[논문리뷰 | NLP] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE (2015) Summary
[논문리뷰]
목록 보기
35/42
Title
- NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE

Abstract
- encoder-decoder model의 고정된 길이의 vector는 성능향상에 bottleneck으로 작용함.
- 이 모델은 RNN, 특히 LSTM을 채택하여 학습 기능을 향상시킴.
- 이 모델의 가장 중요한 차이점은 Context vector를 어떻게 설정하느냐임.
- 이를 개선 할 방법으로, 예측한 target word가 source sentence의 어떤 부분들과 연관이 있는지 자동으로 찾는 모델을 제안함.
1. Introduction
1.1. 논문이 다루는 Task
- 이 논문은 신경 기계 번역(NMT)에서의 어떻게 효과적으로 소스 문장을 타겟 언어로 번역할 것인가에 초점을 맞춤.
- 고정 길이의 벡터를 사용하는 기존 NMT 모델의 한계를 극복하기 위해, 번역 과정 중 소스 문장의 관련 부분을 동적으로 탐색하여 타겟 단어를 예측할 수 있는 새로운 접근 방법을 제안
1.2. 기존 연구 한계점
📌 Encoder - Decoder 구조의 문제점
- 고정된 크기의 벡터가 갖는 Bottleneck 문제가 있음.
-> source sentence를 고정된 크기의 vector에 압축하기 때문에, 긴 문장에 대해서 충분한 정보를 담을 수 ❌
-> 이는 충분한 성능 향상에 대한 방해요소
