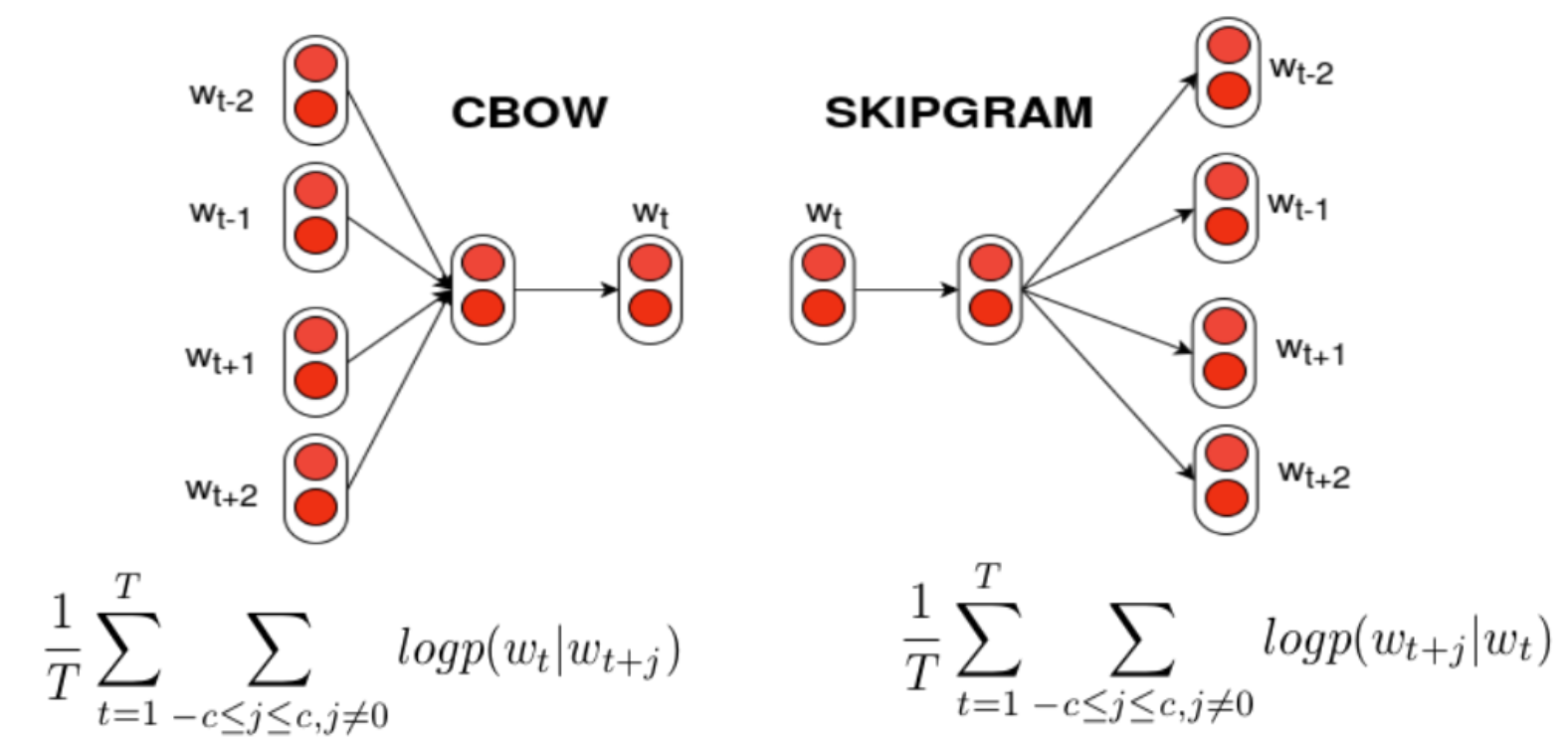
주제: Word2Vec
1. NLP이란?
-
자연어 처리(NPL, Natural Language Processing)
: Text 데이터를 분석하고 모델링하는 분야 -
자연어 이해 (NLU, Natural Language Understanding)
: 주어진 텍스트의 의미 파악 -
자연어 생성 (NLG, Natural Language Generation)
: 주어진 의미에 대한 자연스러운 Text 생성

1.1 NLP에 등장하는 용어 정의
-
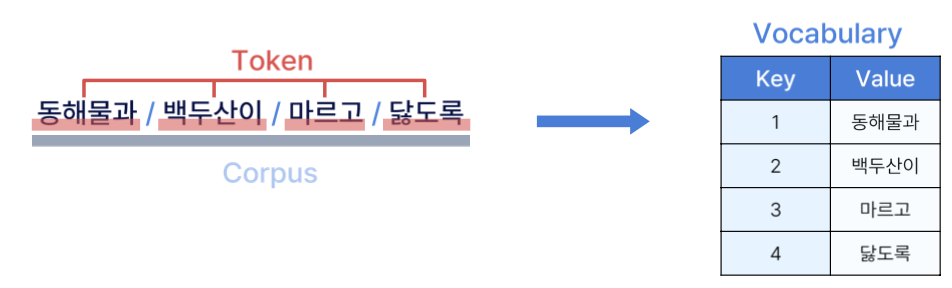
Corpus (말뭉치)
: 자연어 처리를 위해 수집된 텍스트 데이터의 집합 -
Token (토큰)
: 텍스트를 나누는 최소 단위로, NLP에서 처리할 수 있는 의미 있는 단위 -
Vocabulary (사전)
: 특정 Corpus에서 사용되는 고유한 토큰들의 집합으로 Token들의 key와 value를 저장
2. Word Embedding
-
단어를 고정된 크기의 벡터로 표현하는 것으로 기계가 텍스트를 이해하고, 처리할 수 있도록 하는 방법을 의미한다.
-
Word2Vec은 Word Embedding 방법론 중 한 방식을 의미한다.
-
Word Embedding은 단어를 밀집 벡터의 형태로 표현하는 방법을 의미하며 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과를 임베딩 벡터이다.
🎲 특징
1) 유사한 단어들은 벡터 공간에서 가깝게 위치하고, 고차원의 데이터를 저차원으로 변환해 연산량을 감소시킨다.
2) 단어 간의 유사성을 기하하적으로 표현할 수 있다.
ex) 왕 - 여자 + 남자 = 남자왕3) 단어 간의 관계를 잘 반영한 벡터를 생성하여, 이를 기반으로 한 연산이 가능하다.
4) 단어의 다양한 의미를 구빈하지 못하고, 하나의 벡터로 표현된다.
ex) Board는 위원회(이사회), 탑승하다 등 두 가지 의미가 있지만 이 둘을 구분할 수 없다.
2.1 밀집표현과 희소표현
1) 밀집 표현
- 단어를 사용자가 설정한 값으로 벡터 표현의 차원을 맞추는 방식을 의미한다. 벡터 내의 숫자는 실수를 갖고 inde 역할이 아닌 단어를 표현하는 일련의 숫자들이 들어간다.
