Title
- Deep Residual Learning for Image Recognition (2015)
- ResNet
Abstract
- 이 논문에서는 심층 잔여 학습 프레임을 도입하여 성능저하 문제를 해결하며, 깊이가 상당히 깊어질수록 정확도를 높일 수 있음을 보여준다.
- VGG보다 8배 깊은 152개의 layer 사용했고, 3.57%의 error를 보여준다.
- ILSVRC 2015 분류 대회에서 1위를 차지하였고, 100개와 1,000개 Layer를 가진 CIFAR-10에 대한 분석 결과도 제시한다.
- 이는 ImageNet detection, ImageNet localization, COCO detection, COCO segmentation에서도 1위를 차지하였다.
0. Background
-
1) LeNet(1998): 최초의 CNN 모델
-
2) AlexNet(2012):
-227x227 size
-RGB 3 channel
-병렬구조
-LRN(Local Response Normalization) -
3) VGG(2014): 3x3 filter 사용
-
4) GoogleNet(2014):
-기본 CNN
-9개의 inception(차원 축소, 1x1 conv Layer 적용)
-Auxiliary classifier(보조 분류기)
-Global Average Poooling -
5) ResNet(2015):
-Residual Learning
-Short cut(skip) connection
-이미지 분류의 대표적인 기본 모델
1. Introduction
깊이가 깊어질수록 네트워크의 성능은 무조건 향상될까?
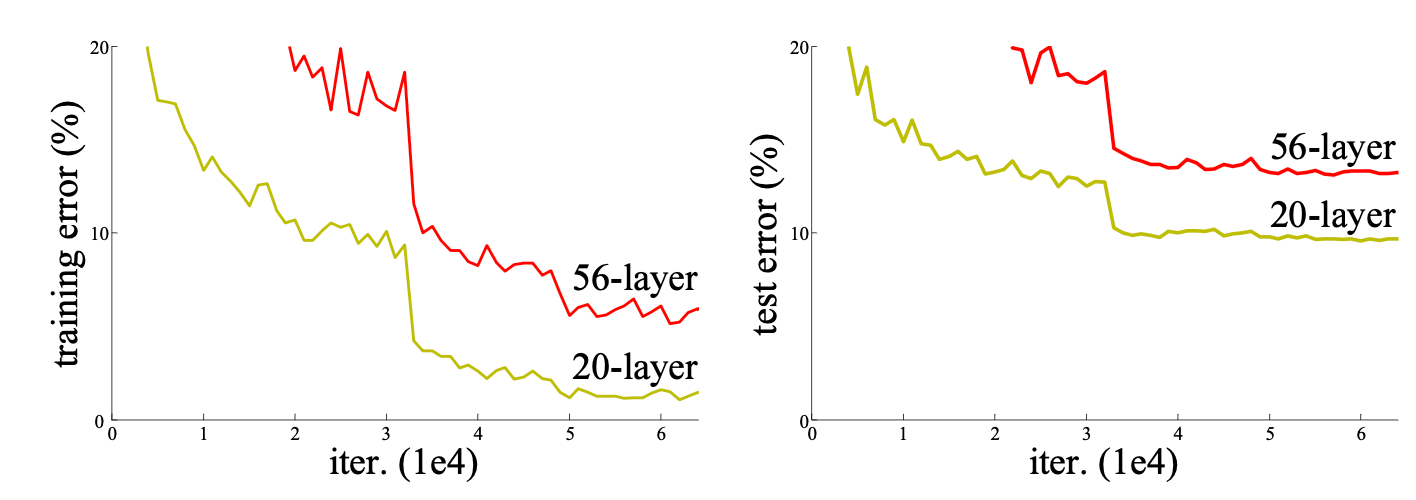
(왼쪽)CIFAR-10 학습 오류 / (오른쪽) 테스트 오류
즉, 네트워크가 깊을수록 훈련 오차가 커지고, 테스트 오차도 커지게 된다.
- 위의 그림과 같이 Layer가 증가할수록 오히려 더 높은 error가 발생한다.
- gradient vanishing, overfitting, 연산량 증가 등의 문제가 발생한다.
- 연산이 진행되면서 원래 정보를 잃게 된다.
이런 의문점으로 시작해서 ResNet가 만들어졌다.
ResNet의 목표는 다음 2가지이다.
1) Layer는 깊게 하되, 학습하는 양을 줄이는 것
2) Layer를 거친 값에 x를 더해줘 기존 정보를 살리는 것
2. Related Work
1) Residual Representations
- VLAD는 사전에 대한 잔차 벡터에 의해 인코딩된 표현이며, Fisher Vector는 VLAD의 확률적 버전으로 공식화할 수 있다.
- 멀리그리드 방법은 저수준 비전 및 컴퓨터 그래픽에서 편미분 방정식을 풀 때 널리 사용되는 방법으로, 시스템을 여러 스케일의 하위 문제로 재구성할 수 있다.
- 이의 대안으로 계층적 기반 사전 조건화가 있는데, 이는 두 스케일 사이의 잔여 벡터를 재현하는 변수에 의존한다.
2) Shortcut Connections
- highway networks라는 gating functions을 항상 잔차 함수를 학습하며, Identity는 절대 닫히지 않고 모든 정보는 항상 학습해야 할 추가 잔여 기능과 함께 전달된다.
- 이 네트워크는 극도로 증가된 깊이인 100개 이상의 Layers에ㅓ 정확도 향상을 입증하지 못했다.
