서론
블로그 포스팅이 많이 뜸했다.
내가 그동안 한 노트북에 좀 실험적(?)으로 코드작성을 많이해서 전체적인 코드가 중구난방이고 반복되고 복잡한 내용이었다.
그래서 숫자만 바꾸고 바로 데이터 넣으면 원하는 데이터가 짜잔 나오게 하려고 코드를 정리하는 시간을 가졌다.
변수정도를 다시 출력하는 셀을 삭제하고 나머지를 그냥 바로 넣으면 되겠다 싶었는데 생각보다 너무..코드의 가독성이 떨어졌다.
줄일 수 있는 부분은 줄이고 ( drop으로 열개가 넘는 컬럼을 지우기보다는 원하는 것만 뽑아서 출력하는 등) 지울 수 있는 코드는 지우는 식으로 깔끔하게 만들기로 했다.
그러면서 몇가지 문제점도 발견했고 '내가 왜 이렇게 빙빙 돌아서 했지...' 싶었던 부분도 있었는데 , 그 부분들을 기록해보고자 한다.
본론
1. drop->[]
df.drop(['요일','도로명','방향','거리','차선수','기능유형구분',
'도심/외곽구분', '권역구분', '01시', '02시', '03시', '04시', '05시', '06시', '07시',
'08시', '09시', '10시', '11시', '12시', '13시', '14시', '15시', '16시', '17시',
'18시', '19시', '20시', '21시', '22시', '23시',],axis=1)이렇게 복잡하게 했던 코드를
df[['일자', '링크아이디','24시']]간단하고 가독성 있게 수정했다.
2. 재활용
아마 이 부분을 좀 생각하기 어려웠지 않았을까.
그동안은 하나의 데이터, 즉 하나의 월로만 전처리를 진행했기에 여러 개로 했을 때에는 변수가 겹치기도 했고 이전 월에서 만들었던 변수를 또 사용해야하는 일이 있을거라고 생각했다.
이전 데이터에서 24시( 다음 날 0시가 될 친구들)을 따로 뺀 변수가 있었는데 그 데이터셋의 마지막 날을 다음 달의 데이터에 붙여야 했었다.
이 변수는 형태를 바꾸지 않는 선에서 다시 활용했다.
3. 잘못 생각한 부분

날짜에 1을 더한 부분을 월 데이터에 더해줄때 월의 1일은 결측치가 될 수 밖에 없었다.
이 부분을 채워주기 위해 기존의 코드에서는 24시 컬럼을 fillna를 사용해 넣어주었는데 이게 생각해보니 링크아이디와 겹치는 속도 데이터가 들어갔다고 보장할 수가 없을 것이다 라고 생각했다.
그래서 이 부분은 또 merge를 이용해
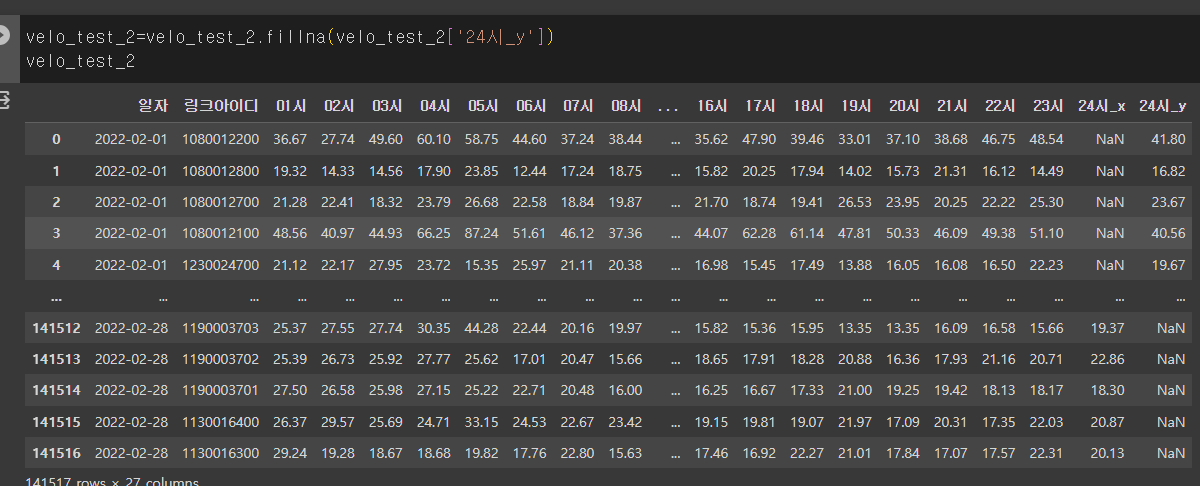
이렇게 일치하는 부분을 확실하게 명시했다.