2) 희소 표현
- One-hot Encoding과 같이 Vector의 차원에서 index 역할을 하는 하나의 숫자만 1이고 나머지는 모두 0인 방식을 의미한다. 이는 공간적 낭비가 있기 때문에 그렇게 많이 사용되지는 않는다.
자연어 처리 분야에서 단어의 밀집펙터 표현을 단어 임베딩 혹은 단어의 분산 표현이라고 한다.
2.2 분산 표현과 분포 가설
1) 분산 표현 (Distributed Representation)
: 단어를 고차원이 아닌 저차원의 연속 벡터로 표현하는 방식을 의미한다.
- 단어의 의미를 벡터 공간 상에서 근접한 위치에 배치함으로써 단어 간의 유사성을 계산할 수 있다.
2) 분포 가설 (Distributional Hypothesis)
: '단어의 의미는 주변 단어들에 의해 결정된다'라는 가설을 의미한다.
- 같은 문맥에서 자주 나타나는 단어들은 비슷한 의미를 가진다.
- 분포 가설에 기반한 NLP 개념들이 굉장히 많다.
2.3 원핫 표현으로 변환
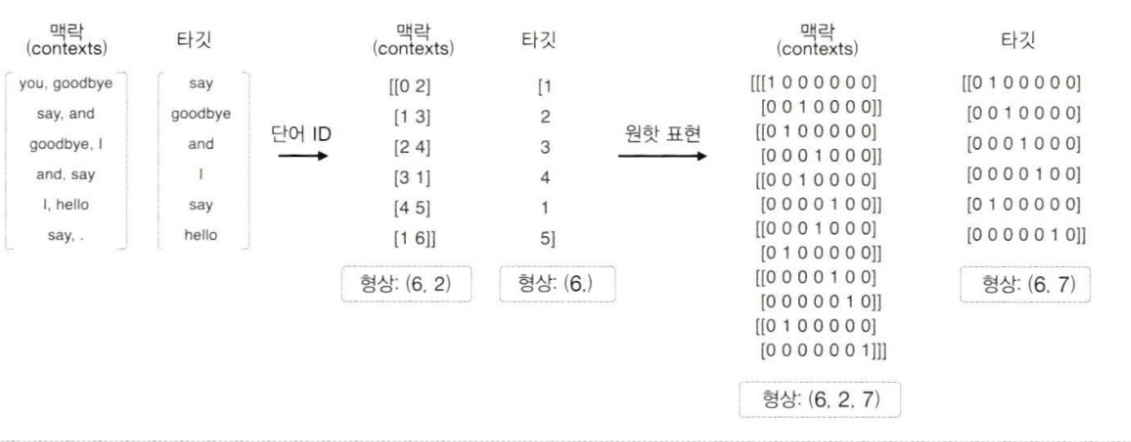
- One-hot Encoding
: 각 단어에 대해 고유한 인덱스를 부여하고, 단어의 수만큼 차원을 가진 벡터를 생성한다. 이때 해당 단어의 인덱스 위치의 값은 1로, 나머지 위치의 값은 0으로 설정한다.
🎲 One-hot Encoding의 한계
- 차원의 저주
: 단어의 수만큼 벡터가 생성되고 차원이 커지기 때문에 계산 복잡성이 증가하고 공간적 낭비가 발생하여 차원의 저주가 발생한다.
- 데이터 희소성(Sparsity)
: 대부분의 값이 0인 희소 벡터는 계산에 비효율적이다.
- 단어 간의 관계 표현 부족
: 모든 단어가 직교하기 때문에 단어 간의 의미적 유사성이나 관계를 전혀 표현하지는 못한다.
2.4 학습 방법

-
이러한 방식으로 만들어진 Word Vector 중에 Word2Vec는 CBOW와 Skip-gram 방식으로 나뉜다.
-
1) CBOW (Continuous Bag of Words)
: 주변 단어들을 이용해 타켓 단어를 예측하는 방식으로 학습한다. ex) The cat과 on the를 활용해 sat를 예측 -
2) Skip-gram
: 타켓 단어를 이용해 주변 단어들을 예측하는 방식으로 학습한다. ex) sat를 활용해 The cat과 on th를 예측 -
여기서 Context에 해당하는 주변의 단어들은 Window라고 한다. Window size가 4라는 것은 선행, 후행 단어 4개를 의미한다.
3. CBOW

- 주변 단어들을 이용해 타켓 단어를 예측하는 방식
3.1 구성요소
1) 맥락 벡터 c, 가중치 행렬 W, 은닉 벡터 h
-
맥락 벡터란 처음 입력하는 값을 의미한다.
-
W의 각 행이 각 단어의 분산표현을 의미한다.
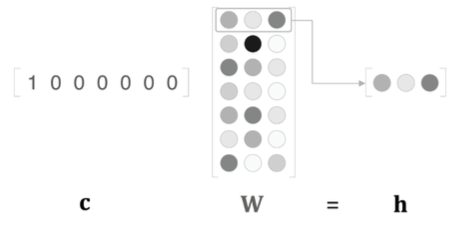
2) Context, Text ID, One-hot vector
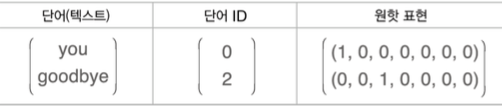
3) FC-layer에 의한 표현 단순화 모형
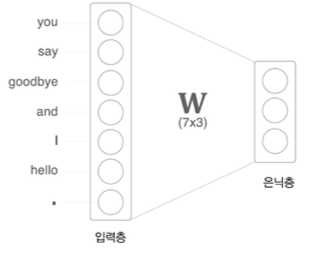
3.2 CBOW 모델의 신경망 구성
-
Softmax를 통해 어떤 단어가 올지 확률을 구한다.
-
출력층보다 입력층의 갯수가 더 많고, 1개의 은닉층을 만드는데 첫번째 입력층의 값과 두번째 입력층의 값에 따라서 2개의 은닉층이 발생한다. 이때 2개를 평균으로 취해줘야한다.
