
대회 설명
대회 진행 과정
SSDC-KATUSA ML/DL 팀 멤버 2명과 함께 진행했다. 일과 이후의 시간과 주말 외박 시간을 활용하여 대회 준비를 했다. 물론 구내식당 식수인원 예측 경진대회도 시계열 관련 대회였지만, 이번 대회는 예측 기간인 2022년의 데이터를 학습에 사용할 수 없다는 점에서 더 난이도가 높았다. 시계열을 공부해본적이 없어서 처음부터 여러 실수를 했다. 날씨, 지하철 데이터 등 여러 외부 데이터를 활용하여 예측을 진행하기 위해 데이터를 준비했는데, ARIMA와 FBProphet과 같은 시계열 모델들은 x와 y 데이터만 입력을 받았다. 그래서 XGBOOST, LSTM과 같은 모델들을 사용해보려고 했으나 외부 데이터를 사용할 수 없기 때문에 시계열을 위한 모델을 사용해야겠다는 생각을 했다. ARIMA의 사용 방법보다 FBProphet의 사용 방법이 더 간단하기 때문에 FBProphet을 사용했다. 하이퍼 파라미터를 계속 수정하며 가장 좋은 성능을 내는 모델을 만들려고 노력했다.
대회 결과
Public(2022.01 - 2022.06) : 28등(MAE 1.71562)
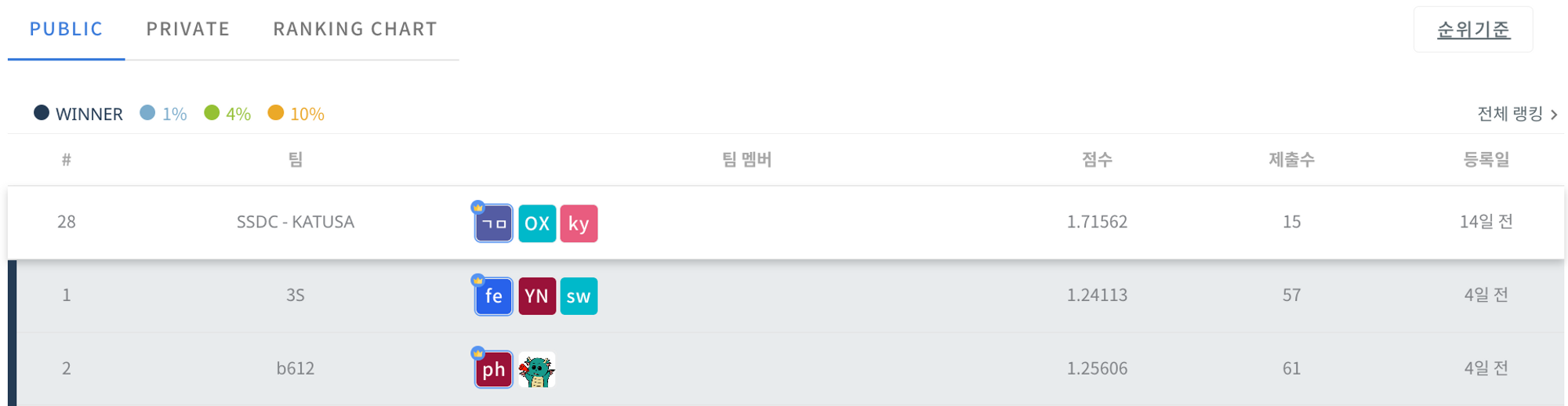
Private(2022.01 - 2022.11) : 19등(MAE 2.03502)
Code
느낀 점 / 배운 점
이번 대회는 정말 너무 힘들었다. 지하철 데이터를 사용하려고 힘들게 전처리를 다 했는데 알고보니 외부 데이터를 학습할 때 사용할 수 없었고, 지금까지 내가 참여했던 대회들과는 너무 달랐다. 이 대회에 할애할 수 있는 시간도 매우 제한적이었다. 그래도 일단 참여 했으니까, 이 대회를 통해 하나라도 배울 수 있을 것이라는 생각으로 정말 열심히 공부하고, 생각하고, 코드를 작성했다. 대회가 마무리될 때 쯤에는 시간을 조금이나마 더 대회에 쏟기 위해 운동 가는 것을 포기했다. 부산 가는 열차에서도 열심히 코드를 돌렸다. 이 정도의 노력을 통해 나름 좋은 결과가 나와서 다행인 듯 하다.
더 다양한 예측 대회에 참여해야겠다는 생각을 했다. 예측 대회 뿐만 아니라, CV 대회에도 더 참여해야겠다는 생각을 했다. 시계열 데이터는 전처리가 매우 중요한데, 이 대회를 통해 여러 시계열 데이터 전처리 기법들을 배웠다. log 함수를 씌우는 것, 차분하는 것 등 여러 전처리 기법들을 적용해보며 적용했을 때의 결과들을 비교하며 가장 잘 맞는 기법을 사용할 수 있었다. 이를 통해 더 많은 모델을 알수록, 그리고 전처리 방법을 더 많이 알수록 대회에서 유리하다는 것을 깨달았고, 대회 참여 이전에 더 많은 공부를 해야겠다는 생각을 했다. 그리고 공부를 할 때 이를 제대로 활용할 수 있도록 모델의 활용에 포커스를 맞추면 좋을 것 같다는 생각을 했다.
이번 대회에서 리더 역할을 하며 리더의 중요성을 다시 한번 느꼈다. 일단 팀을 이끌 때, 특정 멤버가 어떤 역할을 할 것인지, 그리고 어떤 업무를 언제까지 해야하는지 정확하게 정해줘야한다. 또한, 팀 회의가 주기적으로 이루어져야한다. 팀 회의에서는 주어진 업무를 잘 소화하고 있는지, 업무를 소화할 수 있을만한 상황인지, 어려운 점은 없는지 등 멤버들의 상태와 업무 현황을 주기적으로 확인해야한다.
참가 자격을 잘 살펴야한다. 이번 대회를 참가하기 이전, 참가 자격을 잘 살폈어야한다. 이번 대회 참가 자격만 증명할 수 있었다면 10등 안에 들 수 있었다. 잘하면 수상도 가능했다. 그러나 참가 자격을 잘 살펴보지 않았고, 이를 사전에 확인해보지 않았기 때문에 높은 점수를 받았음에도 불구하고 탈락했다.
