Title
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOv4
0. 논문 읽기 전에 알면 좋을 것들
정이는 성장중 velog를 참고하여 작성하였습니다.
ㄱ. Backbone & Head
Backbone

- 입력받은 이미지의 Feature를 추출하는 역할
- BackBone은 특성추출이 목적이기 때문에 Classification을 목적으로 만들어진 모델을 사용함
- 그 당시 가장 성능이 높은 Classification 모델은 VGG16 모델이었으나, YOLO의 저자들은 자신들만의 BackBone 모델인 DarkNet 모델을 만들었음.
- 입력 받는 이미지의 해상도가 448 x 448로 VGG가 받던 224 x 224보다 4배나 더 크고 처리속도가 빠름.
Head
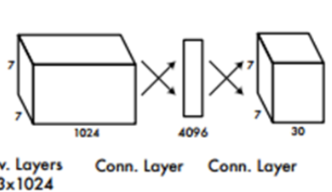
- 특성이 추출된 Feature map을 받아 Object Detection 역할 수행
- 위의 그림은 YOLO v1 architecture임.
- 마지막 출력값을 보면, 448 x 448 해상도를 가진 이미지 한 장을 입력 받았을 때, 7,7,30 사이즈의 3차원 Tensor를 출력값으로 내보냄
- 즉, 출력값의 셀 하나가 원본 이미지의 64 x 64영역을 대표(448 / 7 = 64) + 이 영역에서 검출된 30개의 데이터가 담겨져 있음
ㄴ. Overlap Problem & NMS
Overlap Problem

- Bounding Box들이 같은 객체를 가리키고 있는 것을 overlap problem이라고 함.
- 목표는 각 object에 대해 Single Bounding Box를 생성하는 것이기 때문에 위의 방식은 매우 비효율적임.
NMS
(None Maximum Suppression)
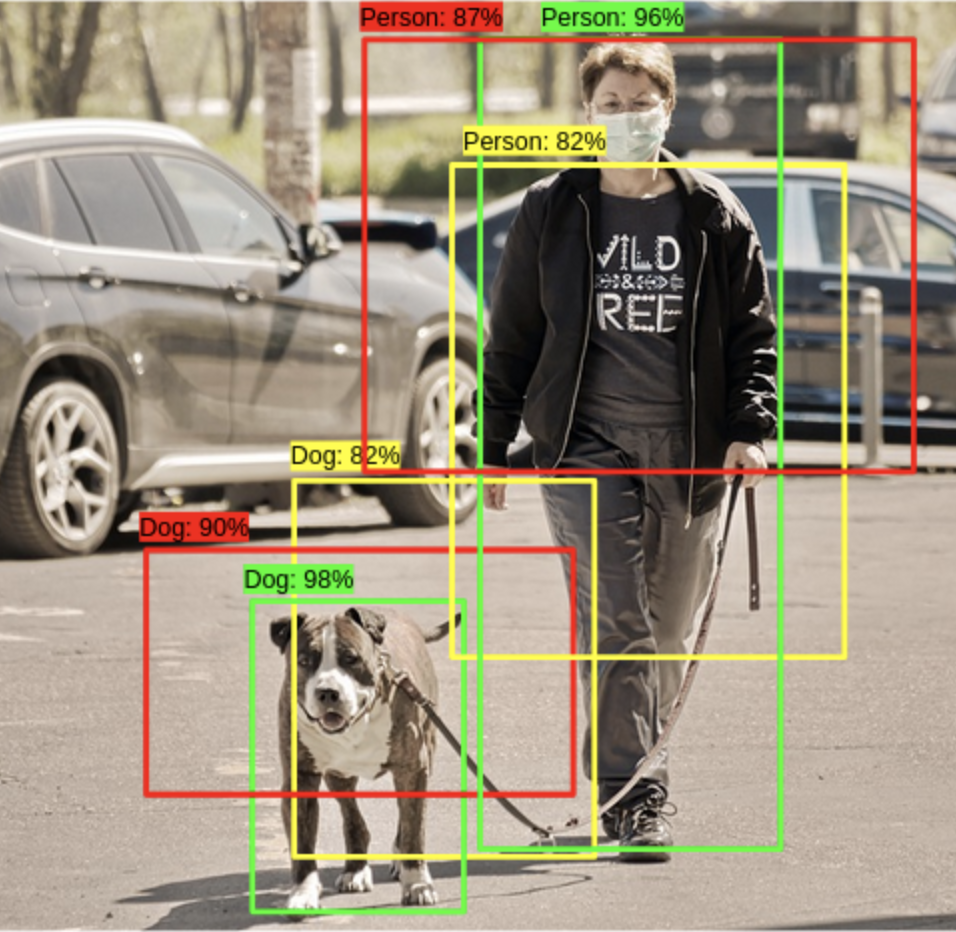
- 예측한 Bounding Box 중에서 정확한 Bounding Box를 선택하도록 하는 기법임
- 위의 사진을 보면, 가장 적합한 Bounding Box는 녹색 Box
- Objectiveness Score가 가장 높은 bounding box를 선택 후 overlap이 높은 Bouding Box를 제거함
IoU (Intersection over Union)
: Bounding Box 간의 overlap를 확인할 수 있는 지표로서, 객체 검출에 대한 성능 지표
Objectiveness Score
: Bounding Box와 같이 변환하는 score로, 모델이 Bounding box에 Object가 존재함을 얼마나 확신하는가를 나타냄.

과정
- 가장 높은 Confidence Bounding Box 선택
- 선택된 Bounding Box와 다른 모든 Bounding box와 IoU 비교
- 다른 Bounding Box와 IoU값이 임계값 이사잉면 목록에서 제외
4 반복
문제점
- 단일 threshold에 따라 달라지기 때문에 이를 설정하는 것은 매우 까다로움
- 물체가 겹쳐있을 때 작은 score를 가진 Bounding Box가 무시됨
Soft-NMS
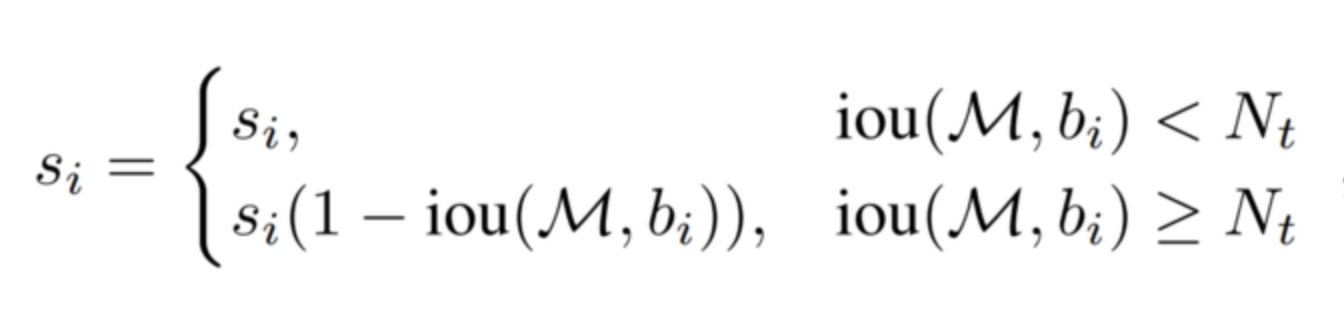
- 높은 IoU와 높은 Confidence Score를 가진 proposal을 완전히 제거하지 X
- IoU값에 비례하여 proposal의 Confidence를 감소시킴
- 위의 그림과 같이 과 가 일정 값 이상일 때, score를 감소시킴.
- 과 의 IoU가 높으면 높은 가중치를 부여하고, IoU가 낮으면 낮은 가중치를 부여함.
문제점
이 함수는 임계값을 기준으로 score가 급격하게 변하여 연속형 함수가 X
ㄷ. YOLO 버전별 정리
🏆 2023년 7월 기준 YOLO는 버전 8까지 나왔습니다! 🏆
YOLO란 Object Detection 모델로, Input에 Image을 넣으면 해당 사진에 있는 물체의 종류, 확률과 위치를 Box로 표시(localizer)해주는 것을 의미함.
장점👍: 실시간에 적용가능할 정도로 빠름
- YOLO v1(2016)
: 2016년에 발표된 최초 버전 + 실시간 Object Detection을 위한 딥러닝 기반의 네트워크
- YOLO v2(2017)
: 2017년 두번째 버전 + YOLO v1의 성능을 개선 & 속도를 높임
- YOLO v3(2018)
: 2018년 세번째 비전 + 기존 네트워크 구조와 학습 방법 개선 & 정확도 및 속도를 높임
- YOLO v4(2020.06)
: 2020년 4월 + SPP와 PAN 등의 기술을 활용하여 정확하고 빠른 속도의 Object Dection
- YOLO v5(2020.07)
: 2020년 6월 + YOLO v4와 비교했을 때 Object Detection 정확도가 10% 이상 향상됨 + 빠르면서도 더 작은 모델 크기를 가짐
- YOLO v7(2022.07)
: 2022년 7월 + Train과정의 최적화에 집중 + Train Cost를 강화하는 최적화된 모듈 & 최적 기법인 trainalbe bag-of-freebies를 제안
- YOLO v6(2022)
: 2022년 9월 + 알고리즘의 효율을 높임 & 특히 시스템에 탑재하기 위한 Quantization & Distillation 방식을 도입하여 성능 향상
- YOLO v8(2023)
: 2023년 1월 + 새로운 repository를 출시하여 Object Detection & Instance Segmentation
& Image Classification 모델을 train하기 위한 통합 프레임워크로 구축함
a. YOLO v1
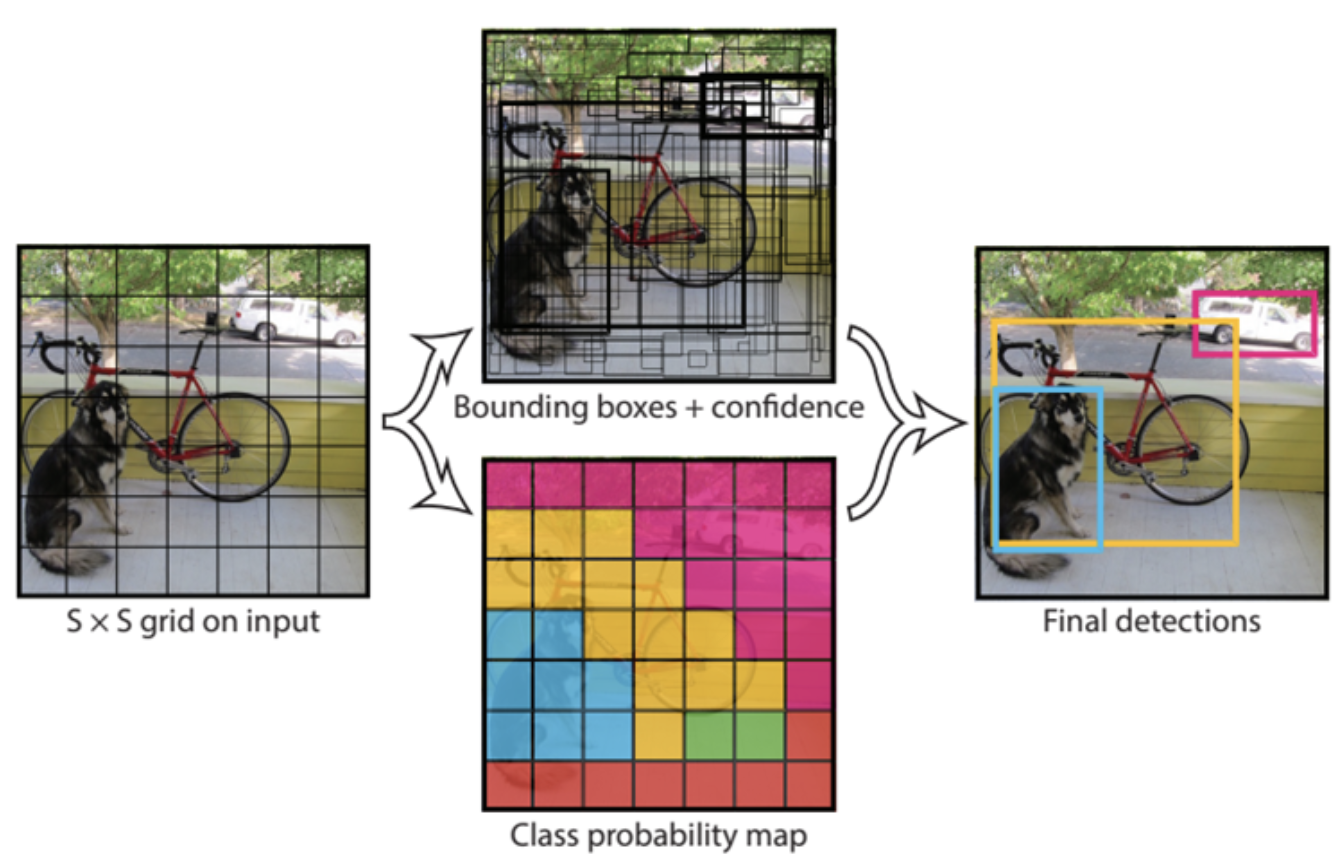
- S x S 크기의 Grid Cell로 Input Image를 분리함
- Cell마다 Bounding boxes, Confidence Score, Class Probability를 예측함

