강의를 들은지 4일차, 드디어 module 3 강의를 들었다. 주제는 '지도학습'으로 Aimers 활동을 시작하면서 처음으로 AI 관련 이론에 대해 제대로 배우게 된 것 같다.
지도학습(Supervised learning)이란 레이블(답)이 정해져 있는 데이터로 인공지능을 학습시키는 과정을 말한다. 지도학습으로 다룰 수 있는 문제는 연속형 데이터를 다루는 회귀(Rgression)문제, 이산형 데이터를 다루는 분류(Classification)으로 나눌 수 있다.
데이터는 입력과 출력 데이터 X,Y형태로 주어지는데 여기서 인공지능은 X->Y로 가는 함수 h를 학습함으로써 새로운 데이터가 들어올 때 예측되는 출력값을 출력할 수 있게 한다.
예를 들어 'price','engine power' 정보를 가지고 차가 'family car'인지 아닌지 예측하는 문제가 있다. 이때 가격과 엔진 파워와 같이 입력 데이터에서 출력 값을 찾아내기 위해 적절한 요소를 feature, 특징이라고 한다.
모델은 '적절한 특징 추출', '적절한 모델 선정', '최적화' 과정을 거쳐 이상적인 출력값을 나타내기 위해 학습한다.
여기서 가장 중요한 과정은 '일반화'이다. 이것이 의미하는 게 뭐냐, 우리가 학습시키는데 사용하는 데이터는 한정적이다. 그렇지만 실제로는 훨씬 많은 데이터가 존재하기 때문에 모델이 만나본 적 없는 데이터에 대해서도 좋은 성능을 보여야 한다. 그러기 위해서는 주어진 데이터로 에러를 줄이는 과정 역시 학습하여야 하는데 그것이 바로 '일반화'이다.
여기서 말하는 에러는 학습 모델의 출력 값인 h(x)와 실제 레이블 값인 y의 차이인 e(h(x),y)를 의미한다. squared error, binary error등 다양한 형태의 에러가 존재한다. 모든 샘플들의 에러를 합쳐 loss function을 만들고 이를 줄이는 방향으로 모델은 학습한다.
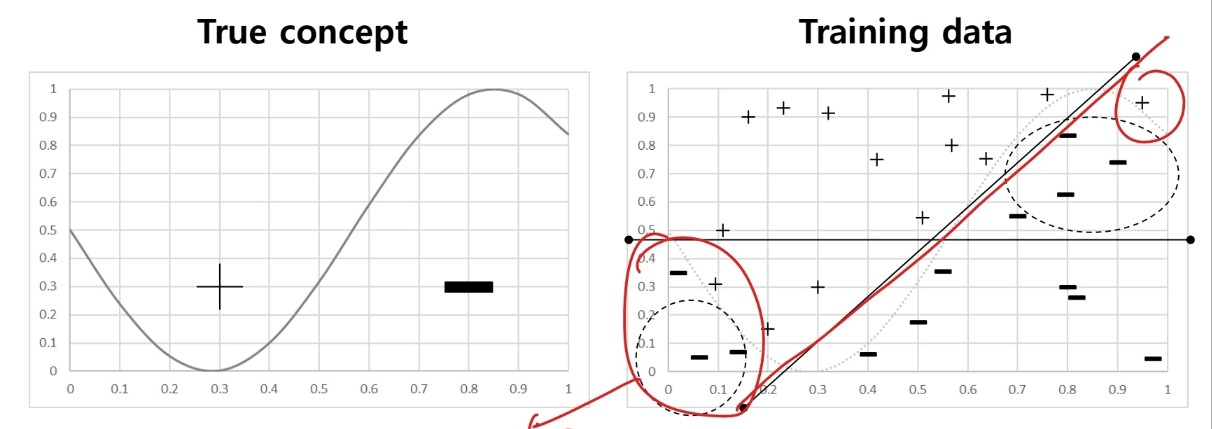
이번 Aimers 강의를 통해서 Bias와 Variance에 대해 처음 알았다. 용어 자체는 알고 있는 용어였지만 내가 알고 있는 내용과는 차이가 있었다. 이 둘은 일종의 에러로 bias는 모델이 제대로 예측을 하지 못 해 발생하는 에러, variance는 노이즈에 예민하게 반응하여 생기는 오류를 의미한다.
bias가 클 때 나타나는 현상을 우리는 Underfitting이라고 한다. 실제 데이터에 비해 너무 간단한 모델을 사용할 때 예측을 제대로 하지 못 하는 경우를 말한다.