3.3 문제점
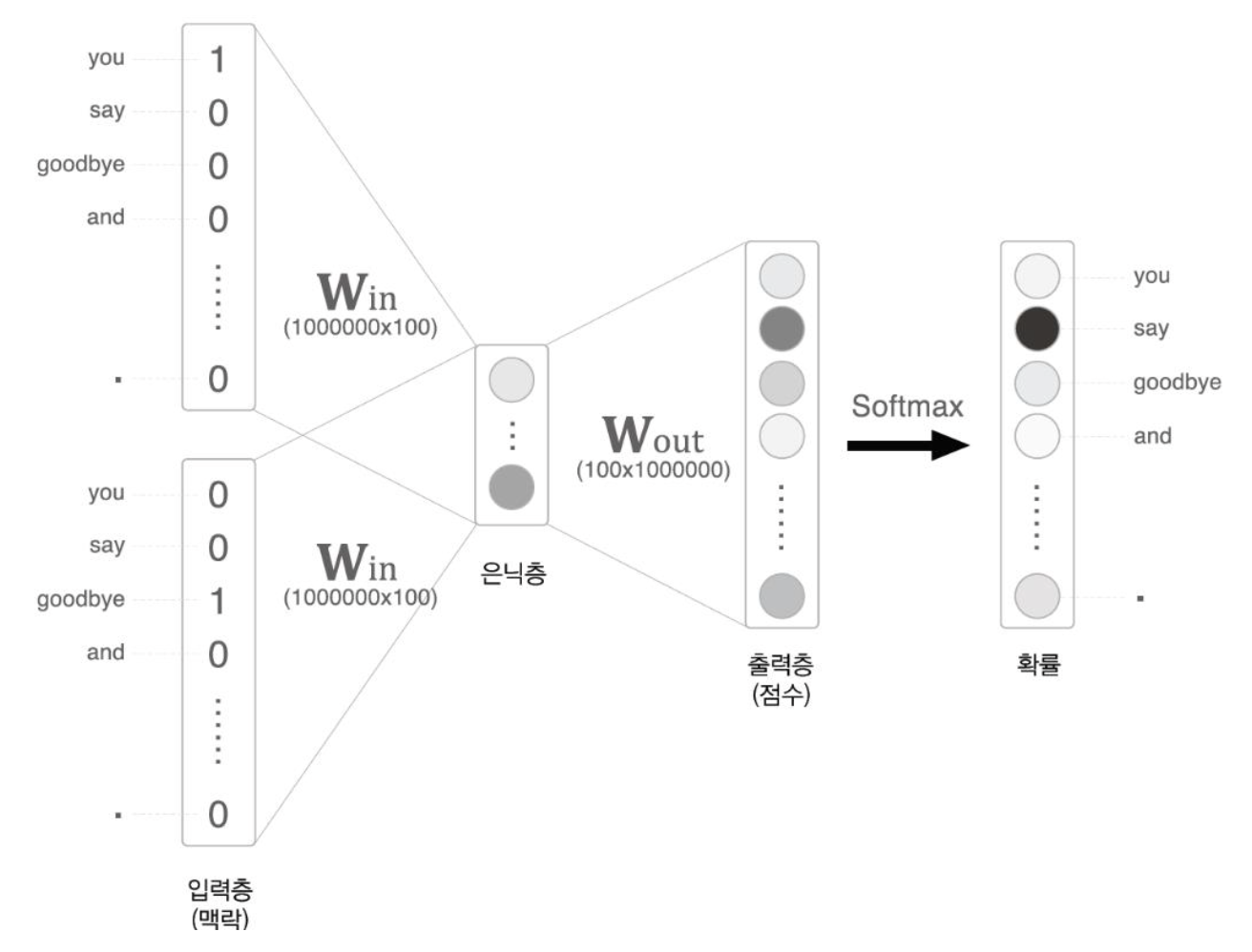
- 입력 및 출력층의 크기가 커질수록 계산량이 많아져 병목현상(BottleNeck)이 발생한다.
BottleNeck
: GoogLeNet에서 나왔던 개념으로 병이 목 부분처럼 넓은 길이 갑자기 좁아짐으로써 교통정체, 컴퓨터 성능 저하 현상이 발생하는 것을 의미한다.
1) 행렬에서의 인덱싱을 통해서 병목현상 제거
: 입력층의 원핫 표현과 가중치 행렬 W_in의 곱 계산
2) 은닉층과 가중치행렬, Soft계층에서의 계산량 증가
: 은닉층과 가중치행렬 W_out의 곱
3.4 개선점
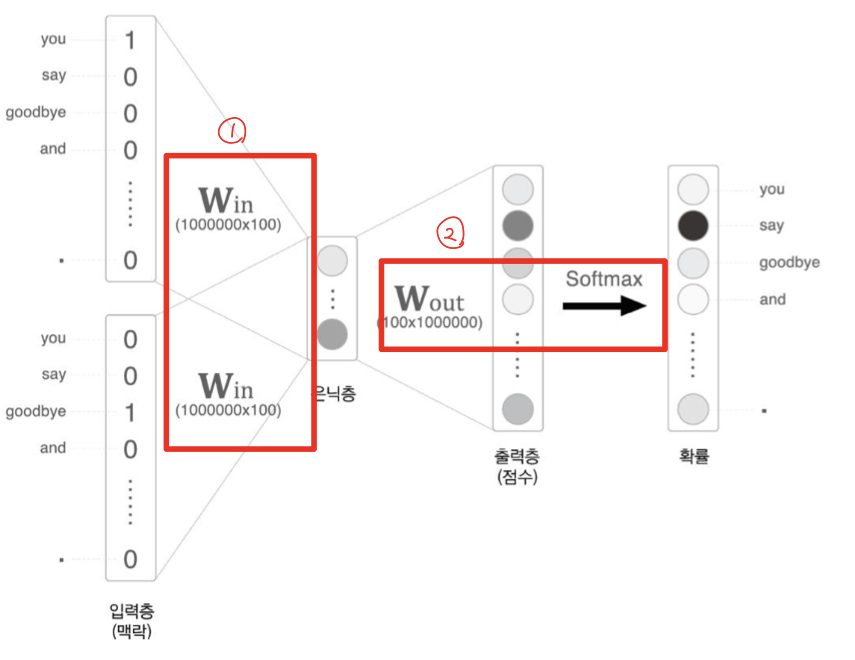
1. Embedding 계층 활용 (첫번째 빨간색 네모칸)
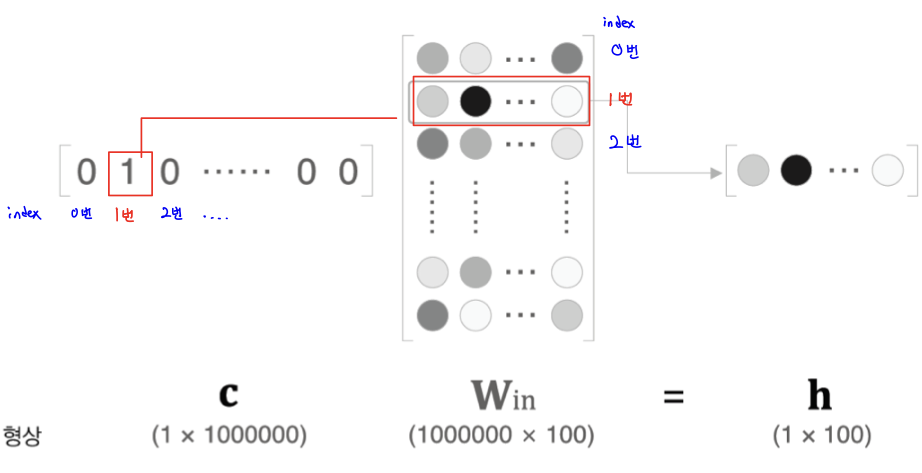
-
맥락 입력 데이터 -> One-hot Encoding 변경 -> 파라미터와 행렬 곱을 수행
-
맥락 벡터와 가중치 행렬의 곱 연산을 통해 은닉 벡터를 얻는 과정을 의미한다. 가중치 행렬에서 맥락 벡터의 인덱스에 해당하는 행을 추출한다
-> 곱 연산이 아닌 행렬에서의 Indexing을 통해 병목현상인 BottleNeck 제거한다.
