포스팅 내용에 대한 저작권은 모두 LG Aimers에 있습니다
module4 딥러닝 강의 중에 드디어 RNN 파트를 시작하게 되었다. CNN은 인공지능 수업 들을 때 프로젝트를 해본 경험이 있어서 비교적 익숙했는데 RNN은 배운 경험이 있음에도 낯설었다. 이상하다 비트코인 데이터 돌려봤던 거 같은디
RNN(Recurrent Neural Network)
순환 신경망으로 시계열 데이터(주식 데이터, 텍스트 데이터 등)를 처리하는 모델.
이렇게 이야기하면 어떤 모델인지 감이 잘 오지 않을테니 그림으로 한 번 보자.
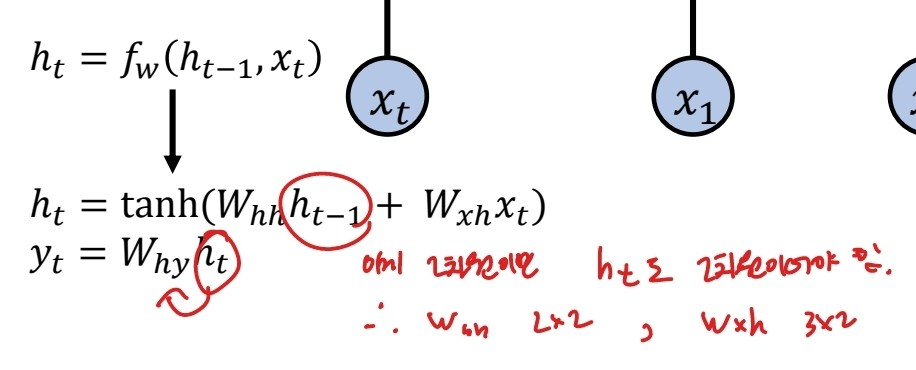
출처:LG Aimers module4 딥러닝 강의 자료
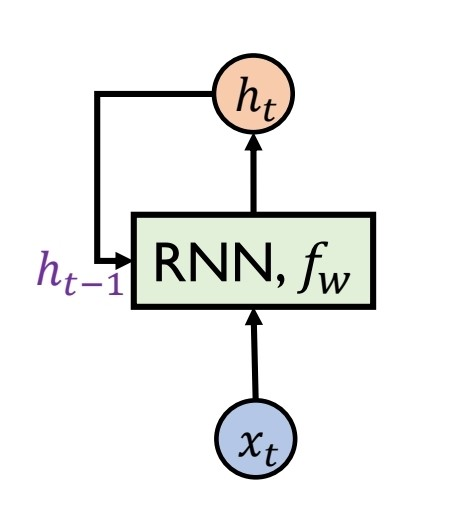
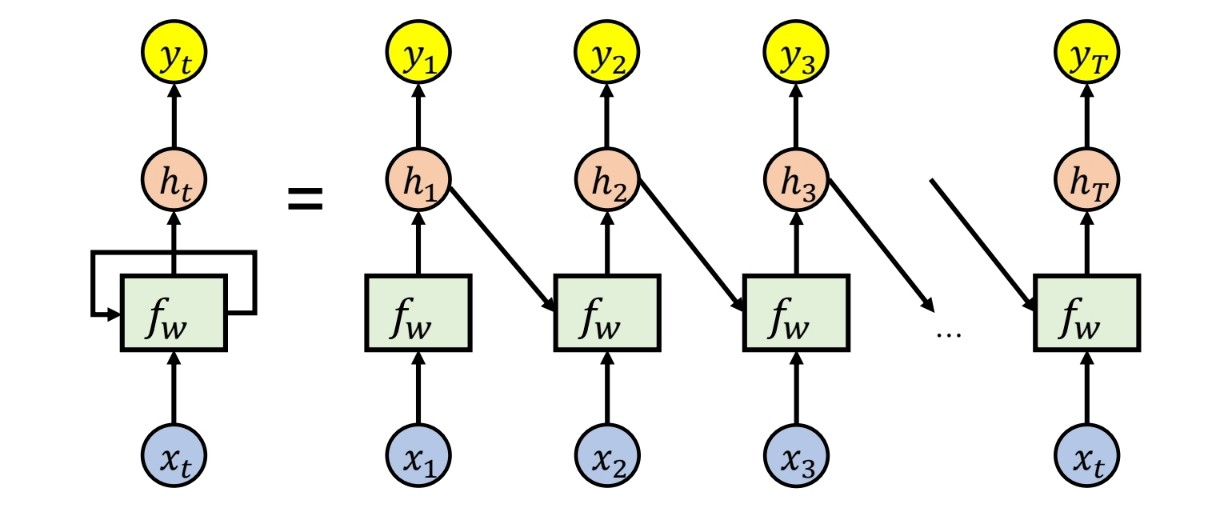
그림으로 보았을 때, 모델이 xt번째 데이터에 대해 학습 할 때 xt-1 데이터를 학습한 결과 값인 ht-1(활성함수 들어가기 이전)을 참고하여 함께 학습하는 순환적인 구조를 띤 형태이다.