3. Deep Residual Learning
3.1 Residual Learning
1. Plain Layers
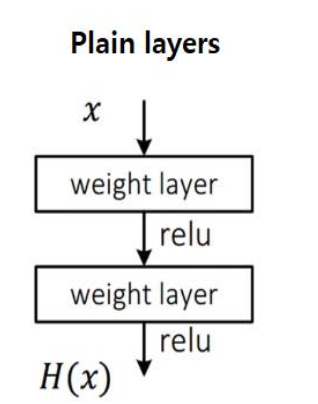
- 이는 VGG기반의 CNN모델이라고 생각하면 된다.
- Layer가 깊어짐에 따라, 정보 손실이 발생한다
- 즉, 최적 H(x)값을 구하기가 매우 어렵다.
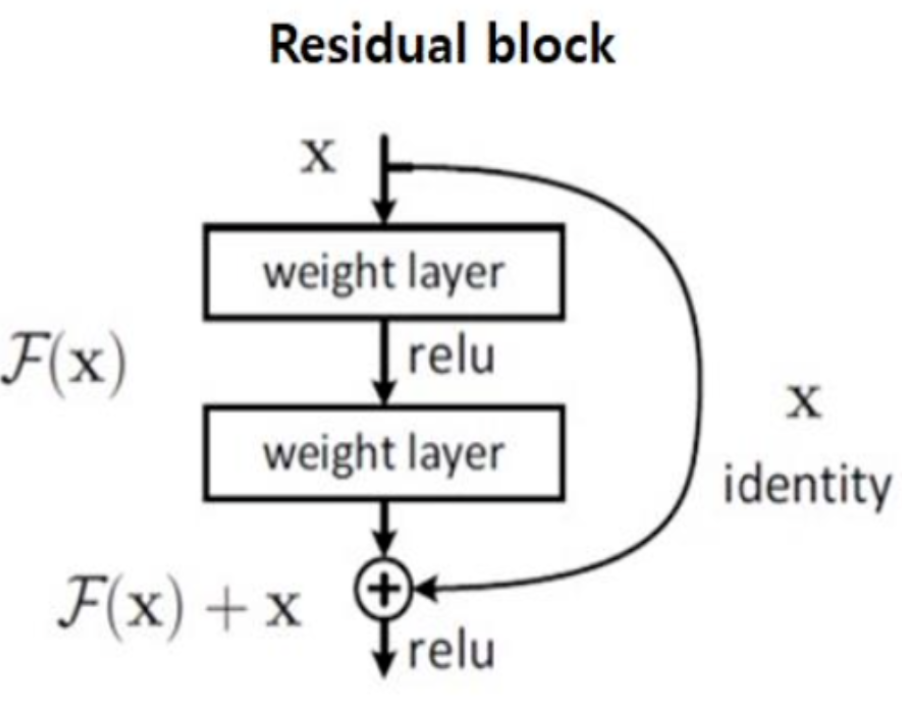
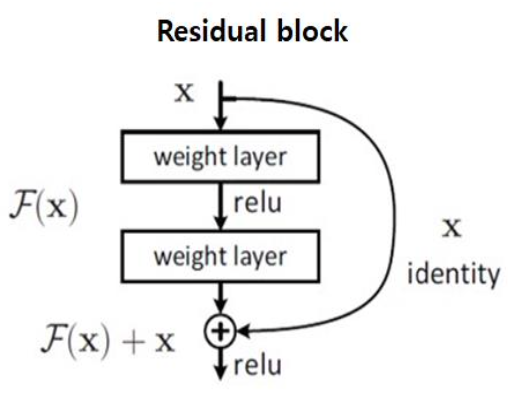
2. Residual block
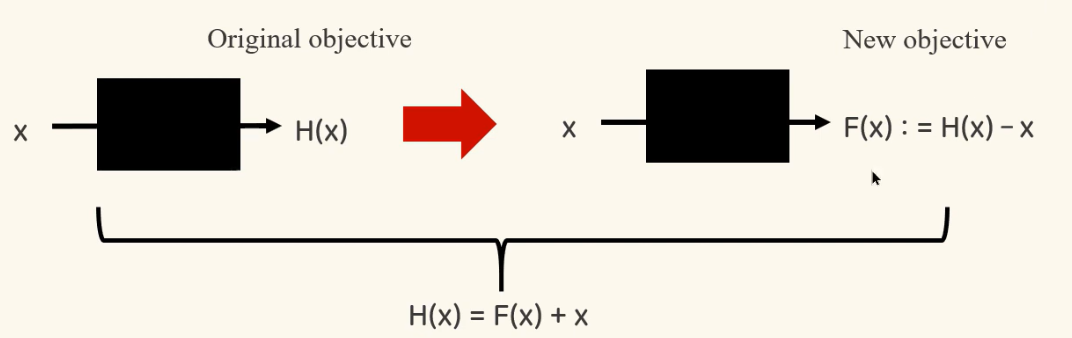
- F(x) = H(x) - x
- H(X) = F(x) + x
- 즉, 앞서 학습된 기존 정보(x)와 잔여한 정보(F(x))를 더하는 것이다. 이는 정보 손실을 방지 해준다.
- 학습시킬 것은 F(x)이다. 이를 추가적으로 학습하면 되기 때문에 연산량을 감소시킨다.
- H'(x) = F'(x) + 1이므로 적어도 기울기가 1로 유지된다. (기울기 소실 문제 해소)
- 이것은 마치
지름길을 뚫어 넣음으로써 기울기 소실 문제에 대해서 자유로울 수 있다.