그래서 input sequence - vector sequence로 Encoding 후, 매 Decoding Stdp마다 vector sequence의 subset을 adaptive하게 선택함.
- 이를 해결하기 위해 align과 translate을 함께하는 방법을 제안함.
- 각 Time Step에서 모델은 번역된 word를 생성하고, source sentence에서 가장 연관이 있는 부분들을 찾고나서 그 다음 모델은 souce position에 기반한 context vector와 이전에 생성된 target word를 이용하여 target word를 예측함.
📌 기존 Encoder - Decoder 구조와 구별되는 점
- 원래는 input sequence에 대해 하나의 고정된 길이의 vector로 표현했지만, 이제 이를 vector sequence로 표현하고 Decoding하는 동안 이 vector의 subset을 adaptively하게 선택한다는 점임.
여기서 adaptively하게 선택한다는 말은?
-> 각 단계에서 모델은 전체 입력 시퀀스에서 가장 관련성이 높은 정보를 포함하는 벡터의 부분 집합을 결정.
-> 이러한 선택 과정은 번역하는 단어나 구에 따라 달라지므로 '적응적'이라고 부름.
2. Related Work
2.1. RNN ENCODER–DECODER
- 고정 길이 벡터를 사용하는 인코더-디코더 구조의 기존 모델들
3. 제안 방법론
3.1. Main Idea
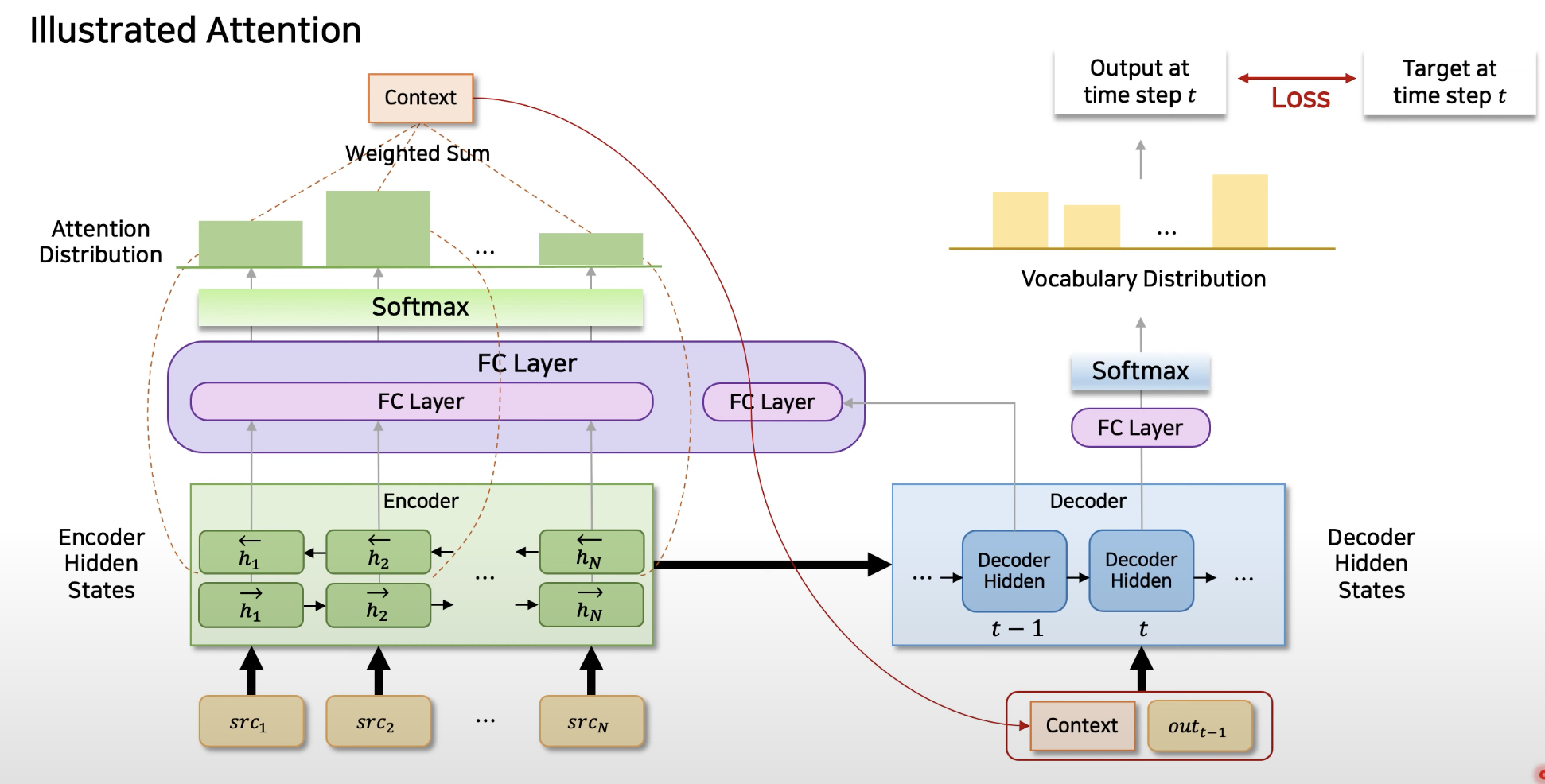
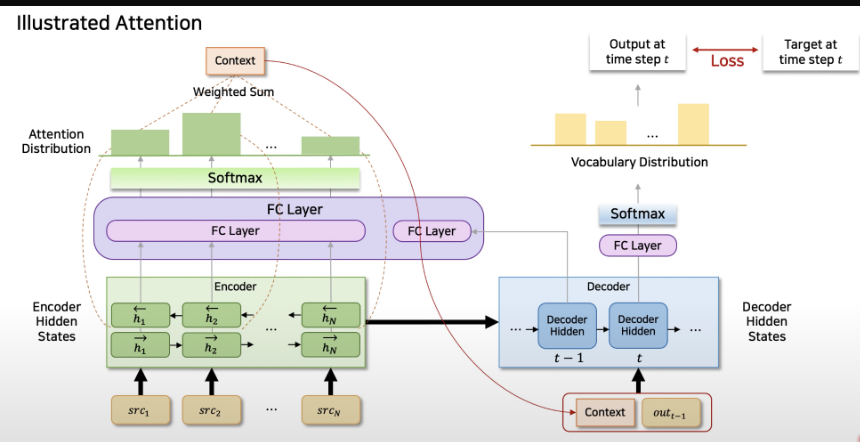
- 신경 기계 번역에서 Attention 메커니즘을 도입하여, 디코딩 과정 중에 소스 문장의 어느 부분에 집중할지를 동적으로 결정하는 방식임.
