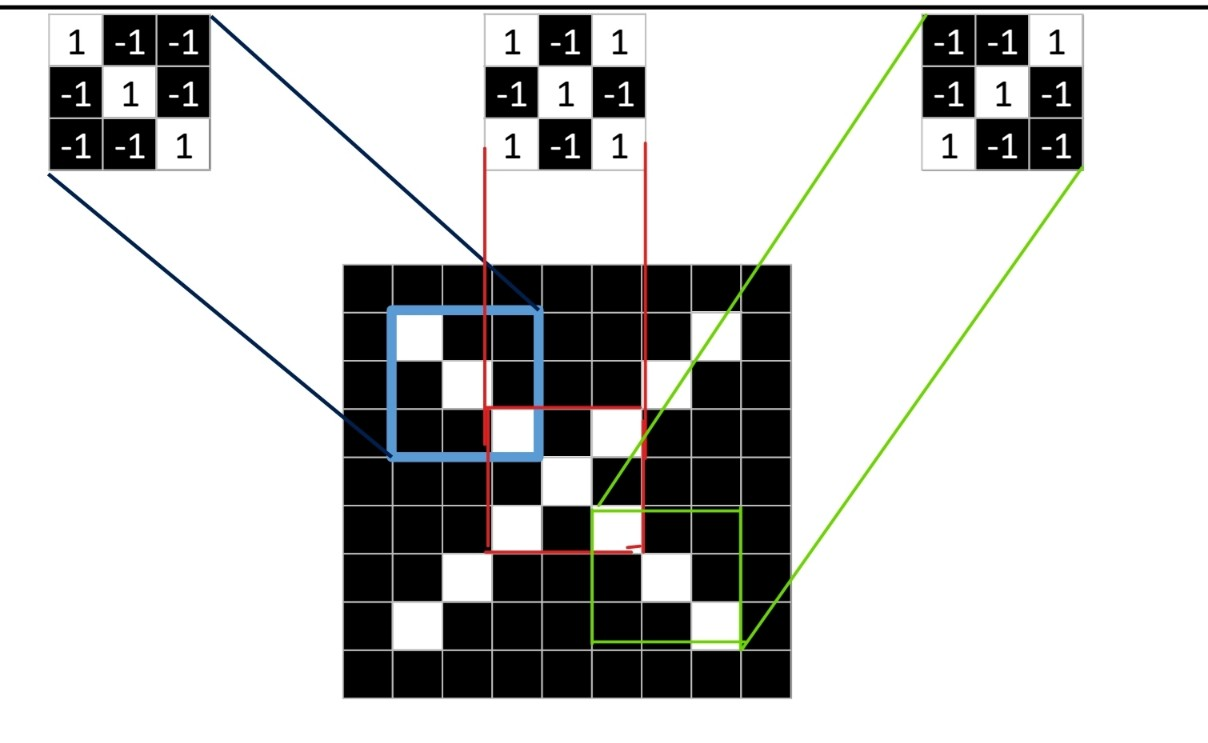
출처:LGAimers module4 딥러닝 강의 자료
- 위의 3x3 이미지 3개를 필터로 보고 해당 필터랑 매칭되는 부분이 있는지 확인한다.
- 이미지에서 픽셀이 흰 부분을 1, 검은 부분을 -1이라고 한다. 각 자리에 대해 서로 곱하여 매치해봄으로써 필터링 과정을 거친다.
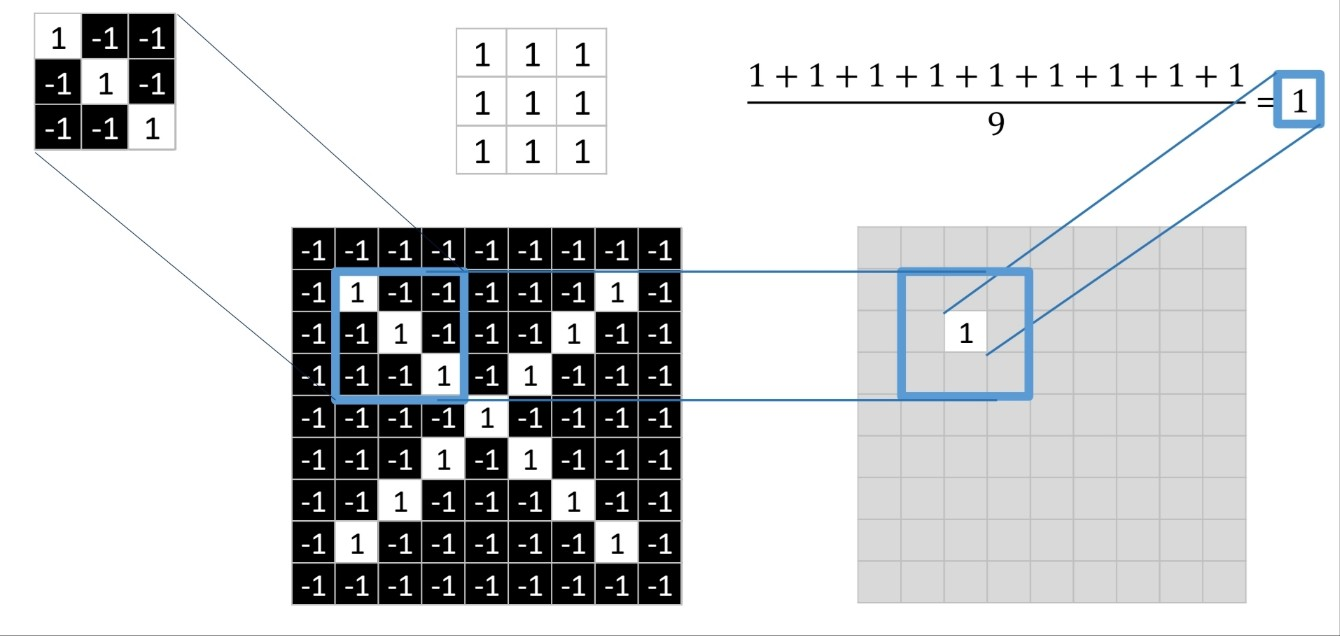
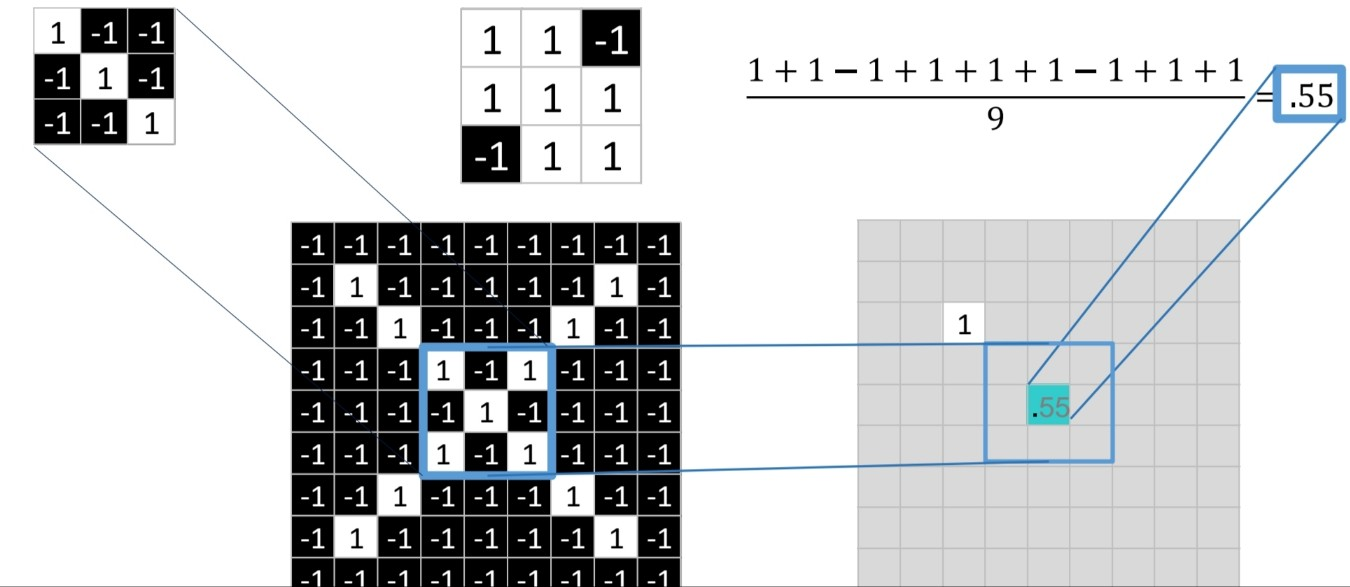
출처:LGAimers module4 딥러닝 강의 자료