Residual Learning의 목표는 다음과 같다.
1) F(x)를 H(x) - x로 변형시켜 H(x)에 근사하도록 학습시키는 것
2) F(x)가 0에 가까워지도록 학습시키는 것(잔차의 개념)
- 잔차란?
회귀식과 관측값 사이에 나타나는 차이를 의미한다.
e(잔차)=y(관측값)−ŷ (예측값)
3.2 Identity Mapping by Shortcuts
1. 기존 CNN 모델 구조
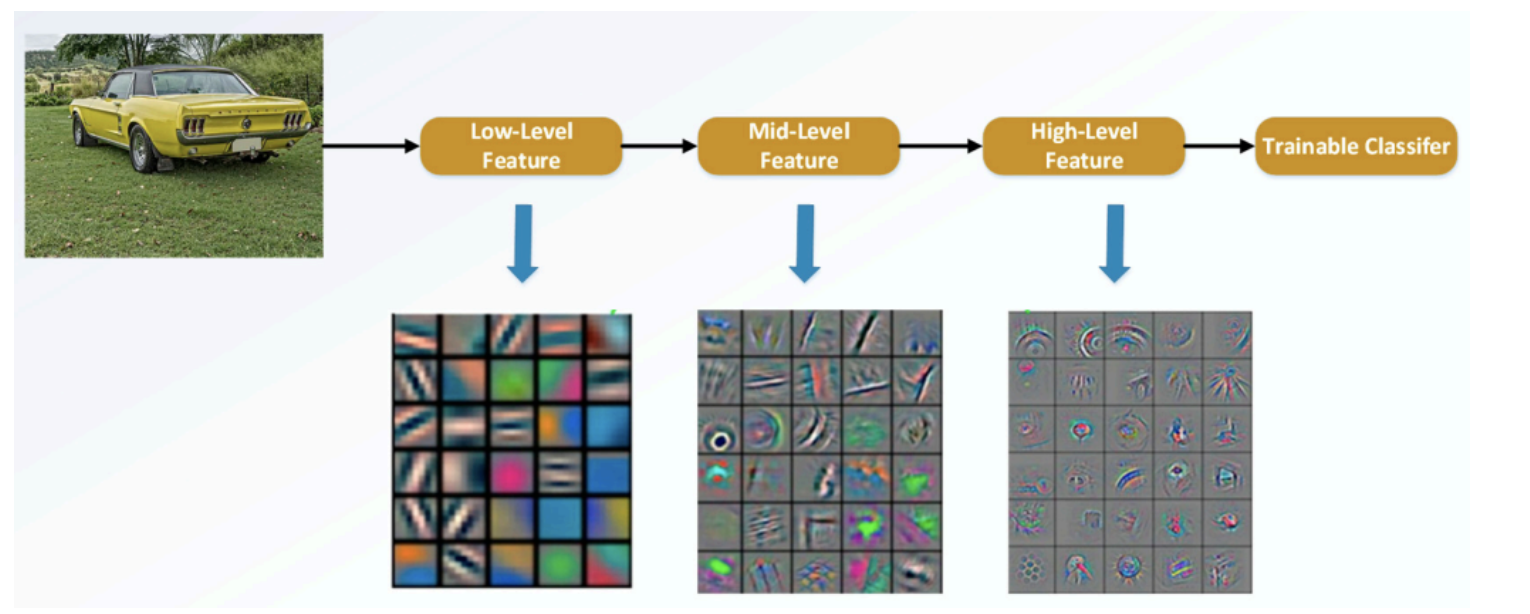
1) Low-Level vision과 Computer Graphics 분야에서 PDEs(Partial Differential Equations)를 풀기 위해 Multigrid 방법들이 많이 사용된다. 이것은 다양한 스케일에서의 하위문제로 시스템을 재정의하는 것이다.
2) 예를 들어, 삼다수 물병을 학습하다고 했을 때, 삼다수 물병이 가까이에서 찍힌 것은 크게 나타나고, 멀리서 찍힌 것은 작게 나타난다.
3) 기존의 CNN 구조에서는 이전의 것이 다음의 전달되어 양향을 미치게 된다. 즉, input에서는 Low-Level feature가 학습되고, output에서는 High-Level feature가 학습된다.
4) 앞선 부분의 feature가 뒤쪽까지 영향이 직접적으로 전달하는 것이 아닌, 중간에 거쳐 전달되기 때문에 학습 과정에서 크게 변한다.
