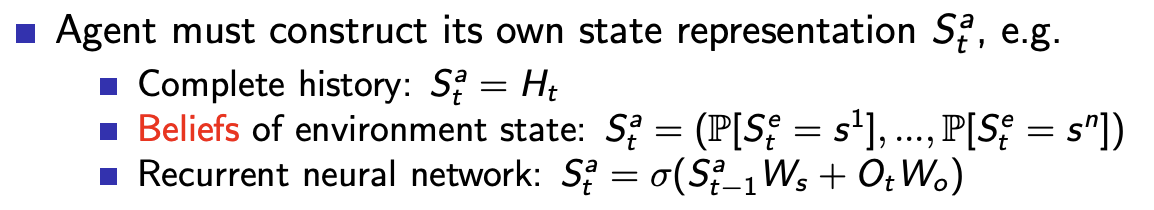RL의 기초 Introduction to RL
RL의 특징
- Supervisor가 없고 reward signal만 있다.
- 피드백은 즉각적이지 않고 지연된다.
- '시간'은 중요하다. (Time really matters)
- 에이전트의 액션은 이후에 받는 데이터에 영향을 끼친다. (Agent's actions affect the subsequent data it receives)
The RL Problem
Rewards
- A reward is a scalar feedback signal 리워드는(보상은) 숫자이다.
- Indicates how well agent is doing at step t 에이전트가 step t에 얼마나 잘했는지 보여줌.
- The agent's job is to maximise cumulative reward 에이전트는 누적 보상을 최대화하는 것이 목적.
보상가설은 다음과 같다.
All goals can be described by the maximisation of expected cumulative reward
"모든 목표는 예상되는 누적 보상의 최대화로 설명될 수 있다."
Agent and Environment 에이전트와 환경
At each step t the agent:
- Executes action
- Receives observation
- Receives scalar reward
The environment:
- Receives action
- Emits observation
- Emits scalar reward
t increments at environment step
History and State
History는 observations, actions, rewards의 sequence
history에 따라서 에이전트는 액션을 선택하고, 환경은 ovservations/rewards를 선택한다.
State is the information used to determine what happens next
state는 history의 function:
Environment State
env state는 환경의 private representation.
환경이 다음 observation/reward를 선택하기 위해 사용하는 whatever 데이터임.
환경 state는 보통 에이전트가 모름.
Agent State
에이전트의 internal representation.
에이전트가 다음 액션을 선택하기 위해 사용하는 whatever 정보임.
RL 알고리즘이 사용하는 information.
Information State (== Markov state)
history의 모든 useful information을 갖고 있음.
정의
A state is Markov if and only if
“The future is independent of the past given the present”
"현재가 주어졌을 때 미래는 과거와 독립적입니다." <- 현재만 중요. 과거는 버림. 과거는 현재에 이미 표현되어 있음.
Once the state is known, the history may be thrown away
상태를 알고 난 다음에는 history를 버릴 수 있습니다.
- The environment state is Markov
- The history is Markov
Fully Observable Environments (Markov decision process, MDP)
에이전트는 env state를 다 볼 수 있음
Agent state = env state = information state
Partially Observable Environments (POMDP)
에이전트는 env를 indirectly 볼 수 있음
agent state =/= env state
에이전트는 own state representation 을 만들어야 함
- Complete history를 사용할 수도 있고,
- env state에 대한 믿음(Beliefs)으로 만들 수도 있고,
- RNN도 그 중 하나.