[논문리뷰 | NLP] BERN2: an advanced neural biomedical named entity recognition and normalization tool (2022) Summary
1
[논문리뷰]
목록 보기
30/42
Title
- BERN2: an advanced neural biomedical named entity recognition and normalization tool

Abstract
- 이 논문은 생명의학 NLP 분야에서 NER & NEN에 대해서 자세히 다루고 있음.
- 이는 생물의학 문헌에서 질병 or 약물과 같은 생명의학적 Entity를 자동적으로 추출하는 데 중요한 기술임.
- BERN2을 소개하며, 이전의 신경망 기반 NER을 개선함.
(더빠른 추론 속도, 다중 작업 NER 가능)
- 대규모 생물의학 텍스트를 주석 처리하는 데 도움이 될 것임.
1. Introduction
- 생물의학 분야에서 텍스트의 양이 증가함에 따라 텍스트에서 유전자/단백질 or 질병과 같은 Entity을 자동적으로 주석 처리하기 위한 NER & NEN이 사용됨.
- 기존 NER 모델들은 제한된 수의 생물의학적 Entity 유형에 대한 주석만 제공하고, 복잡한 형태학적 변이를 포착하지 못하는 문제점이 있었음.
- 하지만 BERN2는 기존보다 더 많은 유형(총 9가지)의 생물의학적 Entity를 지원하고, multi- task named entity recognition을 통해 주석 시간을 크게 단축하고, NEN 모델을 결합하여 Entity 정규화의 품질을 향상시킴.
- 마지막으로, RESTful API를 통한 웹 서비스로 제공되고, 로컬 설치도 가능함.
2. Method
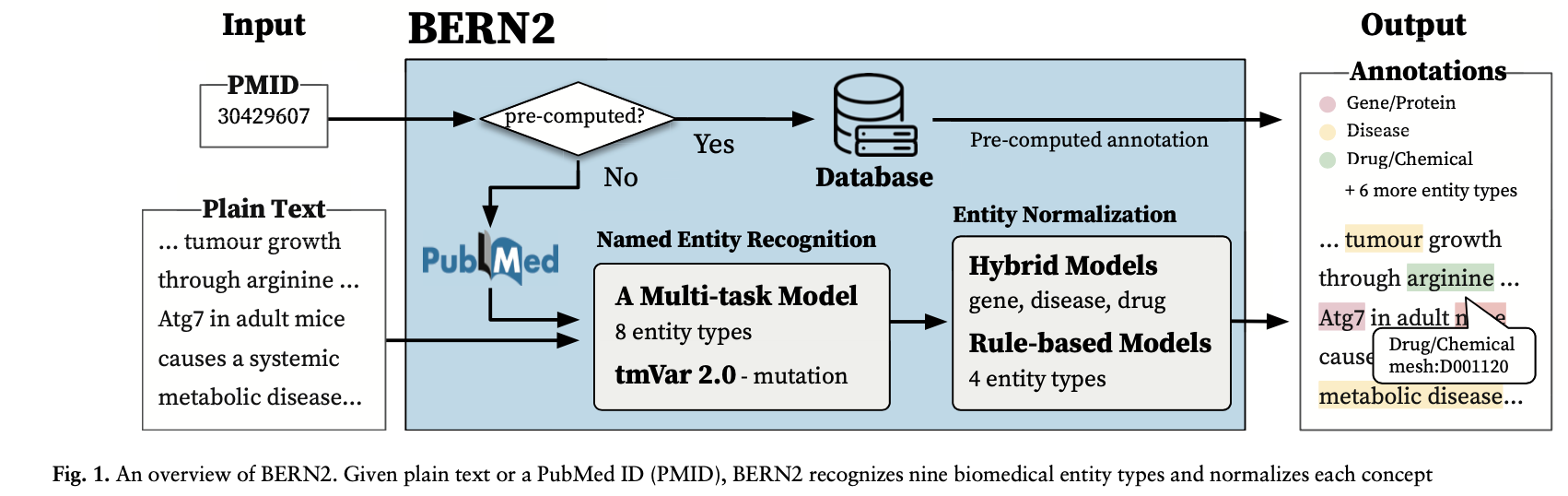
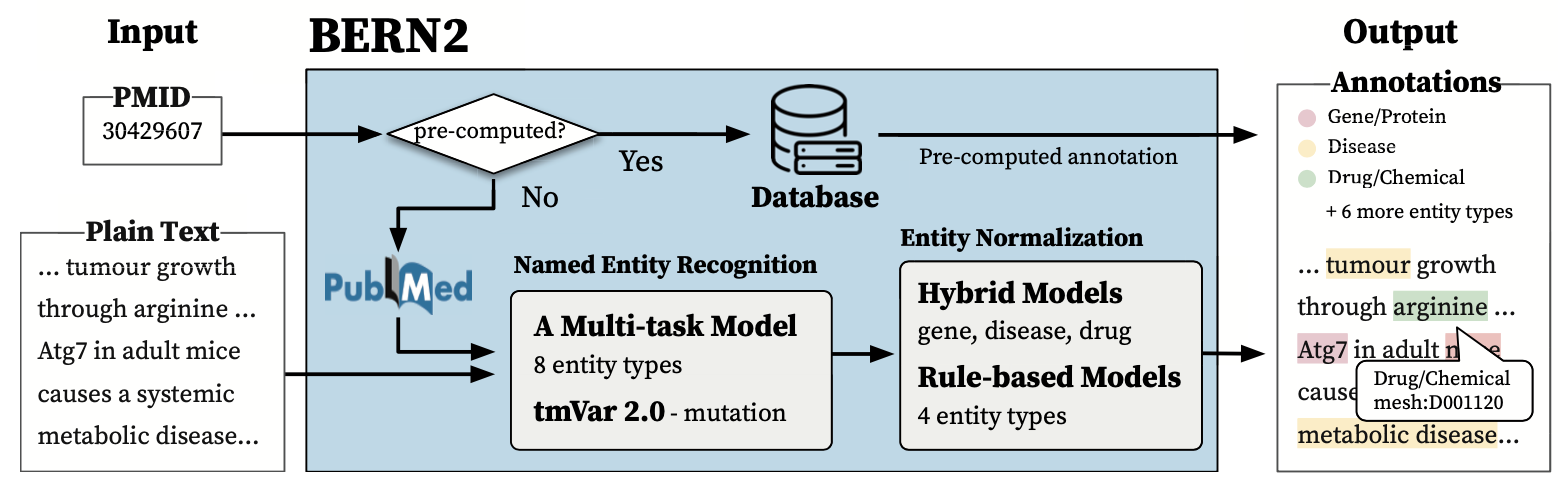
