[논문리뷰 | Anomaly] Graph-based Anomaly Detection and Description: A Survey (2014) Summary
[논문리뷰]
Title
- Graph-based Anomaly Detection and Description: A Survey

이 논문 리뷰는 DSBA(김혜연) 논문 리뷰를 참고하여 작성하였습니다.
0. 논문을 읽기 전에 알면 좋을 것들
Graph Anomaly Deteection 정의
Outlier란 다른 관측치와 매우 상이하고 다른 mechanism에 의해 발생됐다고 의심하게 만드는 관측치를 의미함.
Given: (plain/attributed, static/dynamic) Graph database
Find: 대부분의 그래프의 객체와 다른 객체(edges, nodes)
-> 범위가 광범위함
1. 왜 Graphs를 사용할까?
- Inter-Dependent Data를 잘 고려하기 위해서
- 만약 포인트로 표현하게 된다면, 각각의 데이터로 나타내고 상관 없는 데이터가 나타남.
- 하지만 그래프 기반으로 나타내면 서로 관련된 데이터를 잘 고려할 수 있음.
- 예를 들어, 가짜 후기를 탐지할 때 사용자의 이메일, 네트워크 사용량 등이 서로 관련된 데이터라는 것을 한눈에 볼 수 있음.
- Representation에 유용하기 때문
- Edge를 통해 관련된 Node들에 관한 Inter-Dependency(정보)를 잘 표현할 수 있음.
- Node와 Edge의 특성을 잘 표현해 특성이 많은 데이터셋의 표현에 유용할 수 있음.
- Anomaly의 Relational한 특성
- 하나의 anomaly는 다른 anomaly와 연관될 가능성(개연성, 인과관계)이 일어날 확률이 큼.
- 관련된 그룹, 관련된 사용자에서 anomaly가 같이 등장할 가능성이 큼.
- 예를 들어, 습도로 인한 기계 고장이라면 관련 기계도 고장날 가능성이 큼.
- Adversarially-robust
- 예를 들어, 사기 탐지를 할 때 있어서 로그인 시간이나 IP 주소가 쉽게 조작되어도, 다른 네트워크를 통해 (돈 거래량, 텔레커뮤니케이션, 이메일 등) 사기임을 예측 가능함.
2. Graphs 분류

[기준1] 하나의 그래프를 갖고 있냐 vs 시간대별로 여러개의 그래프를 갖고 있냐
static graph -> snapshot
dynamic graph -> sequence
[기준2] 그래프가 edge or node의 특징을 갖고 있냐 vs 없냐
plain graph -> 구조적인 형태만 가지고 있음.
attributed graph -> 구조적인 형태 + node or edge attribute
2.1. Static Graph
- [Given] 하나의 snapshot을 그리고 있음.
- [Find] 한 장의 그래프가 있을 때, 그 안에서 '희소하고 다른' 패턴을 벗어나는 nodes/edges/substructures를 찾아내는 것임.
2.1.1. Anomaly Detection in Static Plain Graphs
- 주어진 유일한 정보는 '구조'가 유일하므로 구조를 분석하는 방법 위주임.