- Embedding 계층?
: 맥락 입력 데이터와 은닉층 사이의 파라미터를 계산할 때 활용하는 계층을 의미한다. 인덱스를 잘 매핑시켜 복잡한 행렬 연산을 하지 않도록 하는 것이 핵심이다.
- 인덱스 번호만 잘 맞춰서 매핑시켜주면 h값을 계산하기 위해 굳이 (100만개, 1000만개)나 되는 W_in 행렬과 연산 할 필요가 없어지게 된다.
- One-hot Encoding 형태로 되어 있는 C에서는 하나의 값만 1이고, 나머지는 모두 0이기 때문에 C에서 값이 1인 인덱스를 행으로 하는 W_in의 값이 그대로 h로 나오게 된다. 그래서 빨간색 선으로 매칭되어 있는 형태로 h에서 출력된다.
2. Negative Sampling (두번째 빨간색 네모칸)
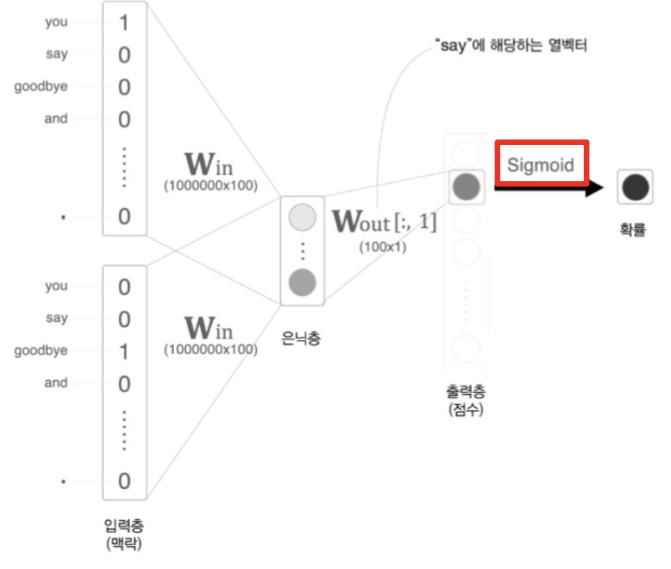
-
어휘가 많아지면 Softmax의 계산량도 증가한다. Softmax 계산식에도 어휘 수에 비례해 증가하므로 Softmax를 대신할 '가벼운'계산이 필요하다.
-
그래서 Softmax를 사용하는 대신 Sigmoid 활성화함수를 사용함으로써 이진분류로 만든다. 즉, 다중분류의 문제를 이진분류로 만든다.
-
예를 들어, 10,000개의 출력층을 만든다고 하면, 연산량이 굉장히 필요하다. 하지만 1개의 정답에 대해 '맞다', '아니다'로 예측하고자고 하면, 이진분류로 계산하기 때문에 연산량이 줄어들 수 있다.
- Negative Sampling의 핵심 아이디어는 '다중분류'를 '이진분류'로 근사하는 것이다
-
예를 들어, "맥락이 'you'와 'goodbye'일 때, 타켓 단어는 'say'입니까?"라는 질문에 답하는 신경망을 생각해야한다. 즉, 긍정적인 예(정답)에 대해서 학습해야한다.
-
위의 그림을 보면, 은닉층과 출력 측의 가중치 행렬의 내적은 'say'에 해당하는 열만을 추출하고, 그 추출된 벡터와 은닉층 뉴런과의 내적을 계산하면 끝이다.
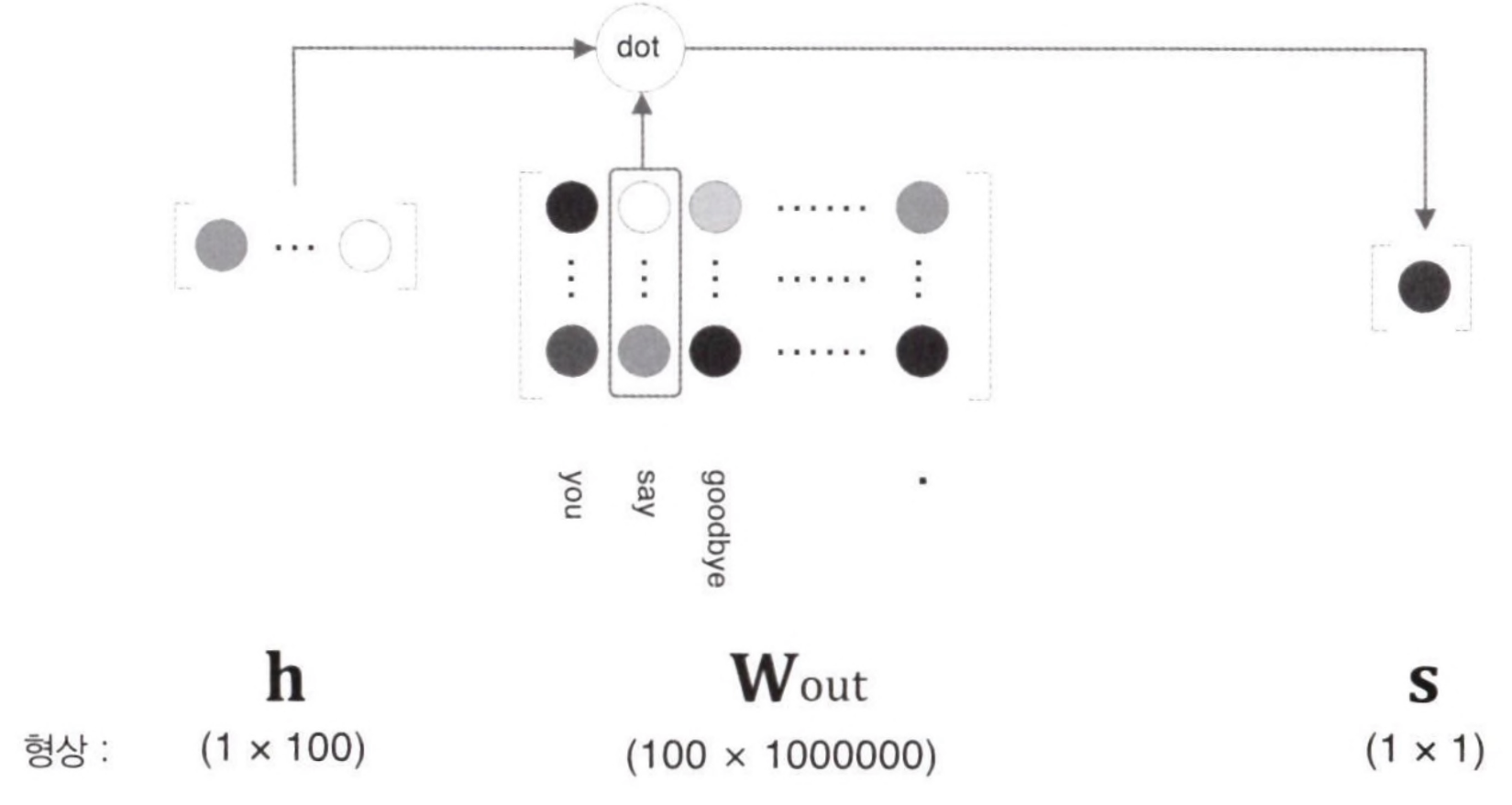
- 위의 그림과 같이 'say'에 해당하는 열벡터와 은닉층 뉴런의 내적을 계산한다. ('dot' 노드가 내적을 계산한다)
- 이전까지의 출력층에서는 모든 단어를 대상으로 계산을 했다. 하지만 Negative Sampling에서는 'say'라는 단어 하나에 주목하여 그 점수만을 계산하는 게 차이점이다. 그리고 Softmax가 아닌 Sigmoid 함수를 사용해 점수를 확률로 변환하는 것이 차이점이다.