- BERN2는 일반 텍스트 또는 PubMed ID(PMID)를 입력으로 받아, 9가지 생물의학적 Entity 유형을 인식하고 각 개념을 정규화하는 도구.
- 9가지 유형의 생물의학적 Entity는 유전자/단백질, 질병, 약물/화학물질, 종, 돌연변이, 세포주, 세포 유형, DNA, RNA를 인식하고 정규화하는 도구임.
- 사용자는 일반 텍스트 or PubMed ID(PMID) 형식으로 입력 할 수 있음.
일반 텍스트가 입력되면, 텍스트 내에서 생물의학 Entity의 정확한 위치와 유형을 추출하고, 이 Entity을 지정된 사전에 있는 대응하는 CUI로 정규화 진행함.
- 특정한 세 개의 개체 유형(유전자/단백질, 질병, 약물/화학물질)에 대해서는 하이브리드 NEN 모델을 사용하여 정규화의 정확도를 높임.
PMID가 입력되면, BERN2는 미리 계산된 PubMed 주석을 외부 데이터베이스에서 검색하여 제공함.
-> 이는 일반 텍스트를 새로 주석 처리하는 것보다 훨씬 빠름.
2.1. Multi-task named entity recognition
- 이 모델은 이전 버전인 BERN과 달리 여러 개의 단일 유형 NER 모델을 사용하는 대신, 하나의 공유 backbone model과 각 entity 유형에 대한 별도의 작업별 Layer를 결합함.
- backbone model로는 Bio-LM을 사용하여, task-specific layer에는 2개의 MLP와 ReLU 활성화 함수를 사용함.
- 이 모델은 각 토큰이 Entity의 시작, 내부, 외부 중 어디에 해당하는지에 대한 확률을 출력함.
- 학습 과정에서 다양한 유형의 entity에 대해 5개의 train set를 합침.
- BERN2의 다중 작업 NER 모델은 GPU 메모리를 적게 소비하면서도 빠른 추론 시간을 제공함.
ex) BERN의 NER 모델은 약 600ms 걸리는 반면, BERN2는 200ms만에 9개의 유형을 주석 처리함.