- 각각의 Grid Cell마다 개의 Bounding Box가 생성됨
- 인접한 Cell이 같은 객체를 예측하는 Bounding Box를 생성하는 문제 발생
해결
: Confidence score & IOU를 계산하여 가장 높은 Confidence score의 Bounding Box를 선택하고 선택한 Bounding Box & IOU가 큰 나머지 Bounding Box를 삭제함

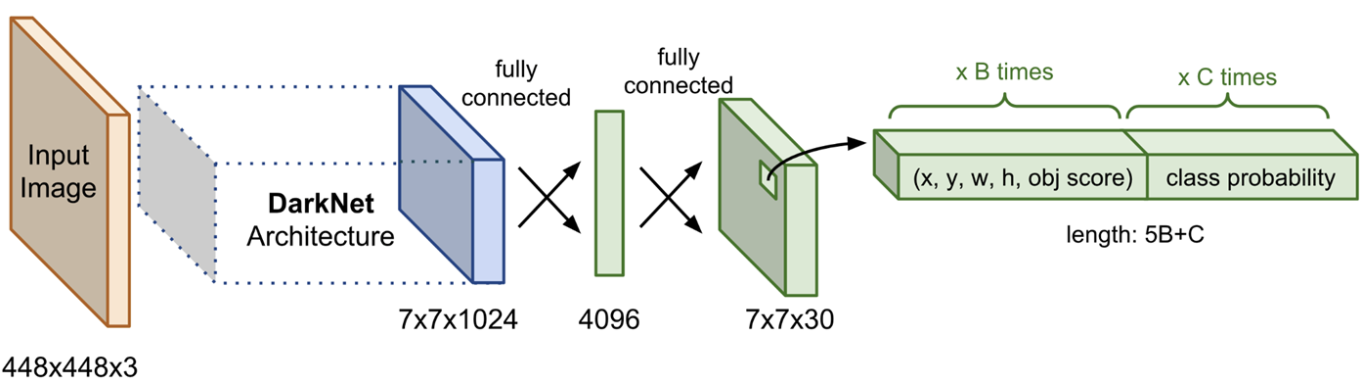
Architecture
- 1-stage 방식으로 24개의 Conv Layer(DarkNet: CNN Layer 20개 / Head: CNN Layer 4개)와 2개의 FC Layer로 구성됨
- BackBone으로 Darknet를 사용하며 ImageNet dataset으로 Pre-trained 된 network를 사용함
- 1 x 1 Conv Layer와 3 x 3 Conv Layer의 교차를 통해 파라미터 감소
정리
1. 당시 SOTA들에 비해 Real-Time 부분에서 가장 좋은 성능을 보임
2. 인접한 Cell들이 동일한 객체에 대한 Bounding Box를 생성 할 수 있음
3. 각 Grid Cell은 하나의 Class만을 예측
한계점
1. 근처에 여러 물체들이 몰려 있을 경우 식별하지 못함.
🤜 지역적 제한 때문에 작은 물체들이 많이 몰려있는 상황에서는(ex.강아지, 새) 식별 X
2. Incorrect Localization으로 인해 Loss Function은 작은 Bounding Box와 큰 Bounding Box에서 오류를 동일하게 처리하게 됨.
b. YOLO v2
- DarkNet ->
DarkNet19
- Anchor Box 도입으로 인한 학습 안정화
🤜 YOLO v1에서는 Grid 당 2개의 Bounding Box 좌표를 예측하였음.
🤜 YOLO v2에서는 Grid 당 5개의 Anchor Box를 찾음.
Anchor Box vs Bounding Box 비교
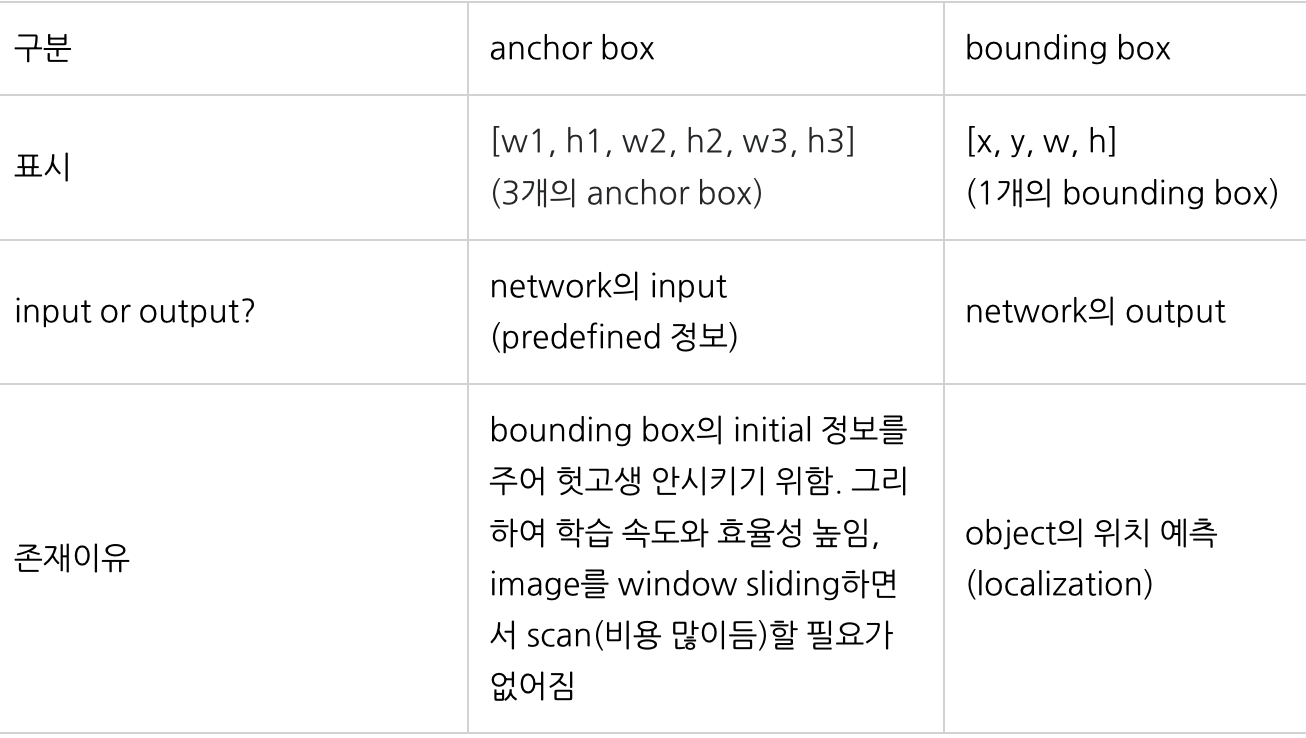
본 논문의 핵심은
(1) 네트워크 설계 과정에서 K-Means Clustering을 활용했다는 점
(2) Batch Normalization, Anchor Box 등 그 당시 최신 논문 Idea를 도입했다는 점
Batch Normalization
: 기존 YOLO v1에서 Dropout Layer 제거 후 Batch Norm 사용해서 mAP score 2% 달성함
Anchor Box
: 여러 개의 크기와 비율로 미리 정의된 형태를 가진 Bounding Box로 형태와 개수를 임의로 지정 가능함.
🤜 미리 지정된 box의 offset(size, ratio)을 예측하기 때문에 훨씬 간단해짐
Dynamic Anchor Box
: Faster R-CNN에서 Anchor Box의 size와 ratio을 정하는 문제가 제기되어 제안됨
🤜 K-Means Clustering을 통해 최적의 Anchor Box를 탐색함으로써 데이터셋 특성에 적합하게 생성 가능함
Hight Resolution Classifier
: 224 x 224 size -> 448 x 448 size로 Pre- train
🤜 mAP 4% 향상
Architecture
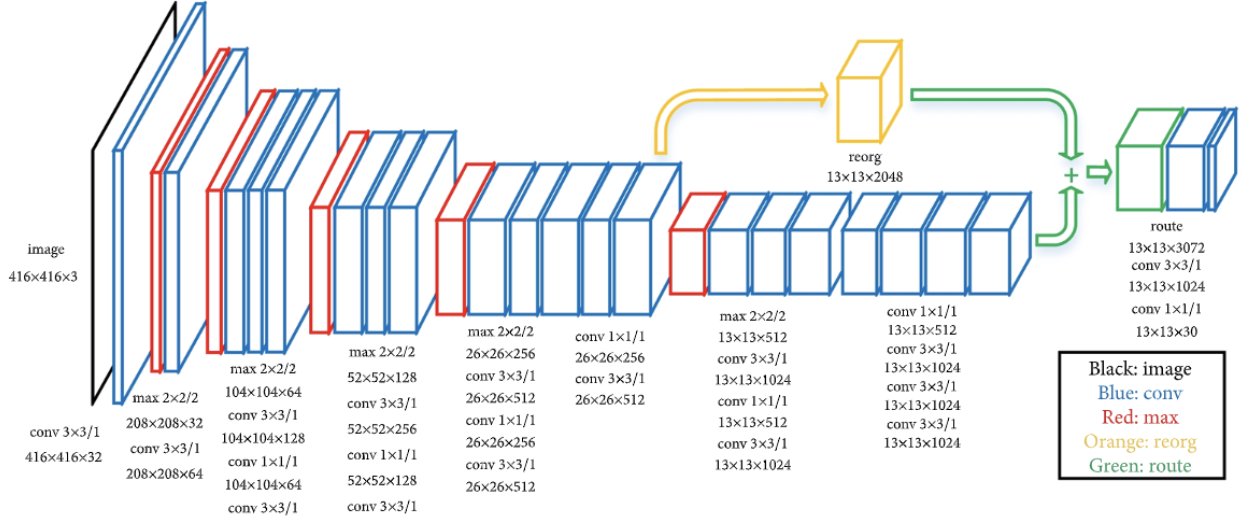

- Fine-grained Features 적용
🤜 중간 Feature Map과 최종 Feautre Map을 합쳐서 이용함
🤜 중간 Feature Map은 지역적 특성을 잘 반영하기 때문에 객체 검출에 Good
- YOLO v2는 3 x 3 Conv와 1 x 1 Conv를 활용하여 13 x 13(x 125) 크기의 Feature map을 출력함.
- Feature map의 크기가 작은 경우 큰 객체를 예측하기 용이함. 하지만 크기가 작은 객체는 예측하기 어려움.
- 기존 DarkNet -> DarkNet19로 제안
- 기존 YoLO v1의 마지막 FC Layer를 삭제하여 1 x 1 Conv Layer로 대체함
- Global Average Pooling을 사용해 파라미터를 줄여 속도 향상
정리
- mAP 값이 73.4%로 당시 SOTA모델인 ResNet, Faster-R-CNN 모델과 비승한 성능을 보였지만, Detection 속도 측면에서 압도하였음.
- 입력 이미지의 크기에 따라 정확도와 Detection의 속도가 trade-off 발생
ex. 이미지의 크기가 작을 경우 정확도👎 / Detection 속도 👍
- 입력 이미지의 크기에 따라 정확도와 Detection의 속도가 trade-off 발생
- K-means clustering을 활용하여 network을 설계함 + anchor box + batch normalization
c. YOLO v3
- YOLO v2 모델에 비해 Detection 속도가 느려짐. 하지만 Detection 성능을 대폭 개선하였음.
Architecture
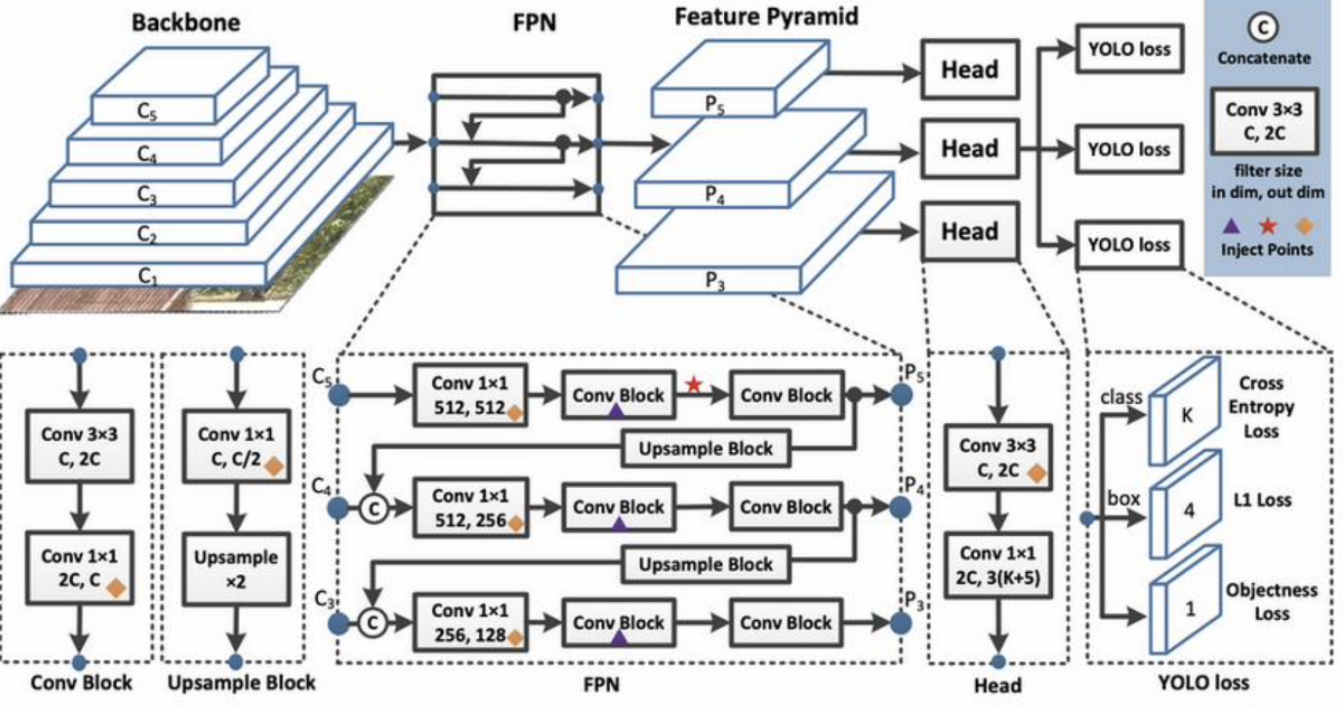