2. ResNet의 Short cut connection 구조
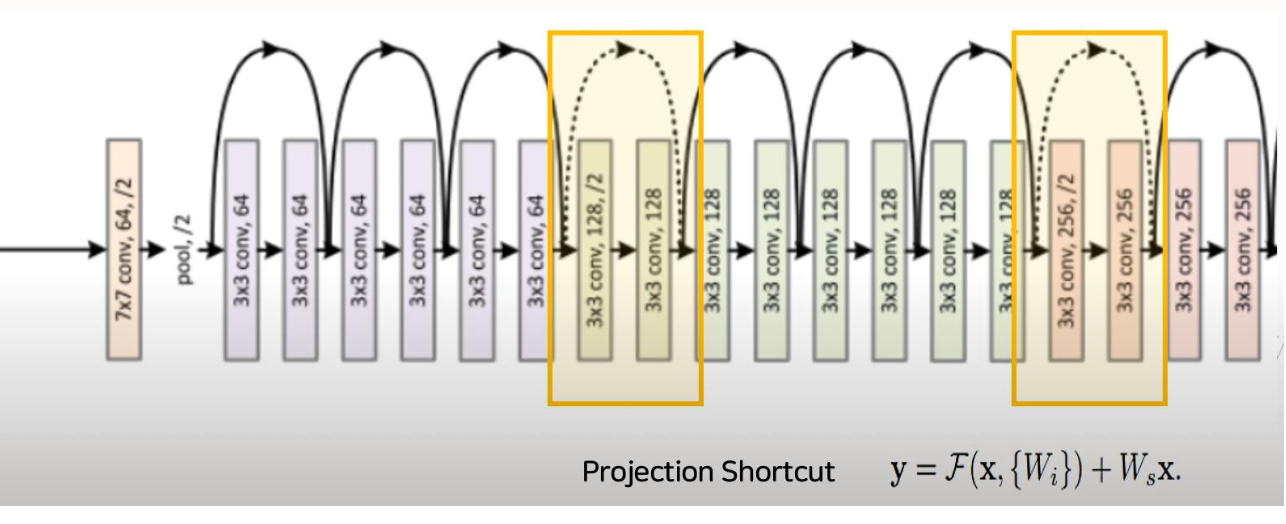
1) 바로 위의 그림에서 보면, 두 개의 conv Layer마다 화살표가 나오는 것을 알 수 있다.
2) 레이어를 뛰어 넘어서 값을 전달하기 때문에 Shortcut (skip)구조라고 표현한다.
3) 기존 구조와 달리 Shortcut connection을 추가해주게 되면 이전으로부터 얼마큼 변하는지 residual만 계산하는 문제로 바뀌게 된다.
4) 이전 Layer의 Feature Map을 다음 Layer의 Feature Map에 더해주는 개념이다.
5) 신경망이 깊어지면 역전파를 통한 학습 시 Gradient가 계속 곱해짐에 따라 Input Layer와 가까운 부분의 Gradient가 0에 가까워지거나(Vanishing gradient problem) 폭발적으로 증가하는 문제(Exploding gradient problem)를 완화시켰다.
즉, 현재 Layer의 output과 이전 스케일의 Layer의 output을 더해 입력을 받기 때문에, 그 차이를 볼 수 있게 된다. 결국 학습하는 과정에서 기존에 비해서 조금만 학습하면 되고, 더 빠르게 학습할 수 있는 장점이 있다.
2.1 Identity Shortcut(일반적인 구조)
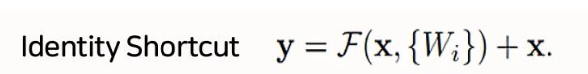
- 바로 가기 연결은 추가 매개변수나 계산 복잡성이 없다.
- 이는 매개변수 수, 깊이, 너비, 계산 비용이 동일한 일반/잔여 네트워크를 동시에 비교할 수 있다.
2.2 Projection Shortcut
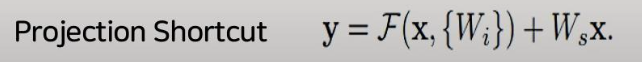
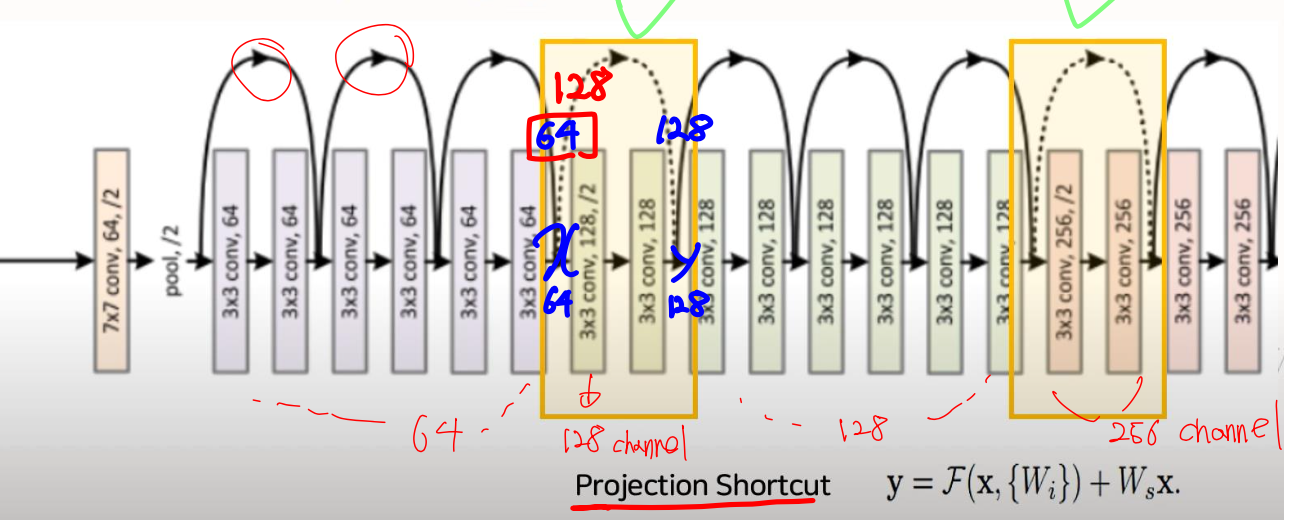
-
여기서 Ws는 size를 맞춰주는 행렬을 의미한다. 즉, 차원을 일치시켜준다.