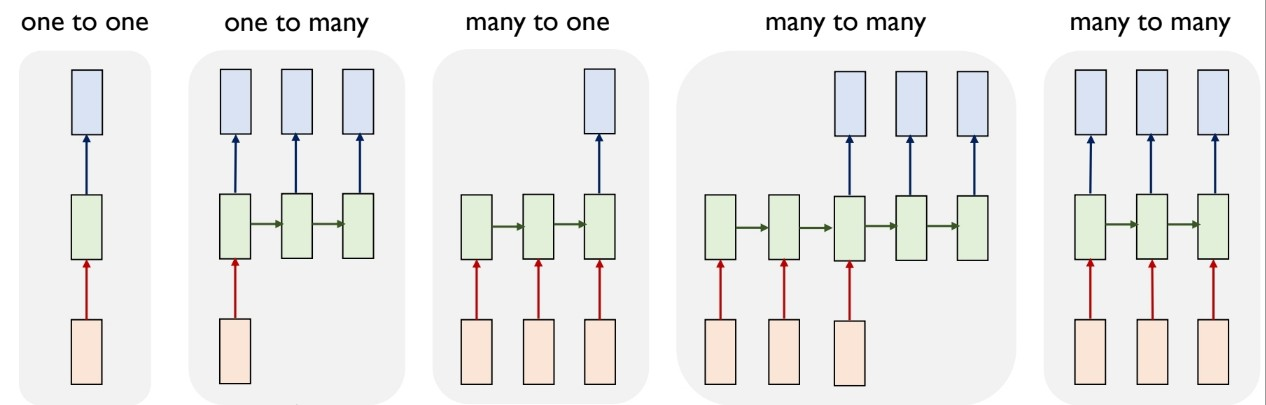
입출력 데이터의 형태에 따라 같은 RNN을 바탕으로 하지만 다양한 형태의 모델을 띠는데 한 번 보도록 하자.
출처:LG Aimers module4 딥러닝 강의 자료
- one to one : 일반 neural network 모델
- one to many : 입력 데이터는 하나의 time step을 가지며 출력 데이터는 여러 time step을 띠는 모델.
예) image cationing(이미지를 보고 이미지에 대한 설명을 하는 모델) - many to one : 입력 데이터는 여러 time step을 가지며 출력 데이터는 time step이 존재하지 않는 데이터일 때.
예) Sentimant Classification(문장을 보고 문장에 담긴 감정 요소를 표현하는 모델) - many to many ① : 가장 일반화된 형태로 입출력 모두 여러 time step 가짐. 그 중 입력 데이터의 마지막까지 다 학습한 후에 출력하는 형태
예) 문장 번역 모델 - many to many ② : 가장 일반화된 형태로 입출력 모두 여러 time step 가짐. 그 중 입력 데이터를 학습하면서 실시간으로 그때 그때 출력 데이터를 만들어내는 모델
예) 영상 프레임 단위 별 분류 모델
하지만 기본적인 RNN 모델의 경우 순환적인 구조로 같은 모델을 반복하여 학습하기 때문에 gradient vanishing, 혹은 gradient exploding 문제가 발생할 수 있다. 그렇기 때문에 이를 해결한 LSTM, GRU 모델을 자주 사용한다.