(출처: 이화여대 강제원 교수님 강의자료)
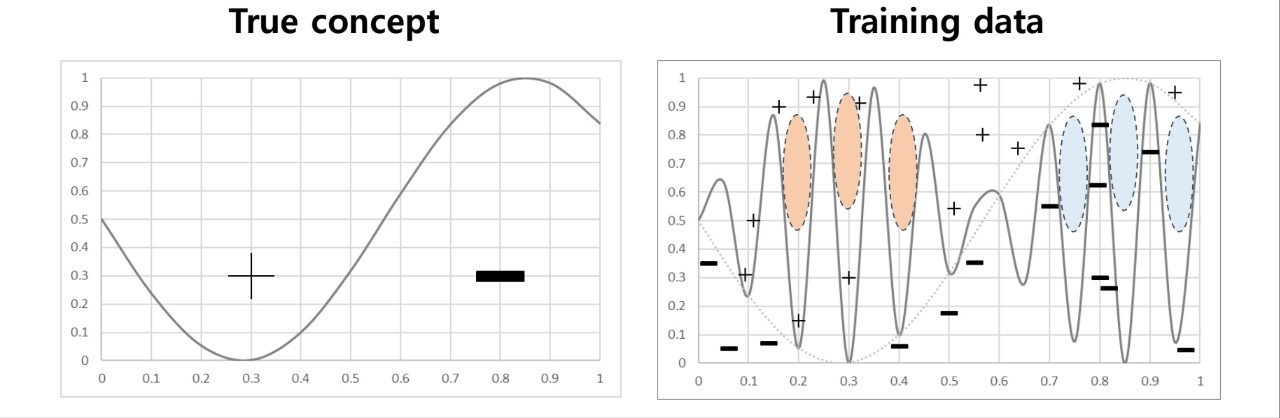
반대로 variance가 클 때는 Overfitting으로 모델이 학습 데이터를 기반으로 지나치게 복잡한 형태를 띠어 다른 데이터가 들어올 때 제대로 예측하지 못 하는 경우를 말한다.
(출처: 이화여대 강제원 교수님 강의자료)
모델이 언더피팅도 오버피팅도 되지 않도록 적절한 bias와 variance 값을 갖도록 학습시켜야 한다.
그렇다면 오버피팅을 막기 위해서는 어떤 방법이 있을까? 일단은 단순하게 데이터 양을 늘리는 것이다. 근데 이게 뭐 현실적으로 가능한 소리인가 뭐 인위적으로 늘리고 뒤집고 그런 거 얘기하는 건가...? 그리고 다른 방법으로는 '정규화'와 '앙상블'이다. 아래에서 나중에 자세히 얘기할 것.
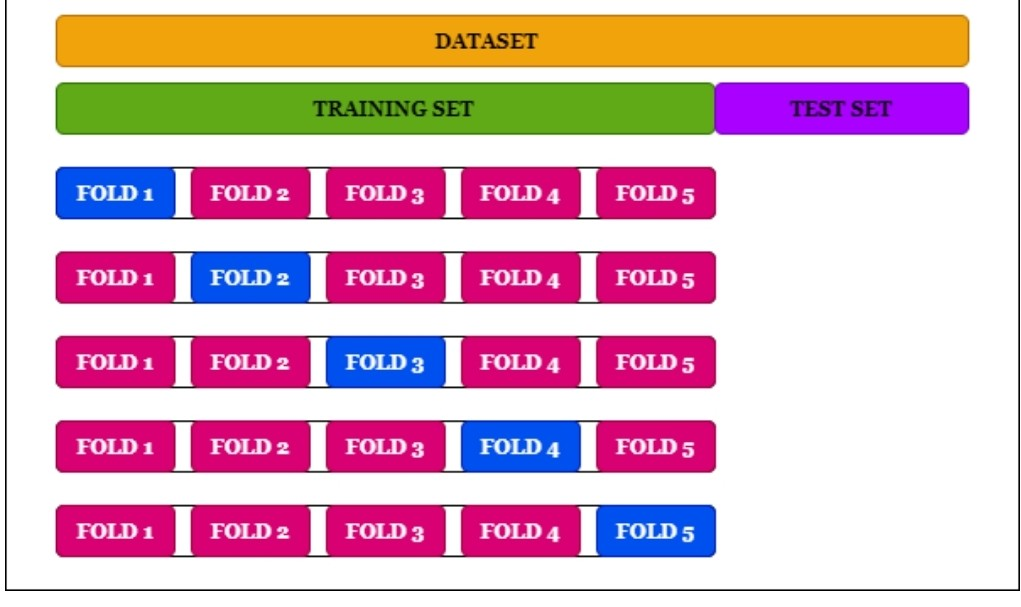
그리고 중요한 게 cross-validation인데 train 데이터를 k개로 나눈 후, k-1개의 데이터를 훈련할 때 사용하고 나머지 데이터를 validation 검증 데이터로 사용하는 것이다. 그렇게 총 k번 학습시키는 것. 이렇게 학습시킨다면 오버피팅을 막기 위 해 더 좋은 모델이 될 것이다.
(출처: 이화여대 강제원 교수님 강의자료)
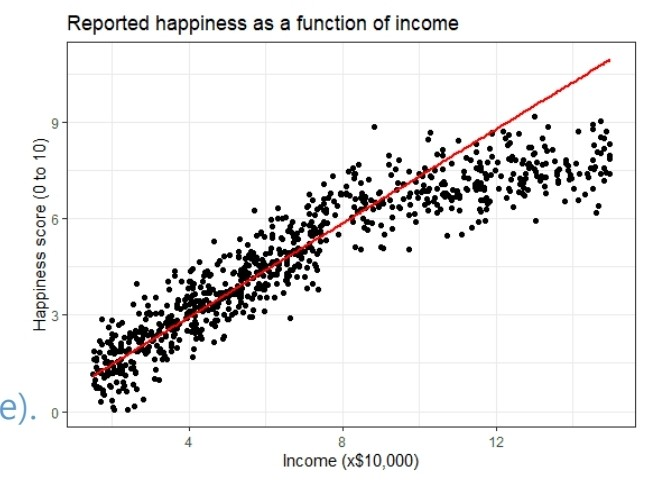
제일 먼저 알려주신 모델은 '선형 회귀'에 관한 모델이었다. 예를 들어 소득에 따른 행복도에 관한 연구를 할 때 실제 데이터 분포는 아래 그림의 산포도와 같다고 한다. 그렇다면 우리가 학습시키는 머신러닝 모델은 빨간 직선과 같은 형태로 답을 예측할 수 있다는 것이다.
