
Hadoop 초기 설정
환경파일들 확인
- hadoop 자체의 환경파일들을 확인하기 위해
cd ~/hadoop/etc/hadoop에 들어가서ls을 입력
- 그럼 위와 같이 환경파일들을 확인할 수 있다.
저장소 지정(workers)
-
cd ~/hadoop/etc/hadoop에서vim workers입력- 나오는 vim 화면에 datanode1, datanode2, datanode3 입력하고
:wq, 여기서 datanode는 실제 데이터가 저장되는 곳(나의 경우 세 개의 datanode를 지정한 것)
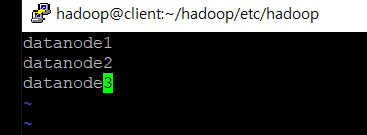
- 나오는 vim 화면에 datanode1, datanode2, datanode3 입력하고
-
workers 파일 복사(scp 사용법)
-
scp [파일대상][서버][서버의 파일경로]
-
scp ./workers namenode:/home/hadoop/hadoop/etc/hadoop/(namenode, secondnode, datanode3 모두 같은 명령어 실행) -
위 명령어는
cd ~/hadoop/etc/hadoop에서 실행 -
이 경우 다른 서버끼리 미리 ssh 연결되어 있어야 함(전에
vi /etc/hosts했던 거)

-
./workers파일을 다른 서버로 복사하는 명령어로, 이 파일을 복사해/home/hadoop/hadoop/etc/hadoop/디렉토리에 배치하면 namenode가 worker 노드를 식별하고 클러스터의 구성을 설정, 작업 분산을 할 수 있음