-> 이를 통해, 고정 길이의 입력 벡터 대신에 입력 시퀀스의 각 부분을 나타내는 벡터 시퀀스를 사용하고, 이 중에서 번역에 가장 관련이 높은 부분을 선택함.
3.2. Contribution
- 번역 과정의 유연성과 정확도를 크게 향상시키며 긴 문장과 복잡한 문장 구조를 더 잘 처리할 수 있게 됨.
4. 실험 및 결과
4.1. Dataset
- WMT'14 사용
-> 이는 Englisht-to-Franch Corpus (총 850M개의 word로 구성되어 있지만, 348M개의 word만 추출하여 학습)
- 토큰화를 통해 가장 빈번하게 사용되는 30,000개의 단어를 선택하여 학습
-> 포함되지 못한 단어는 [UNK]로 변환하여 학습
-> 그 외 전처리 or stemming, lowercasing은 사용 ❌
4.2. Baseline
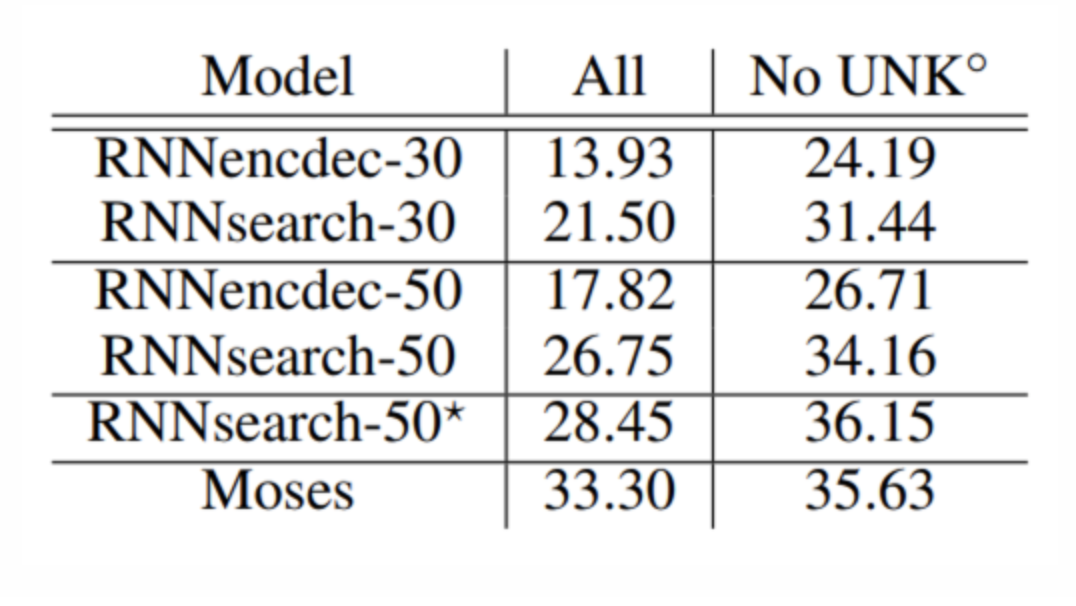
- RNN Encoder-Decoder(RNNencdec, Cho et al. 2014a)와 본 논문에서 제안한 모델인 RNNsearch, 2가지의 모델을 학습하여 비교함.
- 각 모델은 sentence의 길이를 30, 50으로 제한하여 2가지로 학습함.
