Paper Review #6 - DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
MultimodalKnowledgeGraph
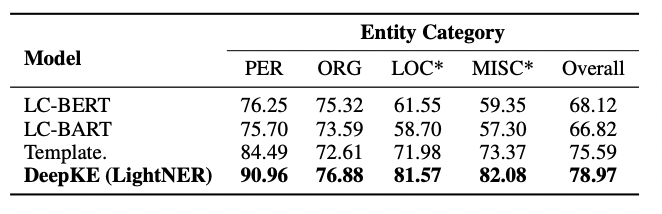
Zhang, Ningyu, et al., "DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population", arXiv preprint arXiv:2201.03335, 2022
수 많은 데이터 속에서 필요한 정보만을 추출하는 IE(Information Extraction) 기술이 발전을 거듭하고 있다. IE 기술의 발전에 따라 대규모의 Knowledge Base 역시 구축 되고 있는데, 지식 베이스는 현실 세게에서 지식 집약적인 업무에 많은 도움을 준다. 따라서 KBP(Knowledge Base Population) 또한 각광을 받고 있는 분야 중 하나인데, KBP라 함은 텍스트로부터 지식을 추출해 KB의 손실된 부분을 완성하는 작업이다. 원문에서 entity와 관계를 추출하고, 이것들을 KB에 연결시켜주는 IE 작업은 여기서도 용이하게 쓰이고 있다.
Named Entity Recognition(NER), OpenNRE(RE), Stanford OpenIE(IE), RESIN(Event Extraction)와 같은 IE toolkit들이 개발 되었지만 아직은 실제 프로그램에 적용하는데엔 한계가 있다.
우선 이들은 다양한 IE 작업이 가능하지만, 기존의 툴킷들은 단지 하나의 작업만 처리할 수 있다. 또한 비록 기존의 IE 모델들이 좋은 성과를 냈을지라도 그들의 성능은 텍스트 뿐만 아닌 여러 타입의 데이터를 다루는 실제 시나리오에 적용한다면 성능이 기하급수적으로 떨어진다. 따라서 다수의 테스크를 처리하는 Knowledge Extraction tooklkit이 필요하다.
이 논문에선 DeepKE란 Knowledge Extraction Toolkit을 제안하는데, 이는 적은 자원, 문서 수준, 그리고 멀티모달 환경에서의 지식 추출 작업(NER, RE, AE)을 가능하게 한다.
Key features
low resource few-shot, document-level, multimodal 환경에서의 다양한 IE task 지원으로, 시나리오에의 유연한 응용이 가능하다. DeepKE는 NER, RE, AE의 세가지 IE task를 지원하고 있다.
NER(Named entity Recognition)
NER은 엔티티가 언급하는 것을 선택하고, 그것들을 사전 정의 된 일반적인 텍스트로 주어진 의미적 카테고리로 분류한다.
예를 들어
"It was one o'clock when we left Lauriston Gardens, and Sherlock Holmes led me meet Gregson from Scotland Yard."
라는 문장이 주어졌을때, NER 모델은
"Lauriston Gardens"가 location이고, "Sherlock Holmes"와 "Gregson"이 사람, "Scotland Yard"가 집단 이란 것을 예측 할 수 있다.
DeepKE는 NER 작업을 위해 사전 정의된 언어 모델을 사용해 문장을 인코딩 하고, 예측을 생성한다. 또한 NER을 few-shot 환경과 멀티모달 환경에서 구현하였다.RE(Relation Extraction)
Relation Extraction은 구조화되지 않은 텍스트의 entity 쌍으로부터 의미적인 관계를 예측하는 작업이다. DeepKE는 표준 감독 RE 작업을 위해 CNN, RNN, GCN, Transformer, BERT와 같은 다양한 모델을 채택하였다. 또한 few-shot과 문서 수준의 RE를 제공하고 있으며, 저자원 RE를 위해 prompt-tuning 기반의 few-shot RE 방법인 KnowPrompt를 구현하였다. 이때 few-shot RE는 사용자들이 몇개의 라벨링된 인스턴스만으로도 relation을 추출할 수 있게 해주기 때문에 현실에 적용하였을때 효과적인 모델이다. 문서 수준 RE의 경우, 한 문서에서 문장 내 관계 삼중항을 추출하기 위한 모델인 DocuNET을 구현하였다. 하지만 문서 수준 RE는 문서의 여러 문장 내 또는 여러 문장에 걸친 정보를 통합해야하는 까다로운 작업을 포함한다. 또한 RE는 멀티모달 환경에서도 구현되었다.AE(Attribute Extraction)
AE는 KBP에서의 필수적인 작업이다. 문장, entity, 쿼리된 attribute mention들이 주어지면 AE는 그에 상응하는 attribute의 타입을 추론한다. 예를 들어
"Liang Zhuge, whose courtesy strategist, litterateur and inventor in the Three Kingdoms period."라는 문장이 주어졌을 때, Liang Zhuge 라는 entity와 attrubute mention인 Three kingdoms period로 부터 이에 상응하는 attribute type인 Dynasty를 예측할 수 있다. DeepKE는 AE 작업을 위해 CNN, RNN, Capsule, GCN, Transformer, BERT를 채택하였다.