Seq2Seq Model
이는 입출력 데이터 모두 일련의 단어들로 이루어진 문장이며, 입력 데이터를 처리하는 encoder와 출력 데이터를 생성하는 decoder로 이루어져 있다.
encoder 작업이 다 끝난 후 decoder 작업을 수행하는 모델. ouptut vector와 hidden state vector은 항상 사이즈가 같아야 한다.
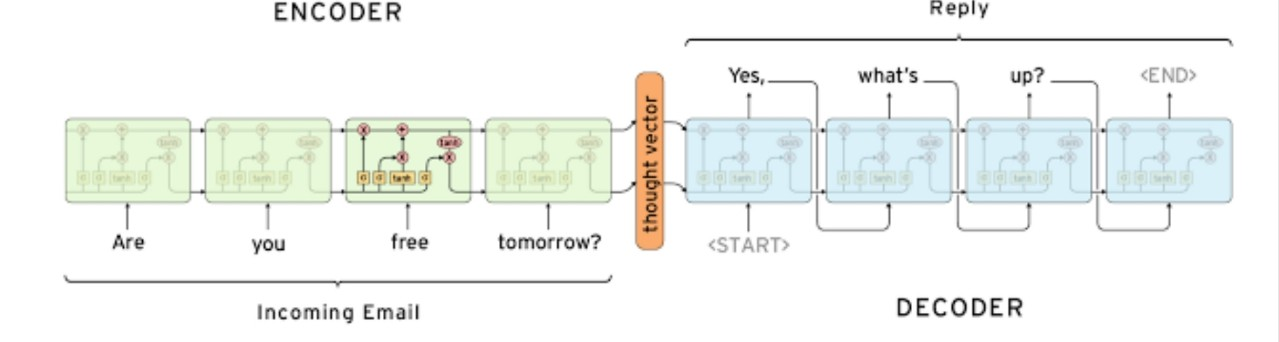
출처:LG Aimers module4 딥러닝 강의 자료
기존 seq2seq모델의 경우 encoder이 작업이 모두 끝난후 만들어진 hidden state vector에 입력 데이터에 대한 정보가 모여 있어 병목 현상이 나타난다. 이를 해결하기 위한 방법이 무엇이 있을까?
바로 "Attention", encoder의 최종 output만을 decoder의 input으로 받는 것이 아니라 각 time step마다 일부 hidden state vector을 받아 예측에 활용하는 것이다.
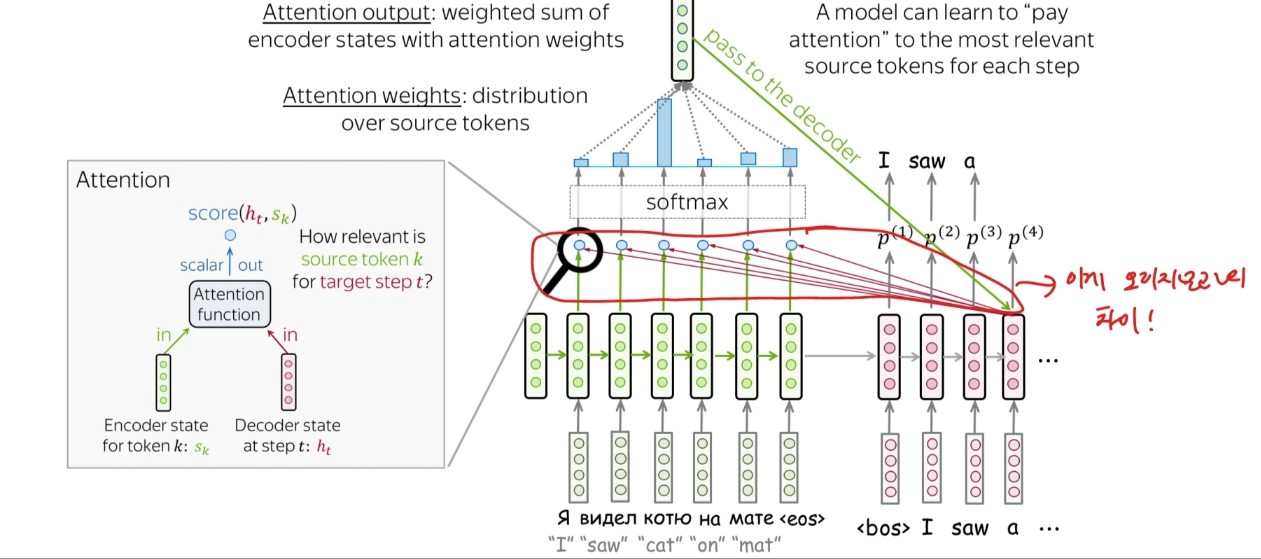