- 필터의 자리와 보고자 하는 이미지에서의 위치 픽셀 색이 흰 색으로 같을 때는 11=1, 검은 색으로 같을 때는 (-1)(-1)=1이다. 그렇기에 일치하는 자리가 1로 나타나고 자리의 수를 모두 더한 후 필터 칸 수 만큼 나눈 숫자를 위 그림과 같이 적는다.
출처:LGAimers module4 딥러닝 강의 자료
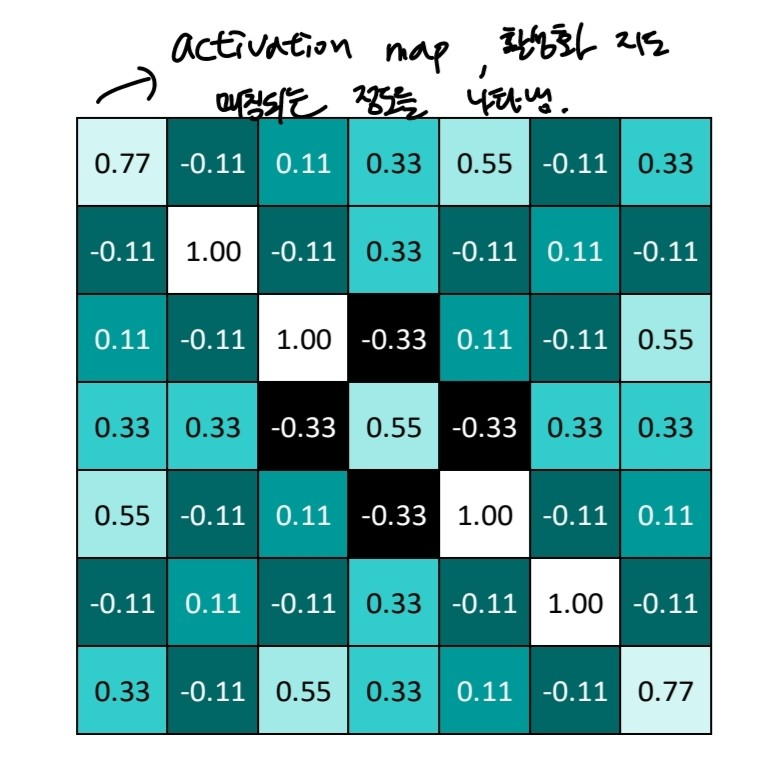
- 이렇게 비슷한 정도를 나타내는 표를 작성한 것을 activation map, 활성화 지도라고 한다. 필터와 이미지가 매칭되는 정도를 나타낸다.