Structure based methods 구조 기반
- Feature-based approaches
🤜 그래프 구조를 활용해서 중심의 features들(node 차수, edge 수 등)로 이상치 탐지
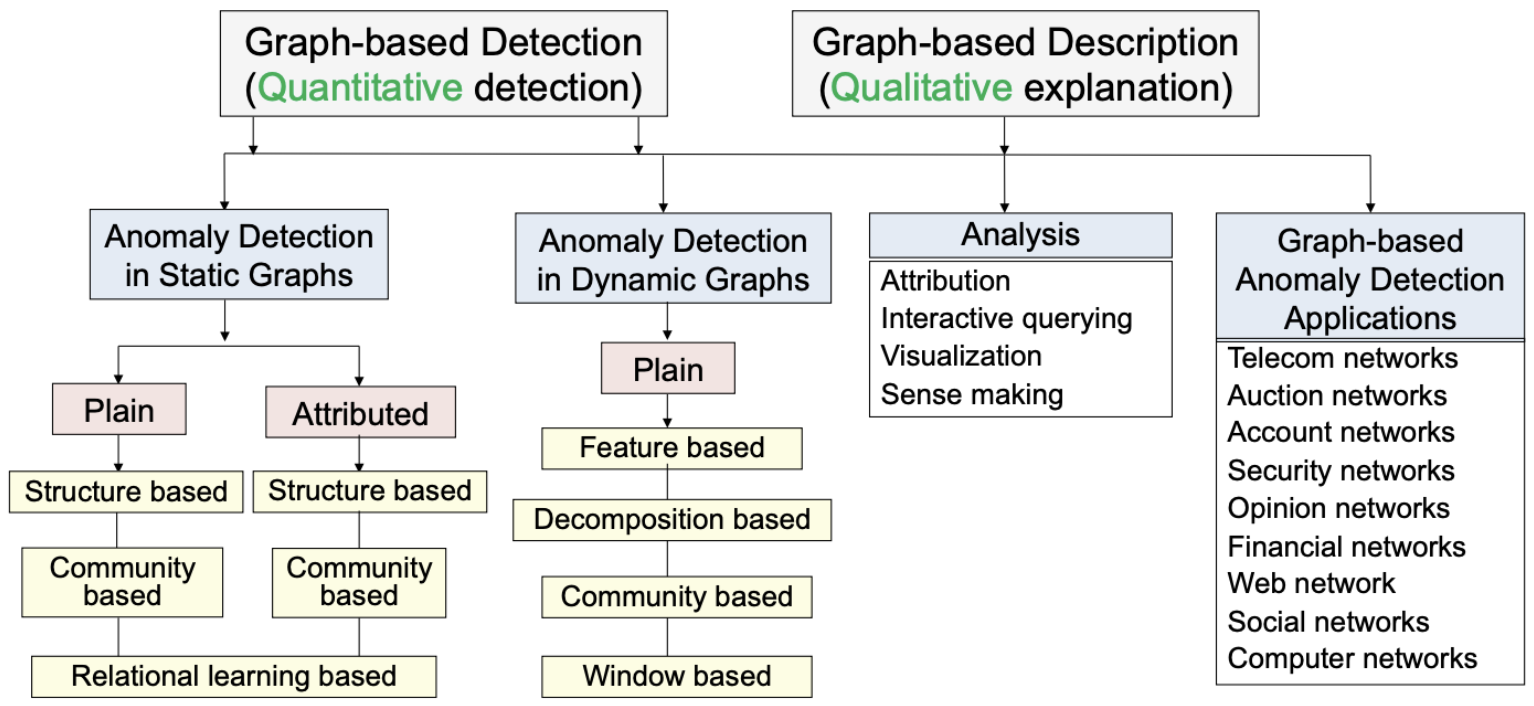
🤜 Ego-network
: 어떤 후보 node가 있을 때, 주변의 거리가 1인 하나의 edge를 연결하는 하나의 네트워크를 조성함.
-> 위 그림 중 초록색 원임.
- Proximity-based approaches
🤜 근접성을 활용해 근접한 객체들은 같은 class에 존재한다는 것을 가정함.
Community based methods 커뮤니티 기반
- 밀접한 nodes로 군집을 이룬 후 그 군집과 연결된 Nodes/Edges를 연결하며 커뮤니티 조성
- 커뮤니티 안에서 특징을 따지고 이상치를 탐지함.
🤜 Ex) SCAN, AUTOPART
Graphs-SCAN (Static Plain)
- 비정상 'node'를 탐지

- 맨 오른쪽 그림은 군집내 응집성이 0.9이므로 군집이 되야하는 조건이 너무 강해서 나머지 모두 outlier로 취급함.
- Graphs-SCAN 같은 경우, 군집내 응집성이 0.8이면 좋은거임.