출처:LG Aimers module4 딥러닝 강의 자료
위와 같은 형태로 encoder의 현 상태에 대한 state vector, decoder의 state vector로 점수를 내고 softmax를 통과 시킴으로써 input 데이터의 각 time step에 담긴 데이터와 decoder에서 출력할 데이터와의 관련성을 확인할 수 있다.
또한 back propagation을 할 때 특정 입력 데이터에 관한 가중치를 수정하고 싶을 때, 기존 RNN 모델의 경우 수많은 time step을 지나며 학습해야 하기에 학습이 잘 안 될 때도 존재한다. 그러나 attention output이 존재할 때에는 그 방향으로도 back propagation이 가능하기에 기존 RNN 모델보다 학습이 용이해진다. 이해가 어렵다면 아래 그림을 확인해보도록 하자.
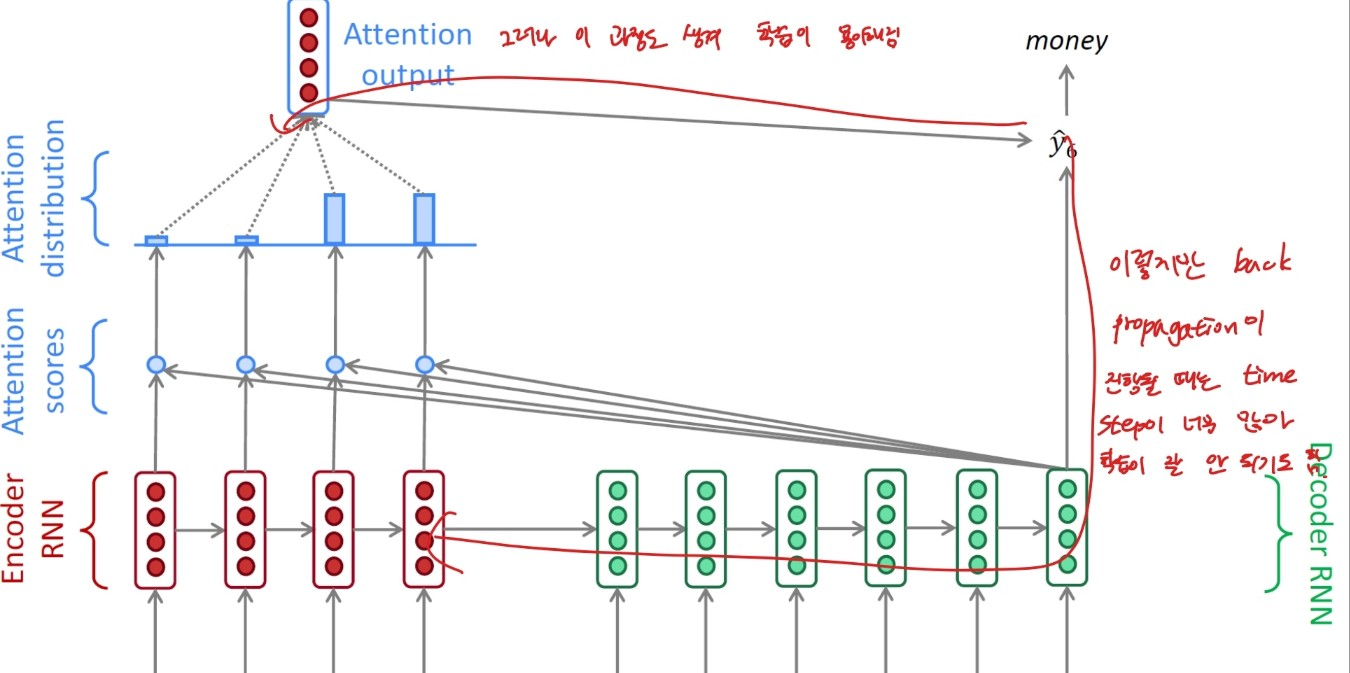
출처:LG Aimers module4 딥러닝 강의 자료
이러한 attention을 활용한 seq2seq 모델의 경우 번역 모델에서 용이해 언어마다 다른 어순을 파악하는데 좋다.