출처:LGAimers module4 딥러닝 강의 자료
: 3가지 필터 모두 필터링 과정을 거친 후 나타는 activation map
위처럼 1개의 이미지에 3가지 필터를 적용할 경우 3개의 activation map이 나타난다. 1개의 activation map을 얻으려면 어떻게 해야 할까? >>> 필터 수 만큼이 채널 수를 가진 이미지를 사용하여 컨볼루션 하면 하나의 activation map을 얻을 수 있다.
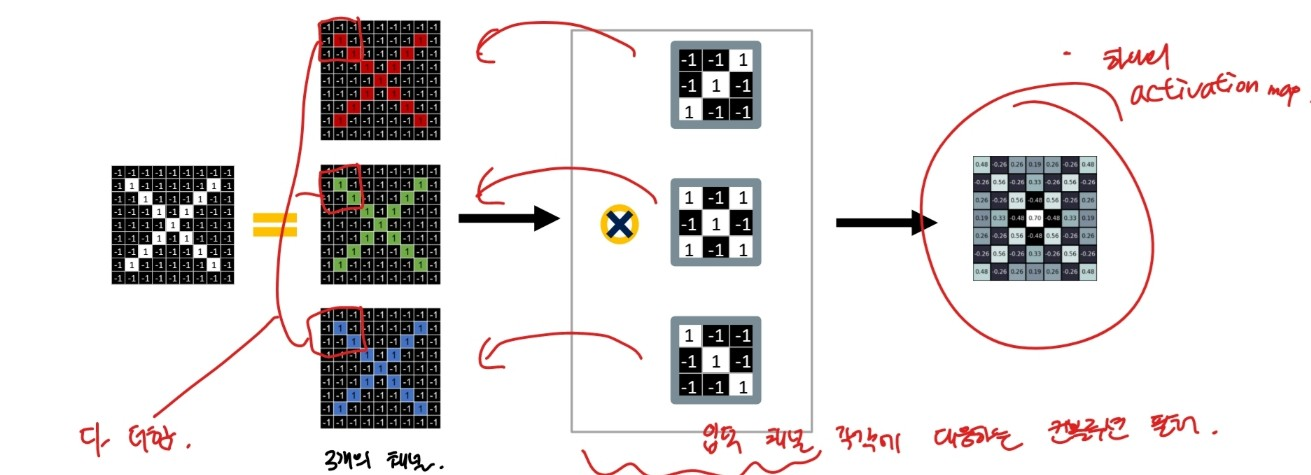
출처:LGAimers module4 딥러닝 강의 자료
convolution layer
32x32x3의 이미지를 5x5x3 필터로 컨볼루션 할 때, activation map은 28x28x1로 이미지의 사이즈는 줄어든다.
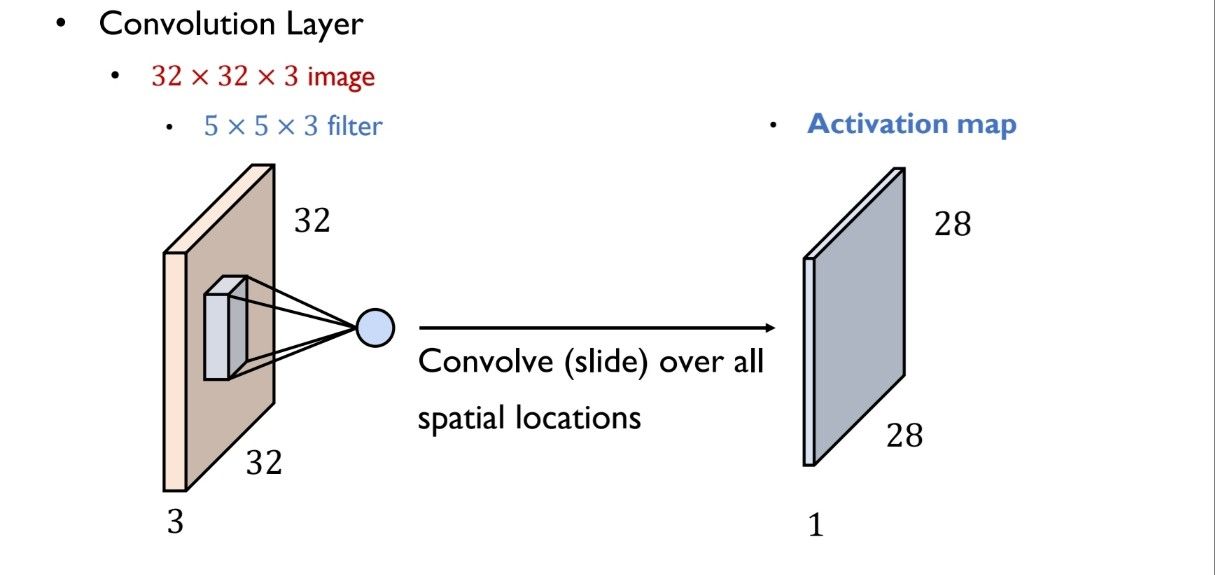
출처:LGAimers module4 딥러닝 강의 자료
만약 5x5x3 필터를 6개 가지고 있을 경우 우리는 각기 다른 6개의 activation map을 얻을 수 있다.