Graphs-AUTOPART (Static Plain)
- 비정상 'edge'를 탐지
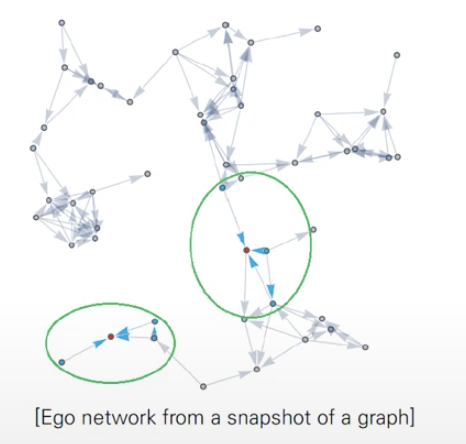
- Total Cost
=Description Cost(유지비용) +Code Cost(정보력)이 최소가 되는 최적의 k도출
- K=1인경우,
🤜 모든 클러스터를 다 갖고 있기 때문에 유지비용이 굉장히 많이 들음 + 정보력은 very good
- K=2인경우,
🤜 유지비용은 적게 듬 + 손실된 정보가 있기 때문에 정보력은 조금 떨어짐
- K=3인경우,
🤜 유지비용은 더 적게 듬 + 정보는 많이 누락되기 때문에 정보력이 많이 떨어짐
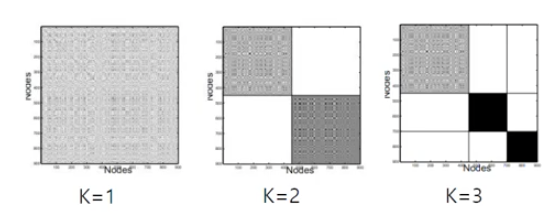
Bridge가 되는 edge를 제외했을 때, cost값이 확연히 변화하면 outlier edge로 판단
- Bridge란?
🤜 클러스터들을 잇는 edge
2.1.2. Anomaly Detection in Static Attributed Graphs
구조와특징을 활용하여 이상치 탐지
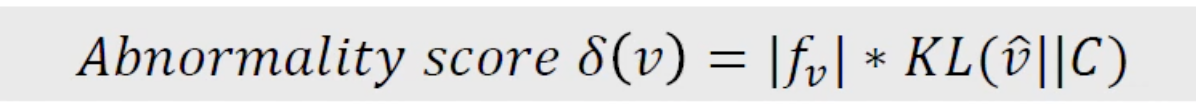
🤜 Edge attribute를 분석해 anomaly를 탐지하는 방법
- EX) {사용자, 영화} / edge:{평가} / edge attribute {평가점수}
변수 설명
- : node 와 연결된 edge들로부터 계산된 edge-attribute value vector의 크기
- ^: node 의 확률분포