(출처: 이화여대 강제원 교수님 강의자료)
그렇다면 저 빨간 직선의 식은 어떻게 나타낼 수 있을까?
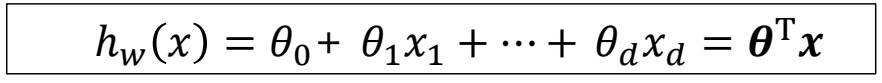
(출처: 이화여대 강제원 교수님 강의자료)
이러한 형태로 나타낼 수 있다. 여기서 x는 입력 파라미터, 세타는 각 파라미터의 중요도를 의미하는 가중치이다.
여기서 선형 회귀 모델이 만들어지는 과정은 아래와 같다.
1) 위 식과 같은 h(x) 모델을 설정한다.
2) loss function , 손실함수를 통해 예측을 잘하는 모델인지 확인한다.
3) 최적화 알고리즘을 통해 최적의 예측을 할 수 있는 세타값으로 모델을 변경한다.
여기서 loss function은 cost function이라고도 하며 어떤 함수를 쓰느냐에 따라 형태는 달라질 수 있다.
아래 그래프는 가중치 값에 따라 달라지는 손실함수를 나타낸 그래프이다.
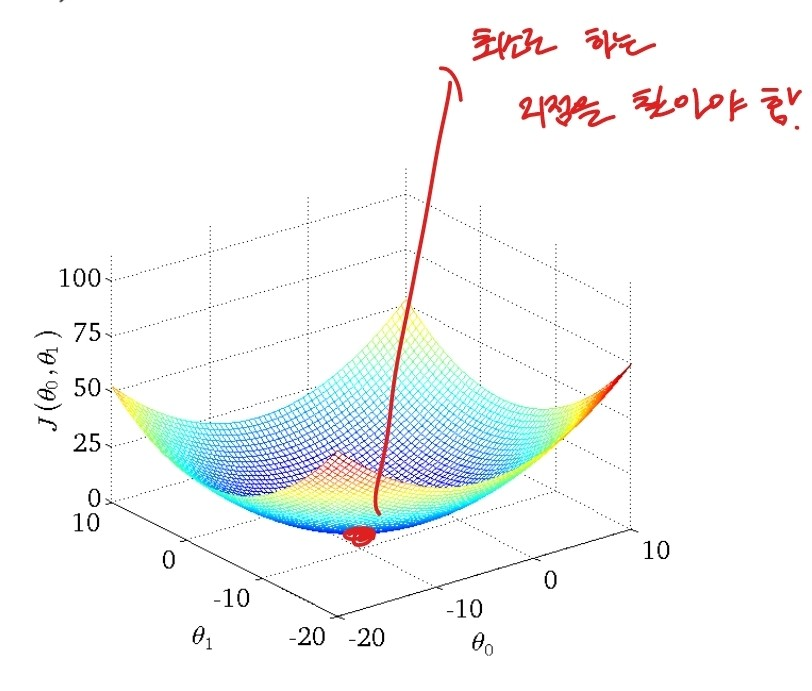
(출처: 이화여대 강제원 교수님 강의자료)
최적화 과정은 위 그래프에서 가장 낮은 지점을 찾는 과정을 말한다. 이 과정에는 normal equation이 있고 흔히 쓰는 gradient descent가 있다.
gradient descent의 경우 위 그래프에서 특정 지점에서 출발할 때, 기울기가 가파른 방향으로 이동하며 기울기가 0인 최적해를 찾아가는 과정을 말한다. 기울기가 가파른 방향으로 이동한다는 것이 무엇일까?

(출처: 이화여대 강제원 교수님 강의자료)
괄호 표시한 곳이 출발 지점에서의 기울기, 그 기울기의 반대 방향으로 학습률만큼 이동해 새로운 가중치 값을 찾아내는 것이다. 여기서 학습률은 너무 작으면 해를 찾는데 지나치게 오래 걸릴 수 있으며 너무 크면 해를 찾지 못 하고 진동할 수 있다.
여기서 Batch Gradient Descent란 전체 데이터 셋에 대한 기울기를 측정하고 가중치를 개선하는 방법이고, Stochastic Gradient Descent는 추출된 데이터 1개에 대해서만 기울기를 측정하고 가중치를 개선하는 방법이다.
이러한 SGD의 문제점 중 하나는 어떤 데이터를 출발 지점으로 보냐에 따라 local optimrum에 빠질 수도 있다는 점이다.