네거티브 샘플링에 대한 양이 많기 때문에 밑에서 한번 더 다루겠다.
3.5 네거티브 샘플링
위에서는 긍증적인 예 (정답)에 대해서만 학습하였고, 부정적인 예 (오답)에 대해서는 학습하지 않았다.
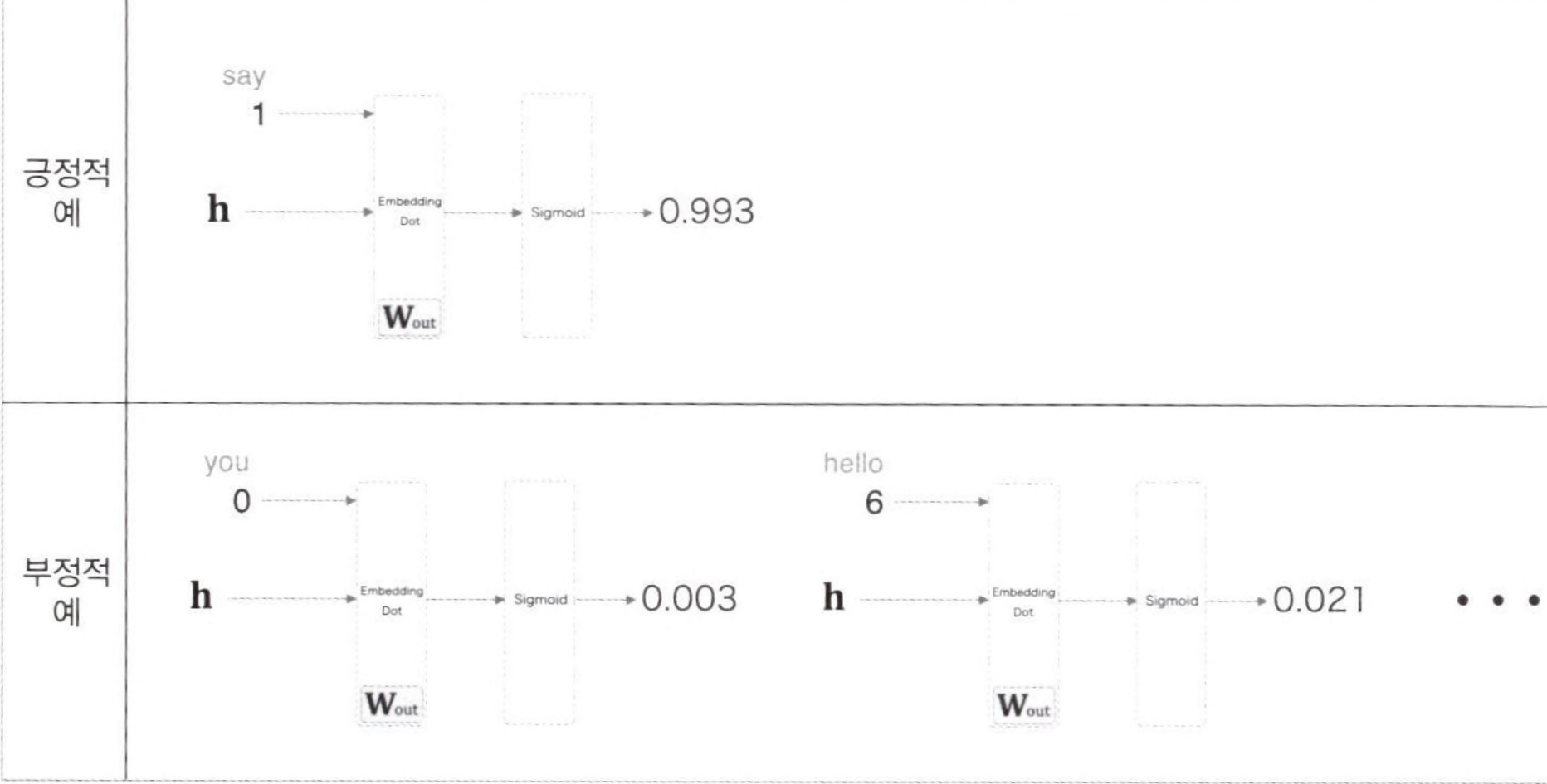
🎲 Negative Sampling의 핵심 아이디어
: 긍정적 답에 대해서는 Sigmoid 계층의 출력을 1에 가깝게 만들고, 부정적 답에 대해서는 Sigmoid 계층의 출력을 0에 가깝게 만드는 것이다.
즉, 타깃이 정답일 확률은 1에 가깝게, 오답일 확률은 0에 가깝게 학습시킨다.
그래서 네거티브 샘플링이란 무엇일까?