Architecture
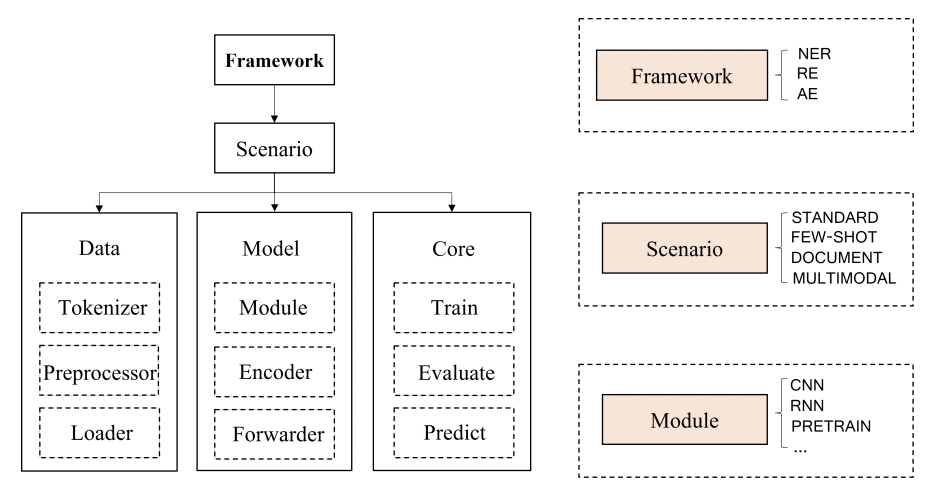
DeepKE는 데이터, 모델, 핵심 요소와 관련한 다양한 task에 모두 같은 프레임워크를 사용한다. 또한 자동화된 hyper-parameter 튜닝과 도커로 편리한 트레이닝과 평가를 제공하며 IE에 사전훈련된 모델을 사용한다.
Data Module
DeepKE는 영어와 중국어 기반 모델이기 때문에 이 두 언어로 토크나이징이 가능한 모델을 사용하였다. 이미지의 경우 글로벌 이미지와 로컬 visual object는 멀티모달 세팅에서의 시각적 정보로 사용이 가능하도록 전처리된다
토크나이저와 전처리기를 통해 데이터셋으로 부터 토큰과 이미지 패치를 얻을 수 있다.Model Module
모델 모듈은 세가지의 핵심 작업을 위해 활용되는 main neural network를 포함하고 있다. CNN, RNN, Transformer 등의 다양한 neural network를 포함하고 있으며 이들은 텍스트를 해당 작업을 위한 특정한 임베딩으로 인코딩 하는 모델을 구축하는데 활용된다. 표준 RE를 위해 BERT, few-shot NER을 위해 BART를 사용하는 것과 같이, 다양한 시나리오에 적용하기 위한 구분된 환경에서의 다양한 구조를 사용한다.
다양한 neural model을 통합하기 위한 Basic model로서 통합된 model loader과 saver를 사용한다.Core Module
Core module엔 train, validation, prediction 메소드가 포함이 되어있다. Train 메소드의 경우 유저가 파라미터(model, data, epoch, optimizer, loss function 등)을 입력할 수 있고, validation을 통해 evaluation이 가능하다. 또한 사용자는 predict 메소드에서 prediction을 위한 configuration을 변경해 결과를 얻을 수 있다.Framework Module
프레임워크 모듈은 세개의 구성 요소(Data module, model module, core module)과 다양한 시나리오들을 통합하는 역할을 한다. 프레임워크 모듈은 데이터 프로세싱, 모델 구축과 모델 구현의 다양한 기능을 포함하고 있으며 사용자는 .yaml 파일의 수정을 통해 모든 하이퍼파라미터의 조절이 가능하다. 자동화 된 하이퍼파라미터 튜닝을 제공한다.
