저번 주 토요일에 SQLD 시험을 무사히 끝내서 이번 주부터는 연구에 더 집중할 수 있게 되었다!
근데 막상 또 하려고하니까 막 예전에 가속도 붙었을 때보다는 의욕이 없넹...🙁
그래도 이제는 해야되니까...! 열심히 해봅세!
저번에 한게 좀 오래돼서 까먹을 뻔 했지만 그래도 내가 어떻게 이걸 했는데..!!
traffic_test_0=traffic_test.insert(2,'0시_x',velo_df.iloc[:,[2]])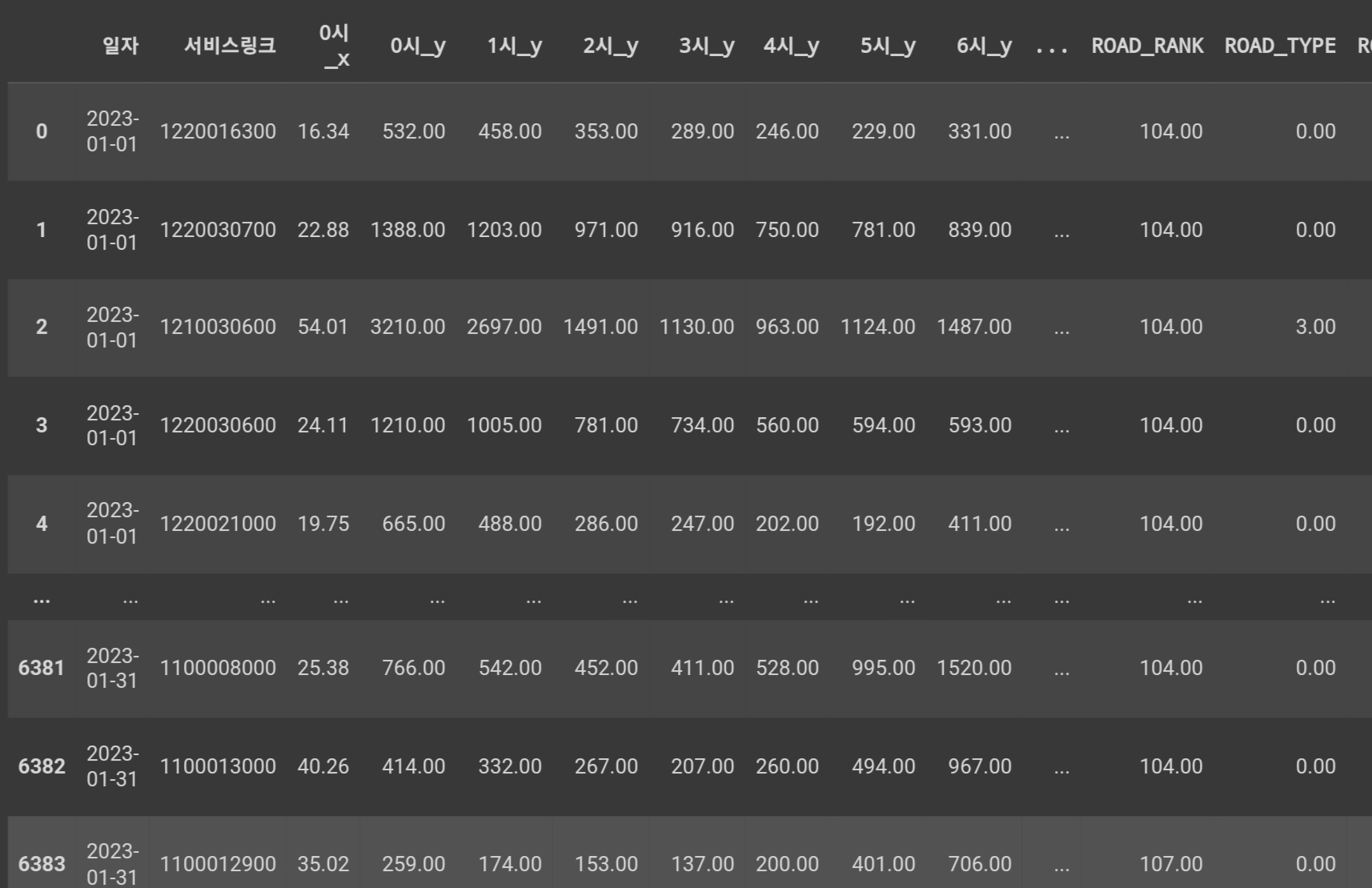
먼저 0시만 따로 빼서 데이터셋을 만들어 주었다.
traffic_test_0으로 모델을 만들어 보도록 하겠다!
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import math우선 이렇게 모듈을 불러와준다.
그리고 train_test_split 을 이용해 훈련세트와 테스트세트를 나눠주었다.
X=traffic_test_0[['0시_y', '1시_y', '2시_y', '3시_y', '4시_y', '5시_y','6시_y', '7시_y', '8시_y', '9시_y', '10시_y', '11시_y', '12시_y', '13시_y','14시_y', '15시_y', '16시_y', '17시_y', '18시_y', '19시_y', '20시_y', '21시_y',\
'22시_y', '23시_y', '표준링크아이디', 'LANES', 'ROAD_RANK', 'ROAD_TYPE', 'ROAD_USE', 'MULTI_LINK', 'CONNECT', 'MAX_SPD','REST_VEH']]
y=traffic_test_0['0시_x']
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.25, random_state=0)랜덤포레스트는 우리가 직접 설정해야하는 하이퍼 파라미터가 많다.