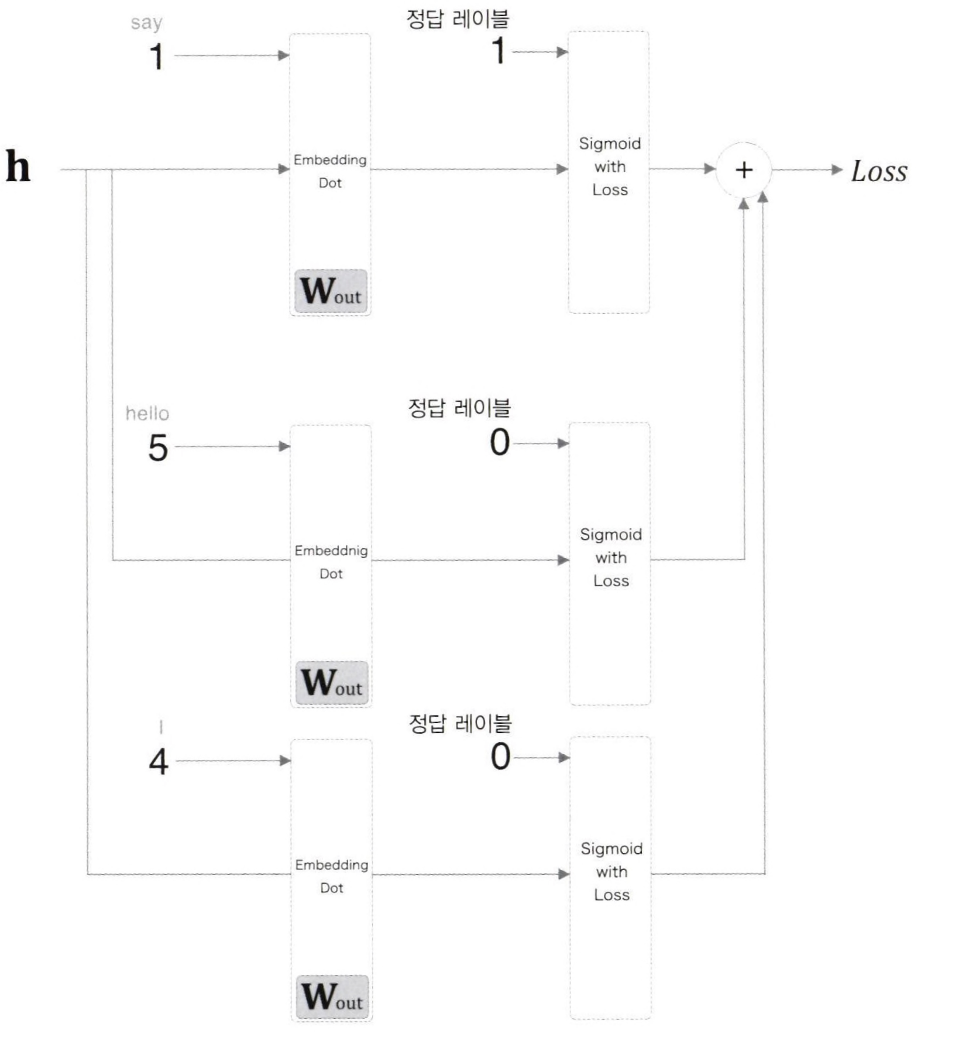
- 위의 그림은 은닉층 이후의 처리에 주목하여 그린 계산 그래프를 의미한다.
정답을 타킷으로 한 경우의 손실을 구하고 오답을 몇 개 샘플링하여 동시에 손실을 구한 뒤 두 손실 값의 합을 최종 손실로 사용하는 기법을 의미한다.
-> 긍정적인 답에 대해서는 Sigmoid with Loss 계층에 정답 레이블로 1을 입력하지만, 부정적인 답에 대해서는 그 계층에 정답 레이블로 0을 입력한다.
그런 다음 각 데이터의 손실을 모두 더해 최종 손실을 출력한다.
3.6 네거티브 샘플링의 샘플링 기법
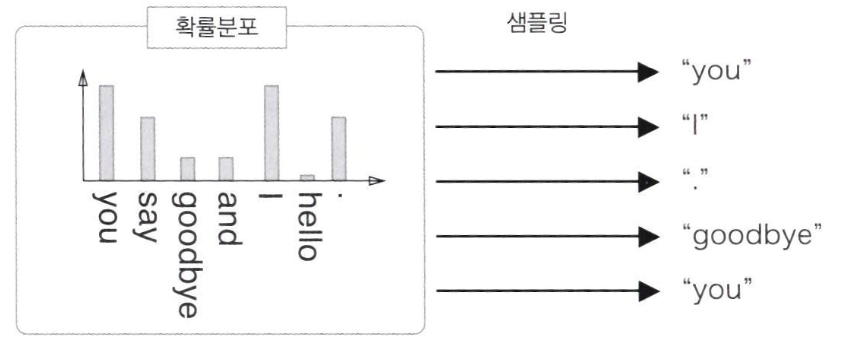
1. Sample 선정 기준
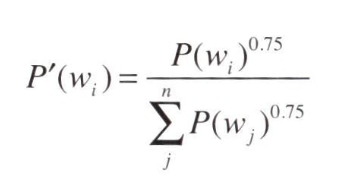
-
Corpus에서 자주 등장하는 단어에 높은 가중치를 부여하고, 드물게 등장하는 단어에 적은 가중치를 부여하는 것이다.
-
Corpus에서 각 단어의 출현 횟수를 구한 뒤 '확률분포'로 나타낸다. 그런 다음에 그 확률분포대로 단어를 샘플링하면 된다.
-
특정 단어가 선별된 확률 P()의 수식은 위의 그림과 같다. 여기서 W(i)는 i번째 단어를 의미하고, f(wi)는 해당 단어의 출현 빈도를 의미한다.
논문에 따르면 0.75는 상수인데, 이 값으로 제곱을 취해 줬을 때 성능이 가장 뛰어나다고 한다
2. Sample 선정 개수
- 데이터의 크기에 따라서 다르지만, 보통 학습 데이터셋이 작을 때는 5~20개 사이의 Negative Sample을 추출하는 게 효과적이고, 학습 데이터셋이 클 때는 2~5개 사이의 Sample을 선정하는 것이 효과적이다.
4. Skip-gram
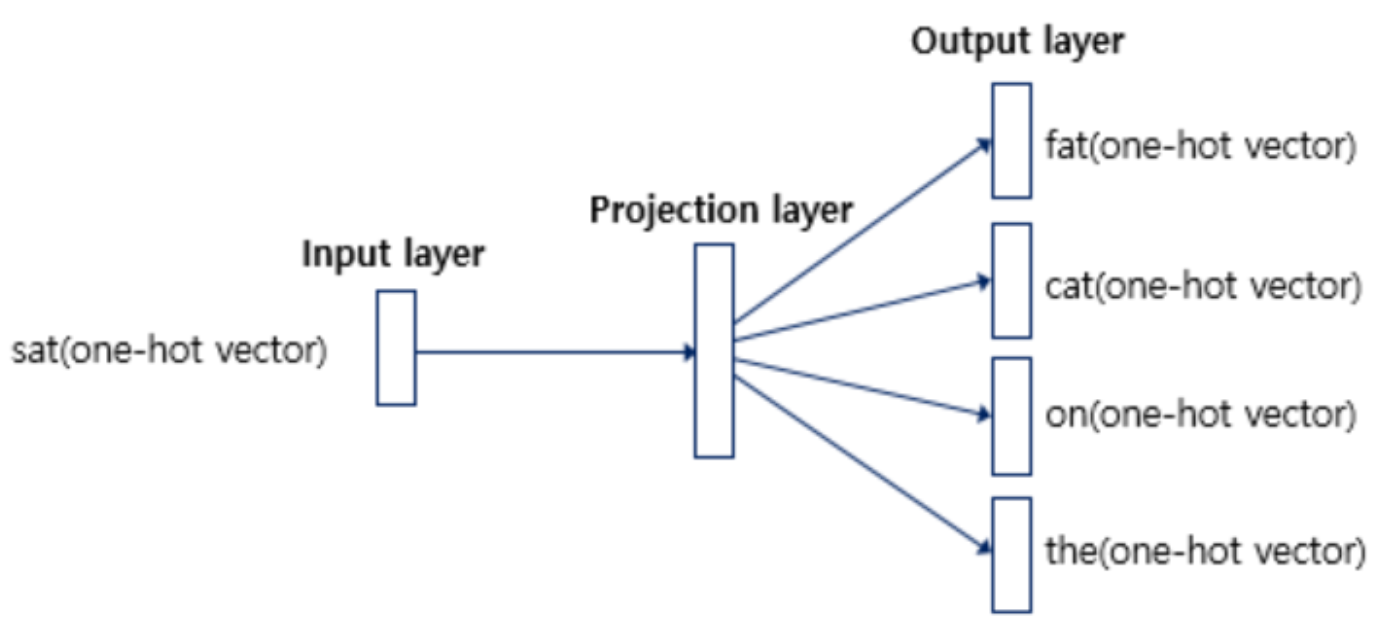

- Skip-gram 모델은 중앙의 단어(Target)부터 주변의 여러 단어(Context)를 예측한다.