seq2seq with attention 모델에서는 attention을 부가적인 요소로만 사용했지만 attention 모듈을 encoder, decoder 모델 자체로 사용하는 모델이 있다...?!
Transformer
RNN이나 CNN을 쓰지 않고 인코더와 디코더를 N개씩 사용하는 구조
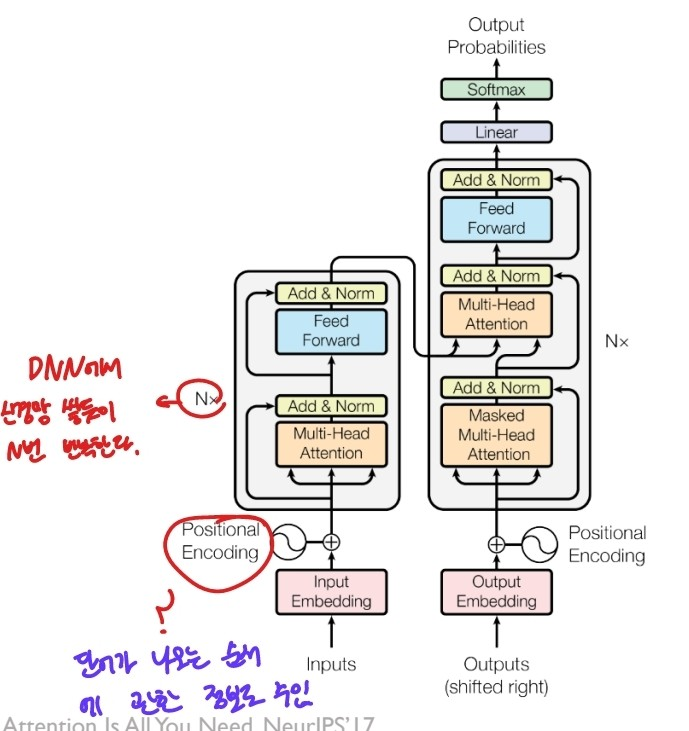

출처:LG Aimers module4 딥러닝 강의 자료
transformer의 경우 self-attention을 활용하는데 이에 대해 자세히 알아보자.