Settings
-
Single sentences
데이터셋 내의 모든 instance들은 단 하나의 문장만을 포함한다. single sentence의 NER, RE, AR 작업을 위한 데이터셋은 모두 entity mention, entity 카테고리, entity offset, realtion type, attribute 과 같은 특정한 정보로 주석이 달려있다.
-
Low-resource
실제 상황에선 라벨링된 데이터가 딥러닝 모델이 정확한 예측을 수행할만큼 충분히 제공되지 않기 때문에 NER과 RE 작업시 low-resuorce few-shot이 요구된다. DeepKE는 도메인 내부 또는 범도메인적인 NER을 위해 prompt-guided attention이 있는 generative framework를 제공한다. 또한 few-shot RE 작업을 위해 synergistic optimization이 있는 knowledge-informed prompt tuning 역시 제공한다.
-
Document-level
두 entity 사이의 관계는 한개의 문장 뿐만이 아닌, 전체 문서의 각기 다른 문장 사이에서도 나타난다. DeepKE는 문서로부터 문장 내 관계를 추출하여 전역/광역적이니 정보를 포착하기 위한 entity level relation matrix를 예측하는데 사용한다.
-
Multimodal
텍스트와 관련된 이미지 신호는 context knowledge를 향상시키고 복잡한 시나리오부터 지식을 추출하는데 도움이 된다. DeepKE는 트랜스포머 기반 multimodal entity와 relation 추출 방법인 IFAformer를 제안하였는데, IFAformer는 Multimodal NER과 RE 작업을 위한 prefix 기반 attention을 사용한다. IFAformer의 트랜스포머에서 multi-head attention의 key와 value에 있는 textual, visual feature들을 동시에 통합하여 텍스트와 관련된 이미지에서 text-object 간 multimodal feature를 정렬할 수 있다.
IFAformer의 구조는 이와 같다.
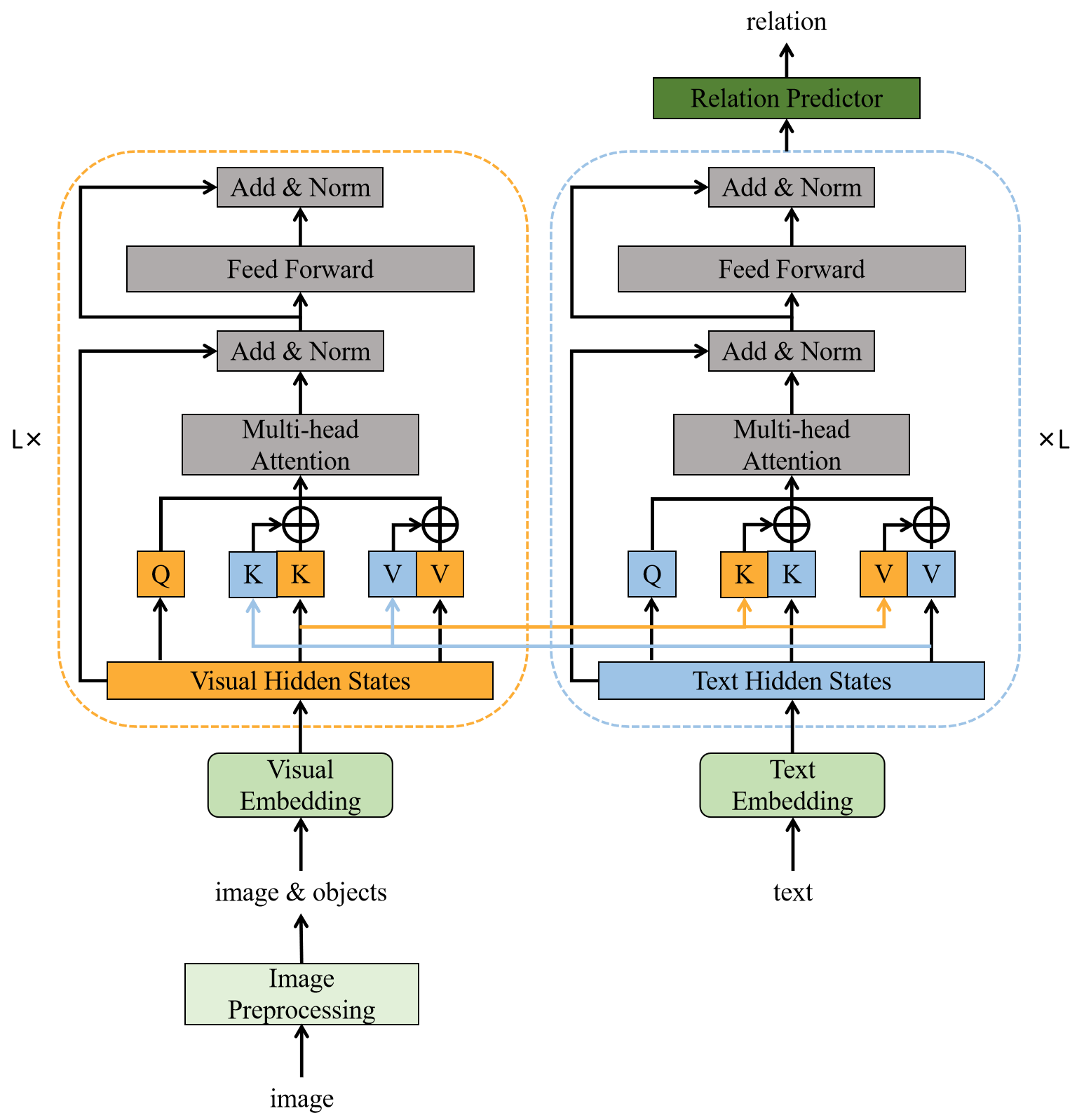
-
Online system & cnSchema-based off-the-shelf models
http://deepke.zjukg.cn
위 링크를 통해 온라인 환경에서 DeepKE를 사용해 볼 수 있다. 모델을 다국어(영어, 중국어)의 다른 시나리오 내에서 훈련시키고 훈련된 모델을 온라인에 공개하였다. 해당 시스템을 통해 원문에서 NER, RE, AR 작업이 바로 가능하고 추출된 relational triple들을 지식 그래프로써 확인 할 수 있다.
Evaluation
only for multimodal settings
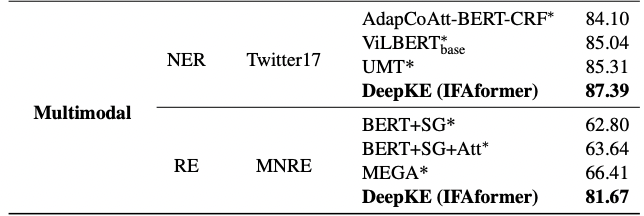
(1) NER
Dataset
- Twitter-2017[2]