-
하둡 서버의 resource map
ec2 보안그룹 설정
- 인바운드 규칙 추가(위에 있는 22번 포트는 기본으로 있는 규칙, 새로 추가하는 인바운드 규칙의 소스는 내 보안그룹 선택하면 됨)
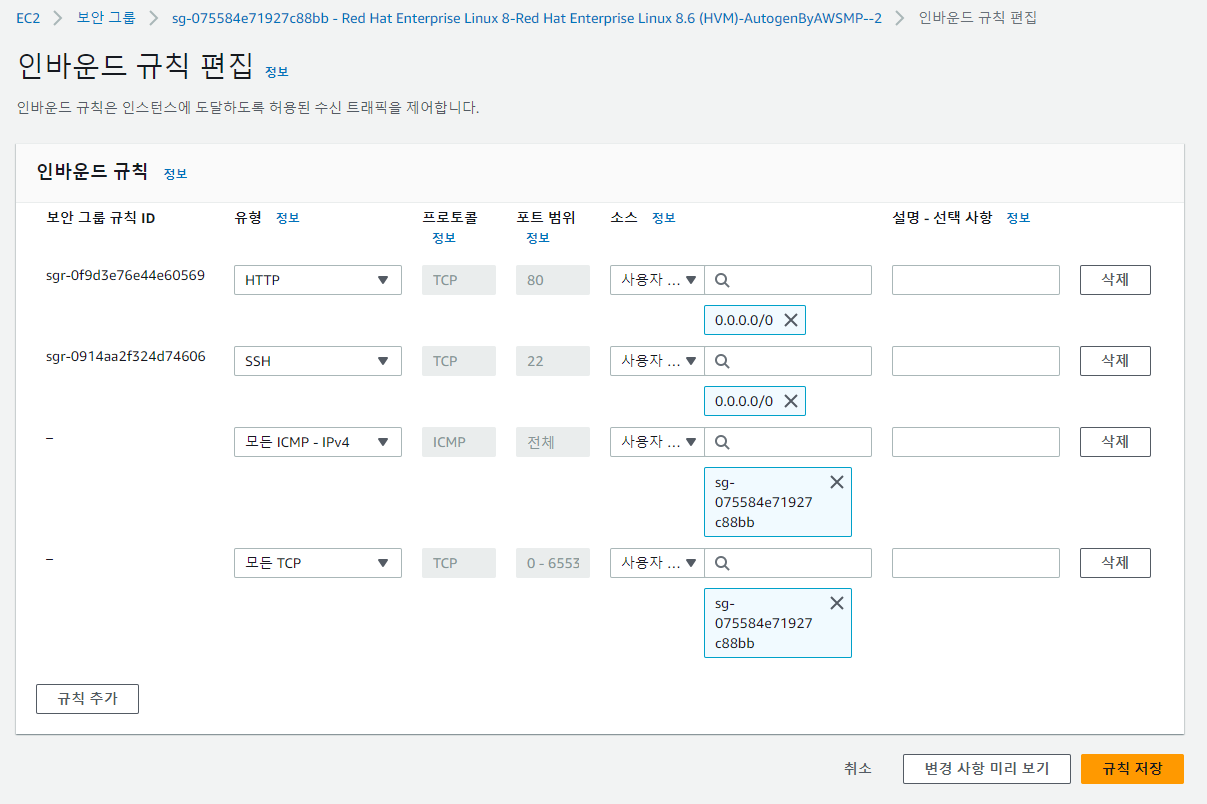
- 인바운드 규칙을 수정하고
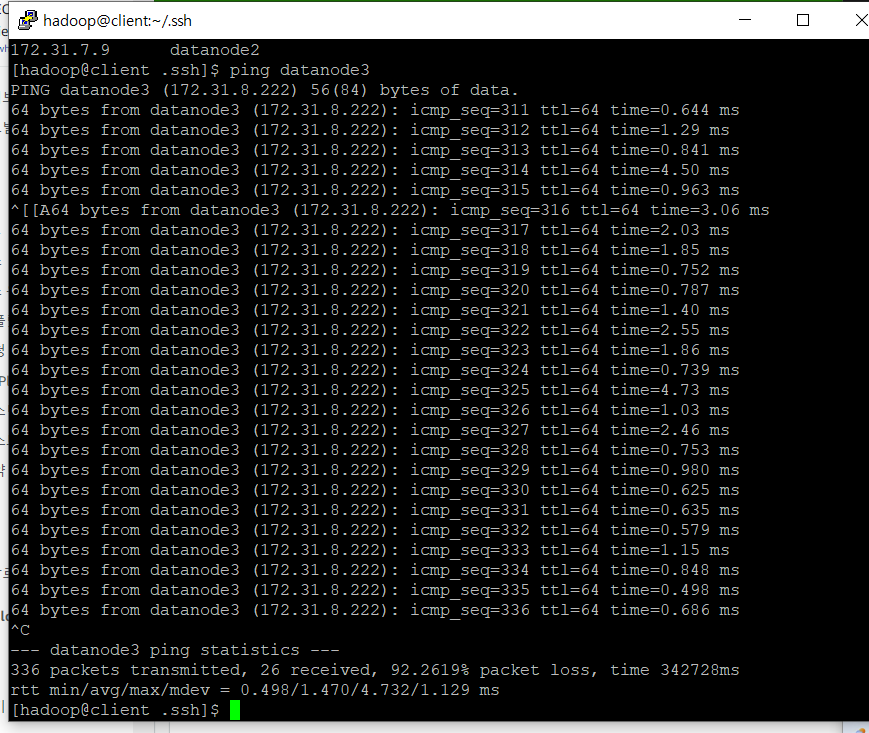
ping datanode3를 입력하면 실시간으로 ping이 보내지는 걸 볼 수 있음(ping은 네트워크 연결 상태를 확인하기 위해 주로 사용)
hadoop format
ssh namenodenamenode로 이동hadoop namenode -format
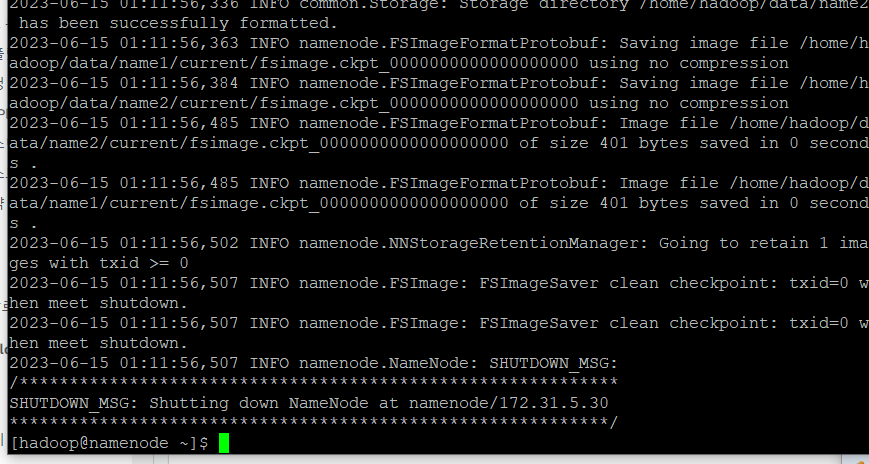
- namenode에 저장된 데이터 초기화, 이는 hadoop 클러스터를 처음 설정할때 또는 데이터를 삭제하고 새로운 클러스터를 구성할 때 사용
- namenode에 어떤 파일이 어디에 저장되고 정보를 저장하는 곳인데, 그 장부를 초기화해서 내용을 쓸 준비를 하는 과정
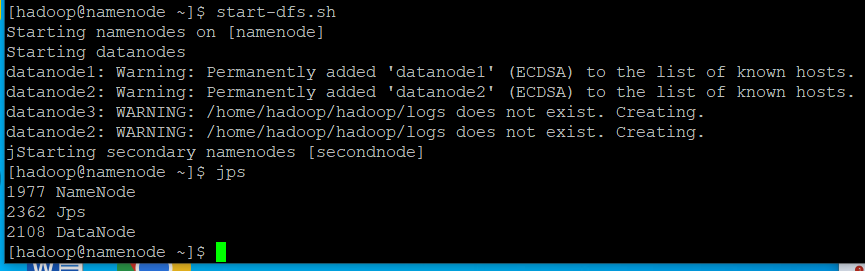
start-dfs
- namenode에서
start-dfs.sh: 분산파일시스템(HDFS)의 서비스를 시작 jps: 자바프로세스를 알려주는 명령어, 직전의start-dfs.sh를 실행하고jps를 입력하면 Namenode, Jps, Datanode가 출력됨
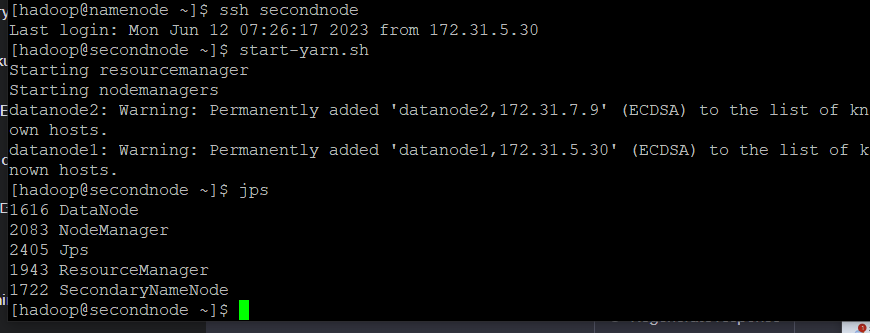