- DarkNet 53 + Skip Connection
- Pooling Layer 삭제됨
- SSD의 Multi-Scale Feature Layer와 Retinanet의 FPN(Feature Pyramid Network)와 유사한 기법 적용
- Multi-Scale Feature Layer
: 이는 서로 다른 크기의 Feature Map에 각 point마다 Object Detection을 수행해주는 기법임
- FPN
: Top-Down방식으로 Feature를 추출하며, 각 추출된 결과들인 Low-Resolution & High-Resolution을 묶는 방식임
정리
- SSD의 Multi-Scale Feature Layer와 유사한 기법과 FPN 적용
- DarkNet 19 -> DarkNet 53 (개별 Feature Extractor 사용)
- 하나의 Grid Cel 당 3개의 Anchor Box로 진행
- Multi-Label Classification을 해결하기 위해 클래스 분류 시
Softmax X 독립적인 여러개의 Sigmoid Layer 사용
- Multi-Label Classification을 해결하기 위해 클래스 분류 시
- Layer 중간에 Feature Map size 축소를 막기 위한 Up Sampling 사용
- Multi-Scaling, Data Augmentation tkdyd
- ResNet과 같이 SKip Connection 사용
🤜 Gradient Vanishing (기울기 소실)을 방지하기 위해
- ResNet과 같이 SKip Connection 사용
Abstract
지금까지 YOLO 1~3 시리즈에서는 정확도를 향상시키는 Feature들은 많이 있었지만 작은 데이터셋에서만 작동하였음.
YOLO v4는 기존 YOLO 시리즈의 작은 Object Detection 문제를 해결하고자 하였고, 대규모 데이터셋에 사용하기 위해 다양한 Feature 조합에 대한 결과와 실제 시험의 타당성이 필요함 + BN, Residual Connectivity와 같은 기능들을 적용
- Weighted-Residual-Connections (WRC)
- Cross-Stage-Partial-Connections (CSP)
- Cross-mini-Batch Normalization (CmBN)
- Self-adversarial-training (SAT)
- Mish-activation
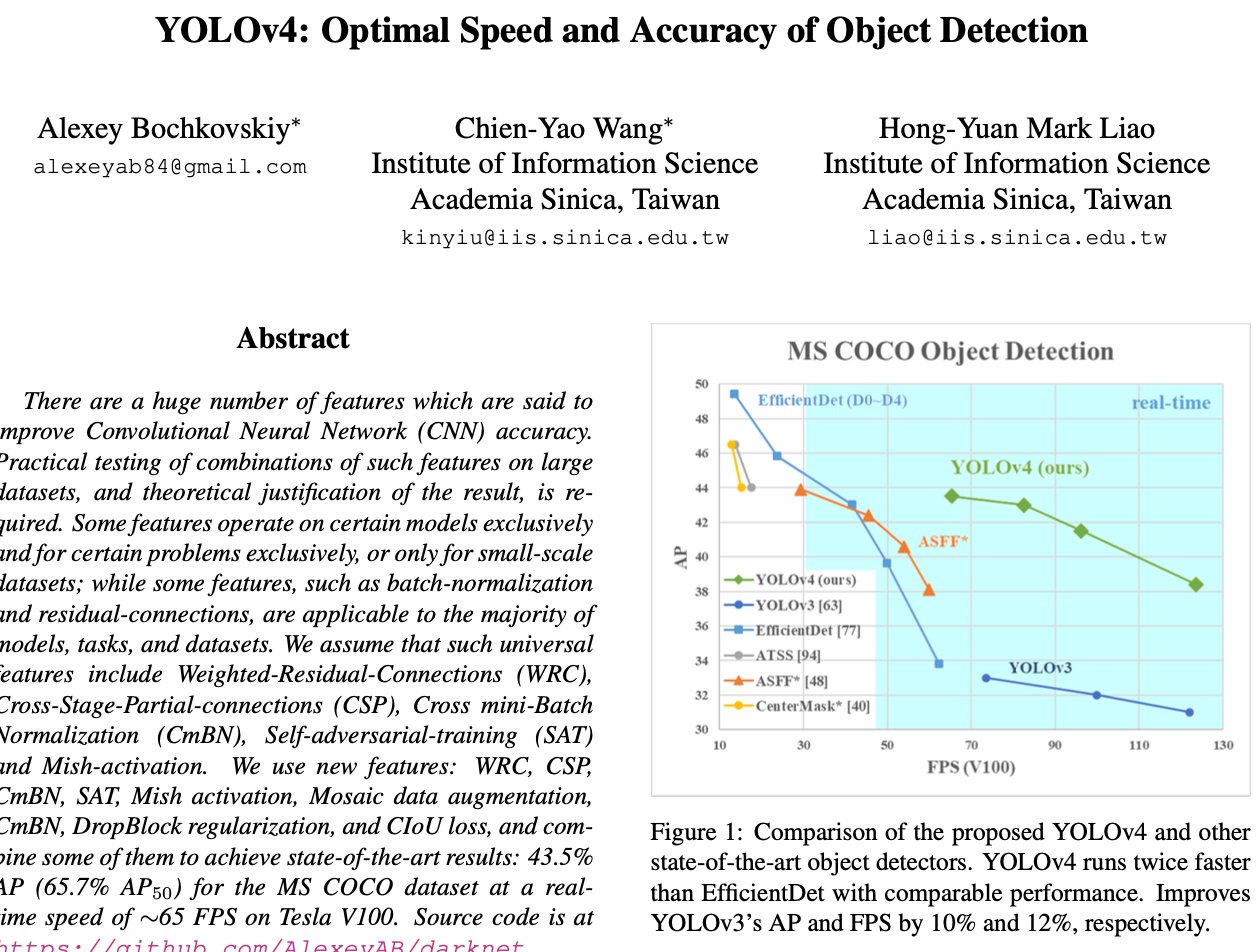
🏆 위의 기능들을 조합하여 MS coco dataset에서 43.5% AP와 실시간에 가까운 65 FPS를 달성한 SOTA model임 🏆
1. Introduction
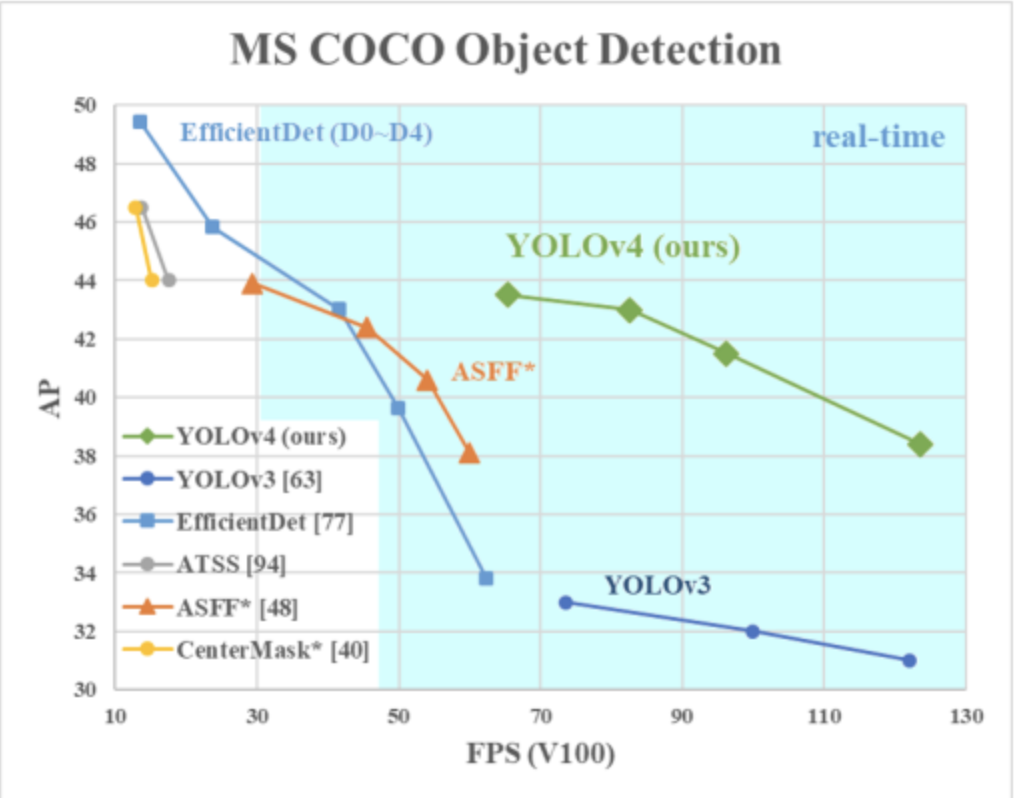
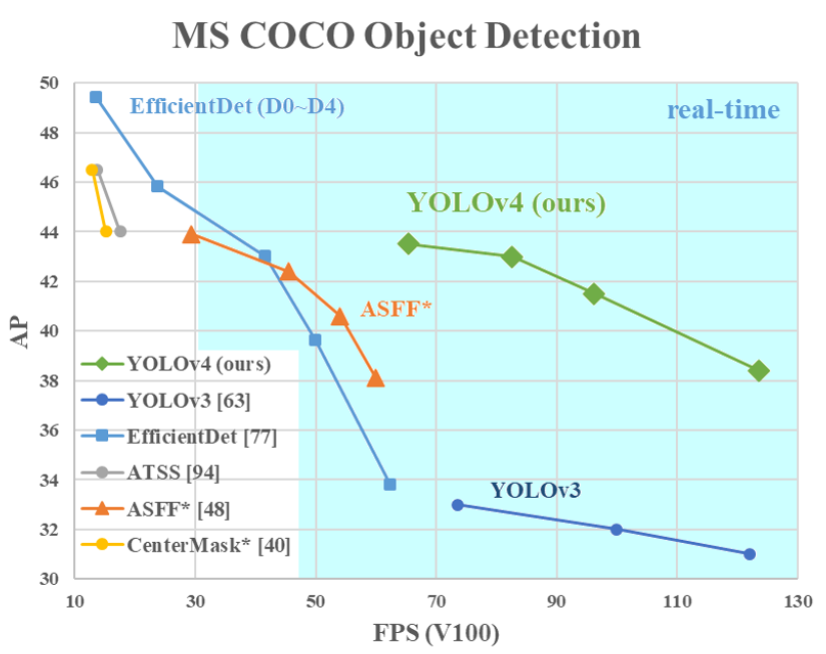
위의 표는 YOLO와 SOTA Detectors와의 비교
- EfficientDet과 비슷한 성능 + 2배 빠른 FPS
- YOLO v3에 비해서 AP는 10%, 그리고 FPS는 12% 향상
- CNN 기반 object detectors는 오직 Recommendation systems에서만 사용할 수 있었음.
- 최신 딥러닝 기반 모델들은 높은 정확도를 가짐. 하지만 실시간으로 작동하지 X 큰 mini-Batch학습을 위해 대량의 GPU가 필요하였음
🤜 이를 해결하기 위해 기존 GPU에서 real-time으로 동작하고, GPU 1개만으로 학습할 수 있는 YOLO v4를 제안함
🤜 Detector를 학습하는 동안, 최신의 BoF와 BoS 기법을 적용하여 효율적이고 학습에 도움을 주는 방법들을 제안함
🤜 YOLOv4의 가장 큰 특징은 YOLO 버전 시리즈의 문제점이었던 객체 검출 문제를 해결하고자 한 것임
2. Related Work
https://herbwood.tistory.com/24 tistory를 참고하면서 작성하였습니다.
2.1. Object detection models
a. Input
- Image
- Patches
- Image Pyramid
b. Backbone
- Input이 BackBbone network를 거치게 되면 semantic을 가지는 Feature map으로 변형되어짐.
- Detector가 GPU or CPU에서 동작하냐에 따라 구분가능.
b.1. GPU Platform