4.3. 결과
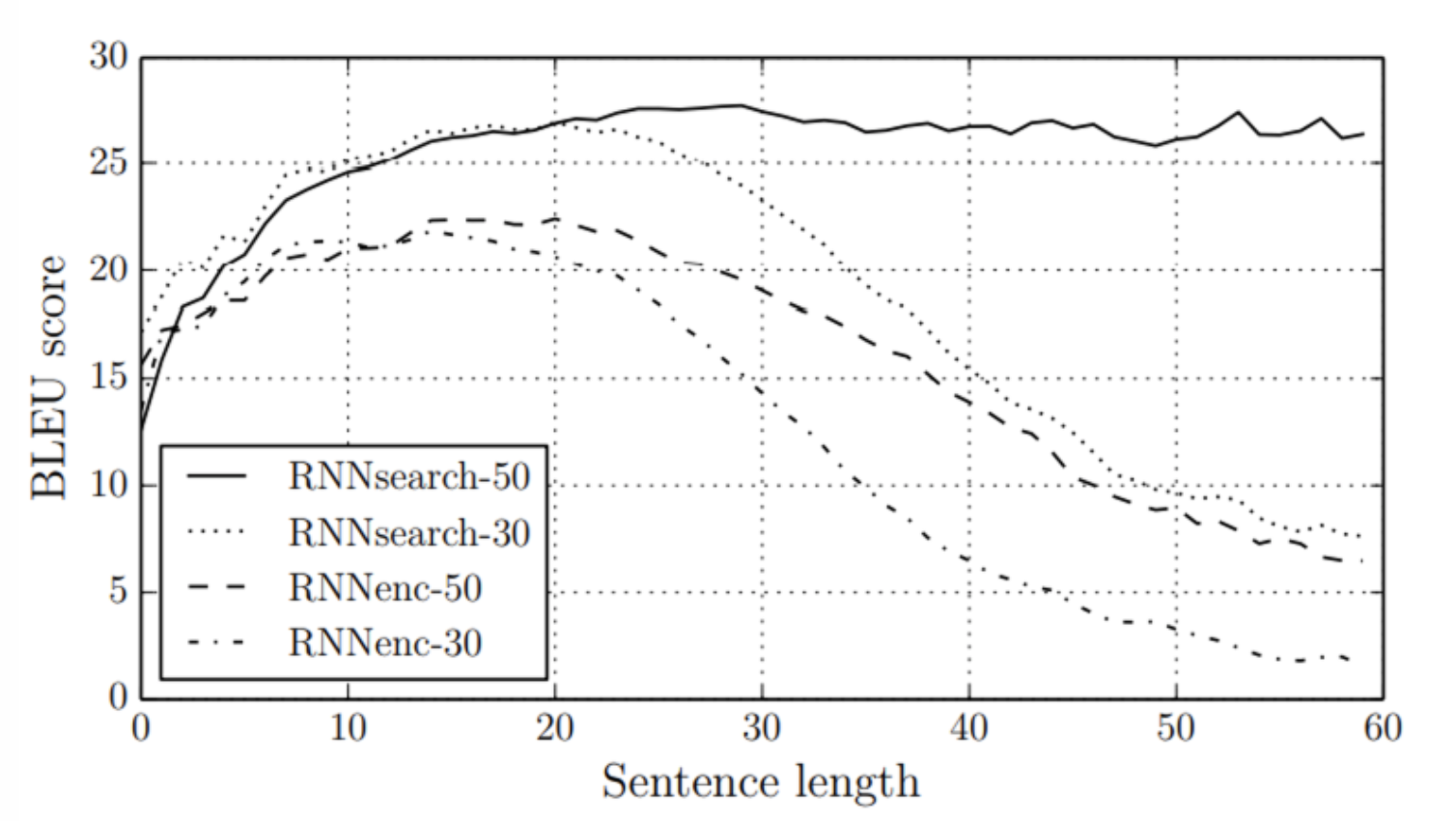
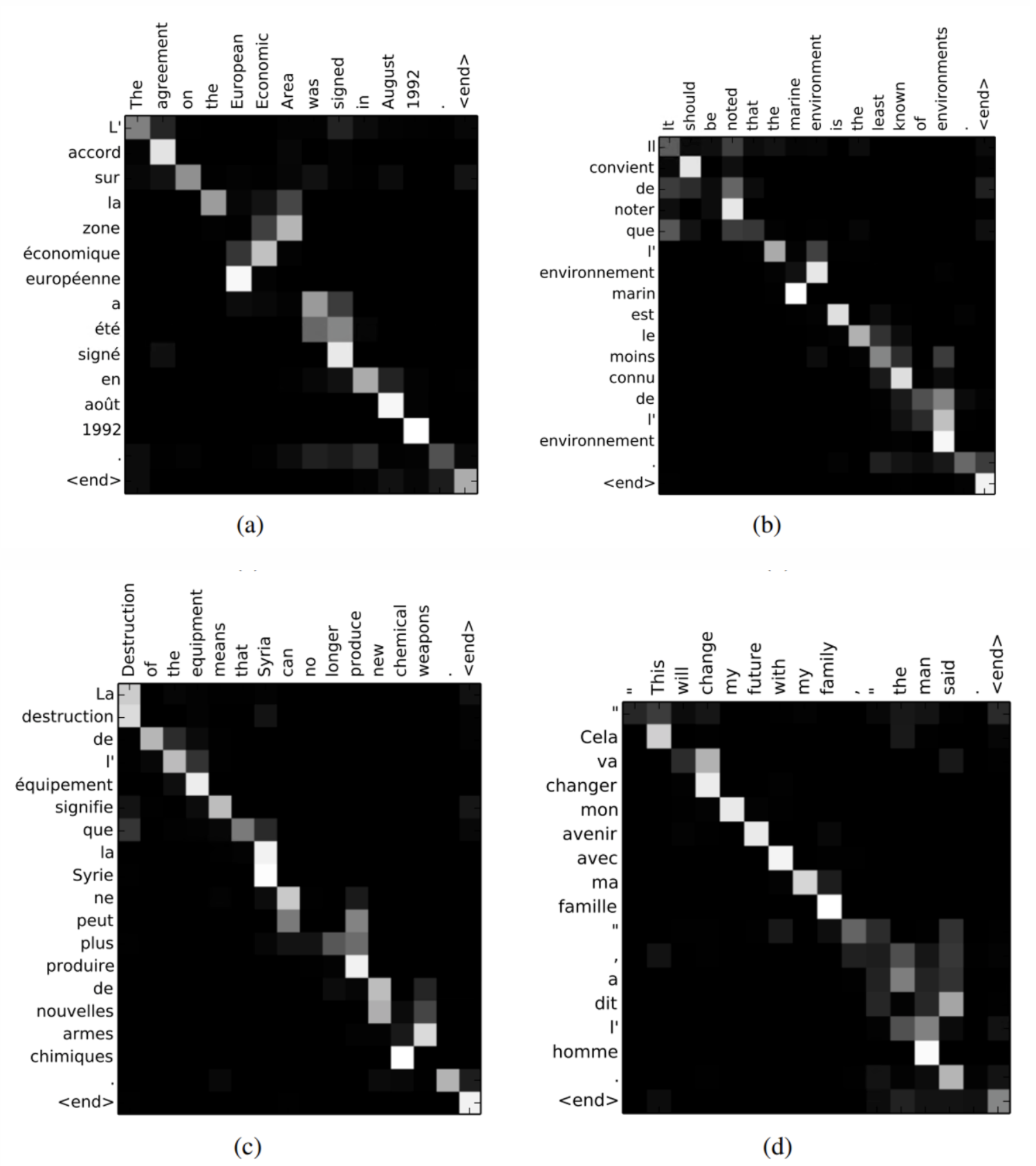
- RNNsearch가 RNNencdec의 성능을 능가함.
-> 특히 RNNsearch-50은 긴 문장에서도 성능 하락이 없었음.
- Align 잘 되는 것을 볼 수 있음.
4.4. 결론 (배운점)
- 하나의 고정된 길이의 vector가 아닌 vector sequence로 표현하는 것이 매우 중요함.
📚 References
논문
유튜브 & 블로그

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