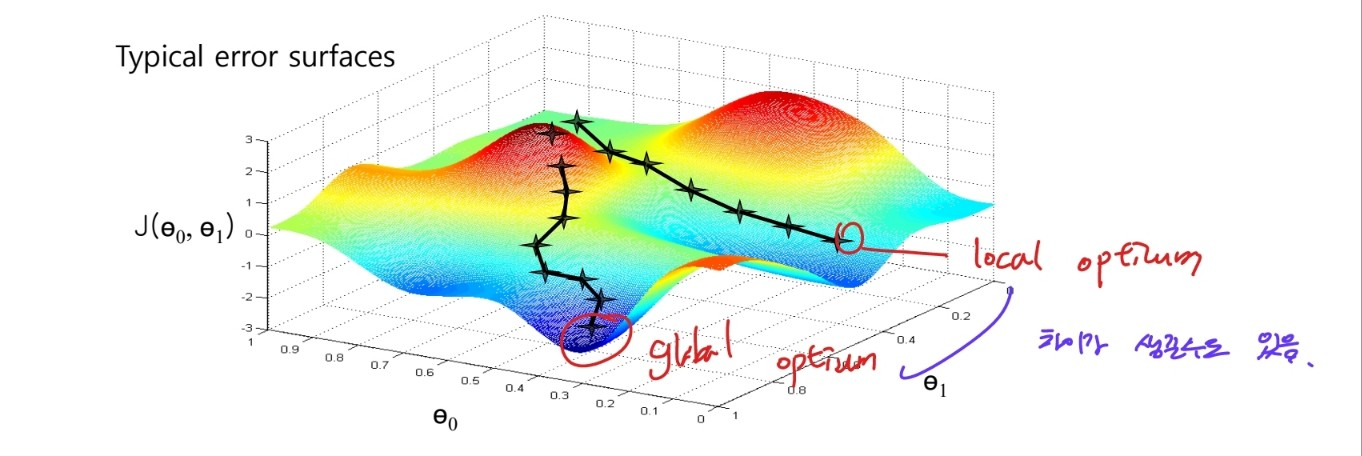
(출처: 이화여대 강제원 교수님 강의자료)
이러한 점을 해결하기 위해 먼저 도입된 것이 바로 '모멘텀'이다.
모멘텀이란 gradient가 기존에 업데이트 되어오던 방향으로 속도를 반영하여 관성을 주는 것으로, 기울기가 0인 local optimum에 빠져도 계속해서 학습을 이어나갈 수 있다. 네스테로브 모멘텀이란 것도 존재하는데 이는 다음 기울기를 이동에 반영하는 것이다.
local minumum에 빠지는 걸 막기 위해 쓰이는 방법 중 또 다른 것은 바로 AdaGrad로 학습을 하면 할수록 학습률을 작게 조절하는 것이다. 하지만 이것도 단점이 존재하는데 학습률을 조절하는 과정에서 과거의 기울기를 계속하여 곱하기 때문에 기울기가 소멸되어 학습이 진행되지 않을 수도 있다는 점이다.
이를 개선하기 위해 나온 것이 RMSProp으로 이는 가장 최근에 변경된 기울기를 더 크게 반영하고 과거의 기울기는 더 적게 반영하여 기울기가 소멸되어 학습률이 작아지는 걸 어느 정도 막을 수 있다.
그리고 이러한 RMSProp에 모멘텀이 추가 된 Adam을 현재로는 가장 많이 쓴다고 한다.
이러한 최적화 과정을 통해 feature수를 줄여 예측하는데 적절한 특징만을 남길 수 있다.
위에서 계속 얘기한 것은 연속형 데이터를 예측하는 회귀 문제, 그렇다면 이번에는 분류 문제에 대해 이야기해보자.
예를 들어 positive, negative만 구분하면 되는 이진 분류 문제가 있다고 할 때 '선형 분류'모델의 경우 아래의 그림과 같다.
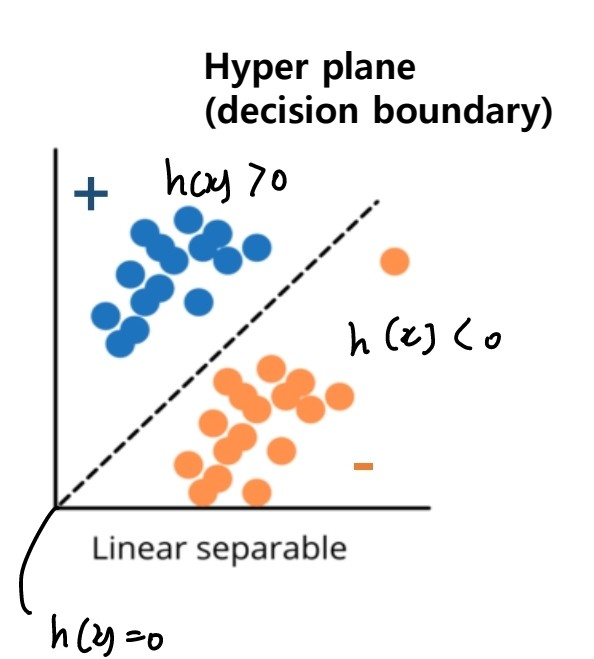
(출처: 이화여대 강제원 교수님 강의자료)
모델이 가리키는 하이퍼플레인을 기준으로 그보다 위에 있으면 positive, 아래에 있으면 negative이다. 물론 2개의 이산형 데이터만 구분지으면 되는 이진 분류뿐 아니라 여러 개의 데이터를 구분해야 하는 다중 분류 역시 가능하다.
위 그림에서의 h(x)는 회귀 모델에서와 비슷한 형태를 띤다.

(출처: 이화여대 강제원 교수님 강의자료)
x는 입력 데이터 파라미터, w는 각 파라미터의 중요도를 나타내는 가중치.
1) 위 식을 바탕으로 sign(Wt X)를 h(x)로 설정한다.
2) loss function , 손실함수를 통해 예측을 잘하는 모델인지 확인한다.
3) 최적화 알고리즘을 통해 최적의 예측을 할 수 있는 세타값으로 모델을 변경한다.
여기서 h(x)식에 sign()이라는 함수?가 더 들어갔는데 이는 출력되는 값을 보고 어떤 클래스를 나타내는지 구분을 해주라는 뜻. 예를 들어 h(x)가 0보다 클 때는 참, h(x)가 0보다 작을 때는 거짓 이런 식으로?