VGG16
: 3 x 3 Conv Filter 사용 + Network의 Depth를 크게 늘린 모델
ResNet50
: Residual Block을 통해 Network의 층 수를 늘린 늘린 모델
SpineNet
: NAS를 활용하여 localization & multi-scale feature에 유리하도록 설계된 scale-permuted 모델
EfficientNet-B0/B7
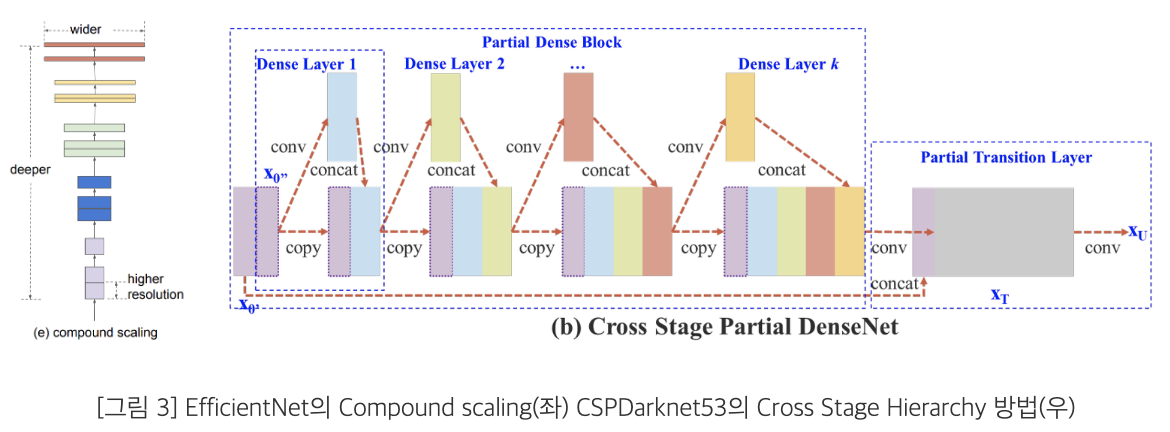
: Width, Depth, Resolution 3가지 Scaling Factor를 모두 고려하여 Compound Scaling을 AutoML을 통해 적은 연산량 및 높은 정확도를 갖도록 하는 모델
CSPResNeXt50
: ResNeXt-50 기반의 Layer의 Feature map을 분할 한 뒤 Cross-Stage Hierachy와 결합하여 연산량을 낮춘 모델
CSPDarknet53
: DenseNet 기반의 Layerdml Feature ma>을 분할한 뒤 Cross-Stage Hierachy와 결합하여 연산량을 낮춘 모델
b.2. CPU Platform
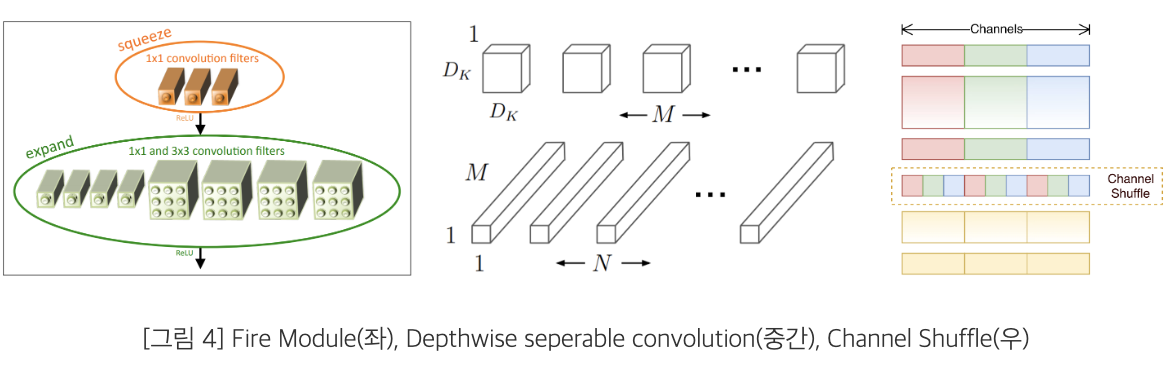
SquuezeNet
: squeeze layer, expand layer을 통해 1 x 1 Conv filter을 사용하여 정확도는 유지하되 Network의 Size를 줄인 모델
MobileNet
-Depthwise Separable Convolution
-Width multiplier
-Resolution multiplier
🤜 Network의 연산량 감소 및 속도 향상을 이룬 모델
ShuffleNet
-Pointwise Convolution을 통해 연산량을 줄임
-Channel Shuffle통한 Input과 Output Channel이 fully related하도록하여 표현력을 향상시킨 모델
c. Neck
- Backbone과 Head를 연결하는 부분이며 Feature map을 재구성하는 구간임.
c.1. Additional Blocks
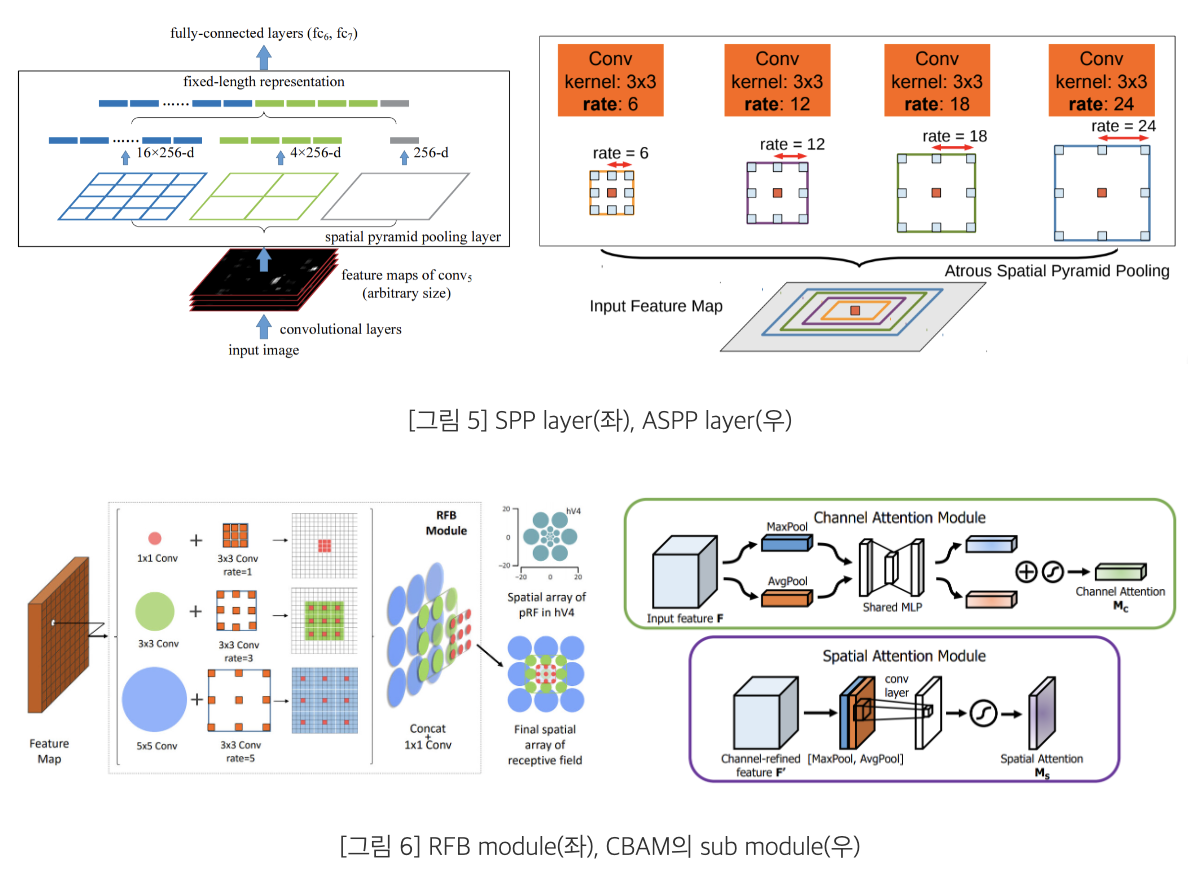
SPP
: Conv Layer의 마지막 Feature map을 고정된 크기의 Grid로 분할한 뒤 Average을 구한 다음 고정된 크기의 representation을 취함.
ASPP
: Spatial Pyramid Pooling 구조에서 확장 계수를 추가한 Astrous convolution 더해진 구조
RFB
: 경량화된 CNN모델에서 학습된 Feature를 강조하여, 빠른 속도 및 정확도에 기여한 구조
SAM
: Conv Feature을 refine한 뒤, 상대적으로 중요한 값을 강조하여 적은 연산량을 이뤄낸 attention 모델임.(BAM, CBAM)
c.2. Path-aggregation Blocks
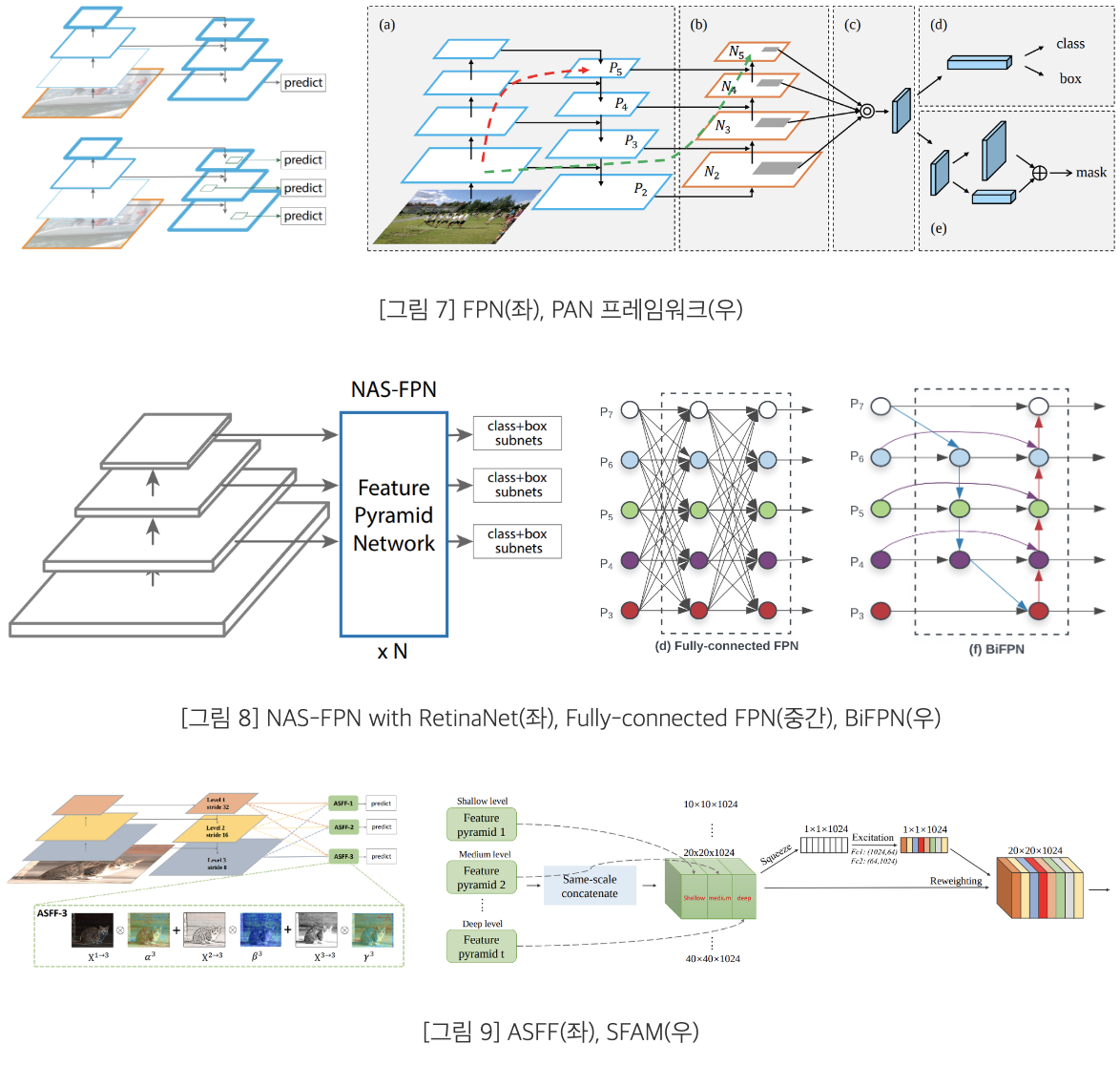
FPN
: Low-level Feature map & High-level Feature map의 특징을 top-down, bottom-up, lateral connection을 통해 Object Detection 성능 향상에 기여한 Network
PAN
: Bottom-up Path Augmentation을 통해 Low-level Feature의 정보를 High-level Feature에 전달함으로써 Localization 성능을 향상시킨 Network
NAS-FPN
: NAS를 통한 Feature Pyramid Network을 탐색하여 얻은 최적의 FPN 구조임
Fully-connected FPN
: 서로 다른 level의 Feature map 간의 정보를 완전 연결하여 통합하는 방식의 Feature Pyramid
BiFPN
: 같은 scale의 Feature map에 Edge를 추가하여 많은 Feature들을 융합할 수 있음
ASFF
SFAM
d. Head
- Head는 one-stage detector와 two-stage detector로 구분함.
d.1. One-stage detector
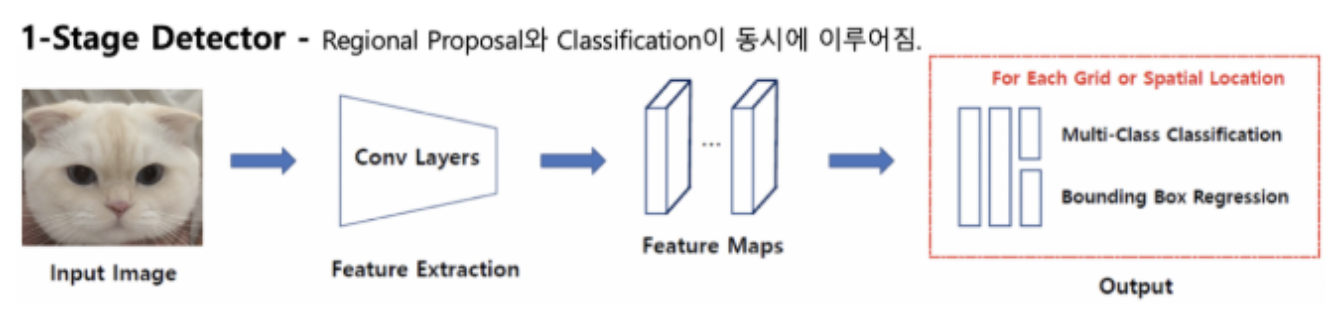
Regional Proposal이란?
- 물체가 있을만한 영역을 빠르게 찾는 알고리즘으로 object의 위치를 찾는 Localization 문제임.
ex) Selective Search, Edge Boxes
-
Regional proposal와 Classification이 동시에 이루어짐.
🤜 Classification & Localization 문제를 동시에 해결하는 방법임. -
비교적 빠르지만 정확도가 낮음
- Anchor-based detector와 anchor-free detector로 나눠짐
d.1.1. Anchor-based One-stage detector
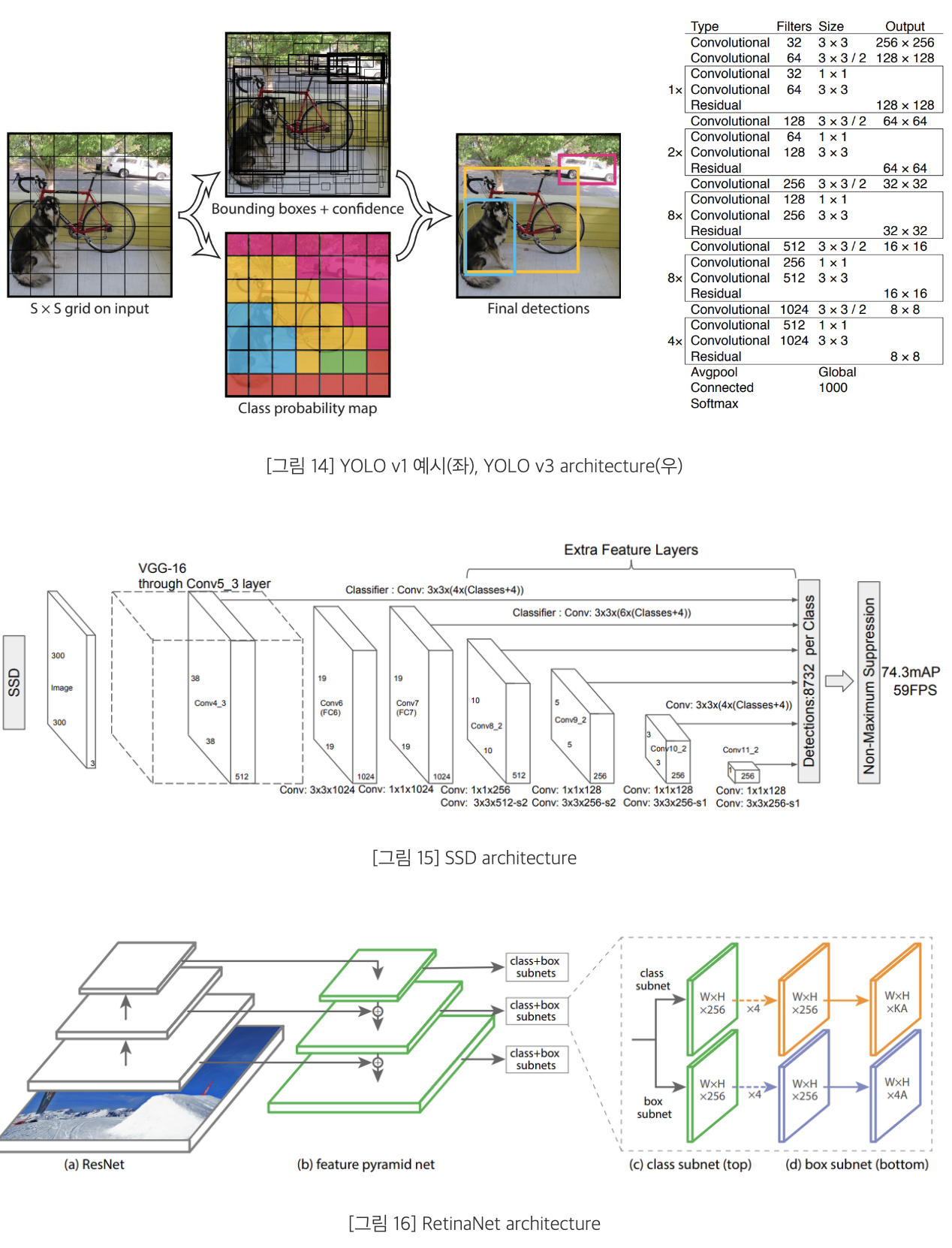
YOLO
: 통합된 Network를 기반으로 Classificationrhk Localization을 동시에 수행하여 객체 탐지 속도를 높인 모델
SSD
: Single Shot multibox Detector로, Multi-scale Feature map을 활용했고 다양한 scale & aspect ratio을 가진 Default box를 통해 정확도와 속도를 높인 모델
RetinaNet
: Focal Loss를 도입하여 Object Detection Task에서 발생하는 Class Imbalance 문제를 완화한 모델
YOLO v3
: Backbone으로 DarkNet-53을 활용하여 Multi-scale Feature map을 활용하여 객체 탐지 속도를 높인 모델
d.1.2. Anchor-free One-stage detector
CorneNet
CenterNet
MatrixNet
FCOS
d.2. Two-stage detector
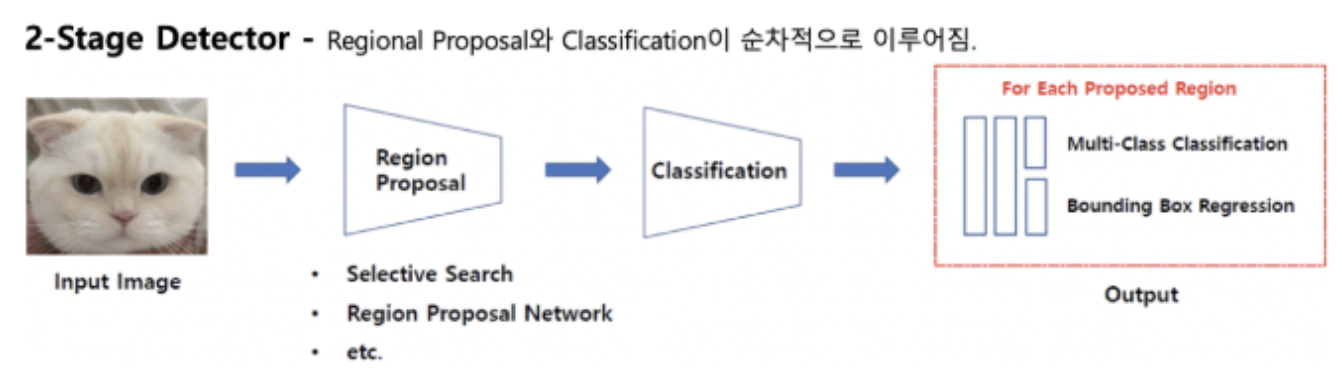
- Regional Proposal와 Classification이 순차적으로 이루어짐
🤜 Classification & Localization 문제를 순차적으로 해결함
- 비교적 느리지만 정확도가 높음.