4.1 Skip-gram 모델의 신경망 구성
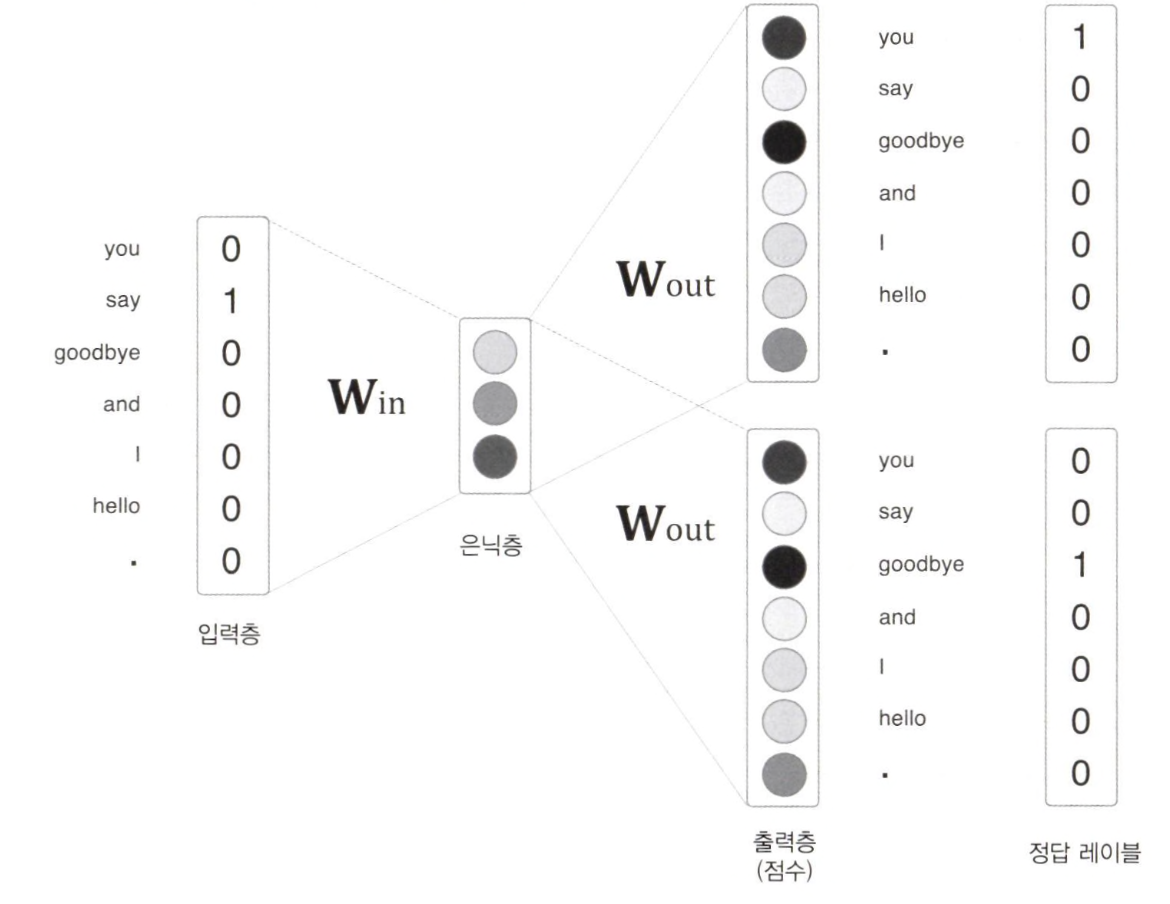
- 입력층은 하나이고, 출력층은 맥락의 수만큼 존재한다.
- 각 출력층에서는 (Softmax with Loss 계층 등을 이용해) 개별적으로 손실을 구하고, 이 개별 손실들을 모두 더한 값을 최종 손실로 한다.

- CBOW와 마찬가지로, W가 One hot Encoding된 입력벡터와 은닉층을 이어주는 가중치행렬임과 동시에 Word2Vec의 최종 결과물인 임베딩 단어벡터의 모음이 된다.
- 위의 그림에서 중요한 것은 'quick'과 'brown'을 따로 떼어서 각각 학습한다는 것이다.
- 학습과정을 살펴보면 다음과 같다. Target에 'The'를 넣고, 그 다음 단어인 'quick'을 주변 단어로 정답으로 두어서 한번 학습하고, Target에 'The'를 두고, 그 다다음 단어인 'brown'을 주변 단어로 해서 한번 더 학습하는것이다.
- 이렇게 되면 Corpus 내에 존재하는 모든 단어를 Window 크기로 슬라이딩해가며 학습을 할 수 있고, iteration 1회가 마무리된다.