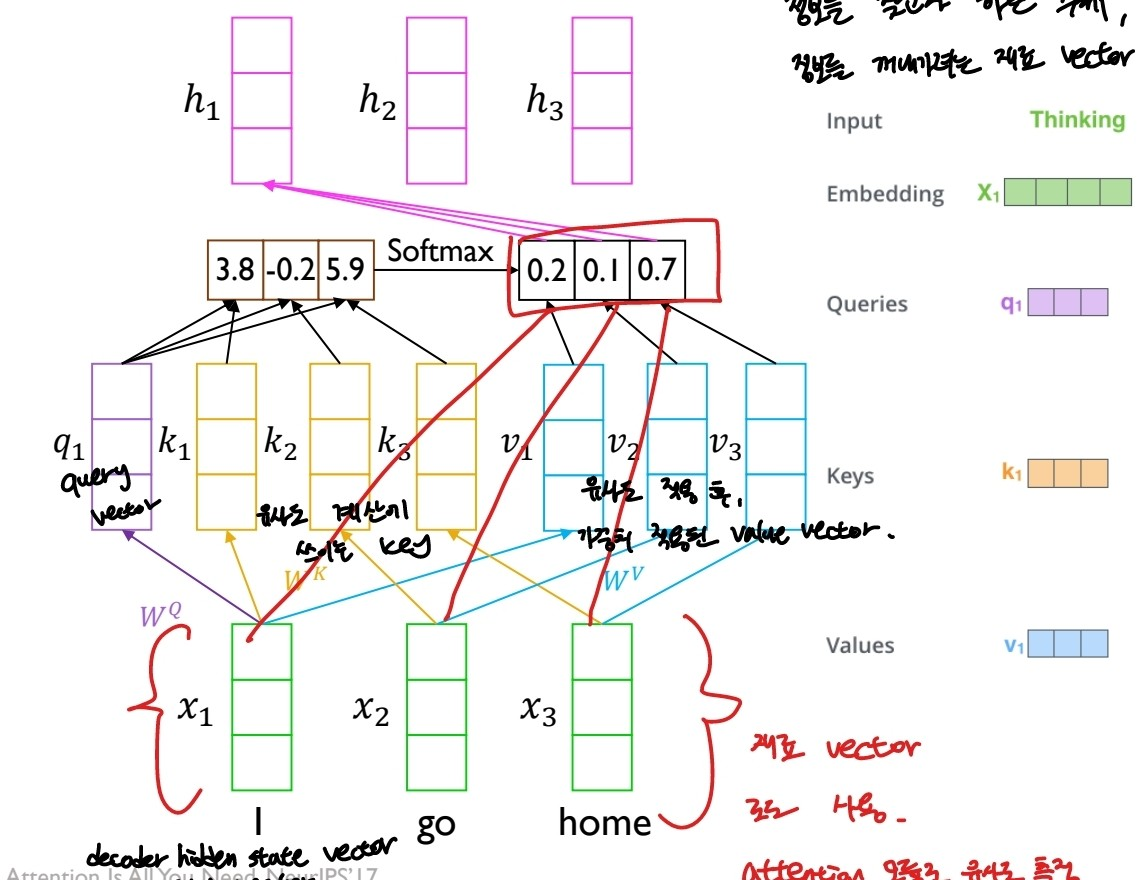
출처:LG Aimers module4 딥러닝 강의 자료
x1~x3의 시계열 데이터가 입력 데이터로 들어오고, 각 데이터들에 대한 유사도를 구해야 한다. 예를 들어 h1은 x1 데이터에 대한 각 (데이터들의 유사도)*value vector
x1 데이터는 비교 대상이 되기 위한 query vector, 유사도 측정을 위해 쓰이는 key vector, 유사도 측정 후 그에 관한 가중치를 적용하기 위한 value vector 이렇게 활용될 수 있다. 각 Q, K, V 벡터는 가중치 행렬을 곱하여 만들어낼 수 있다.