- : 모든 atttribute들(평가들)의 global 확률분포
해석

2.2. Dynamic Graph
- 시간대별로 변화의 양상을 보여줄 수 있는 sequence
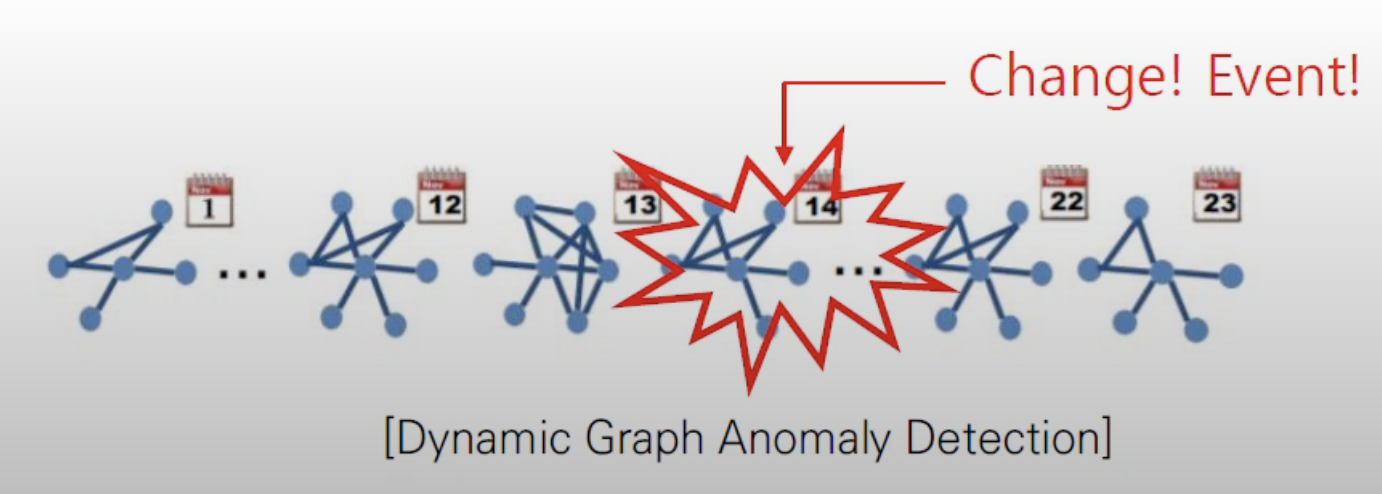
- [Given] sequence of a graph
- [Find]
1) 변화 or 이벤트에 해당하는 timestamp
2) 변화의 원인이 되는 top-k nodes, edges, substructures (attribution)
이와 다른 표현으로는
Event Detecton, Change-point Detection, 순간적인 이상 패턴 detection
2.2.1. Anomaly Detection in Dynamic Graphs(plain, attributed)

1. Anomaious Nodes
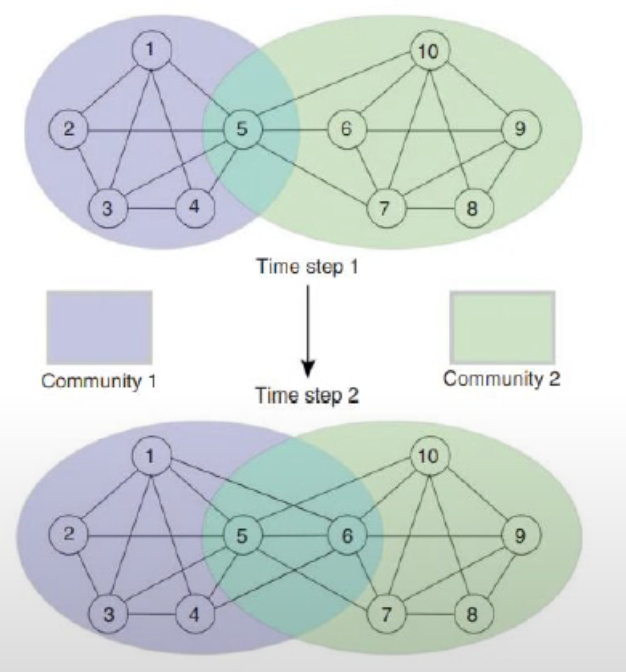
1) 6번 node가 속하는 군집이 변화하였고(구조 변환)
-> 이때 community2에만 속한 것이 community 1에도 속함.
2) 다른 node의 소속이 변화하지 않았으므로 Anomalous
3) 그렇게 때문에 6번 node가 Anomalous한 노드임.
2. Anomaious Edges

1) Edge (3,4)와 (1,4)의 경우 다른 edge의 weight에 비해 증가량(감소량)이 매우 크므로 Anomalous
2) 다른 edge들은 변화하지 않았으므로 Anomalous
3) 그렇게 때문에 (3,4)와 (1,4)는 Anomalous한 엣지임.
