대회 설명 / 링크
이번 경진대회의 목표는 일정 시간별로 제품이 생산되는 공정에서 생산된 제품이 어떤 측정치를 가질지를 회귀 모델을 통해 예측하는 것이다. 본 프로젝트에서 사용한 데이터셋은 여러대의 기계를 통해 제품을 생산하는 공정에서 각 기계의 각 시간별 상태와 해당 상태에서 생산된 제품의 측정치로 구성되어 있다.
이를 이용하여 임의의 시간에서 임의의 기계 상태가 주어졌을 때 생산된 제품의 측정치는 어떻게 나올 것인지를 예측하는 모델을 총 2개 만들어야 했다.
생산 공정 과정은 아래와 같다.
-
Machine 1, 2, 3에 해당하는 3개의 기계가 병렬적으로 동작하여 각 기계의 출력물을 Combiner으로 전달
-
Combiner의 첫 산출물 생산, 15개의 위치에서 산출물의 특정 값이 측정 (무슨 측정값인지는 구체적으로 알려지지는 않았다)
-
2번에서 측정된 15개의 값이 첫번째 Stage(Stage1)의 출력값
-
첫번째 Stage를 통과한 산출물이 Machine 4와 Machine 5를 차례로 (즉 직렬적으로) 통과
-
Machine 5를 통해 생산된 산출물이 최종 산출물이 되며, 앞서 첫번째 Stage와 같이 여기서도 15개의 위치에서 특정 값 측정
-
5번에서 측정된 15개의 값이 두번째 Stage(Stage2) 의 출력값
이 과정에서 각 기계의 센서 값과 각 Stage의 Output이 시간별로 기록된 것이 전체 데이터셋이 된다. 이를 Stage 1과 Stage2로 나누어 각 Stage의 회귀 모델을 구현하는 것이 이번 경진대회의 목표이다.
각 Stage 별로 모델을 하나씩 구현해서 총 2개의 모델을 구현해야 하며, 두개의 예측 결과값을 따로 제출해야 한다. 채점은 이 둘의 R2 Score를 계산하여 이것의 평균을 통해 이루어진다.
대회 진행 과정
우선, 이번 대회에서 주어진 데이터는 feature 수가 정말 많았기 때문에 feature 선택을 정말 잘 해야할 것 같다는 생각을 했다. 그래서 Feature을 제거하지 않은 상태로 RandomForestRegressor 알고리즘을 통해 모델을 학습시킨 후에 각 feaure의 중요성을 확인하고, 가장 영향을 많이 주는 상위 20개의 feature들을 학습에 사용했다.
Ridge, LSTM 등 여러 알고리즘들을 사용해보았지만, RandomForestRegressor의 결과가 가장 좋았다. 그래서 이 학습 알고리즘을 이번 대회에서 사용하기로 했다.
대회 성적을 향상시키기 위해 feature 추가, 알고리즘 하이퍼 파라미터 튜닝을 하였다.
추가할 feature을 선정하기 위해 이전에 파악한 각 feature의 중요성을 고려하였다. 하나하나 넣어보며 성능을 향상시켜주는 feature은 그대로 두었고, 성능을 낮추는 feature은 제거했다. 시계열 데이터인데 시간 관련 정보가 index로 설정되어 있어서 이를 feature으로 만들어주었다. hour, minute, second라는 feature을 만들어주었고, hour은 성능을 낮추기 때문에 이후 제거하였다. minute과 second feature의 영향력이 크다는 것을 파악할 후에 minsec이라는 minute과 second를 합친 feature을 만들어주었고, 이를 통해 모델의 성능이 크게 향상하였다.
하이퍼 파라미터 튜닝을 위해 GridSearch를 사용하였고, 이를 바탕으로 조금씩 값을 수정하였다.