-
위의 그림은 동작과정으로
(1) Selective search Region Proposal Network 알고리즘을 통해 물체가 있을법한 영역을 우선 뽑는다.
(2) 이 영역을 RoI(Region of Interest)라고 하고, 각 영역들을 Conv Network를 통해 Classification, Localization을 수행함 -
Anchor-based detector와 anchor-free detector로 나눠짐
d.2.1. Anchor-based Two-stage detector
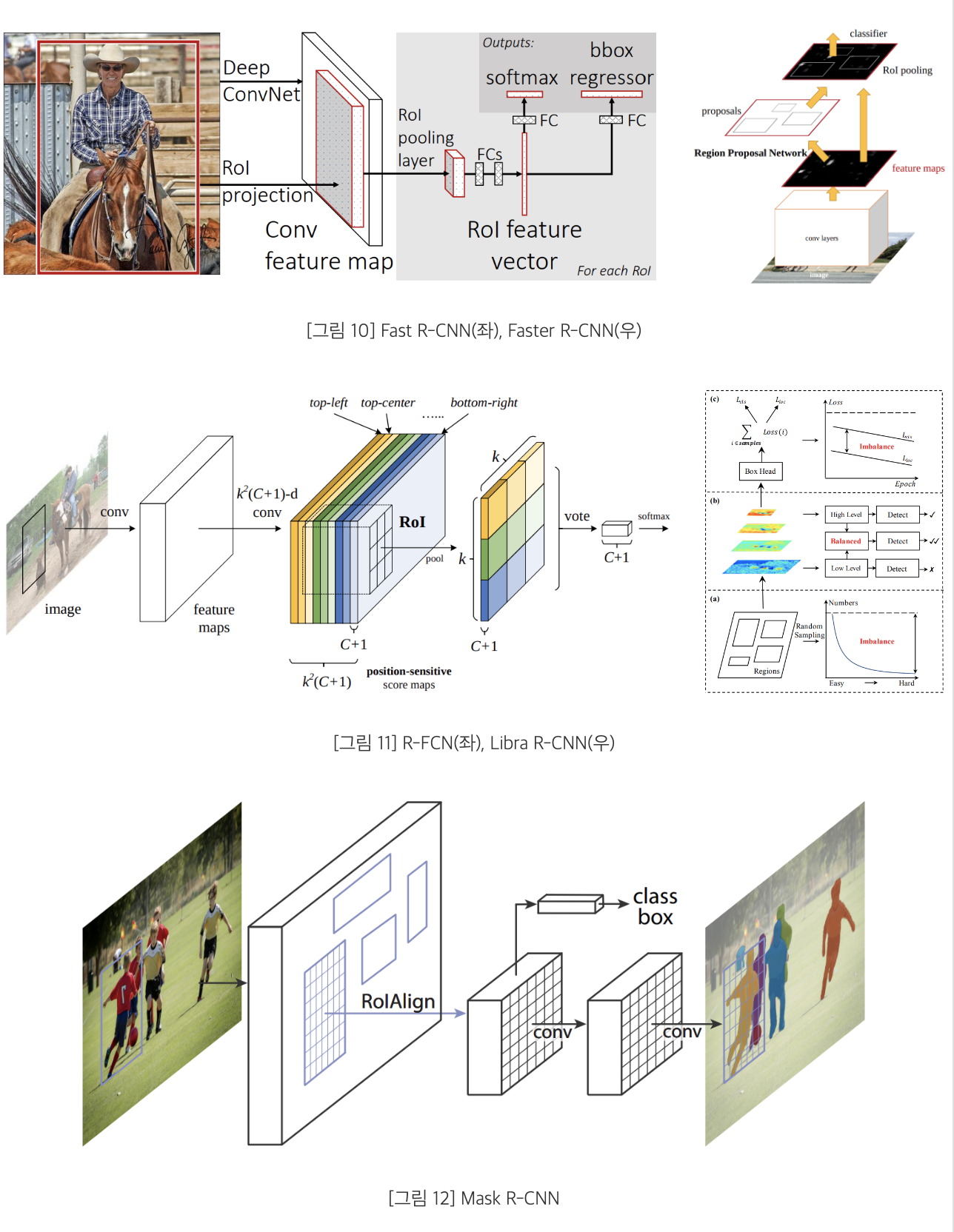
Fast R-CNN
: Image를 CNN에 입력하여 ROI를 RoI pooling을 통해 고정된 크기의 feature vector를 FC Layer에 전달하여 R-CNN에 비해 학습 및 객체탐지 속도를 높인 모델
Faster R-CNN
: RPN을 추가하여 모델의 작동 과정에서 발생하는 병목 현상을 최소화하고 Fast R-CNn에 비해 학습 및 객체탐지 속도를 높인 모델
R-FCN
: RoI끼리 연산을 공유하고 Position sensitive score map과 ROI pooling을 도입하여 Translation invariance 딜레마 문제를 해결한 모델
Mask R-CNN
: RoI pooling을 통해 얻은 feature와 RoI가 어긋나는 것을 해결하기 위해 RoI Align 방법을 도입한 Instance Segmentation 모델
Libra R-CNN
: IoU Based sampling / Balanced Feature Pyramid / Balanced L1 Loss를 도입한 모델
d.2.2. Anchor-free Two-stage detector