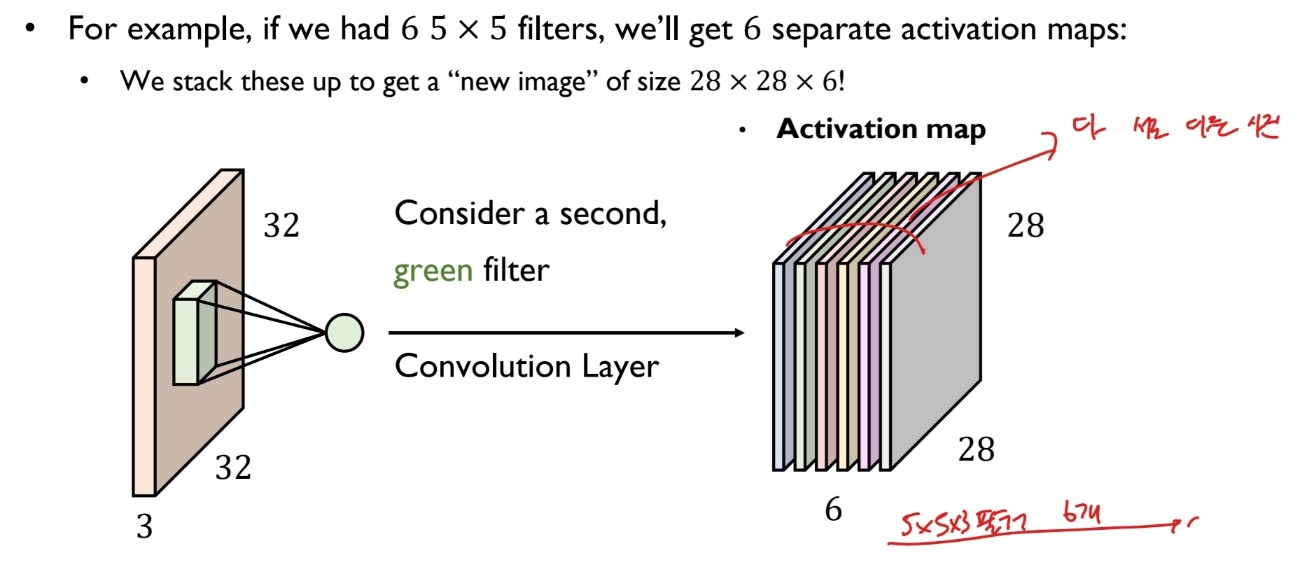
출처:LGAimers module4 딥러닝 강의 자료
Pooling
convolution으로 쌓아놓은 이미지 스택을 축소 시키기 위한 과정
1.window size 설정
2.window stride 설정
3.activation map에서 (maxPooling의 경우) window 사이즈만큼 걸어서 확인 한 후, 가장 큰 값을 추출
2x2 사이즈 window, maxpooling일 때
