
오늘도 탈탈 털린 진희씨..
입맛이 없어서 점심 안먹고 계속 서치해서 적용해본 결과 MSE가 50000이 나온 것에 관하여....
심심치않은 위로를 해주신 남자친구께 감사하며
오늘 내가 한 것을 적어보겠다...
어제 정리한 매핑 정보를 교통량 데이터와 속도 데이터에 연결해주었다.
이번에도 마찬가지로 merge()로~
효자머지🥹
그리고 NaN값 제거~
교통량도 마찬가지로 똑같이 진행~
진짜는 이제부터 였는데....

🤓말하는 감자의 뭐라도 해보깅-⭐헤헷 콩-⭐
임포트 한 것들을 보면 나의 행적이 보일 것이다.
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import mean_squared_error, r2_score
from sklearn import metricsㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋ.ㅋ
뭘 자꾸 시도는 해보는데 모듈이 없어서 계속 불러오다보니까 이만큼 쌓였다.
train, test로 나누기 전에 데이터 타입이 맞지 않는 열이 있어서 그것들을 제거해주고 해주었다.
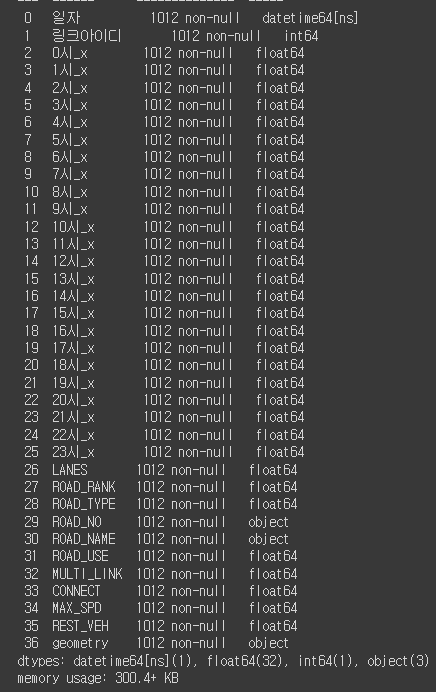
다 float으로 맞춰주는게 나을 것 같아서
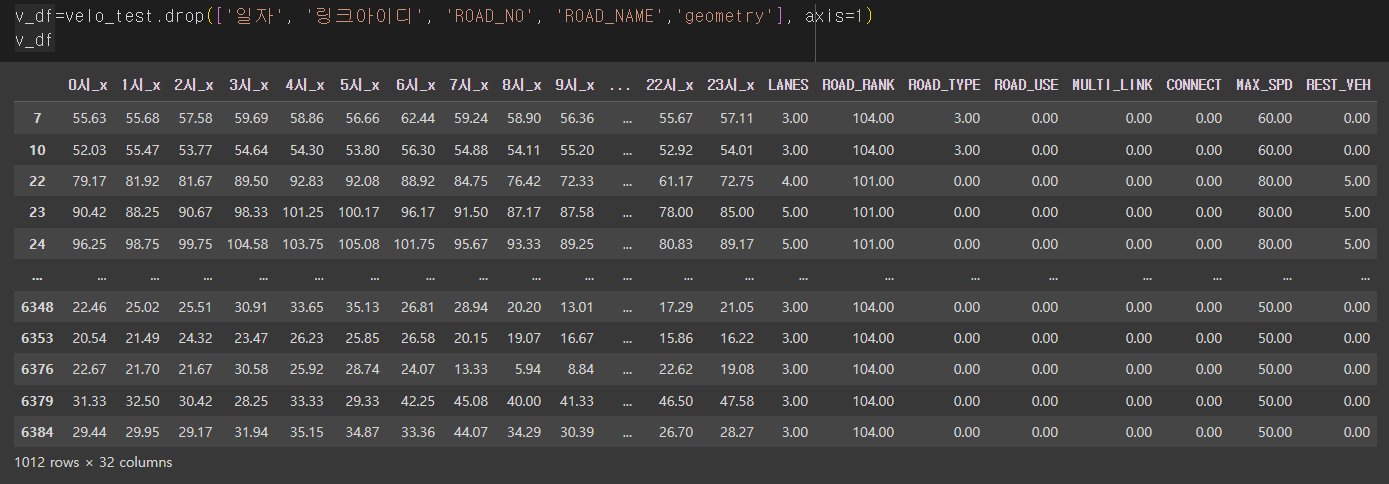
저렇게 지워주었다!