-
위의 그림에서노란색 박스2개는 Projection Shortcut을 의미한다. 첫번째 노란 박스 앞에서x를input으로 잡게 되면 64 channel이고, 이를 건너 뛰고 난output의 값인y는 128 channel이다. 이 두 값을 더해줘야 되는데 각각 64, 128 channel이기 때문에 더할 수 없다. 그렇게 때문에x값에 사이즈를 128로 일치시켜줌으로써 더해준다.
3.3 Network Architectures
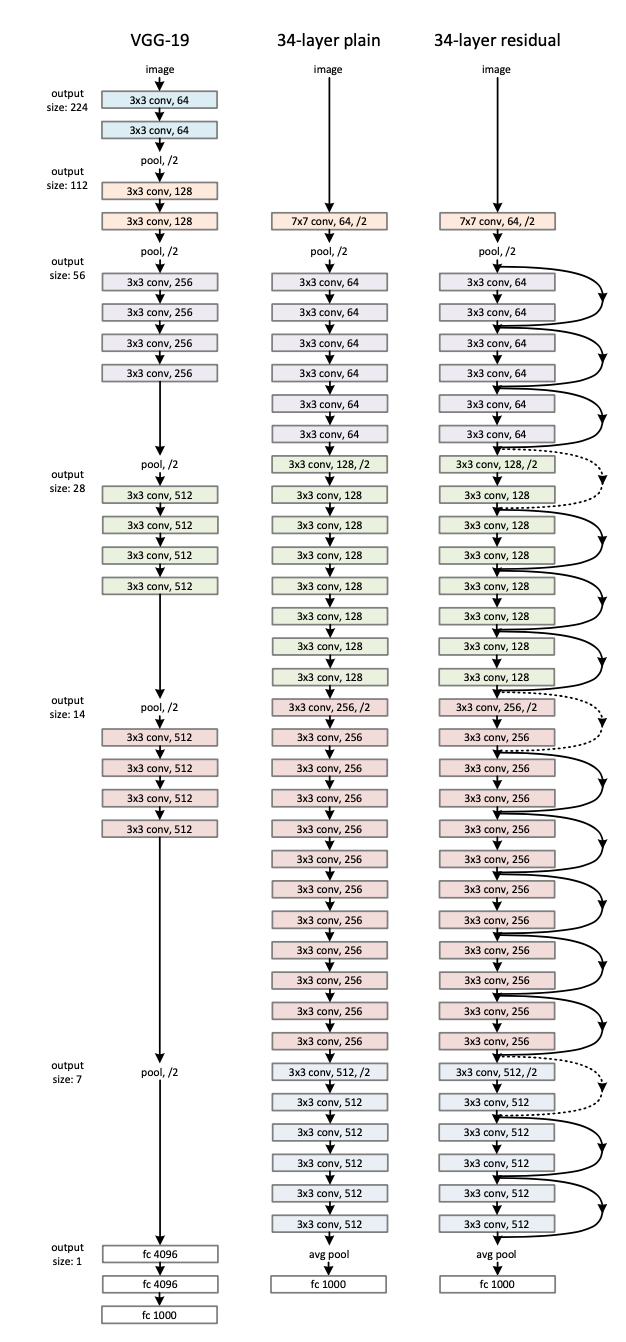
-
VGG-19Layer에서는 대부분3x3 필터를 가지고 있고, 동일한 출력 Feature Map에서 레이어의 필터 수는 동일하고, Feature Map 크기가 절반으로 줄어들면 Layer 당 시간 복잡성을 유지하기 위해 필터 수는 두 배로 증가한다. -