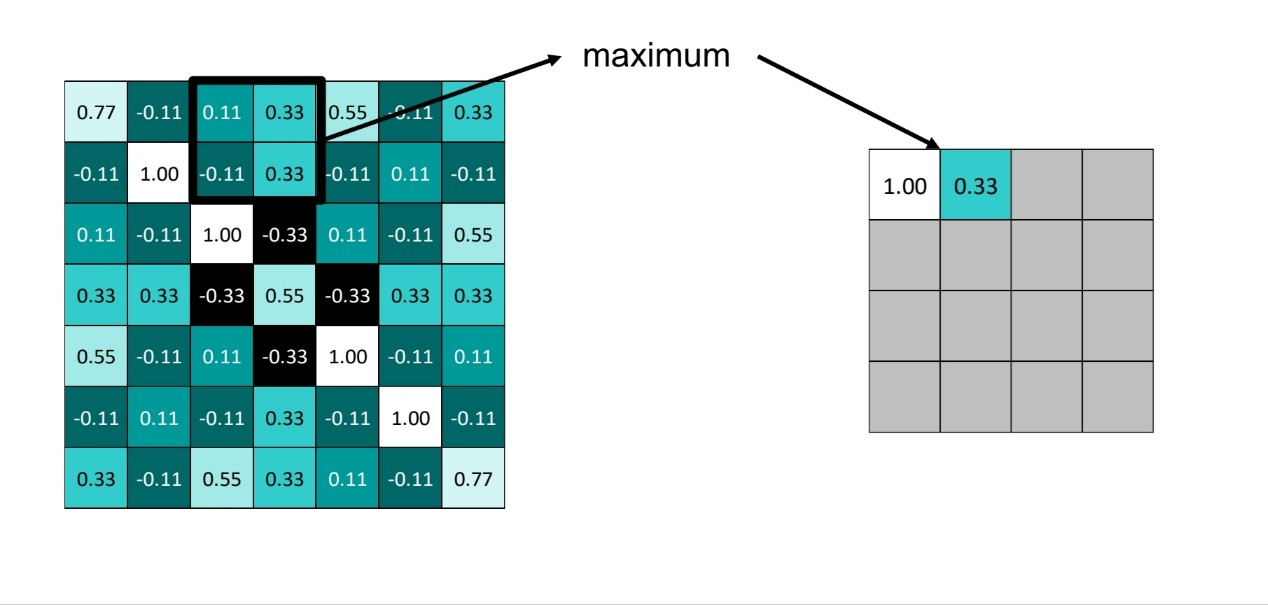
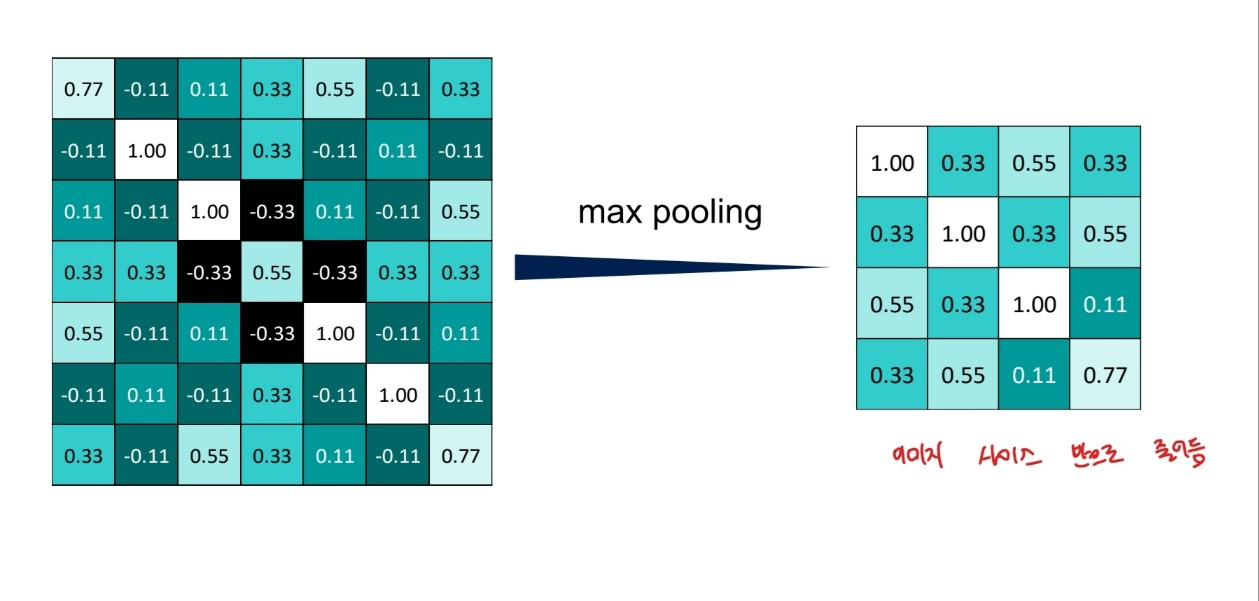
출처:LGAimers module4 딥러닝 강의 자료

출처:LGAimers module4 딥러닝 강의 자료
pooling 과정 역시 채널 별로 진행
ReLu
cnn에서도 값을 간소화하기 위해 relu 함수 적용한다. 음수 데이터를 없애기 위해 적용한다고 보면 될듯