RepPoints
: Deformable Convolution을 활용하여 객체의 둘레에 점을 찍어 얻은 reppoints를 기반으로 anchor 없이 Object Detection을 수행하는 모델
2.2.BoF (Bag of freebies)
- Object Detector는 오프라인으로 학습되고 연구자들은 이 장점을 살려서, inference 비용 및 시간을 늘리지 않으면서 높은 정확도를 얻을 수 있도록 학습시키는 방법을 연구함.
🤜 즉, inference에는 비용을 늘리지 않고 정확도를 높일 수 있는 더 나은 방법들을 개발하는 방법을 BoF라고 함.

BoF는 위의 같이 3가지로 분류됨.
a. Data Augmentation
- 목적은 이미지의 변동성을 높이고 설계된 모델이 다른 환경에서 얻은 이미지에 보다 Robust하게 하도록 하게 함.
(1) photometric distortion
(2) Simulating object occlusion
: 객체가 서로 겹치는 상황을 가정하고 이러한 상황에 모델이 잘 대처하게끔 하기 위해 사용되는 방법임
Image Level
-Random erase
-CutOut
-Hide-and-seek
-Grid mask
Feature map Level
-Dropout
-DropConnect
-DropBlock
: Feature map에서 연속하는 영역의 activation을 0으로 만들고 network에 regularization을 주는 방법 / 아래의 그림이 DropBlock임.

Using Multiple Images
: 다수의 Image를 함께 사용하여 Augmentation 하는 방법
-Mixup
-CutMix
: 이미지 내 특정 patch 영역에 Label이 다른 학습 이미지를 잘라 붙이고 학습 pixel을 사용하여 regularization 효과를 유지하는 Augmentation 방법
GAN
-Stylized-MageNet(SIN)
b. Semantic Distribution Bias
(1) Class Imbalance
: Object Detection시 positive / negative sample 사이에 클라스 불균형 문제가 발생함. 이를 해결하기 위해 Two-stage와 One-stage로 해결책 제시.
- Two-stage
- One-stage
(2) One-hot hard representation
- Label smoothing
: label을 0 or 1이 아닌 smooth하게 부여함으로써 모델의 regularization & 일반화 능력을 향상시킴
- Label refinement network
c. Bounding Box Regression
(1) Anchor-based method
(2) IoU-based method
- GIoU (Generalized IoU)
- DIoU (Distance IoU)
- CIoU (Complete IoU)
: DIoU Loss에 두 객체 사이으이 aspect ratio를 고려하고 penalty term을 추가하여 객체가 겹치지 않은 경우 더 빠른 수렴을 가능하도록 한 Loss Function
2.3. BoS (Bag of specials)
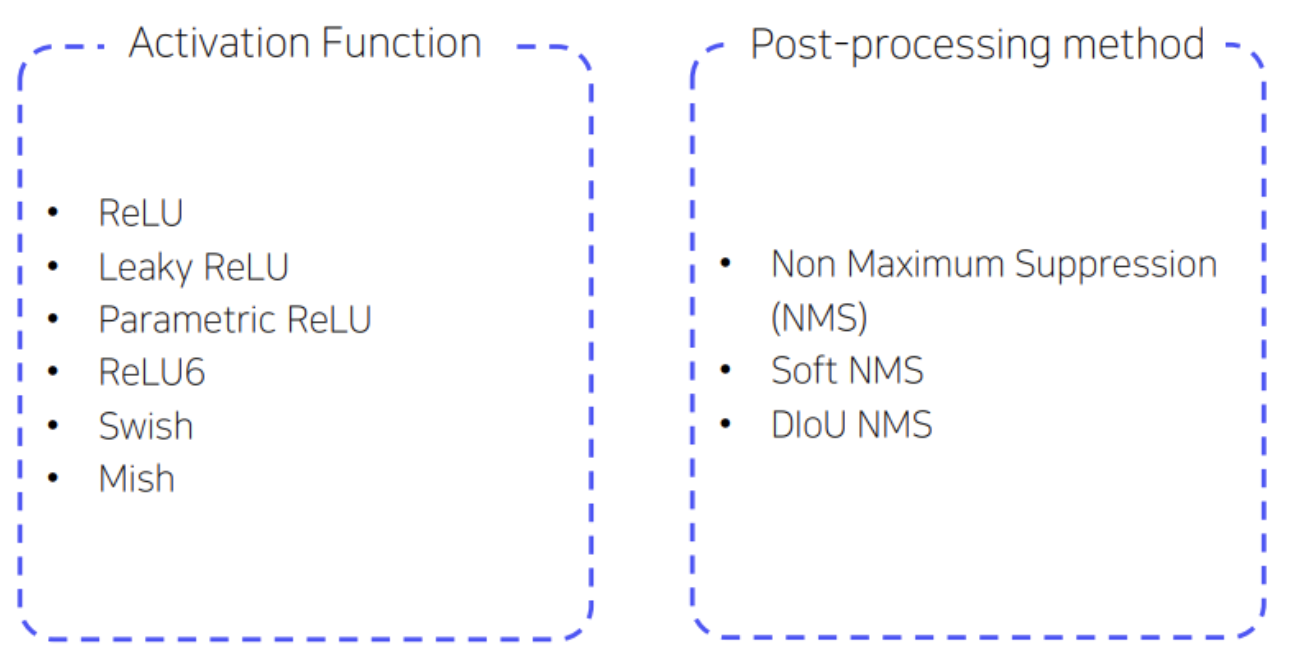
- BoS는 inference 비용을 조금 높이고 정확도를 향상시키는 방법으로 아래와 같이 5가지로 분류할 수 있음

a. Enhancement of Receptive field
- backbone network에서 얻은 feature map에 대한 receptive field를 키우는 방법임
-SPP
-ASPP
-RFB
b. Attention Module
- Channel-wise, Point-wise로 나눠지고, 이는 각각 SE module, SAM에 해당함
-SE(Squeeze-and-Excitation)
-SAM
c. Feature Integration
- Feature map을 통합하기 위한 연구
-SFAM
-ASFF
-BiFPN
d. Activation Function
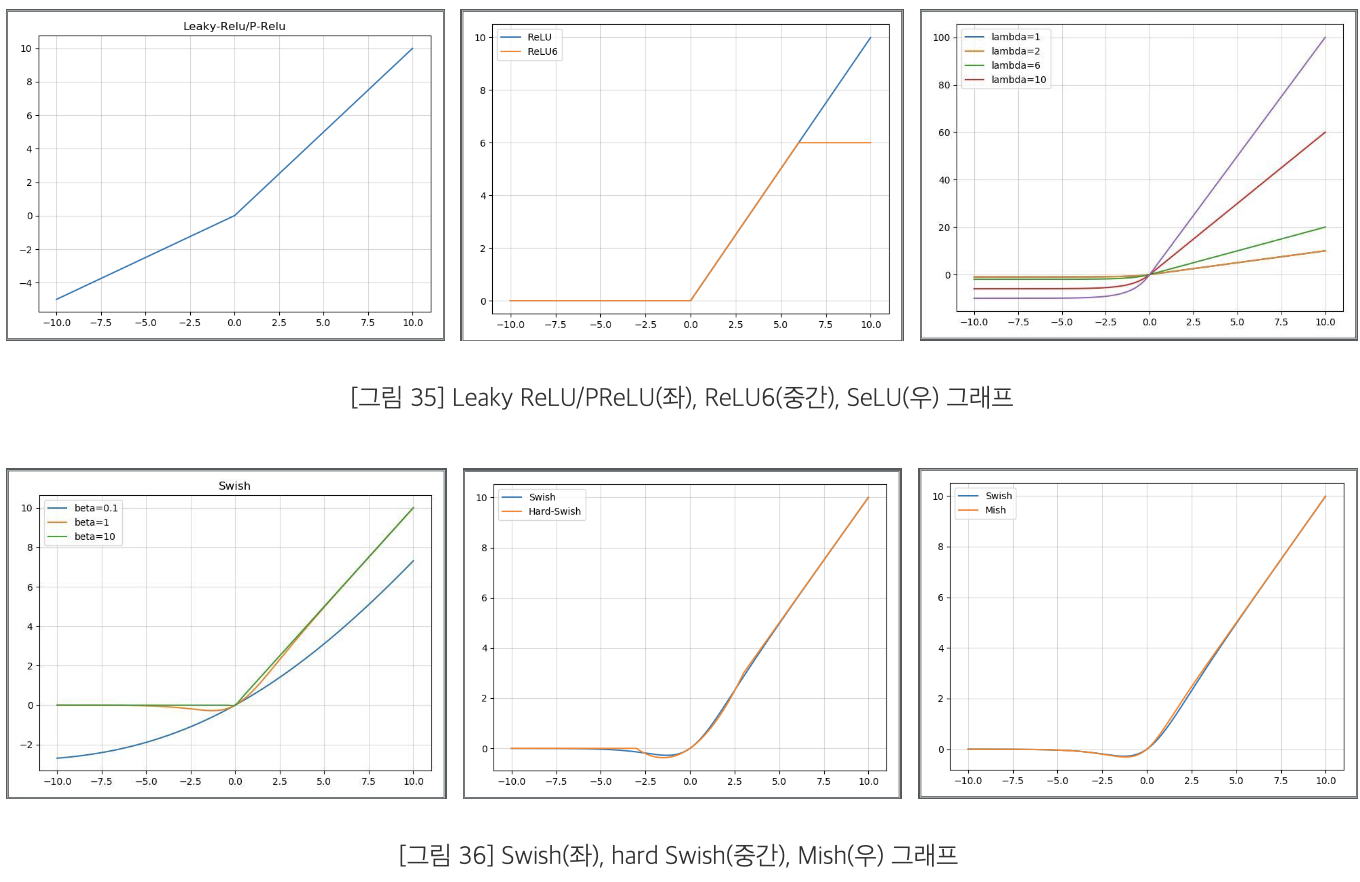
- Leaky ReLU
- PReLU
- ReLU6
- SELU
- Swish
- hard-Swish
- Mish
: upper bound가 없고 캡핑으로 인한 포화가 발생 X, 음수를 허용하여 gradient가 잘 흐르도록 설계된 activation function을 의미
e. Post-processing method
: 같은 객체를 예측하는 불필요한 Bounding box를 제거하는 NMS 방법
- Greedy NMS
- Soft NMS
- DIoU NMS
: 기존의 NMS 임계치에 DIoU penalty term을 추가하여 겹친 객체에 대한 탐지 성능을 향상시킨 NMS 방법임
3. Metholdology
3.1. Selection of architecture