ResNet는 VGG보다 필터 수가 적고 복잡성이 낮다. 그리고 Shortcut connection을 추가해서 residual만 계산되기 때문에 적고, 빠르게 학습할 수 있다.
4. Experiments
4.1 ImageNet Classification
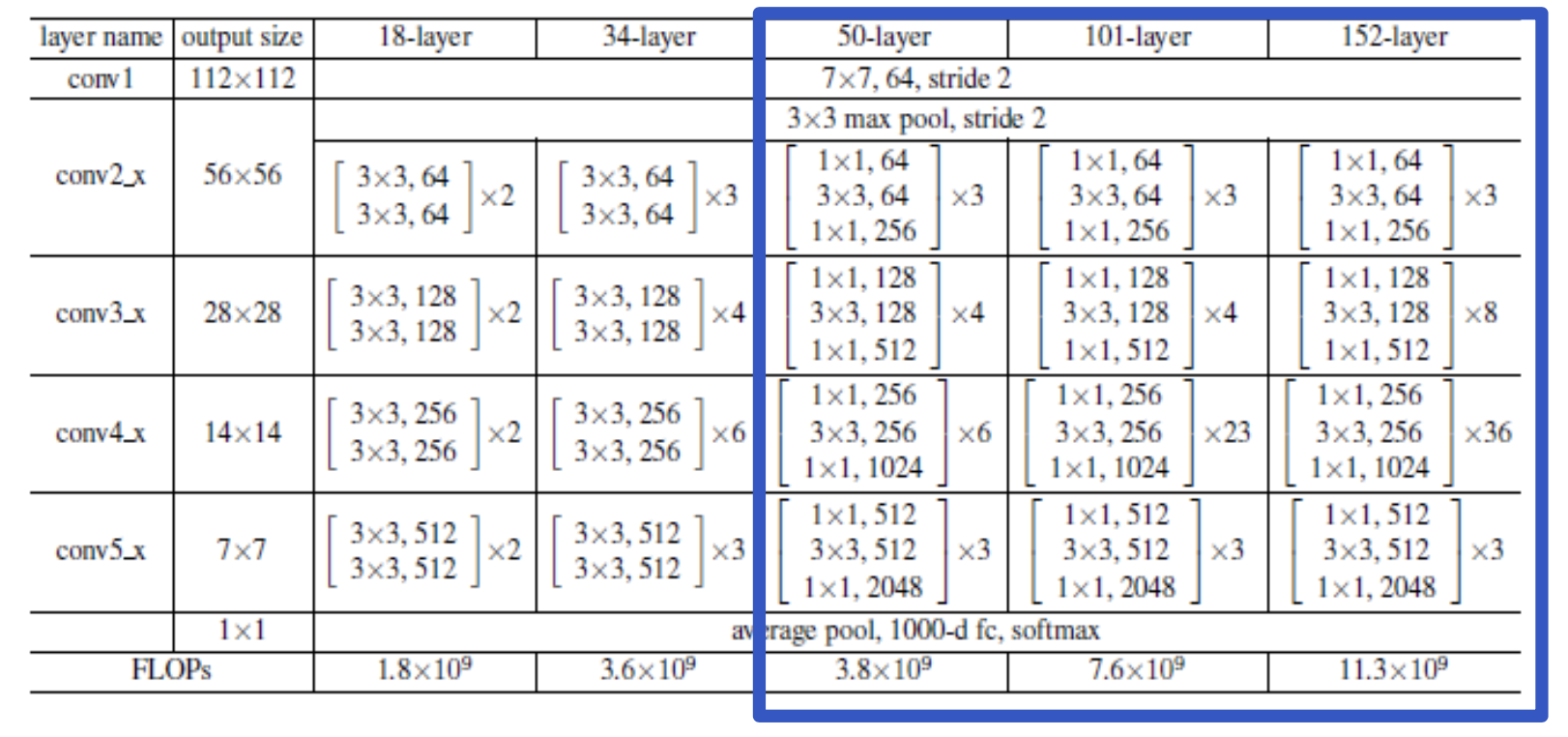
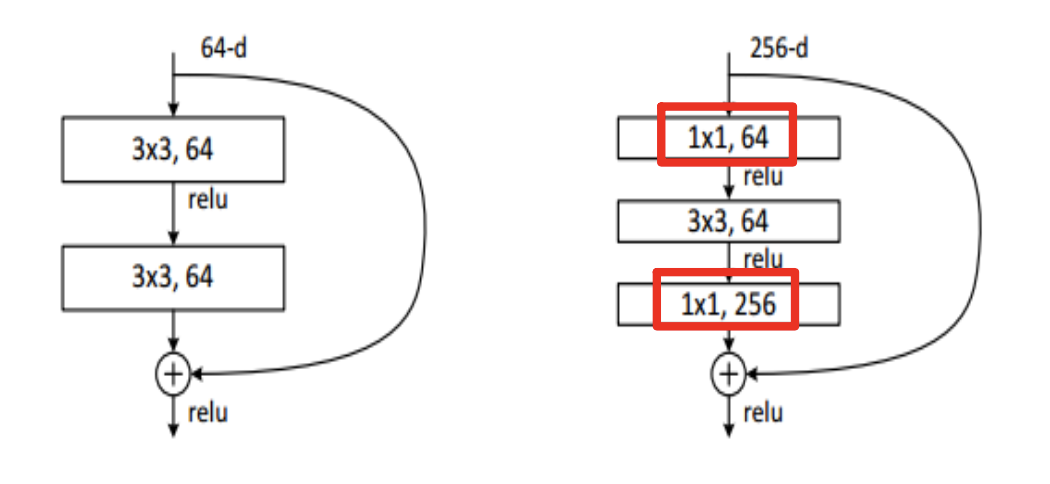
-
파란색 박스를 보면, Layer가 50개 이상일 때 1x1 conv를 통해 연산량을 줄여준다. -
18, 34 Layer에서는 1x1 con가 없다.
Bottle Neck 구조(병의 주둥이와 같이 좁은 곳을 통과한다는 의미)
GoogleNet의 inception module과 유사하다.
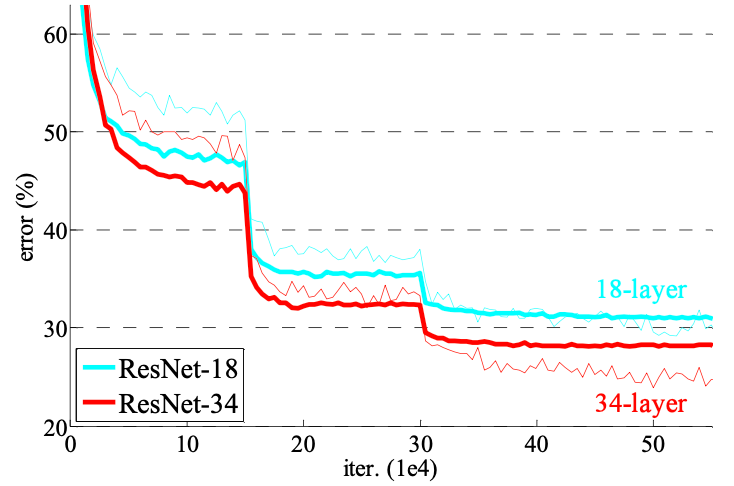
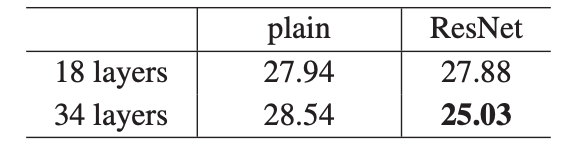
- 18 Layer보다는 34 Layer에서 낮은 에러율을 보였다.