2.2. Hybrid named entity normalization
- 기존의 규칙 기반 NEN 모델은 생물의학 Entity의 모든 형태학적 변이를 처리할 수 없었음.
- 해결책으로 BioSyn (2020), 이는 벡터 표현을 사용하여 신경망 기반의 생물의학 NEN 모델임.
- BioSyn은 Entity Encoder로부터 사전 임베딩 행렬을 구축하고, 입력된 멘션 임베딩과 가장 높은 inner product score을 가진 사전 행렬의 Entity 이름을 검색해서 각 멘션을 해당 CUI로 정규화 진행
- BERN2는 먼저 Rule-based 정규화를 시도하고, 이로 정규화되지 않은 Entity에 대해서는 BioSyn을 사용함.
- 이 하이브리드 접근 방식은 유전자/단백질, 질병, 약물/화학물질의 세 가지 Entity 유형에서 사용되며, 각각에 대해 특별히 조정된 BioSyn이 사용됨.
- 이 하이브리드는 NEN 모델을 사용함으로써 정확하게 정규화된 Entity수를 늘릴 수 있음.
- 주석 결과에서는 각 Entity가 Rule based NEN 모델 or BioSyn에 의해 정규화되었는지 사용자에게 표시됨.
3. Results
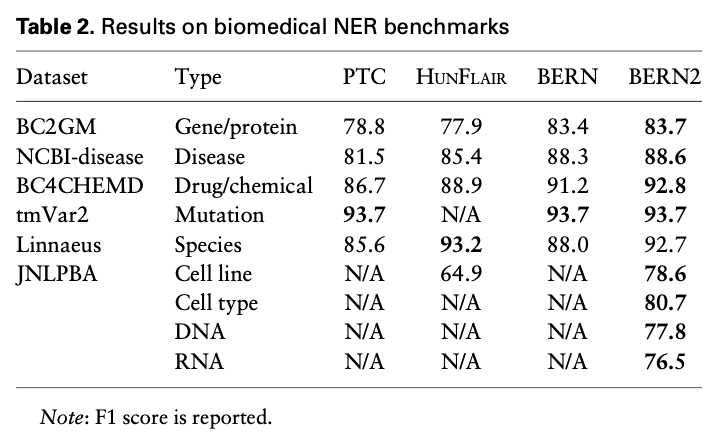
- biomedical NER benchmarks에서 좋은 성능을 보임.

- biomedical NEN benchmarks에서 좋은 성능을 보임.
4. Conclusion
- BERN2는 효율적이고 정확한 생물의학 텍스트 마이닝 도구임.
- 이는 다중 작업 NER 모델과 하이브리드 NEN 모델을 사용하여 기존의 생물의학 텍스트 마이닝 도구들보다 뛰어난 성능을 제공함.
- BERN2는 웹 서비스 / 로컬 설치 두 가지 방식을 지원하여 다른 시스템에서의 사용을 용이하게 함.
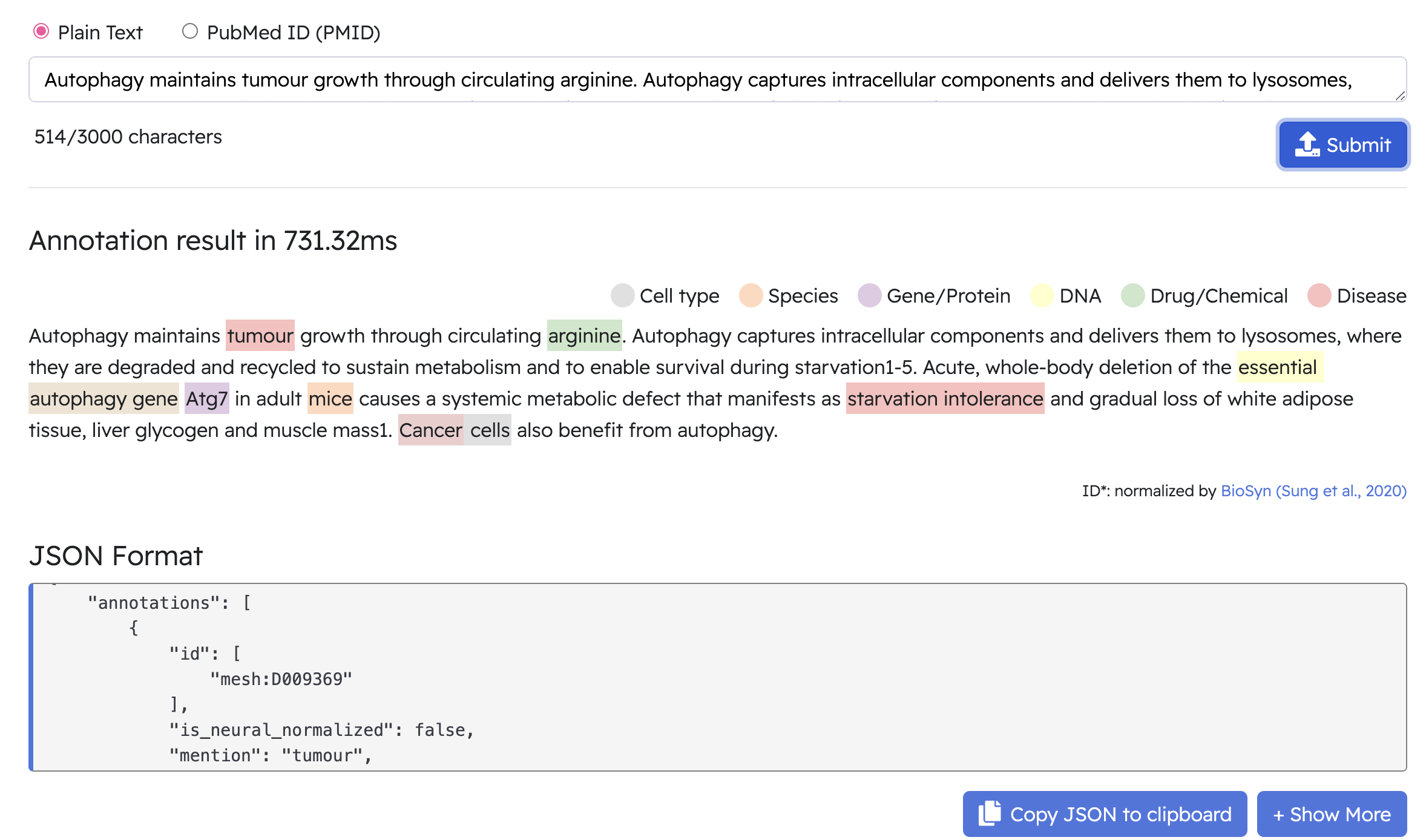
5. Demo
import requests
def query_plain(text, url="http://bern2.korea.ac.kr/plain"):
return requests.post(url, json={'text': text}).json()