그리고 분류 모델에서 쓰는 손실함수는 회귀 모델과는 차이가 있다는 점을 기억하자.
그리고 이번 교육을 통해 처음 들은 단어 score, margin이다.
일단 margin은 모델이 예측한 값이 맞았냐 아니냐를 의미한다는 점은 이해했다. 그러나 score... 예측한 값이 얼마나 confident한지... 이게 무슨 개소리인가... 내는 모르겠당
분류 모델에서 사용하는 loss function은 여러 개가 있는데, 일단 예측이 맞았는지 아닌지만을 구분하는 'zero-one loss'의 경우 경사하강법, gradient descent 방법으로 가중치를 개선 시킬 수 없어 잘 사용하지 않는다.
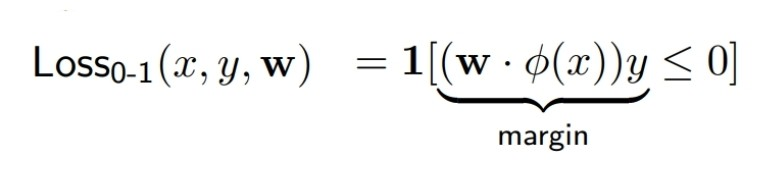
(출처: 이화여대 강제원 교수님 강의자료)
이런 zero-one-loss 함수를 더 개선한 hinge loss function도 존재하다. 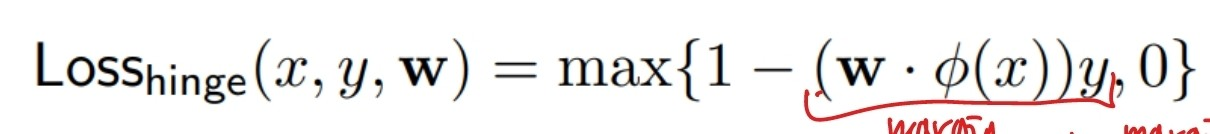
(출처: 이화여대 강제원 교수님 강의자료)
하지만 우리가 제일 많이 쓰는 건 예측한 값과 실제 레이블값을 확률로 두고 유사도를 비교하는 'cross-entropy' 방식이다. p가 예측 분포, q가 실제 분포
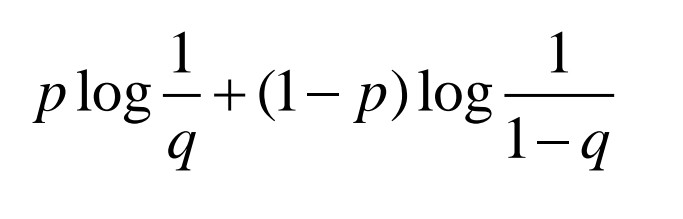
(출처: 이화여대 강제원 교수님 강의자료)
손실 함수로 크로스 엔트로피 함수를 사용하려면 우리가 써야 하는 활성 함수가 있다. 왜냐하면 크로스 엔트로피의 경우 확률을 비교하여야 하는데 우리가 예측 모델로 쓰는 식 h(x)는 실수형의 데이터를 출력하기 때문이다. 그렇기에 값에 따라 0부터 1사이 값으로 바꿔주는 '시그모이드 함수'를 활성함수로 사용해주어야 한다.
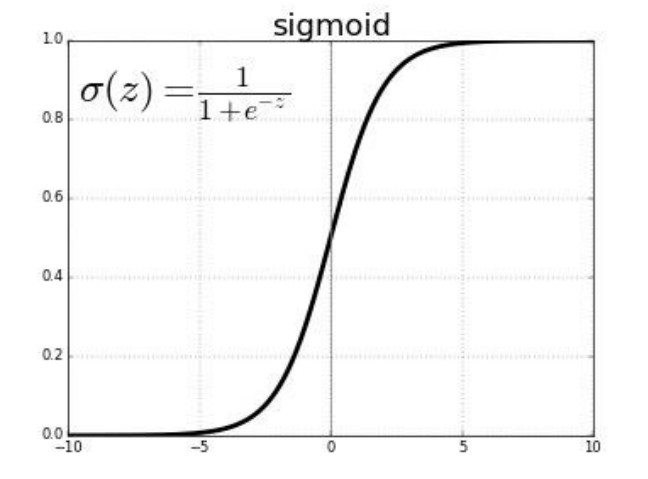
(출처: 이화여대 강제원 교수님 강의자료)
multiclass classification, 다중 분류를 할 때에는 이진 분류 모델을 확장해서 쓸 수 있다.