- 18 Layer에서는 plain(27.94)과 ResNet(27.88) 에러율은 비슷했으나, 학습 파라미터 수가 ResNet이 더 적기 때문에 학습 속도가 빨랐다.
- 34 Layer에서는 plain(28.54)과 ResNet(25.03) 에러율을 보였으며, ResNet이 더 우수하였고, 검증 데이터에 일반화할 수 있다.
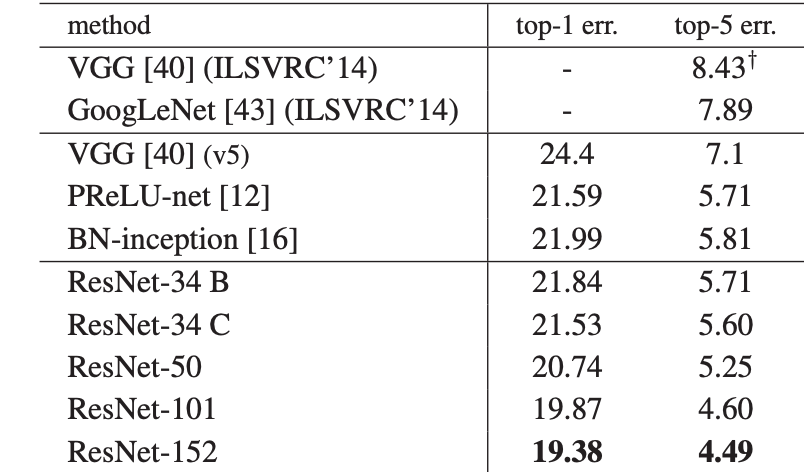
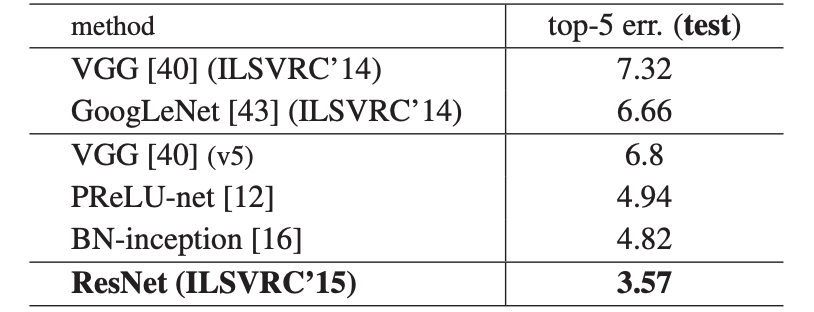
-
위의 그림은 각각 ImageNet 검증 세트에서 단일 모델 결과의 오류율과 앙상블 오류율을 의미한다.
-
ResNet은 학습 오류를 성공적으로 줄인 결과 상위 1%의 오류율을 35% 감소시켰다.
-
50/101/152 Layer ResNet은 34 Layer ResNet보다 상당한 마진으로 더 정확한다.
4.2 CIFAR-10 and Analysis
-
50만 개의 훈련 이미지와 10개의 클래스로 구성된 1만 개의 테스트 이미지로 구성된 CIFAR-10 데이터세트로 구성된.
-
첫 번째 Layer는 3x3 Convoluional Layer이고, 그 다음은 각각 {32, 16, 8} size의 Feature Map에 3x3 Conv Layer가 있는 6n개의 Layer 스택을 사용한다. 각 Feature Map size에 대해 2n개의 Layer을 사용한다.
-
필터의 수는 각각 {16,32,64}이고, 서브샘플링은 보폭이 2인 convolutional으로 구성된다.
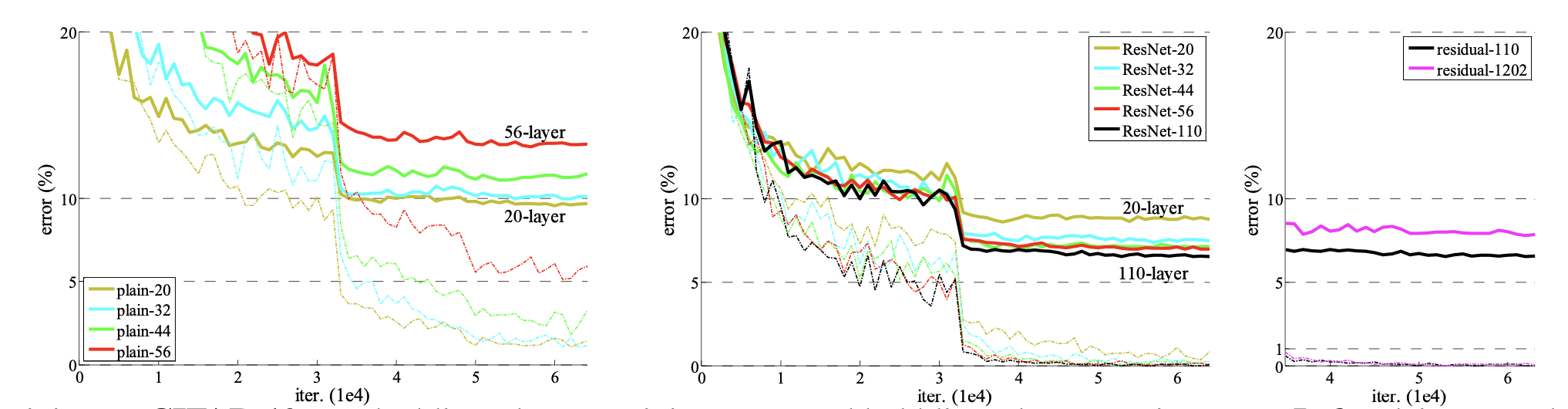
- 1,000개 이상의 Layer를 쌓아봤는데 1,000개 이상의 Layer에서 성능이 낮아지는 것은 overfitting 때문이다. 이 논문에서는 dropout, maxout 등의 regularization이 쓰이지 않기 때문에 추후 regularization으로 문제를 해결해야 한다.