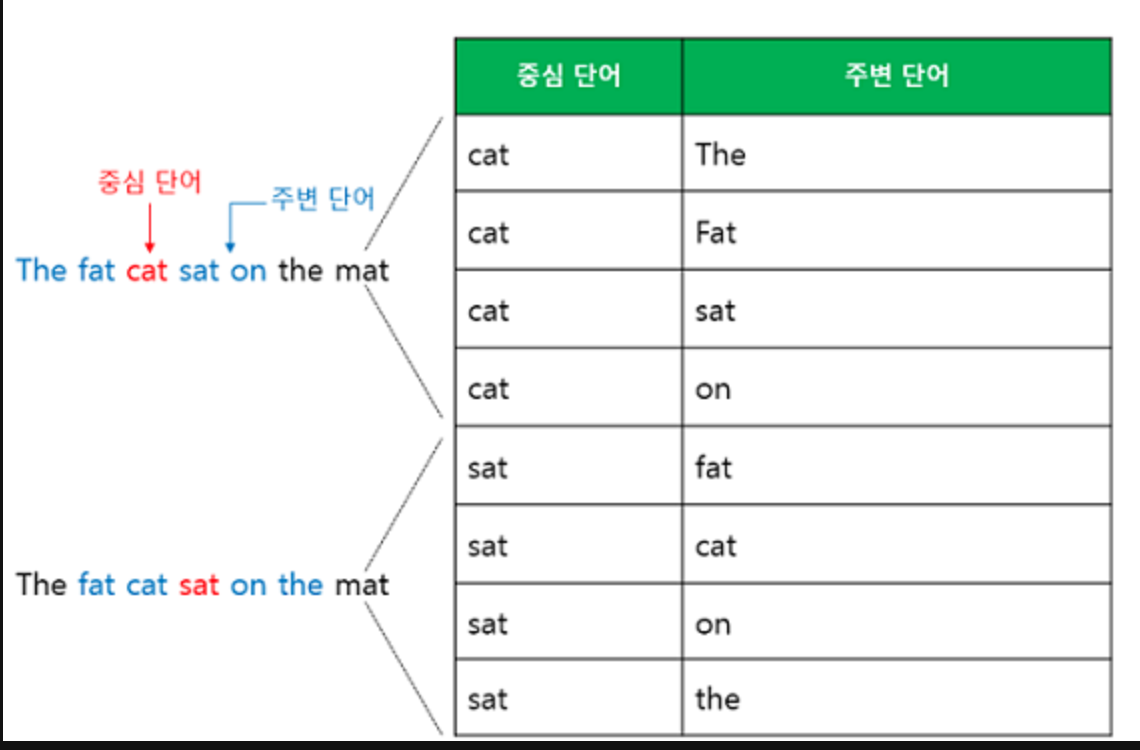
- 윈도우 크기가 2인 Skip-gram의 경우, 중심 단어는 엡더이트 기회를 4번정도 확보할 수 있다.
- CBOW의 경우, 중심 단어는 단 한번의 업데이트 기회만을 가진다.
- 즉 말뭉치 크기가 동일하더라도 학습량이 4배 차이난다는 것이다. 그렇기 때문에 Skip-gram이 높은 성능을 보인다.
4.2 확률 표기
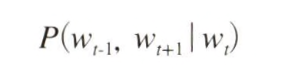
- W(t)가 주어졌을 때, W(t-1)과 W(t+1)이 동시에 일어날 확률을 의미한다.
이 모델에서는 조건부 독립이라고 가정하기 때문에 다음과 같이 표현할 수 있다.
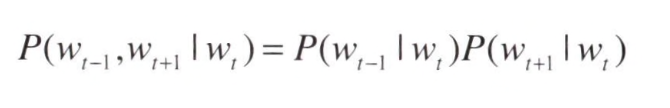
- 이를 교차 엔트로피 오차에 적용하여 Skip-gram 모델의 손실 함수를 유도할 수 있다.
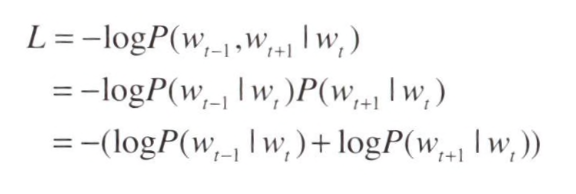
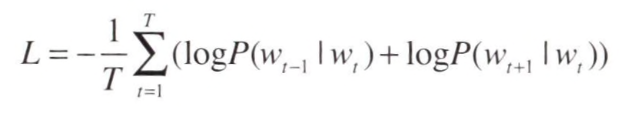
- Skip-gram 모델은 맥락의 수만큼 추축하기 때문에 그 손실 함수는 각 맥락에서 구한 손실의 총합이 되어야 한다.
- 말뭉치가 커질수록 저빈도 단어나 유추 문제의 성능 면과 단어 분산 표현의 정밀도 면에서 skip-gram 모델이 CBOW모델보다 뛰어나다.
- Skip-gram 모델은 손실을 맥락의 수만큼 구해야 해서 계산 비용이 커지기 때문에 느리다. 반면 학습 속도면에서는 CBOW 모델이 더 빠르다.
성능은 SGNS가 가장 우수한 것으로 알려져 있다.
CBOW < Skip-gram < Skip-gram with Negative Sampling(SGNS)
5. 다양한 Word Embedding
- Word Embedding은 매우 다양하고, Word2Vec, FastText, Glove, LSA 등이 있다.
1) Glove (Global Vectors for Word Representation)
-
단어 임베딩을 생성하기 위한 다른 인기 있는 비지도 학습 알고리즘
-
전역 단어 공존 통계를 활용하여 단어 간의 의미 관계를 캡처한다.
2) FastText
-
Word2Vec의 변형으로, 단어 집합 밖 단어와 서브워드 정보를 처리할 수 있다.
-
단어를 문자 n-gram의 가방으로 나타내어 형태론적 정보를 포착하고 보지 못한 단어를 처리할 수 있다.
3) ELMo (Embeddings from Language Models)
-
양방향 언어 모델을 사용하여 임베딩을 생성하는 깊은 컨텍스트 기반 단어 표현 기술
-
단어가 나타나는 문맥을 고려하여 보다 미묘한 임배딩을 생성한다.
4) BERT (Bidirectional Encoder Representations from Transformers)
-
전이학습을 활용하여 많은 양의 텍스트 데이터에서 사전학습된 심층 신경망 모델
-
언어 모델을 사용하여 단어 임베딩을 생성하며, 다양한 NLP 작업에 대해 세부 조정될 수 있다.
- 밑바닥부터 시작하는 딥러닝2 pp113-190 참고해서 내용 작성하였습니다.
- https://velog.io/@xuio/NLP-TIL-Word2VecCBOW-Skip-gram#-skip-gram 참고해서 내용 작성하였습니다.
🎯 Summary
Word Embedding 개념은 논문 읽을 때 매우 매우 중요한 개념이다. 특히 추천시스템에서 다양한 Embedding 기법이 등장하고 이를 적용하여 성능 향상을 올리는 중요한 역할이다. 그렇기 때문에 이번 개념 정리는 나에게 매우 필요했다. 특히, CBOW 모델을 개선하기 위해서 Emedding 계층과 다중 분류에서 이중 분류로 만드는 Negative Sampling의 개념이 특히 기억에 남았다. 그리고 나중에 skip-gram with Negative Sampling(SGNS) 개념이 나오는 만큼, skip-gram과 Negative Sampling 이 두 개념을 한번 더 봐야겠다.
최신 Word Embedding 기법을 공부하고 싶은 마음이 생겼다. 이제는 피할 수 없는 BERT논문 리뷰를 해야 되는데 두렵고 떨린다...잘 해내길!!!
📚 References
- 사이토 고키(2019), '밑바닥부터 시작하는 딥러닝2', 한빛미디어, pp.113-190.
- https://velog.io/@xuio/NLP-TIL-Word2VecCBOW-Skip-gram#-skip-gram
- 딥러닝을 이용한 자연어 처리, https://wikidocs.net/
- https://heytech.tistory.com/354