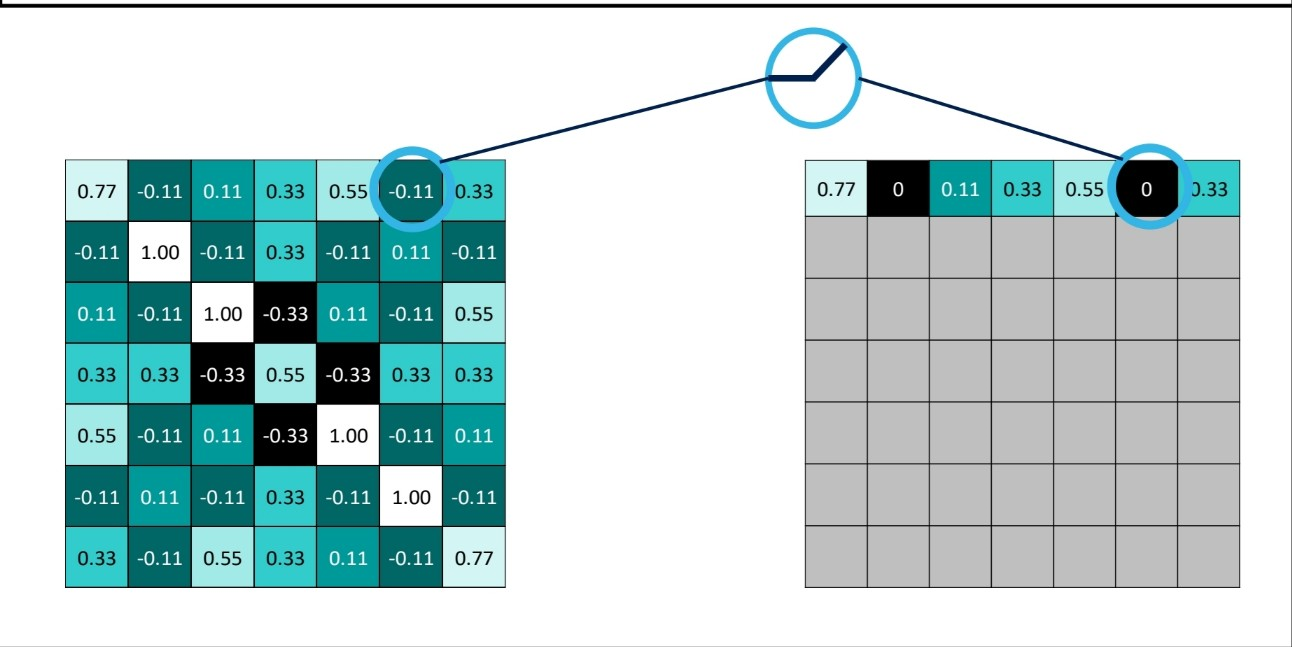
출처:LGAimers module4 딥러닝 강의 자료
cnn 과정은 아래와 같은 과정으로 이루어져 작은 이미지를 만들어낸다.
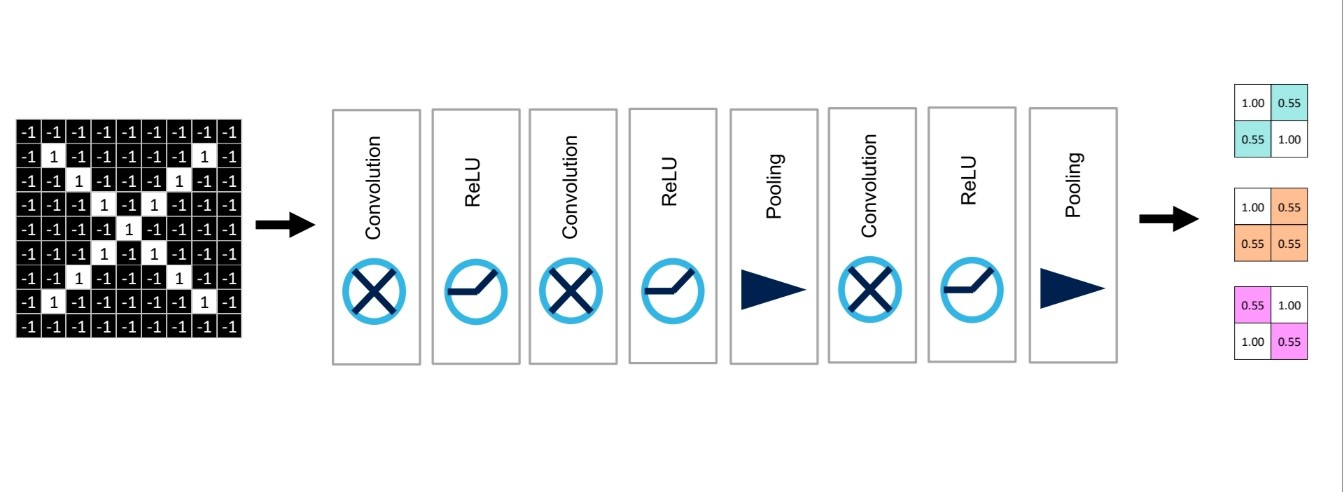
출처:LGAimers module4 딥러닝 강의 자료
이렇게 만들어낸 작은 이미지, 2x2의 이미지를 1줄로 변경한 후 각 자리를 입력으로 보고 정답인 output node와 매칭하여 적절한 가중치를 준다.