4.3 Object Detection on PASCAL and MS COCO
- VGG-16을 ResNet-101로 대체했을 때의 개선점에 관심을 두었다.
- 가장 주목할 점은 까다로운 COCO 데이터 세트에서 COCO의 표준 지표가 6.0% 증가했다는 것이고, 이러한 개선은 전적으로 학습된 표현에 기인된다.
- ILSVRC & COCO 2015대회뿐만 아니라 여러 트랙에서 1위를 차지했다.
5. Conclusion
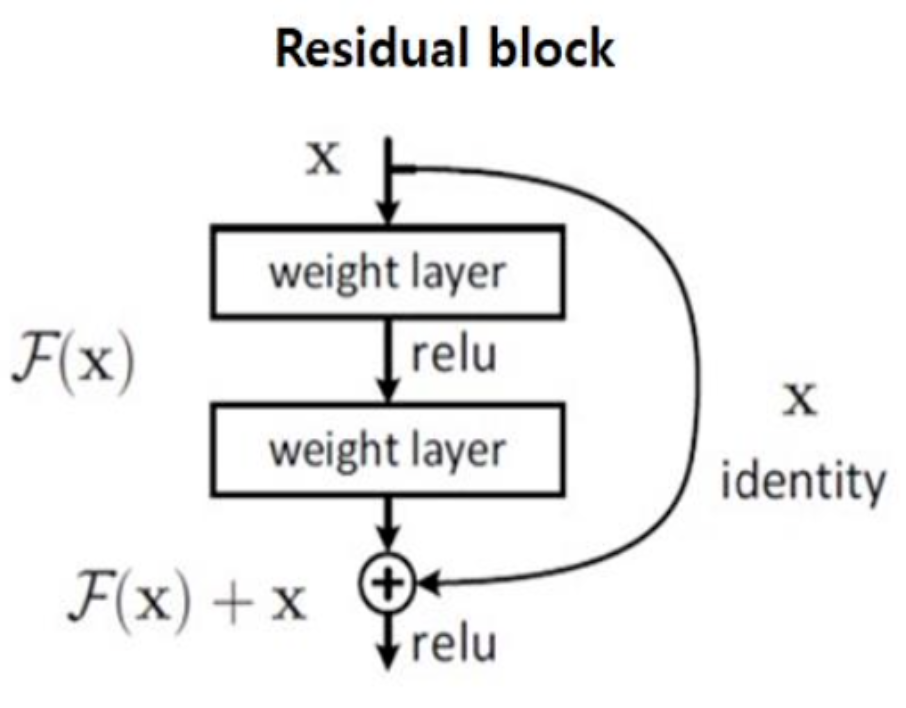
ResNet은 2가지를 확실히 짚고 넘어가야 한다.
1) Identity Mapping
: residual block에 들어온 Input data를 skip함으로써 Output하여 데이터를 보존하는 역할을 한다.
2) Residual Mapping
: 잔차를 학습함으로써 각 residual block에 들어온 Input data의 정보 손실을 줄이고, 이를 통해 성능을 높일 수 있게 하는 역할을 한다.
🎯 Summary
ResNet은 현재까지도 많은 논문에 영향을 끼치고 있기에 평소보다 논문을 더 꼼꼼하게 읽어봤다. Identity, Residual Mapping 이 두 개념을 다른 사람에게 말할 수 있다고 하면, 이 논문을 이해했다고 할 수 있다. 또한, GoogleNet의 Inception module와 같이 Bottle Neck 구조와 매우 유사하고, Layer가 50개 이상이 될 때 1x1 conv를 통해 연산량을 줄여 준다는 특징이 있었다. 여기서 50보다 낮은 Layer에서는 왜 1x1 conv를 추가 하지 않았을까?라는 생각이 들었다. 아마 성능 저하 때문에 그런게 아닌가 싶다.
논문 리뷰는 항상 어려운거 같다. 그럼에도 불구하고 패션 데이터 분석을 위한 한 걸음이라고 생각하며 열심히 논문 리뷰를 해야겠다. 다음은 U-Net 논문과 DenseNet 리뷰이다. 다양한 아키텍처를 공부해서 지식의 확장이 있길 소망한다.
📚 References
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Microsoft Research, 'Deep Residual Learning for Image Recognition'(2015)
- Tistory, 2019.12, ResNet(Shortcut Connection과 Identity Mapping) [설명/요약/정리],
https://lv99.tistory.com/25 - Tobigs, https://tobigs.gitbook.io/tobigs/deep-learning/computer-vision/resnet-deep-residual-learning-for-image-recognition
