
[CUDA 공부/책] 3.cuda_memory.cu
<CUDA 기반 GPU 병렬 처리 프로그래밍> 책 읽으며 실습 코드 실행해보고 있음.(코드는 https://github.com/bluekds/CUDA_Programming/tree/master/Book_BJ 여기에서 확인할 수 있음. 근데 짧은 코드면 나
[CUDA 공부/책] 2-1.hello_cuda.cu
<CUDA 기반 GPU 병렬 처리 프로그래밍> 책 읽으며 실습 코드 실행해보고 있음.(코드는 https://github.com/bluekds/CUDA_Programming/tree/master/Book_BJ 여기에서 확인할 수 있음. 근데 짧은 코드면 나
[CUDA 공부] 1-2. elementwise.py
https://github.com/xlite-dev/LeetCUDA/blob/main/kernels/elementwise/elementwise.py위의 python 코드에 대한 설명 (from GPT)이 파이썬 스크립트는 CUDA 커널을 PyTorch 확장으로
[CUDA 공부] 1-1. elementwise.cu
CUDA 공부를 시작한다.우선 보고 있는 자료는 LeetCUDA (https://github.com/xlite-dev/LeetCUDA) 와 <CUDA 기반 GPU 병렬 처리 프로그래밍>이라는 책.책은 이제 차근차근 읽어나갈 거고, 우선 LeetCUDA의
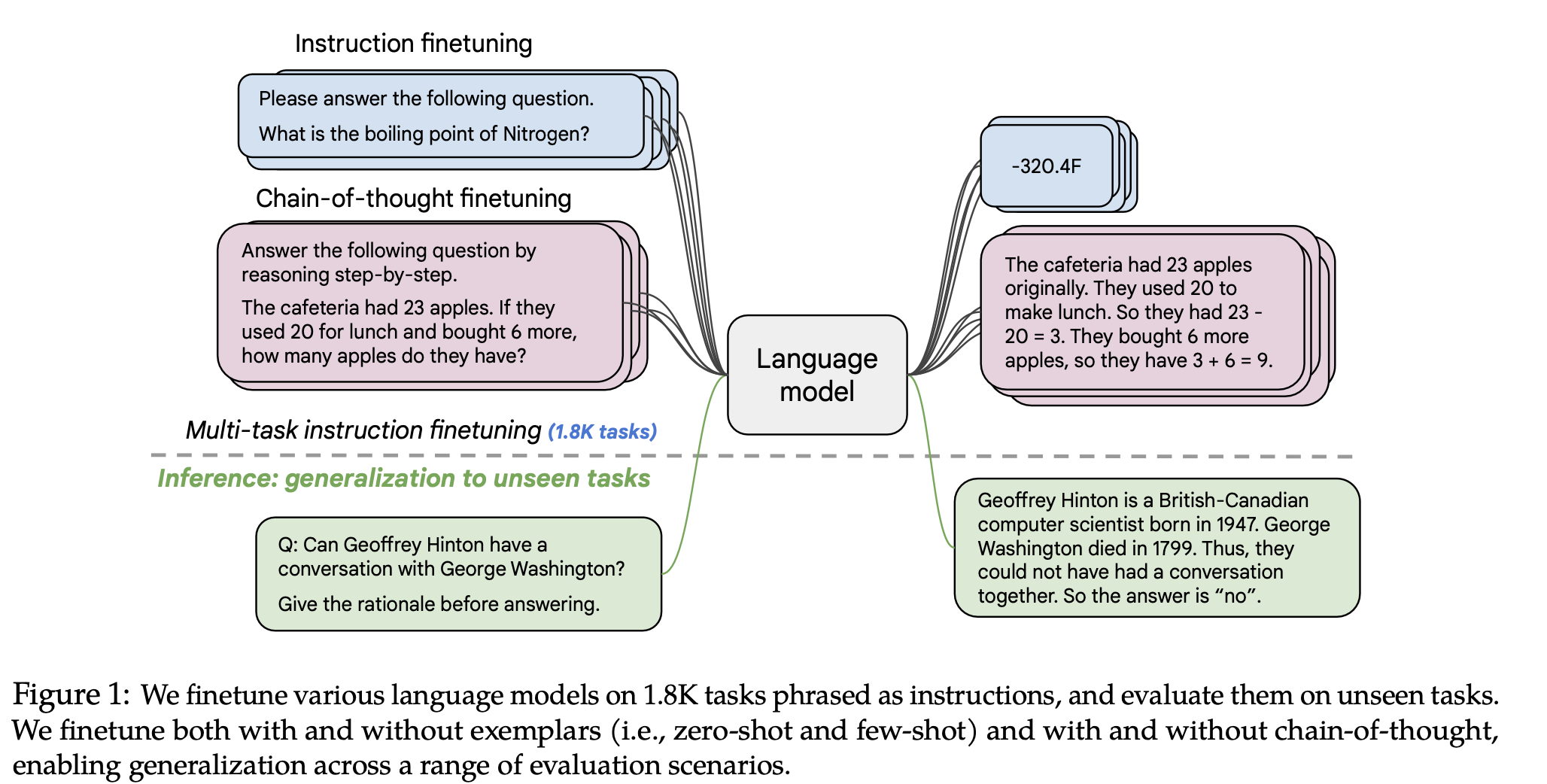
[FLAN] Scaling Instruction-Finetuned Language Models
기본적으로 instruction tuning은 instruction과 입력을 넣으면 원하는 출력이 나오게 하도록 하는 학습 방식이다. 다양한 instruction+input & output pair를 주고 학습시킴으로써 이 지시를 모델이 이해하도록 하는 게 주 목적.
Instruction Tuning 개요
https://newsletter.ruder.io/p/instruction-tuning-vol-1 읽고 정리겸 끄적끄적,,Natural Instructions영어, 193k examples, 61 taskscommon schema를 사용해서 다른 데이터셋에 비
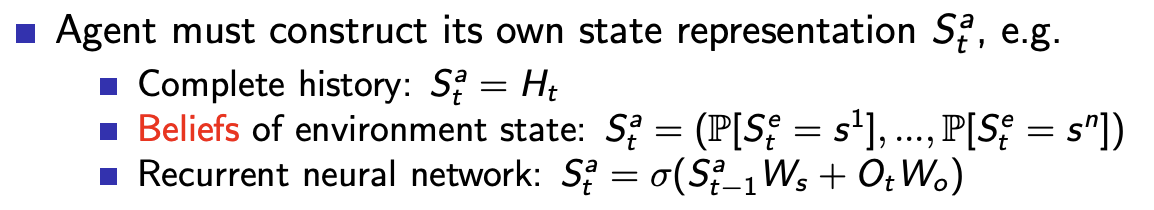
RL의 기초 Introduction to RL
Supervisor가 없고 reward signal만 있다.피드백은 즉각적이지 않고 지연된다.'시간'은 중요하다. (Time really matters)에이전트의 액션은 이후에 받는 데이터에 영향을 끼친다. (Agent's actions affect the subseq
[RL] Reinforcement Learning
공부,, 시작해봅니다. 참고 강의 자료:https://www.davidsilver.uk/teaching/참고 Textbook:http://incompleteideas.net/book/RLbook2020.pdf