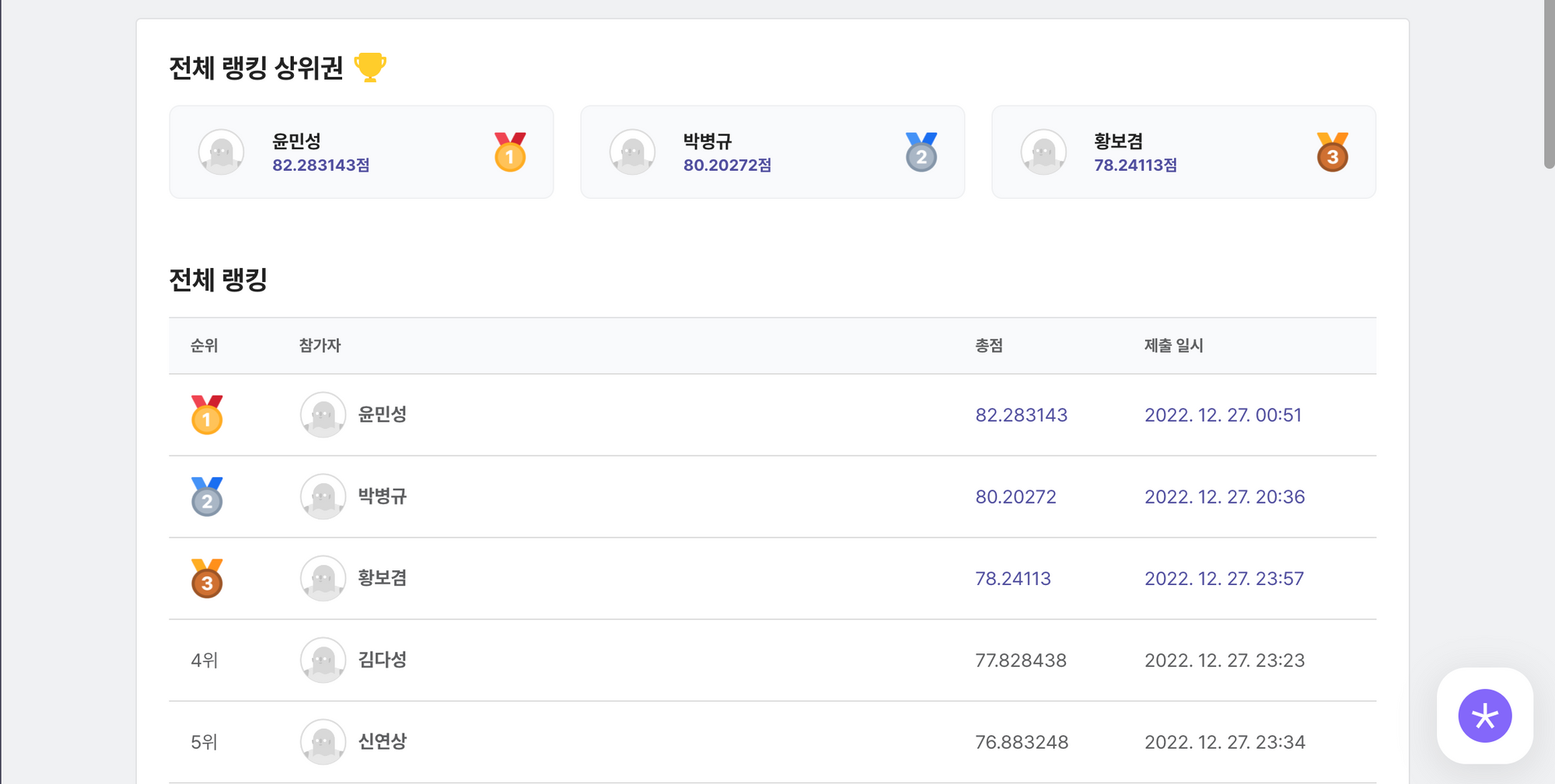
이러한 과정을 통해 대회 종료 하루 전 3등 자리를 차지할 수 있었다. 이후 모델 성능을 향상시키기 위해 다른 feature들을 활용하여 하나의 feature을 새로 생성해보는 등 여러 시도들을 해보았지만, 성능이 오르지 않았다.
그러다가 대회 종료 30분 전, 4등이었던 김00님이 3등 자리를 차지했다. 그래서 급하게 다른 학습 알고리즘들을 사용해보자는 생각을 했다. 이전에 사용해보지 않았던 ExtraTreesRegressor을 RandomForestRegressor의 하이퍼 파라미터와 동일한 하이퍼 파라미터로 설정하고 사용한 결과, 다시 3등을 차지할 수 있었다. 이후 트리 생성 갯수를 1500으로 하이퍼 파라미터를 설정하며 78.24점을 기록할 수 있었다.
대회 결과
최종 3등(우수상)
Code
느낀 점 / 배운 점
대회에 참여하며 각 과정 하나하나가 정말 중요하다는 생각을 했다. Feature 처리를 통해 점수가 크게 올랐고, 학습 알고리즘 변경과 하이퍼 파라미터 튜닝을 통해 성능이 많이 향상되었다. 각 과정 하나하나가 모델의 성능에 많은 영향을 주고 있음을 다시 한번 깨달았고, 어느 것 하나 작게 여겨서는 안된다는 것을 깨달았다.
사실 연말까지 계속 쉬려고 했는데 갑자기 대회가 개최되어서 장려상만 받자는 마음으로 시작을 했고, 그래서 처음에는 56점으로 3위였다가 대회가 진행될수록 계속 순위가 떨어지는 것을 바라보고만 있었다. 그런데 장려상을 받지 못할 순위로 떨어질 것 같다는 생각을 했다. 그래서 조금만 더 올려보자는 생각으로 여러 시도를 해보았는데, 성적이 크게 올라서 3등을 하자. 라는 마음가짐으로 계속 노력했던 것 같다.
이번 대회 내내 너무 재밌었다. 다른 사람들과 경쟁하는게 너무 재밌었고, 머리를 쥐어싸매고 머신러닝 모델들을 사용해보는게 너무 재밌었다. 또한, 내가 생각해낸 아이디어들을 바로바로 모델 학습에 적용했을 때 성능이 향상되는게 너무 재밌었다.

코드 보고 싶었는데 들어가지지 않네요 ㅜㅜ