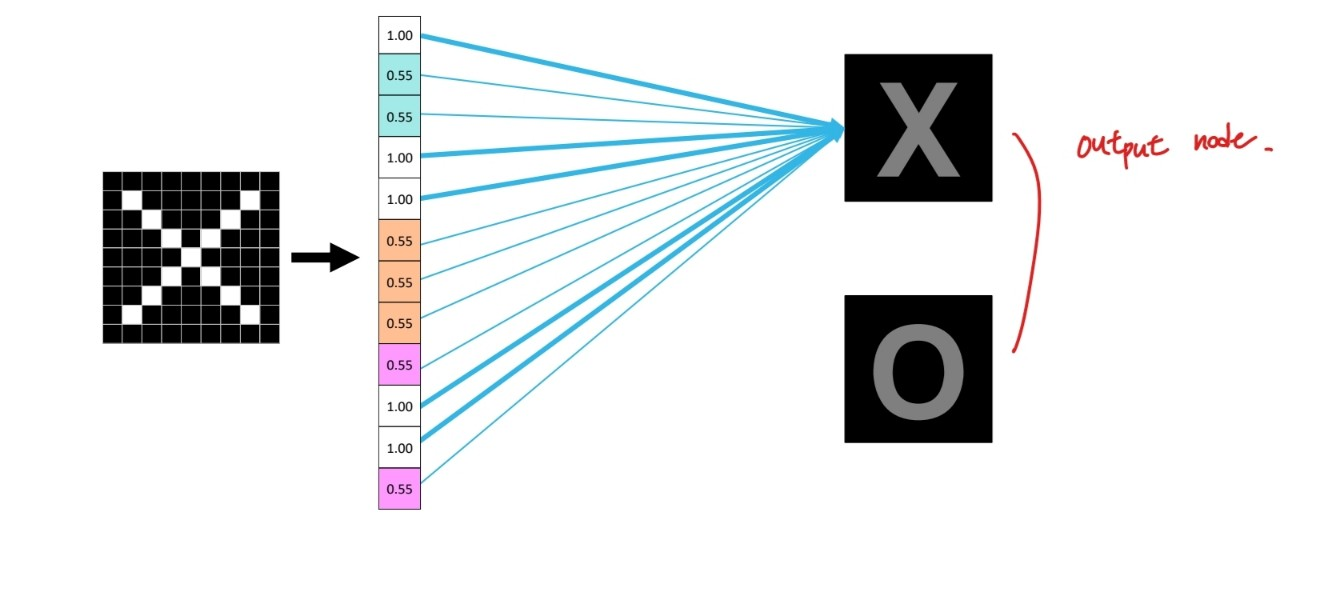
출처:LGAimers module4 딥러닝 강의 자료
선이 굵을수록 가중치가 큰 것.
그렇다면 새로운 데이터가 들어올 때는?
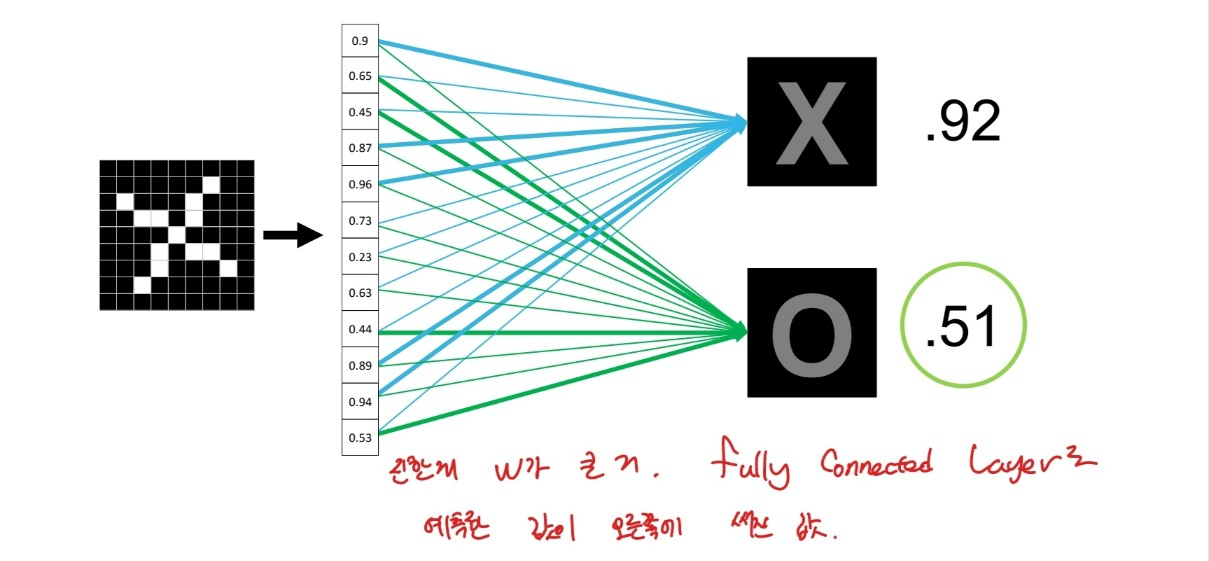
출처:LGAimers module4 딥러닝 강의 자료
오른쪽 숫자가 fully connected layer가 예측한 값. x가 1에 가까우므로 해당 그림은 x라고 판단.