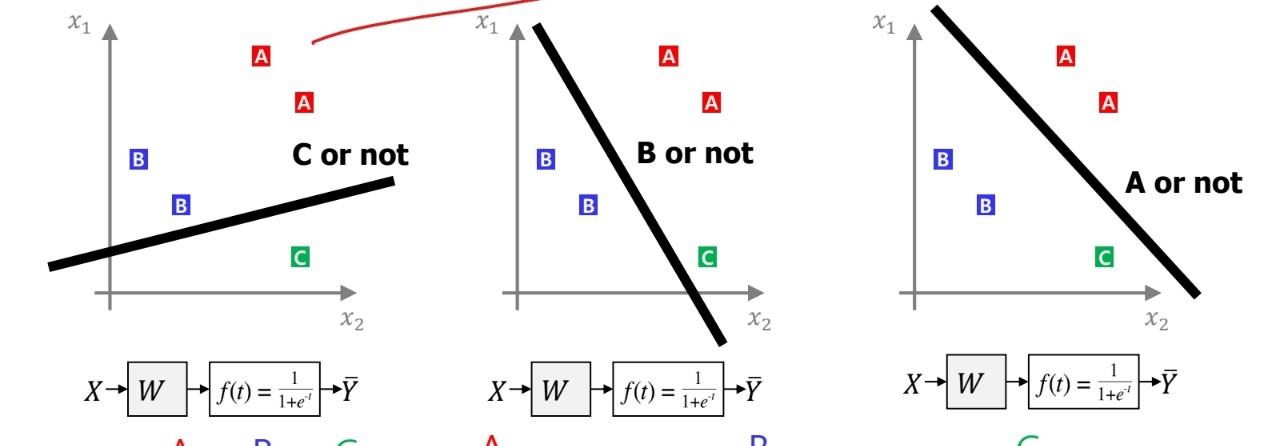
(출처: 이화여대 강제원 교수님 강의자료)
위 그림과 같이 여러 개의 이진 분류 모델을 만들어낸 후, 각각의 score에 시그모이드 함수를 적용하여 확률 값으로 나타내고, 이 확률 값을 통해 분류할 수 있다.
위에서 이야기한 선형 모델들 이외에 성능이 더욱 향상된 모델들이 있는데, 그 중 하나가 바로 support vector machine(SVM)이다.
하이퍼 플레인과 가장 가까운 샘플을 '서포트 벡터'라고 하여 이들을 서로 최대한 하이퍼 플레인과 거리를 두게끔 하는 모델인 것이다.
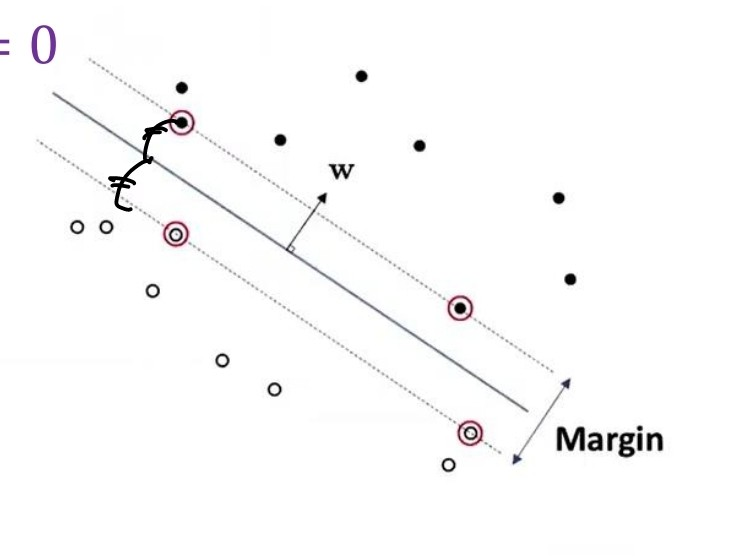
(출처: 이화여대 강제원 교수님 강의자료)
여기서 서로 반대의 위치에 있는 서포트 벡터 사이의 거리를 margin 이라고 한다.
이러한 SVM은 마진 영역에서 어떤 샘플들도 존재하는 걸 용인하지 않는 Hard margin SVM, 일부는 허용하는 Soft margin SVM이 존재한다. 우리는 margin을 최대화 할 수 있는 가중치 w를 찾아야 하는 것.
그리고 svm은 그림과 같이 선형 분류를 할 수 있을 뿐 아니라 비선형 데이터 역시 차원수를 높여 선형 분류가 되게끔 할 수 있다.
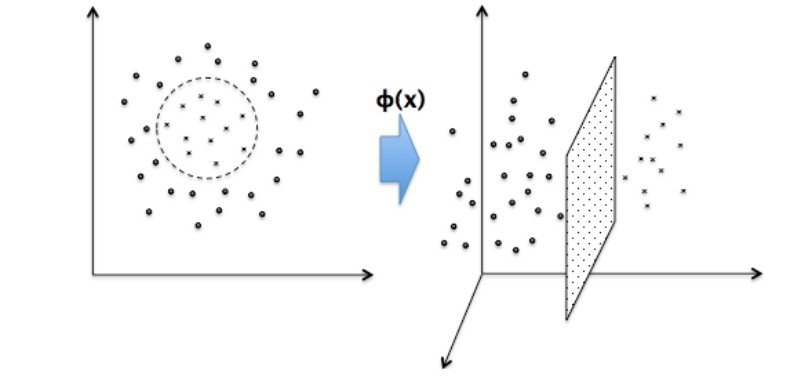
(출처: 이화여대 강제원 교수님 강의자료)
또한 Artificial Neural Network, ANN도 존재한다. 이는 DNN의 기본으로 우리가 흔히 인공지능을 배울 때 가장 많이 배우는 '인공 신경망'이다. 인간의 뇌 형상을 따라한 컴퓨터 모델...!!!