if __name__ == '__main__':
text = "Autophagy maintains tumour growth through circulating arginine."
print(query_plain(text))
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 생물의학적 명명체 인식(NER)과 정규화(NEN)를 위한 고급 도구인 BERN2를 개발하고 제시하는 것을 목표로 함.
- 이 도구는 기존의 생물의학 텍스트 마이닝 도구의 한계를 극복하고 문헌에서 생물의학적 개체들, 예를 들어 질병과 약물 등의 보다 정확하고 효율적인 주석을 제공하기 위해 설계함.
- 특히, 다중 작업 NER 모델과 신경망 기반 NEN 모델을 사용하여 문헌에서 생물의학적 개체의 자동 추출을 향상시킴.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
다중 작업 NER 모델: BERN2는 다중 작업 모델을 사용하여 명명체 인식을 위해 여러 생물의학적 개체 유형의 효율적이고 병렬적인 주석을 가능하게 함.
하이브리드 NEN 모델: 이 도구는 규칙 기반 및 신경망 기반 모델을 결합하여 Entity 정규화의 정확도를 높임.
9가지 생물의학적 개체 유형 지원: BERN2는 다양한 생물의학적 Entity를 인식하고 정규화할 수 있으며, 다른 도구들에 비해 더 넓은 범위를 제공함.
웹 서비스 및 로컬 설치
- 어느 프로젝트에 적용할 수 있는가?
- 생물의학 지식 그래프 구축
- 대규모 생물의학 텍스트의 주석
- 생물의학 검색 엔진
- 문헌에서 생물의학적 개체의 추출 및 분석을 포함한 연구
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- BERN
- Bio-LM
- BioSyn
- 느낀점은?
- 의료분야에 특화된 NER & NEN 모델을 찾다가 우연히 발견했는데,
📚 References
논문
사이트

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