- 작은 Object들을 검출하기 위해서 Input 해상도를 크게 사용함
- 기존 224, 256 해상도 -> 512 사용
- Reveptive filed를 키우기 위해 Layer 수를 늘리고 Parameters를 늘렸음. -> 정확도를 높임
🤜 Architecture의 변경을 통해 속도문제를 해결함
- FPN & PAN 기술을 도입
- CSP 기반의 backbone과 SPP 등의 새로운 network 구조를 도입하여 성능을 향상시킴
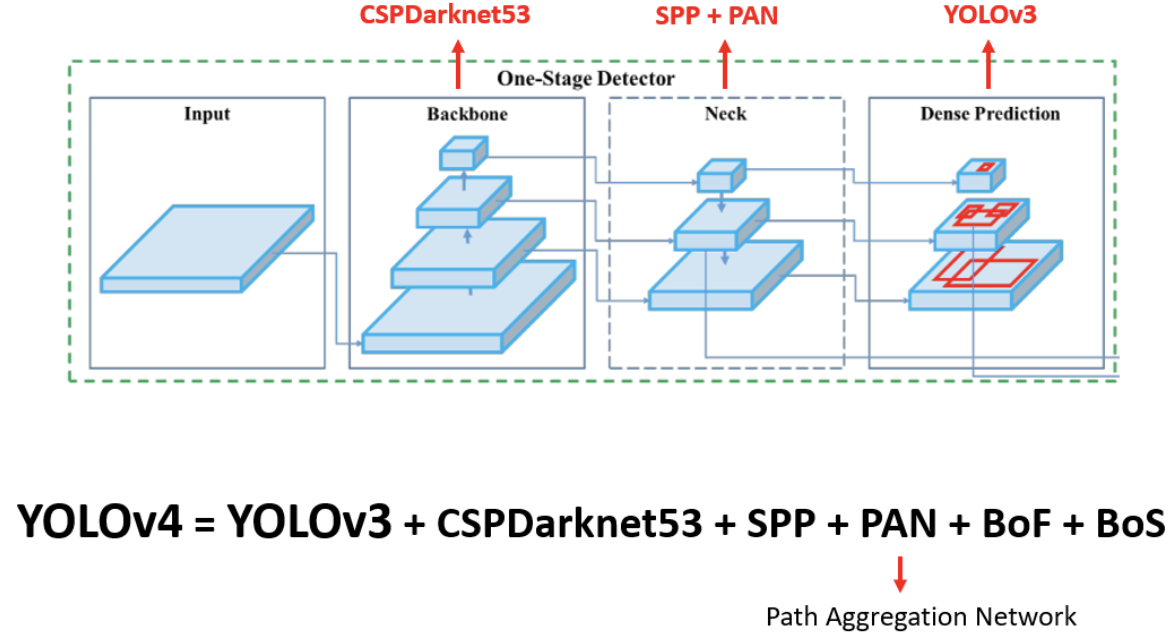
🏆 YOLOv4 🏆
= YOLOv3 + CSPDarkNet53 + SPP + PAN + Bof + BoS
3.2. Additional improvements
- 단일 GPU 훈련에 적합하도록 하기 위한 설계
- Mosaic & SAT(Self-Adversarial Training) 새롭고 독자적인 Data Augmentation 기법 제시함
- Genetic Algorithms을 적용하여 최적의 Hyper-parameters 선택
- 기존의 기법들을 detector에 적합하도록 수정함
a. Mosaic

- 네 개의 학습 이미지를 섞는 Data Augmentation 방법
- 이미지를 섞음으로써 객체가 인식되는 일반적인 맥락에서 벗어난 관점을 Network에 제공함
b. SAT (Self-Adversarial Training)
- Forward, Backward 2번의 stage를 걸쳐 수행되는 Data Augmentation 방법
🤜 adversarial perturbation을 활용하여 눈에 보이지 않는 오작동을 유도하는 Sample들을 활용해 Robust한 모델로 만들 수 있음.
- 1-Stage에는 원본 이미지를 변형시키고 이미지 내에 객체가 없어보이게 하는 adversarial perturbation을 추가함.
- 2 stage에는 변형된 이미지를 사용해서 학습함.
c. 기존의 기법들을 수정

- 위의 그림은 CmBN(Cross Mini-Batch Normalization)으로 CBN을 변형시킨 버전임.
- 하나의 Batch에서 mini-Batch Batch Norm을 계산하는 것이 아닌 Batch-size가 큰 것과 같은 효과를 부여함.

- SAM
: Spatial-Wise Attention -> Point-Wise Attention으로 변형
- PAN
: shortcut connection -> concatenation으로 대체
3.3. YOLO v4
지금까지 소개한 방법 중 YOLO v4의 Best Combination은 다음과 같음.
Backbone
- CSPDarkNet-53
Neck
- SPP / PAN
Head
- YOLO v3
Bag of Freebies (BoF) for backbone
- CutMix & Mosaic data augmentation
- Dropblock Regularization
- Class label smoothing
Bag of Specials (BoS) for backbone
- Cross-stage partial connections (CSP)
- Mish activation
- Multi-input weighted residual connections (MiWRC)
Bag of Freebies(BoF) for detector
- CmBN
- CloU-Loss
- Mosaic Data Augmentation
- DropBlock Regularization
- Eliminate Grid Sensivity
- Self-Adversarial Training
- Consine Annealing Scheduler
- Using multiple anchors for a single ground truth
- Random training shapes
- Optimal Hyperparameters
Bag of Specials(BoS) for detector
- SPP-block
- SAM- block
- Mish activation
- PAN path- Aggregation block
- DloU - NMS
4. Experiments
4.1. Influence of different features of Classifier training
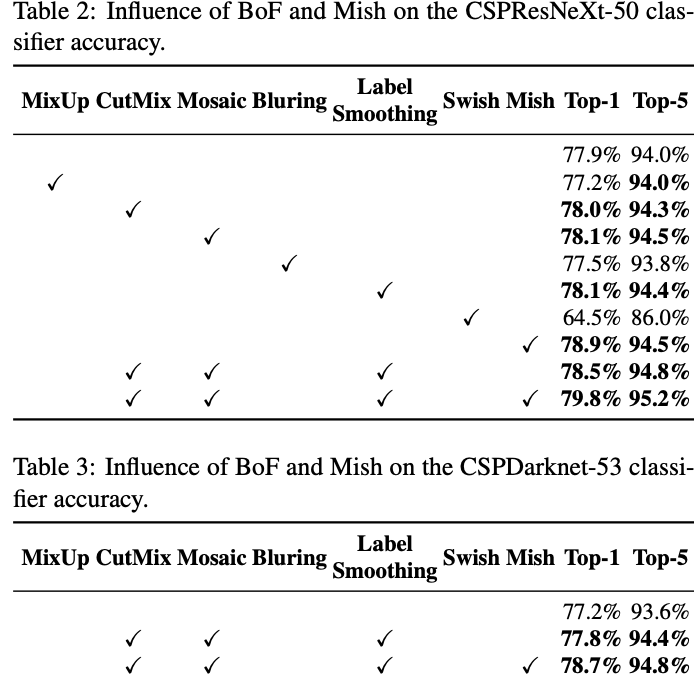
- Classifier 학습 시 서로 다른 Features의 영향에 대한 실험
- Cutmix, Mosaic, Label Smoothing, Swish Mish와 같은 Features를 사용할 때 성능이 향상된 것을 확인할 수 있음
4.2. Influence of different features on Detector training
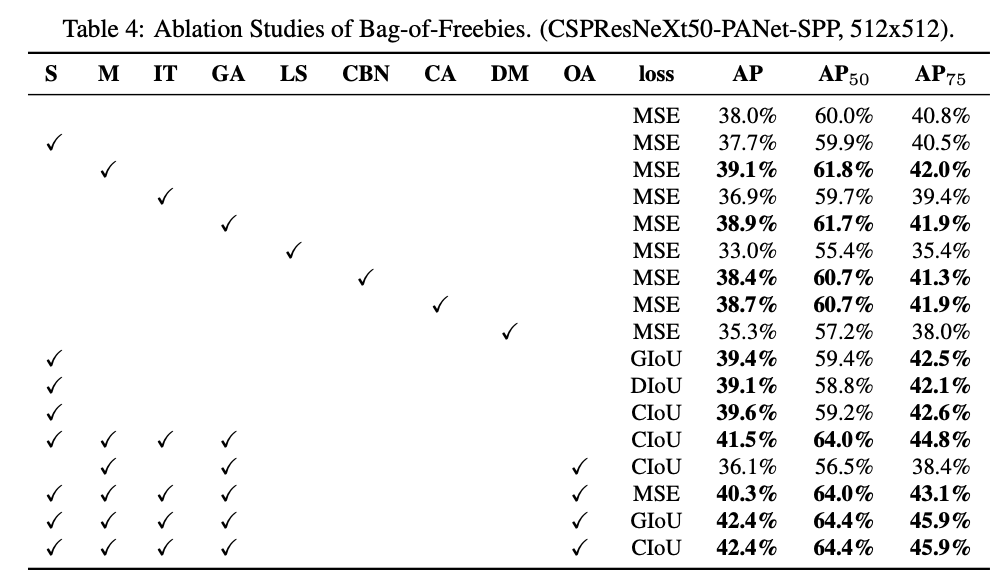
- Detector 학습 시 서로 다른 Features의 영향에 대한 실험
- CIOU 사용하는 것이 성능 Good
- IoU 기반의 Loss를 적용하는 것이 성능 Good
- QA 적용하는 것이 성능 Good
4.3. Influece of different backbones and pre-traied weighings on Detector training
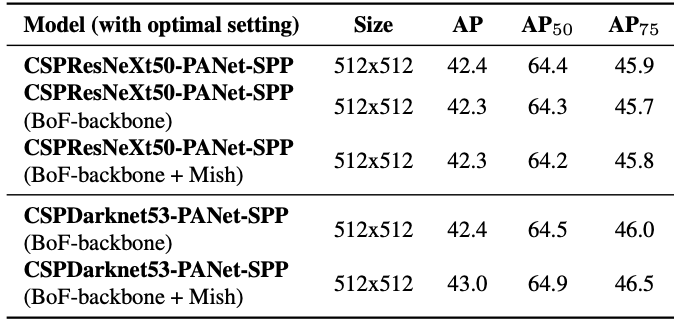
- Detector 학습 시 서로 다른 backbone과 pre-trained weigh의 영향에 대한 실험
- SAM 사용했을 때 성능 Good
4.4. Influence of different mini-batch size on Detector training
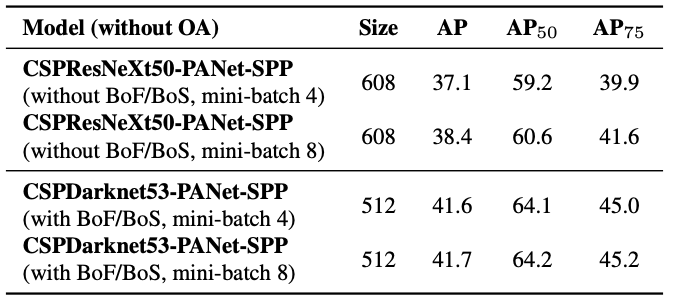
- Detector 학습 시 mini-batch 크기에 따른 영향에 대한 실험
- 가장 우수한 Classification 정확도를 보이는 Backbone model이 Detector의 정확도에서도 가장 우수한 것은 아님.
- CSPDarknet53 model이 Detector에 보다 더 적합함
5. Results