교통량 데이터도 !
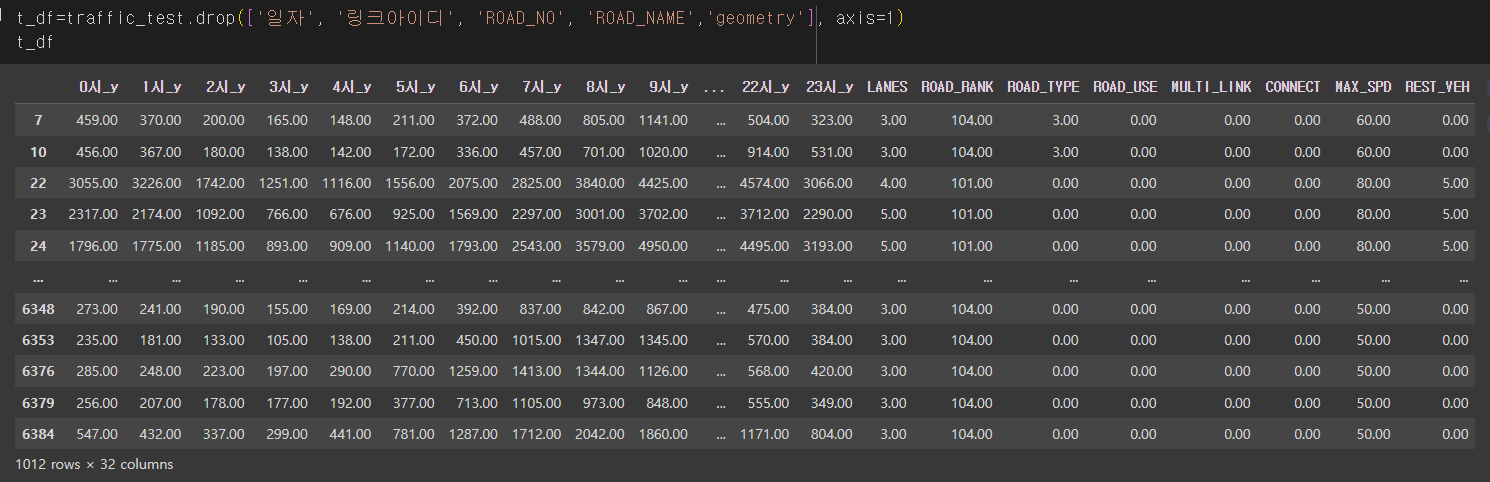
이 뒤 부터는 혼공머신 책을 보고 참고한 것들이라 코드만 적어놓는다.
렌덤포레스트로-
X_train, X_test, y_train, y_test = train_test_split(v_df,t_df, test_size=0.2, random_state=42)
rf_model = RandomForestRegressor(n_jobs=-1, random_state=42)
scores = cross_validate(rf_model, X_train, y_train,
return_train_score=True, n_jobs=-1)
ㅇ..어엇 생각보다 높고 괜찮은 값인데...?살짝 과대적합이지만
오케이 특성중요도도 출력해주고~
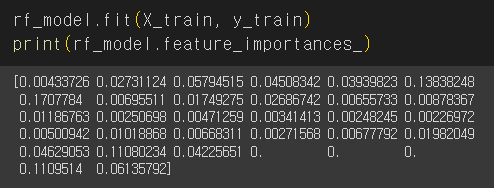
예측도 해주고~
이제 정확도만 출력해주면..❕❗❕❗
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
응?
.
.
.
.
50000? 소수점이 뭐가 잘못됐나?
.
.
.
.
🫠🤯🤮😭
어딘가 잘못됐다!
ㅎㅎ..
.
..
...
나도 저런 숫자는 처음봤다.
다시 피드백 받아야지...
다음 쓰는 글에는 문제 해결을 적을 수 있으면 좋겠당...
하루 끝-

비전공자 주인장 일하느라 방치