3. Graph-based Anomaly Detection & Description
Graph based Anomaly Detection
- [Given]
: (plain/attributed, static/dynamic) 그래프 데이터 베이스
- [Find]
: 대부분의 그래프의 객체와 다른 객체 (nodes, edges, substructures)
Graph based Anomaly Description 문제
- [Given]
: Anomalies of 그래프 구성요소(nodes, edges)
- [해석 & 설명]
: 각각의 anomalies 탐지하고 원인을 찾고 이를 해석 및 설명
- [Find & 특징화]
: 각각의 anomalies에 연관된 요소들을 찾고 특징찾기
3.1. Anomaly 원인 (역으로) 파악
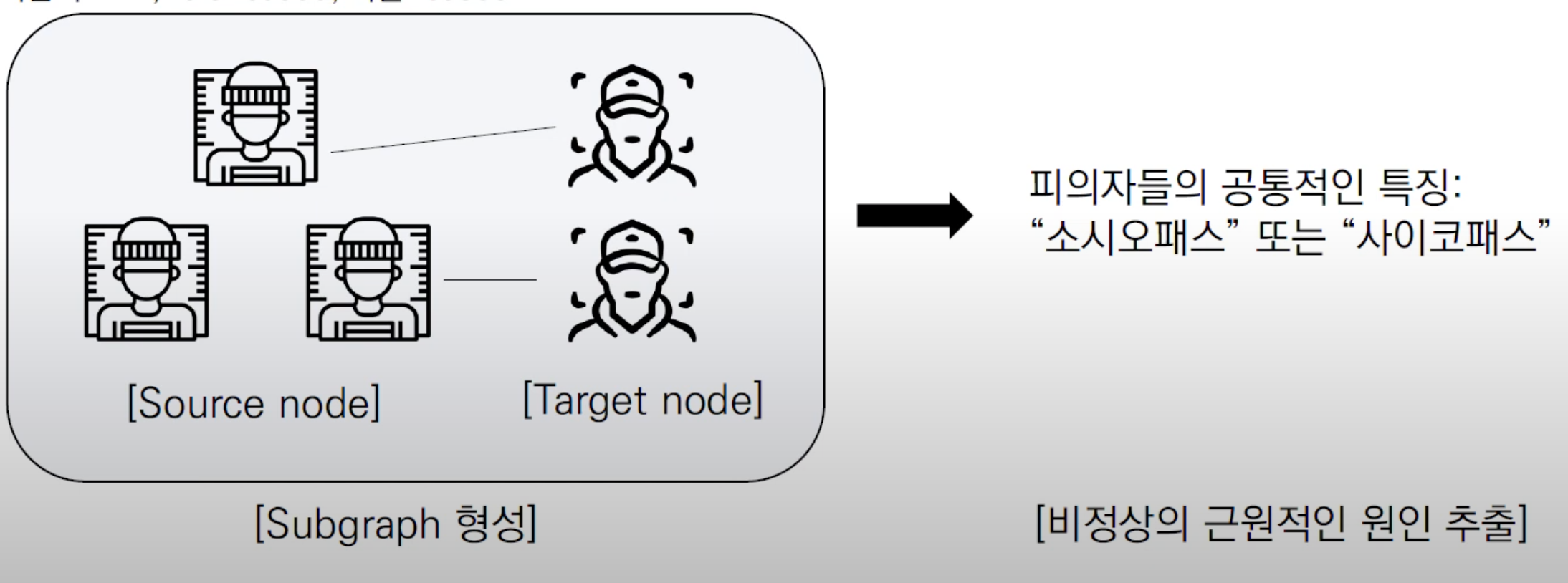
예전방식
-
Source-target queries
: source node에 상응하는 관련된 target node들을 연결 시키면 sub-graph가 형성되며 'potential root. cause for abnormal'을 알기 쉬워짐 -
2018년까지는 직관적으로, rule-based로 찾고 있었음.
- 그 이후부터는 확률-based로 각각의 확률을 고려해서 어떤 특징이 이 그래프를 가장 잘 표현하고 있는지
Dot2Dot
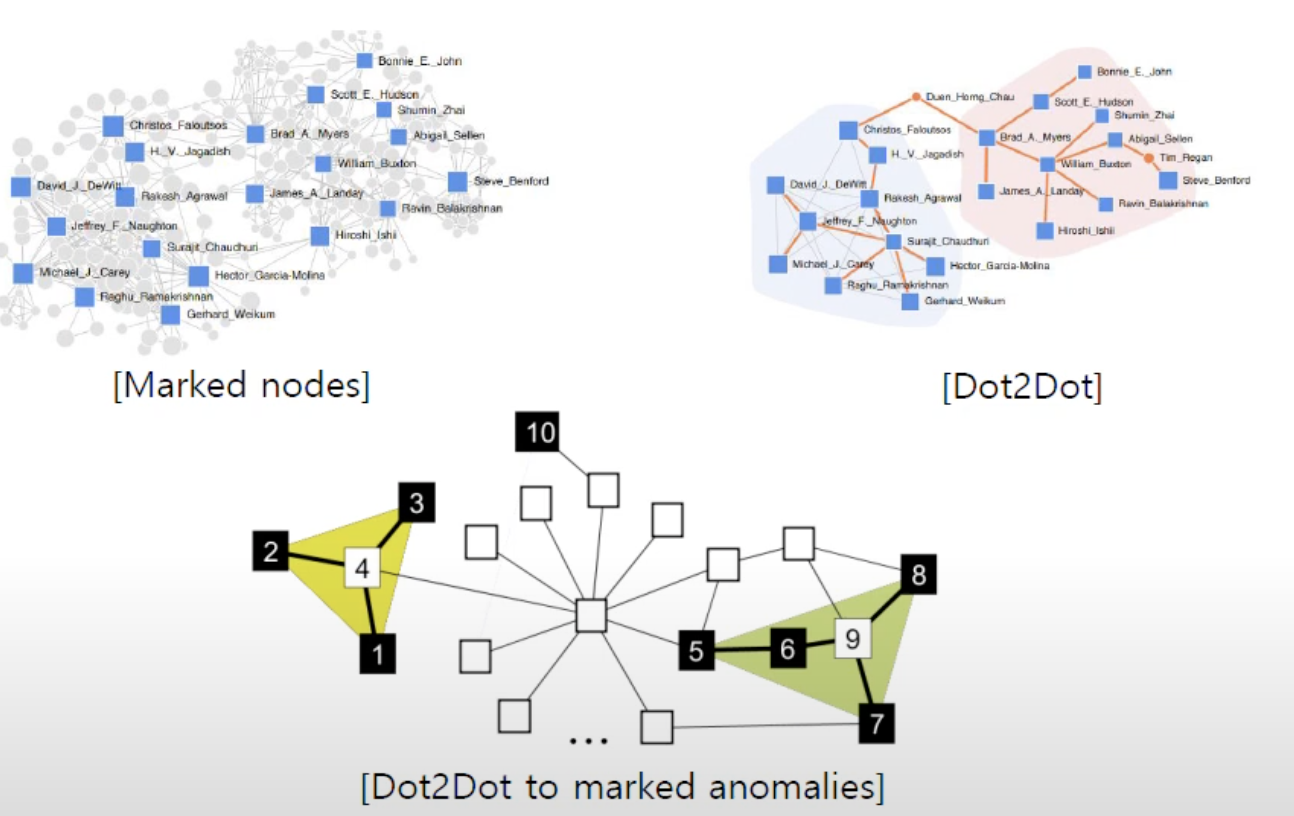
- marked node를 연결하는 가장 단순한 path 결정
- 마킹된 노드들(anomalies)을 그룹들로 나누고, 각 그룹 내 connection을 찾음.
- Anomalies들도 세분화되므로 각 그룹의 특징 및 anomalous한 원인을 찾는 데 도움 됨.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자들은 그래프 데이터에서의 이상 탐지를 위한 최신 방법에 대한 포괄적이고 체계적인 개요를 제공하고자 함.