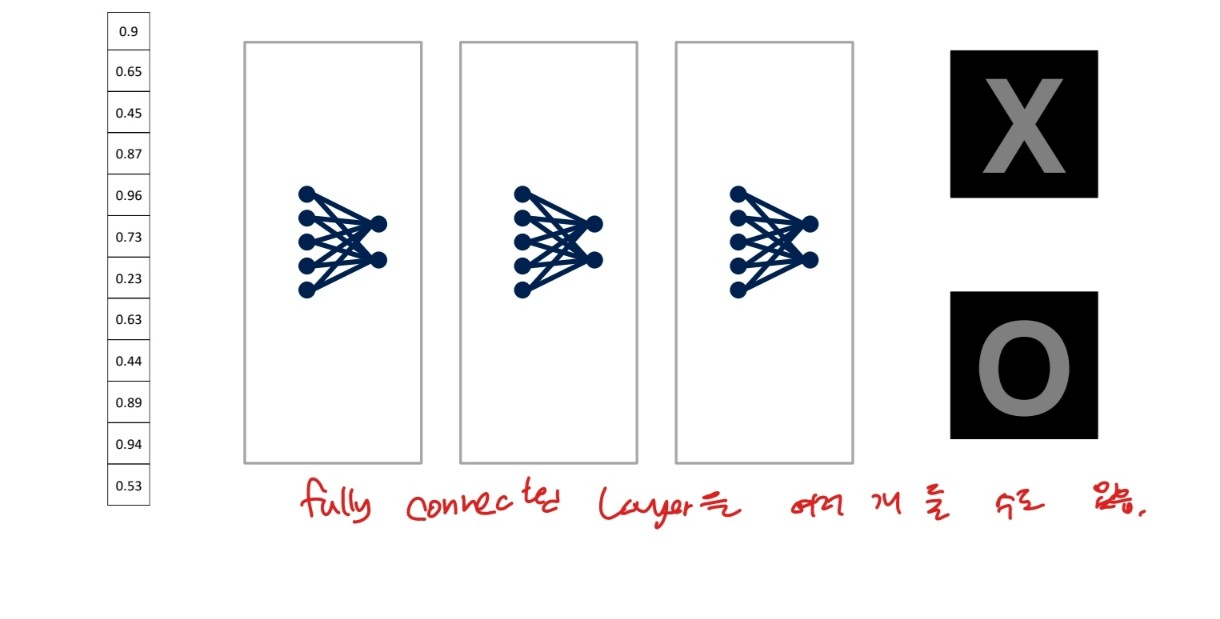
출처:LGAimers module4 딥러닝 강의 자료
fully connected layer 역시 층층히 쌓을 수 있다.
그렇다면 최종적인 cnn 모델은 어떤모습을 할까
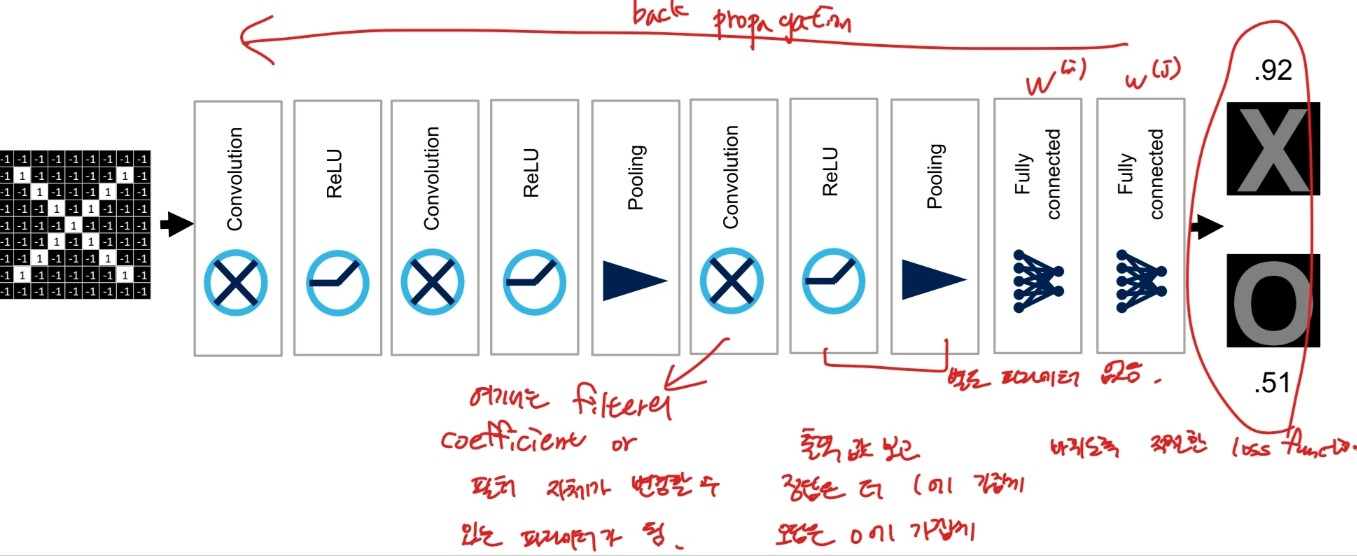
출처:LGAimers module4 딥러닝 강의 자료
다른 DNN과 마찬가지로 CNN도 back propagation을 통해 적절한 가중치를 학습한다. convolution layer의 경우 필터의 coefficient나 필터 자체가 변경될 수 있는 파라미터가 될 수 있으며 ReLu Layer나 Pooling Layer은 별도의 변경할 수 있는 파라미터가 존재하지 않는다.
cnn모델에서 중요한 점은
convolution layer에서는 필터의 개수, 필터의 사이즈
pooling layer에서는 window size, window stride이다. 여기서 stride란? pooling을 할 때 window를 몇 픽셀마다 이동하면서 볼 것인지를 의미한다.
fully connencted layer에서는 다른 인공신경망 모델과 마찬가지로 계층 수, 뉴런 수에 따라 학습력이 달라질 수 있다.
반드시 3x3 필터를 사용하지만 계층 수가 굉장히 큰 VGGNet, 필요에 따라 특정 계층을 생략하며 학습할 수 있는 ResNet등 CNN 아키텍처는 많은 게 존재한다.