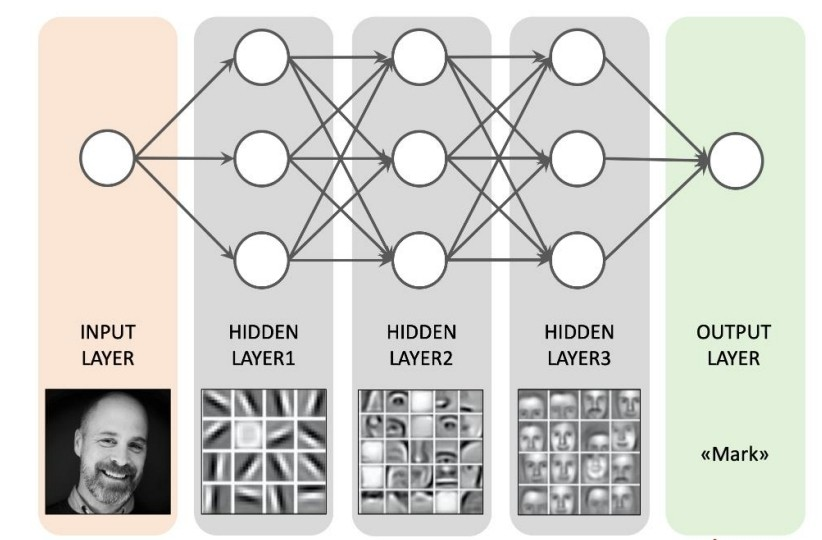
(출처: 이화여대 강제원 교수님 강의자료)
첫번째 계층에서 입력 데이터를 통해 모델을 생성해낸 후, 그 모델이 나타낸 출력 값으로 또 다른 모델을 만들어내 학습하는 과정을 반복한다.
이렇게 여러 개의 계층이 쌓여가며 분류를 좀 더 명확하게 할 수 있는 것. 하지만 반복적으로 여러 신경망을 거쳐 학습하기 때문에 활성함수로 시그모이드 함수를 쓸 경우 gradient가 0으로 포화하여 학습을 진행할 수록 나중에는 학습이 진행되지 않는 경우가 생긴다. 그렇기 때문에 'ReLu'함수라는 새로운 활성함수를 주로 쓴다.
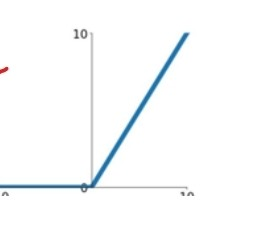
(출처: 이화여대 강제원 교수님 강의자료)
인공 신경망의 경우 여러 계층을 지나면서 복잡한 하이퍼 파라미터 플레인을 만드는 모델을 만들어낼 수 있다. 그렇기 때문에 xor 문제와 같은 문제도 해결해낼 수 있다.
지도학습에서 성능을 나타낼 수 있는 건 여러 개가 있다.
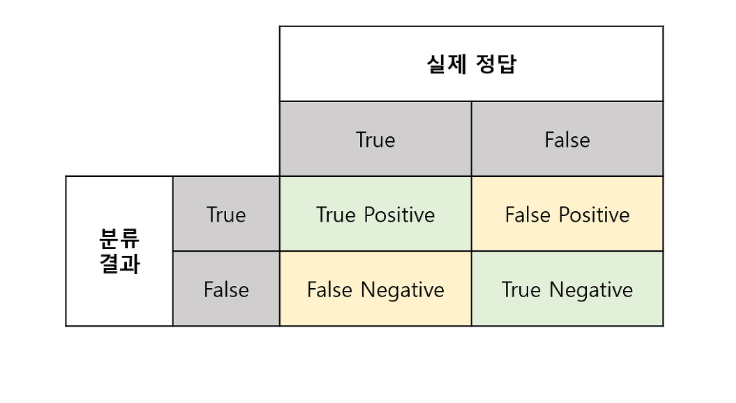
모델의 분류 결과와, 실제 답에 대한 비교를 위와 같이 나타낼 수 있을 때

제대로 예측했는지를 나타내는 '정확도'

모델이 positive라고 판단한 것 중 제대로 판단된 정도를 가리키는 '정밀도'
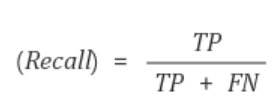
실제 positive 값들 중 모델이 제대로 판정한 경우의 비율을 나타내는 '재현율'이 있다.
단순히 정확도만 볼 것이 아니라 정밀도와 재현율도 제대로 확인을 하여야 모델의 성능을 확인할 수 있다.
우리가 만든 모델이 학습할 때 사용하지 않은 한 번도 보지 않은 데이터에 대한 성능을 끌어올리기 위해서 쓰는 과정 중 하나가 바로 '앙상블 기법'이다. 이는 성능을 끌어올리고, 노이즈에 안정적으로 대응할 수 있는 모델을 만든다.
앙상블 기법이 무엇이길래 그럴까?
먼저 앙상블 기법 중 하나인 배깅.