Baseline
- AdapCoAtt-BERT-CRF[3]
- ViL-BERT[4]
- UMT[5]
(2) RE
Dataset
- MNRE[6]
Baseline
- BERT+SG[7]
- BERT+SG+Att (Bert+SG with attention calculating semantic similarity between textual and visual graphs)
- MEGA[8]
Reference
[1] https://wikidocs.net/24682
[2] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
[3] Zhang, Jinlan Fu, Xiaoyu Liu, and Xuanjing Huang. 2018b. Adaptive co-attention network for named entity recognition in tweets. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1).
[4] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
[5] Jianfei Yu, Jing Jiang, Li Yang, and Rui Xia. 2020. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3342–3352, Online. Association for Computational Linguistics.
[6] Changmeng Zheng, Zhiwei Wu, Junhao Feng, Ze Fu, and Yi Cai. 2021b. Mnre: A challenge multimodal dataset for neural relation extraction with visual evidence in social media posts. In 2021 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6.
[7] Changmeng Zheng, Junhao Feng, Ze Fu, Yi Cai, Qing Li, and Tao Wang. 2021a. Multimodal Relation Extraction with Efficient Graph Alignment, page 5298–5306. Association
[8] Changmeng Zheng, Junhao Feng, Ze Fu, Yi Cai, Qing Li, and Tao Wang. 2021a. Multimodal Relation Extraction with Efficient Graph Alignment, page 5298–5306. Association for Computing Machinery, New York, NY, USA.
[9] https://colab.research.google.com/drive/1ZRqqXMSDWoPpAKL7h9w9pq-SY-2gjc-u?usp=sharing