- 그들은 이러한 알고리즘들에 대한 일반적인 프레임워크를 제시하고, 그 효과성, 확장성, 일반성, 그리고 강인성에 대해 논의함.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- unsupervised vs. (semi-)supervised approaches
- static vs. dynamic graphs
- attributed vs. plain graphs
등 다양한 설정으로 분류함.
- 이상 탐지의 근본 원인을 이해하는 것, 즉 탐지된 이상의 '왜'에 대한 중요성을 강조함.
- 어느 프로젝트에 적용할 수 있는가?
- 금융, 경매, 컴퓨터 트래픽, 그리고 소셜 네트워크와 같은 다양한 분야에 적용 가능할 듯.
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- MiMAG: Mining Coherent Subgraphs in Multi-layer Graphs with Edge Labels (2017)
- Federal Bureau of Investigation (FBI) (2015)
- 느낀점은?
- 논문의 양이 상당했음..(거의 67페이지?) 다 못 읽고 핵심적인 것만 읽어봄.
- 이상치 탐지를 할 때 탐지된 이상치의 원인을 찾고 이를 어떻게 해석할지 그리고 각각의 anomalies에 연관된 요소들을 찾고 특징 찾는 것이 매우 매우 중요하다는 것을 깨달음.
- 이상치 논문에 관해 한번 읽어보면 좋을 듯!!
📚 References
논문
Youtube
- https://youtu.be/1xAIorGMy8I?si=684xiemRF8I0Y8qb, 고려대학교 DSBA 연구실
