
오늘은 화요일.
분명 어제도 모델 수정을 했을텐데 따로 적진 않았다.
왜냐고?
.
.
.
.
.
멘탈이 굉장히 나갔었기 때문이다...

한 부분에서 생각이 꼬여서 계속 고민했다...4시부터 고민해서 8시에 퇴근!😂
심지어 어제 되긴했는데 갑자기 행이 700개대로 줄어드는 아주 이상한 현상이 일어나서 바로 자리를 박차고 퇴근했다.
오늘은 새로 모니터도 설치하고 진행도가 많진 않아서 어제 오늘 한 것 한꺼번에 적을 것이다!
우선 내가 랜덤포레스트로 모델 만든건 아주 형편없는 것이었다!🤓
보통 모델은 하나의 데이터를 가지고 분석을 진행하는데 나에게는 두 개(교통량, 속도)의 데이터가 있었다.
나두 아는뎅...
근데 내가 소신껏 행동하지 못해서 두 개의 데이터로도 뭔가 모델을 만들거나 할 수 있는건가?라는 생각이 들었다.
그렇게 해서 두 데이터를 모두 넣었고 평균제곱오차가 50000이 나왔었다.
당연한 현상이었다...
컴퓨터는 거짓말 하지 않으니까...
우리가 예측하려고 하는 것은 한 개의 열로 표현되어야 한다.
즉 교통 데이터를 기준으로 할 것이라면 속도 데이터에서 우리가 예측하고 싶은 열 한개만 추출해서 붙이는 방식으로 해야된다는 것이다..
이것도 생각했었는데 뭔가 아까웠다(??)
그래서 0시부터 23시까지의 열을 한 개씩 이용하여 예측해서 (그럼 총 24개의 모델이 나오겠지?)가장 정확도가 높은 것을 채택하려고 한다!
그리고 또 수정사항이 있었는데...
서비스링크와 표준링크아이디 호환(?)하기
머릿 속에서 꼬여서 몇 시간을 고민하게 만든 녀석들인데..
(내가 제대로 이해 못한거긴 하지만)
다시 정리를 해보자면
👉TOPIS에서 제공하는 데이터의 링크아이디는 서비스링크.
교통, 속도 데이터도 TOPIS에서 받았으므로 서비스링크이다.
👉추가로 얻은 링크 정보를 품은 데이터는 표준링크.
ITS에서 얻었다.
즉, 표준링크아이디를 기준으로 합쳐야 했던 것이다.
이제 코딩부분으로 들어가보면
컬럼의 이름을 바꿔주고
pd.merge(link_csv,mapping_data1,how='left',on='표준링크아이디')표준링크아이디를 기준으로 합쳐주었다.
아, 여기서 'mapping_data1'이 뭐냐고?
링크정보데이터에서 링크아이디의 열을 리스트로 출력해서 겹치는게 뭐가 있나 확인해본 적이 있다.
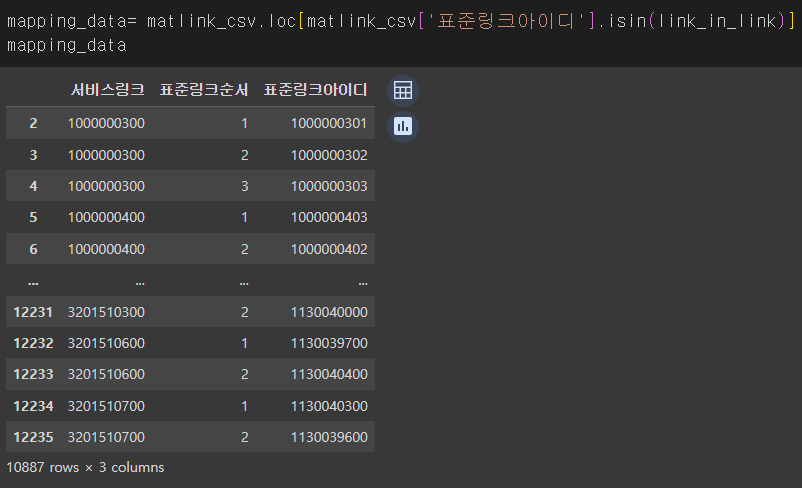
이렇게 됐었는데
2,3,4번의 행만 봐도 서비스링크 1000000300에 서로 다른 표준링크아이디가 3개가 배정되어 있는것을 확인할 수 있다.
꼭 이 값들을 다 쓰지 않아도 되고 저 중에 하나만 써도 돼서 이상이 없게 하기 위해 drop_duplicates을 이용하여 서비스링크에서의 중복되는 값을 없애주었다.
mapping_data.drop_duplicates(['서비스링크'])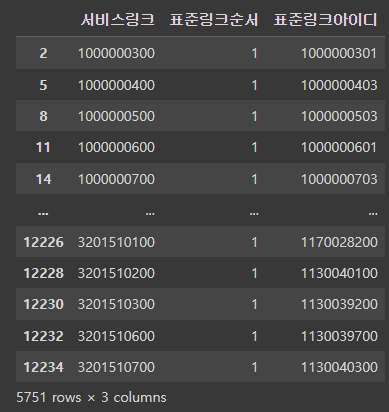
위의 사진과 비교하면 서비스링크의 중복되는 값이 없어진 것을 확인할 수 있다.