- 다른 Object Detectors의 SOTA 모델과 비교해봤을 때 YOLO v4는 속도와 정확도 측면에서 가장 빠르고 정확함.
- MS COCO DataSet에서 43.5%라는 AP 값을 보이며, 그 당시 SOTA 달성.
- 기존보다 낮은 성능의 GPU에서도 불구하고 빠른 학습 및 정확도 Good 👍
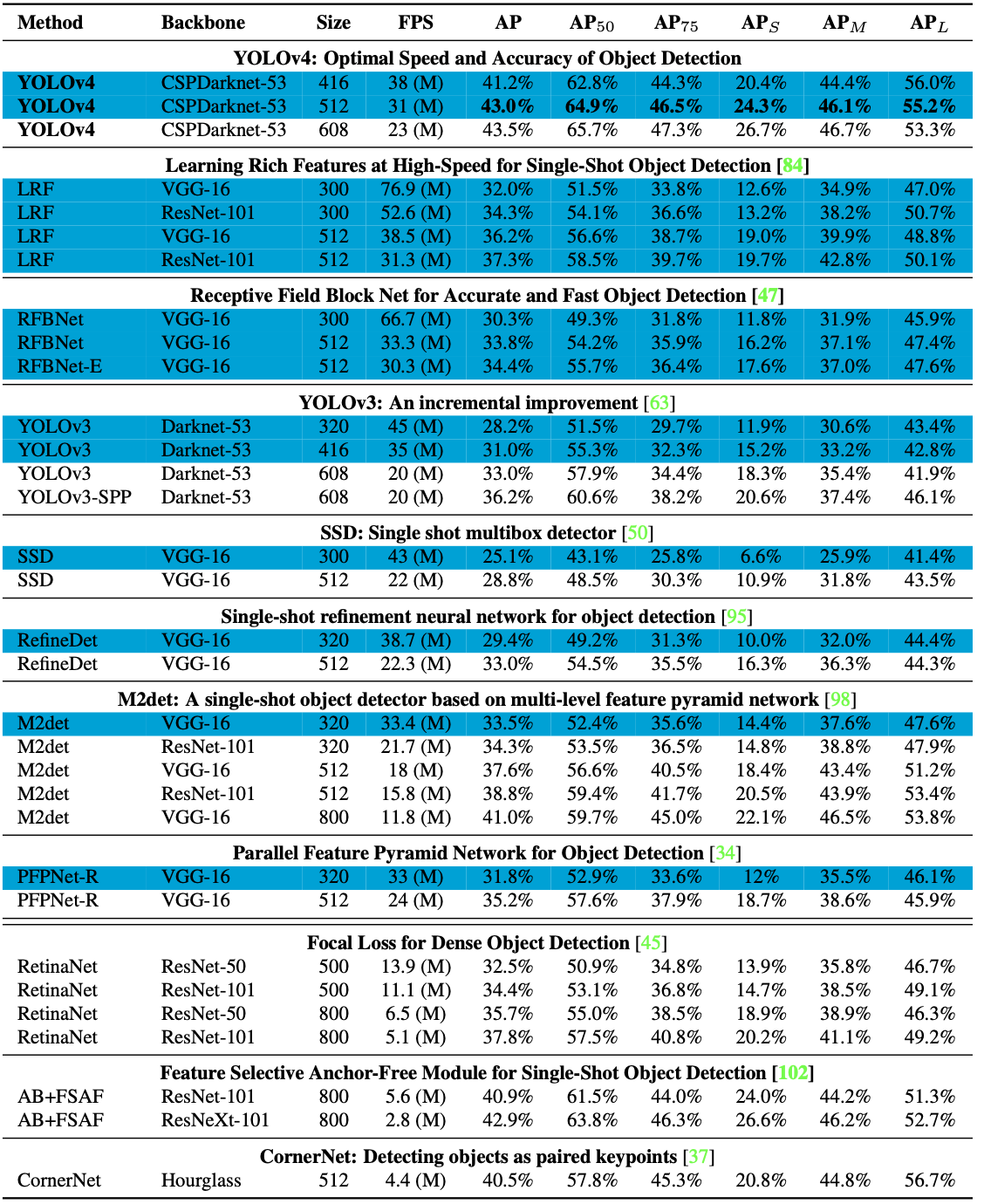
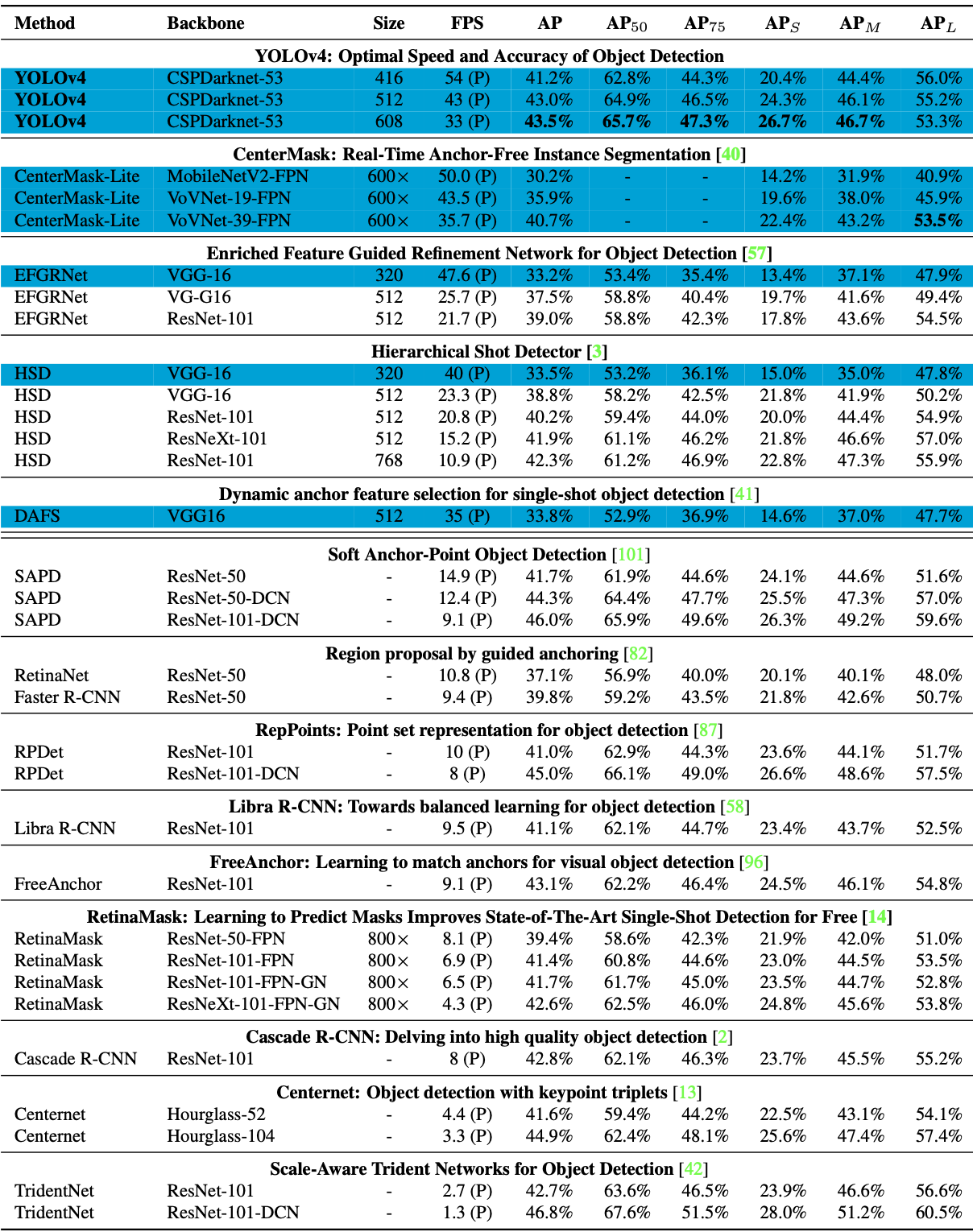
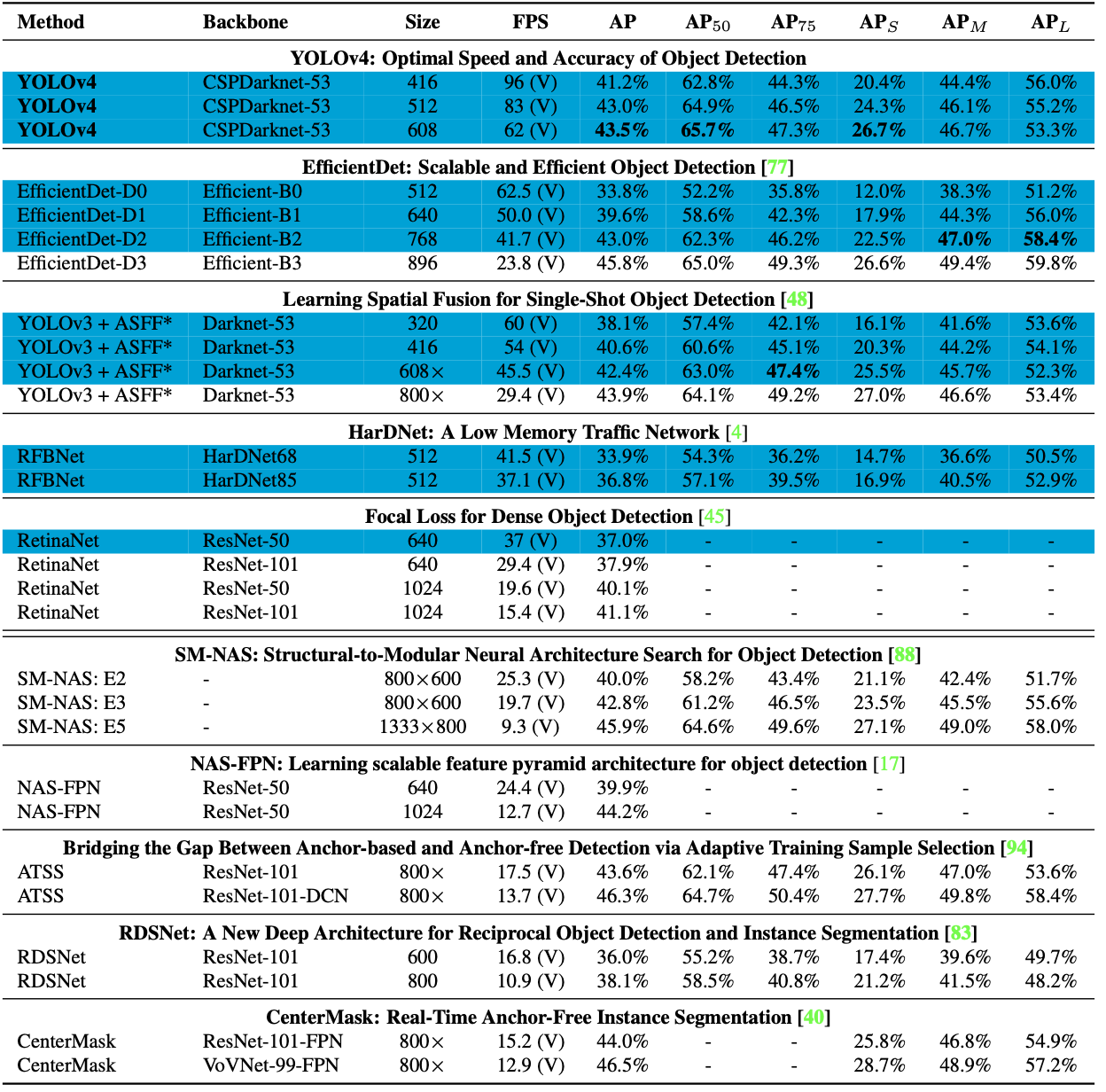
- 위의 그림은 GPU에 따른 다른 Object Detectors와의 결과 비교표임.
6. Conclusions
- YOLO v4 = YOLOv3 + CSPDarkNet53 + SPP + PAN + Bof + BoS으로 구성됨
- GPU 1개만으로 real-time으로 동작하고, BoF와 BoS 기법을 적용하여 객체 검출 문제를 해결하였고, 이는 광범위하게 적용 가능함
- One-stage Anchor-based Detectors의 실행 가능성 입증
- 향후 연구 개발을 위한 best-practice로 사용 할 수 있음
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 이전의 Object Detection 모델들의 한계점을 보완하여 높은 정확도를 유지하면서 더욱 빠른 속도를 달성하고자 함
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- Architecture의 변경을 통한 속도 문제 해결
: FPN & PAN 기술 도입 + CSPDarknet53(backbone) + SPP+PAN 등의 새로운 network구조를 도입하여 성능 향상
- BoF (효과적이고 효율적인 학습을 위한 기법들)
Data Augmentation, Regularization Method, Normalization, Object Function
- BoS (정확도 향상을 위한 추가 모듈 기법 및 후처리 방법)
Enlarging Receptive Field / Attention Mechanism / Feature Integration
- 새로운 Data Augmentation 기술
Mixup, CutMix, Mosaic
- 어느 프로젝트에 적용할 수 있는가?
- Object Detection
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- YOLO
- YOLO v2
- YOLO v3
- YOLO v5
- Faster R-CNN
- 느낀점은?
- 이 논문은 Object Detection 내용보다도 모델의 성능 개선, 네트워크 구조 수정, Loss Function, Augmentation, NMS 등 다양한 방법을 통해 성능 향상을 할 수 있다는 것을 알 수 있었음.
- 처음 보는 알고리즘들과 기술들이 너무 너무 너무 많이 나와서 사실 몇개는 찾아보다가 포기했다... 다음에 시간되면 정리하겠음..! 하지만 딥러닝을 바라보는 시야가 넓어져서 Good이었음!
📚 References
논문
유튜브
블로그