일정 범위에서 어느 값이 가장 최적인지 맞추기 위해 다음과 같은 코드를 실행시켰다.
params = {
'n_estimators':(500, 600),
'max_depth' : (8, 50),
'min_samples_leaf' : (8, 18),
'min_samples_split' : (8, 16)
}
rf_model = RandomForestRegressor(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_run, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print('최적 하이퍼 파라미터:', grid_cv.best_params_)
print('최적 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))여기서 내가 사용한 파라미터는 n_estimators, max_depth, min_samples_leaf, min_samples_split이다.
- n_estimators : 결정트리의 개수를 지정해준다. 기본 값은 10. 트리의 개수가 많으면 많을 수록 성능향상이 되는 것은 맞지만 시간이 오래 걸릴 수 있다.
- max_depth : 트리의 최대 깊이.
- min_samples_leaf : 리프노드가 되기 위해 필요한 최소한의 샘플 데이터 수를 지정해준다.
- min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터수를 지정해준다.
모델을 만들 때 하이퍼파라미터를 따로 지정해주면 모델의 정확도가 상승하기 때문에 적당한 값으로 넣어주는 것이 좋다.
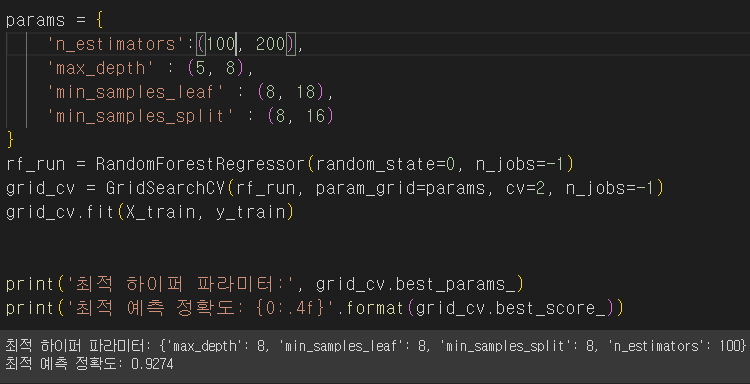
맨처음에 저렇게 하이퍼파라미터의 범위들을 지정해주고 모델을 돌렸더니 위와 같은 값이 적당하다 출력되고 정확도는 0.92정도 였다.
나는 여기서 결정트리의 개수를 좀 늘리고 싶어서 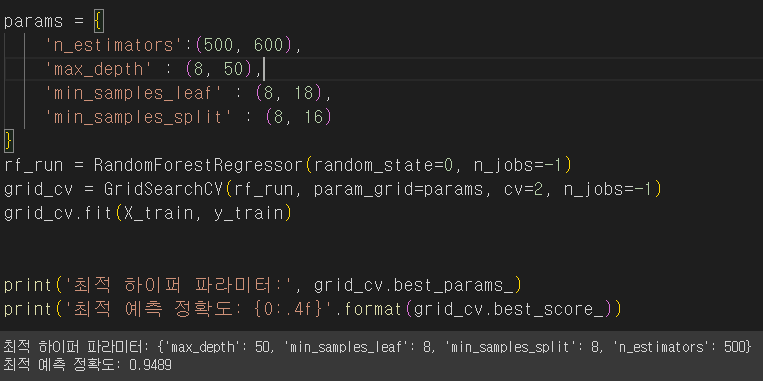
500~600의 범위를 지정해주었는데 500개가 가장 최적이라는 결과가 출력되었다.
물론 시간은 진짜 오래걸렸다.
예측 정확도는 0.94로 0.02 정도 향상된 것을 알 수 있다.
적절한 파라미터의 값을 넣어주는 것이 중요하다는 것을 알았다 ㅎㅎ
따라 저 위의 값으로 모델을 다시 만들어 주었고
rf_model = RandomForestRegressor(random_state=0, max_depth=50, min_samples_leaf=8, min_samples_split=8,n_estimators=500)
rf_model.fit(X_train, y_train)pred = rf_model.predict(X_test)
rf_model.score(X_test,y_test)예측도도 출력할 수 있게 되었다.!
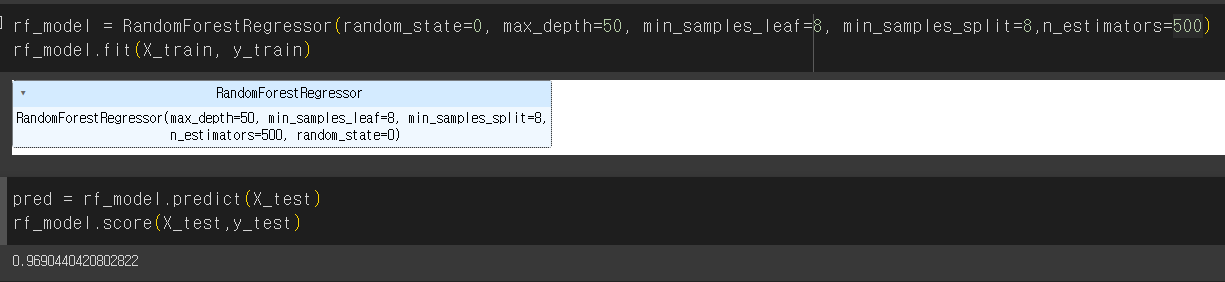
0.96정도면 꽤 높다고 생각하는데...어느정도가 나와야하는지는 오빠한테 한번 물어봐야겠다!