5751의 행이 중복되는 값을 제거하고 매칭되는 것이니 NaN값을 제거해도 저만큼의 행이 나올 것이다.!
test2.dropna(subset=['서비스링크'], how='any', axis='index').reset_index(drop=True, inplace=False)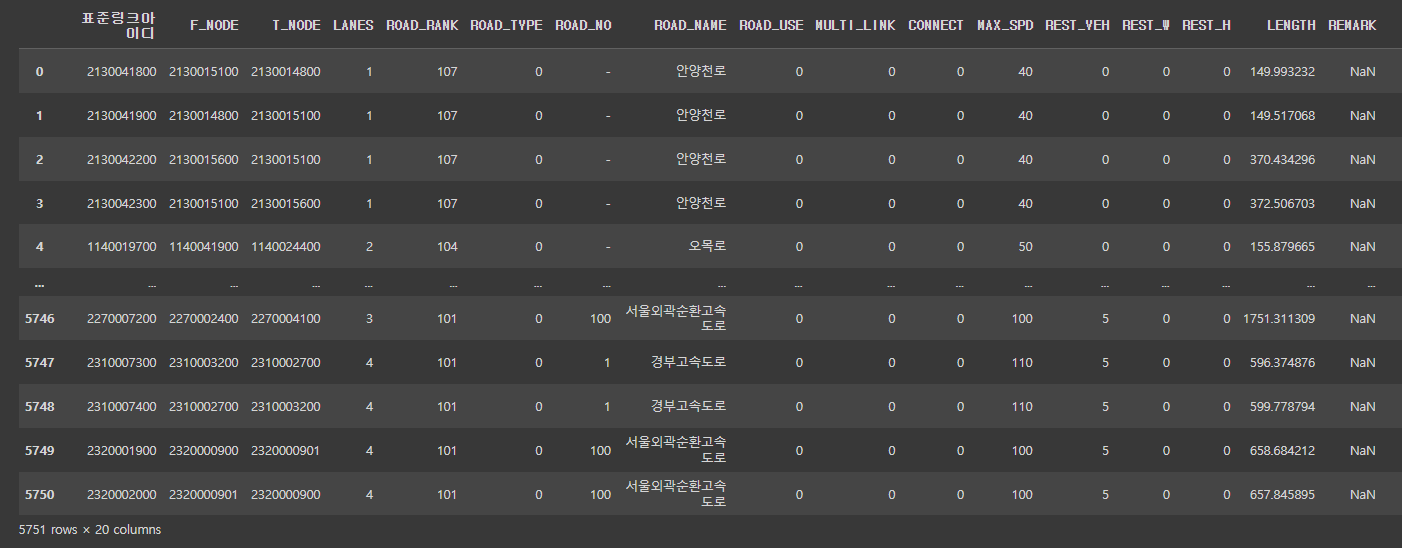
subset을 이용해 NaN값을 제거해줄 열을 지정해주었는데 5751개의 행이 나옴으로써 내가 잘 매치했다는 것을 알았다!🤪
여기까지가 4시간 걸림...
그리고 오늘 이 부분을 교통 데이터에 붙여보았다.
교통 데이터 링크아이디에 표준링크 붙인 건 안 비밀
속도와 교통 데이터의 '링크아이디'라는 컬럼명을 '서비스링크'로 변경해주고
traffic_df.rename(columns={"링크아이디":"서비스링크"}) # 교통데이터는 TOPIS에서 제공하는거라 서비스링크이기 때문교통 데이터는 서비스링크니까
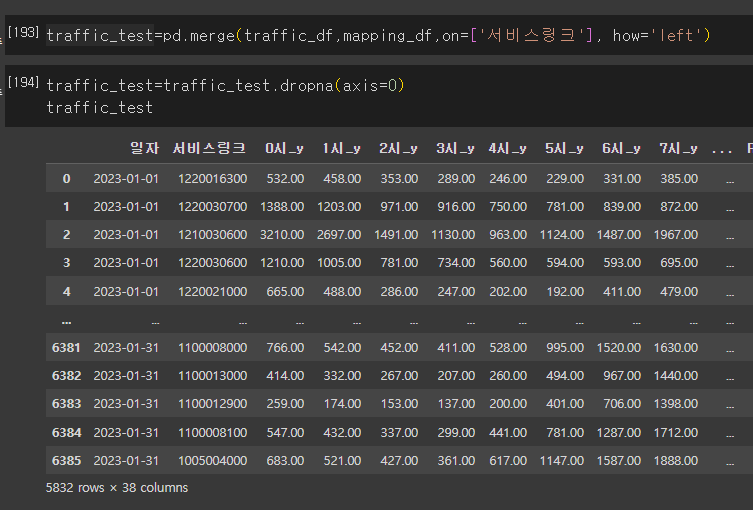
서비스링크를 기준으로 연결해주고 NaN값을 제거하니 아주 예쁘게 행들이 출력된 것을 확인할 수 있었다.
그리고 속도데이터의 시점을 한 개씩 다 넣어주기로 했으니까
traffic_test.insert(2,'0시_x',velo_df.iloc[:,[2]])(velo_df.iloc[:,[2]] : velo_df에서 행은 모두 출력하고 2번째 열만 빼기)
이렇게 하면
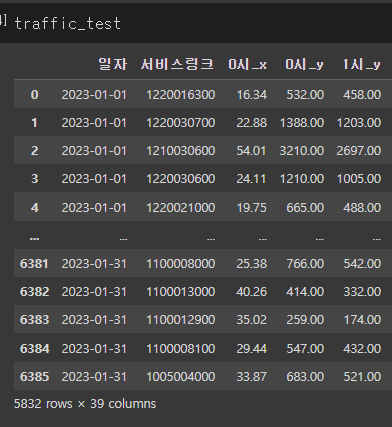
잘 붙은 것을 확인할 수 있다..!!!
(행의 순서나 그런 것들은 이전에 모두 같게 맞춰주었으므로 바로 붙여줘도 됨)
데이터 전처리는 끝난 것 같다...🎉
하하...이제 모델 만들어서 돌려야지...
고생했다...🫠