사실 내가 원하는 형태는 저 NaN값이 없어지고 앞으로 쫙 당겨진 모습이었지만 이건 코딩이니까..코드로 구현해야지...
정말 많이 고민했다...ㅋㅋㅋ
어쨌든 fillna를 이용해서 채워주거나 dropna를 이용해서 없애주긴 해야했다.
dropna는 행과 열 전체를 지워주어 저 부분만 똑 떼어서 지울 순 없었다. 그래서 이건 패스!
fillna를 이용해 '24시_y'컬럼을 따로 떼어서 넣어주려했는데 안들어가지더라...
...저 컬럼만 떼니까 안됐지....
저렇게 특정한 값으로 넣어주고싶으면 NaN값을 가지고 있는 데이터셋과 같은 형태를 가지고 있어야하는 것 같았다.
(쉽게 얘기하지만 찾는데 어려웠다. 더 공부해야겠으)
그래서 내가 생각한 방향은 기존의 것을 똑같이 복제해서 그대로 넣어주자! 였다.
(만들어질 데이터 변수명) = (복제할 데이터 변수명).copy간단하다.!
이렇게 만들어진 걸로 NaN값을 채우고 컬럼 잘 다듬어 정리하니까
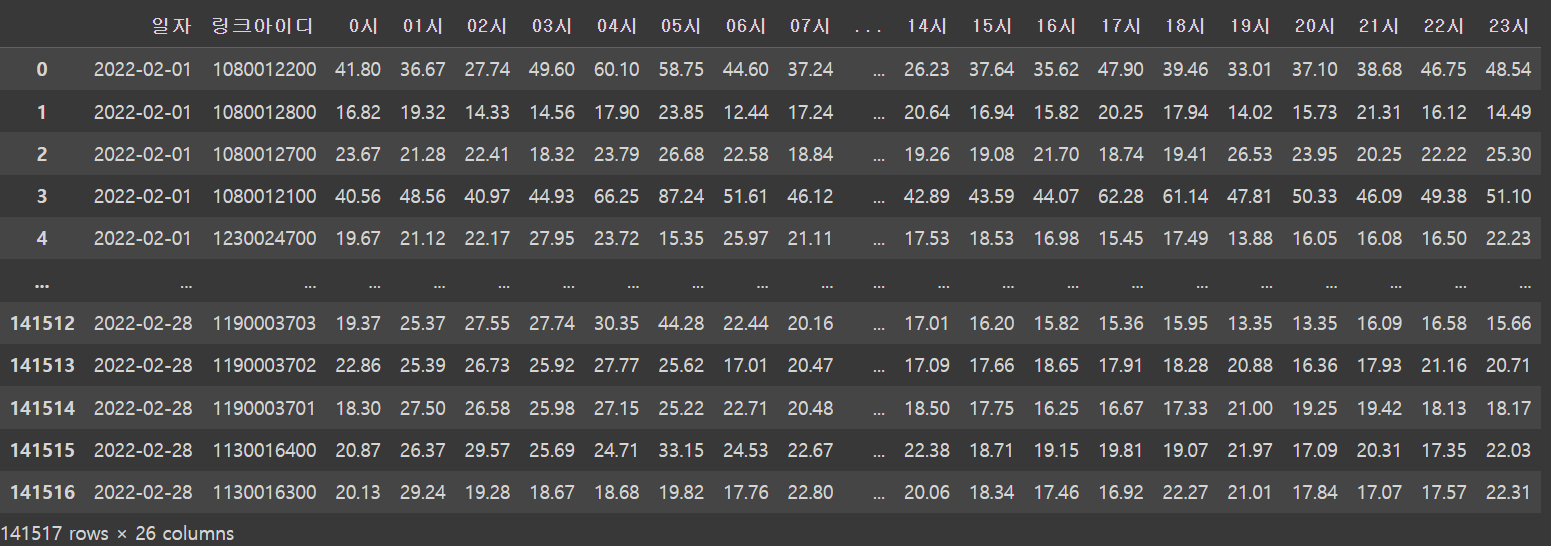
잘...나왔더라...ㅎㅎㅎㅎ....
이렇게 해서 셀 12개 복사해서 12월까지 데이터 잘 만들어줬다.
결론
이제 교통량해야지...