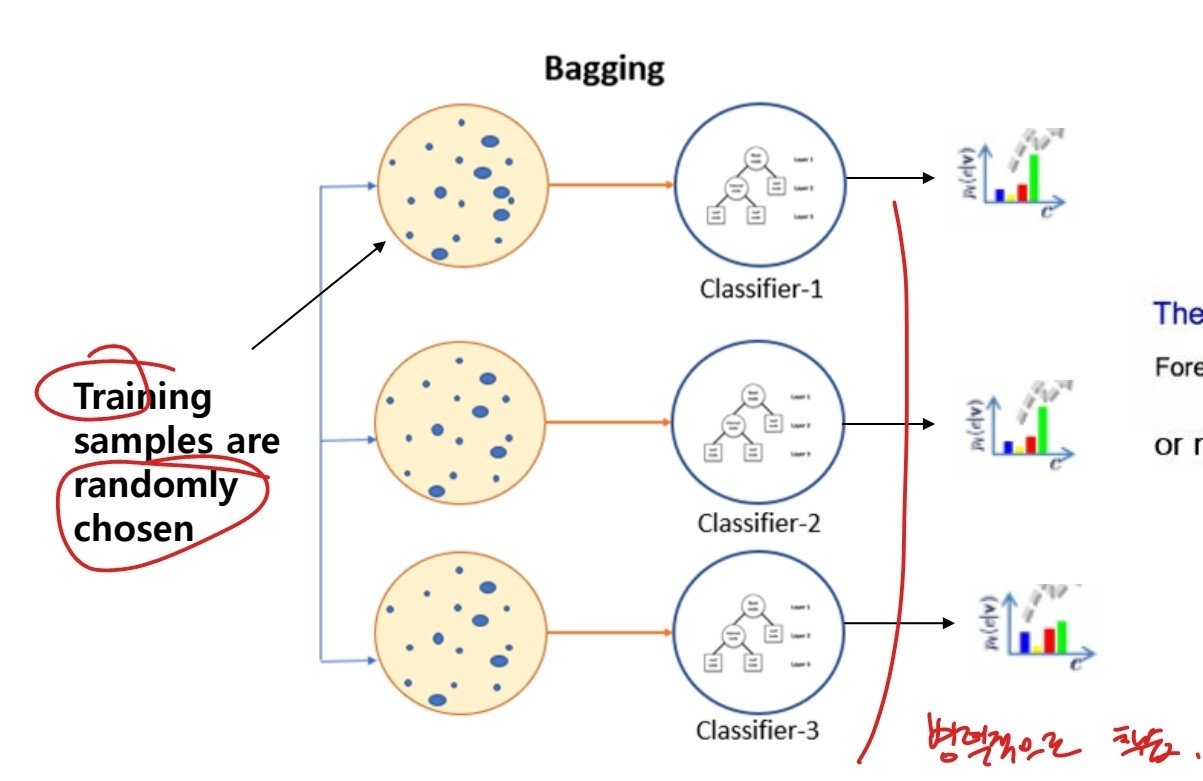
(출처: 이화여대 강제원 교수님 강의자료)
배깅은 데이터 샘플을 랜덤하게 추출하여 여러 모델들을 병렬 형태로 학습시키는 방식이다. 배깅은 (Bootstrapping + aggregating)의 준말로 데이터를 부트스트랩화 하여 나눈 후 각 데이터에 대한 모델을 병렬적으로 학습시킨 후 합쳐서 성능을 확인하는 방식.
여러 개의 모델로 동시에 학습하기에 다른 노이즈가 들어와도 강해지는 특징이 있다.
그리고 또 다른 앙상블 기법인 부스팅.
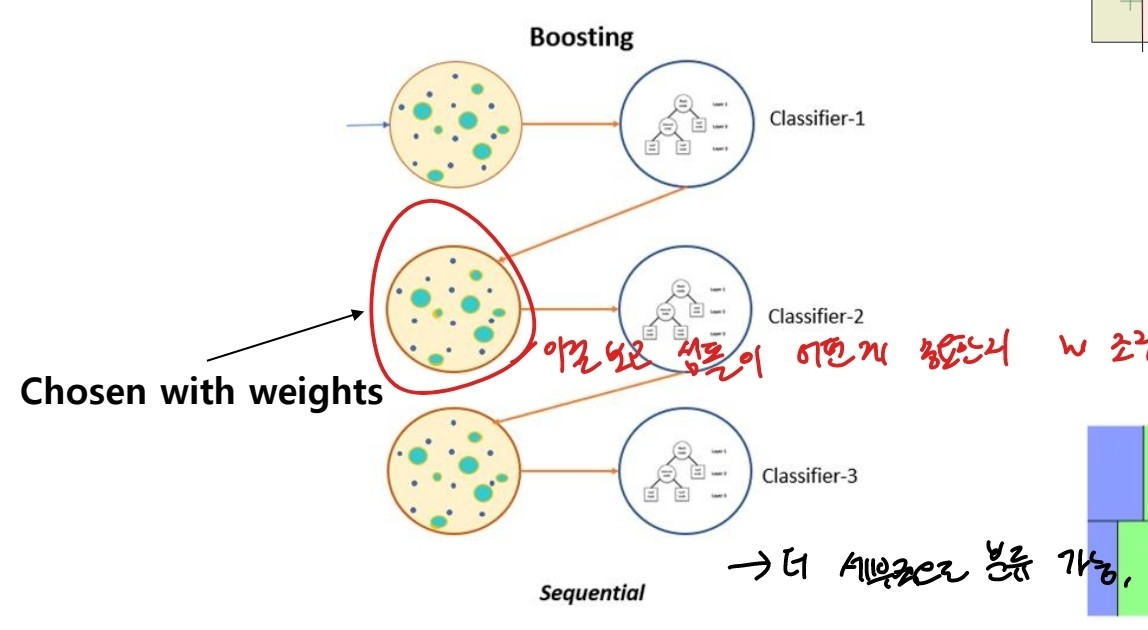
(출처: 이화여대 강제원 교수님 강의자료)
부스팅은 배깅과 달리 모델을 직렬로 연결하여 계속 학습하는 것인데 기존 데이터로 처음 학습시킨 후 나타난 결과에 따라 적절한 가중치를 메긴 후 반복적으로 모델을 만들어 학습시키는 것을 의미한다.
부스팅 기법을 통해 모델은 더 세부적으로 분류하여 성능을 높일 수 있다.