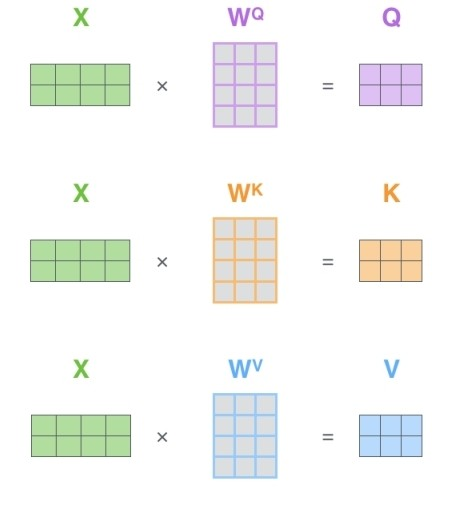
출처:LG Aimers module4 딥러닝 강의 자료
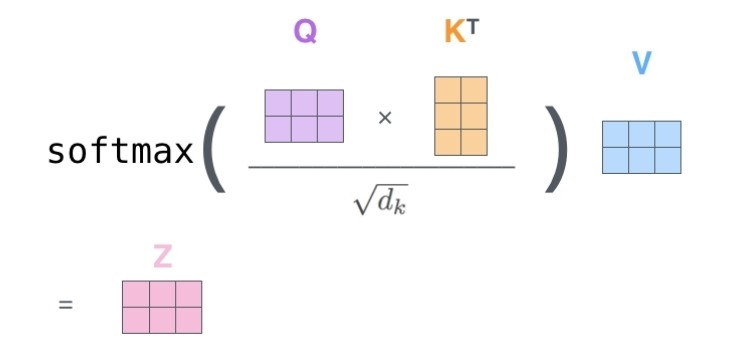
출처:LG Aimers module4 딥러닝 강의 자료
여기서 dk는 key vector의 차원 수를 말하는데 이를 왜 나누어줄까? key vector의 값이 커질수록 분산이 커지기 때문에 softmax 함수는 한 값 100%가 되게끔 몰린다. 이를 방지하기 위해서 K 벡터의 차원 수의 루트로 나눠 주는 건데... 뭐가 됐든 쓸 데 없는 요소를 제거해주는 과정
위와 같은 방식으로 각각의 query, key, value vector을 병렬적으로 attention을 구하는 방법을 multi head attention이라 한다.
각 sequence마다 단어들이 query가 되어 유사도를 측정하기 때문에 기존 seq2seq 모델의 문제를 해결할 수 있다.
그렇다면 transformer의 decoder에서는 어떤 게 다르게 동작할까?
우선 transformer의 경우 입력 데이터를 time step에 따라 순서대로 받는 것이 아닌 한 번에 입력 받고, pisitonal encoding 과정을 거쳐 각 데이터들의 순서를 같이 데이터로 주는 형태이다.
그렇기 때문에 decoder에 들어가는 정보는 다음 time step의 데이터를 같이 받기 때문에, 학습할 때 학습을 통한 결과로 내는 것이 아닌 함께 들어와있는 다음 time step을 베껴가는 식으로밖에 학습하지 못 한다. 이를 방지하기 위해 maske self-attention 학습이 이용된다.

출처:LG Aimers module4 딥러닝 강의 자료
Self-Supervised Learning
레이블이 따로 존재하지 않은 데이터가 주어졌을 때, 주어진 데이터의 일부를 가린 후 가려진 부분을 예측하는 방식으로 학습하는 모델


출처:LG Aimers module4 딥러닝 강의 자료
그림에서 가려진 부분을 채우는 학습을 하거나 퍼즐을 맞추는 학습을 통해 동물 머리의 위치 등 유의미한 정보를 학습해간다.

출처:LG Aimers module4 딥러닝 강의 자료
위 그림에서 Task A는 레이블이 지정되어 있지 않은 데이터를 학습하기 위한 과정으로 그 일부는 이미지의 패턴을 읽는 과정을 포함하고 있다. 그렇기 때문에 이 과정을 떼와서 다른 학습, Task B에 활용할 수 있다.
BERT
transformer을 활용한 모델로 masked language modeling과 next-senetence prediction task를 학습하면서 매우 큰 데이터를 다룰 수 있는 모델이다.
-
Masked Language Model(MLM)
: 입력 데이터 중 일부를 랜덤하게 가린 후 가려진 부분을 예측하는 학습을 하는 모델-주어진 단어들의 15프로만 가리며, 그 15프로 중에서도 80프로만 [MASK] 표시로 가리며 나머지 10프로는 랜덤한 다른 단어로, 나머지 10프로는 원래 주어진 단어로 둔다. -
Next Sentene Predcition(NSP)
: 문장 B가 문장 A 다음에 오는 문장이 맞는지 아닌지 판단하는 학습.
출처:LG Aimers module4 딥러닝 강의 자료- [CLS] : 두 문장이 실제 이어지는 문장인지 판단해달라는 신호 - [SEP] : 문장 끝을 나타내는 신호