start-yarn
ssh secondnode로 이동한 후start-yarn.sh- yarn은 지원부서같은 개념, 한 node가 빡세면 다른곳으로 보내주는 개념
- 이때 secondnode에서
jps를 입력하면 Datanode, Nodemanager, Jps, Resourcemanager, secondaryNamenode가 출력됨
start-mr
-
mr-jobhistory-daemon.sh start historyserver명령어 입력
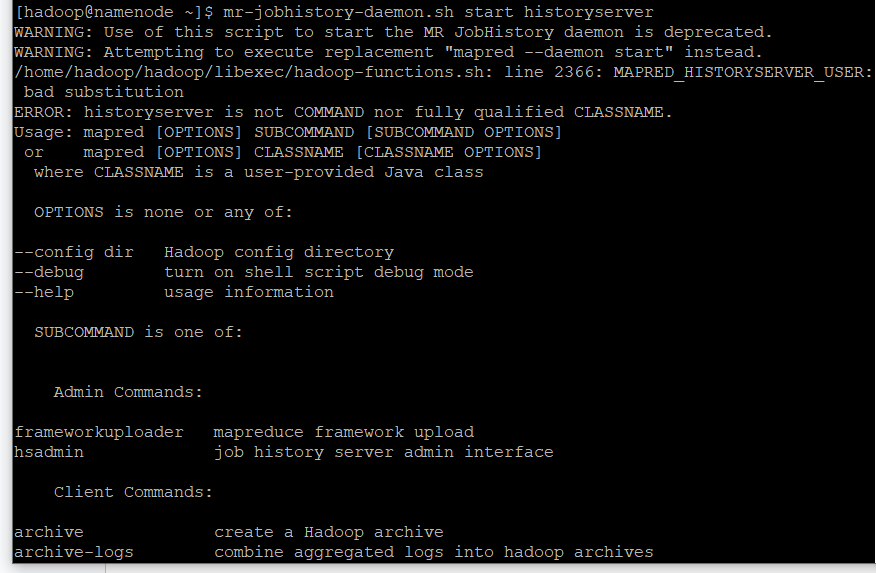
-
이때 datanode3에서
jps입력 시 Datanode, Jps, Nodemanager가 출력됨
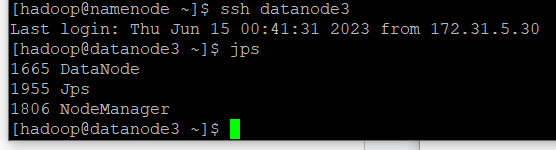
-
위 세개의 start를 실행 한 뒤 namenode와 secondnode에서 jps를 실행하면 Datanode, Nodemanager, Jps, Resourcemanager, secondaryNamenode가 출력됨
-
datanode3에서 jps를 실행하면 Datanode, Jps, Nodemanager가 출력됨
hadoop 상태 확인 페이지
-
보안그룹 인바운드 규칙 추가
- 50070 포트로 소스는
0.0.0.0/0으로 시정하고 규칙 추가

- 50070 포트로 소스는
-
hadoop 상태 확인하는 페이지 열기
- 주소창에
namenode public IP:50070입력(client나 private 아님 !!)
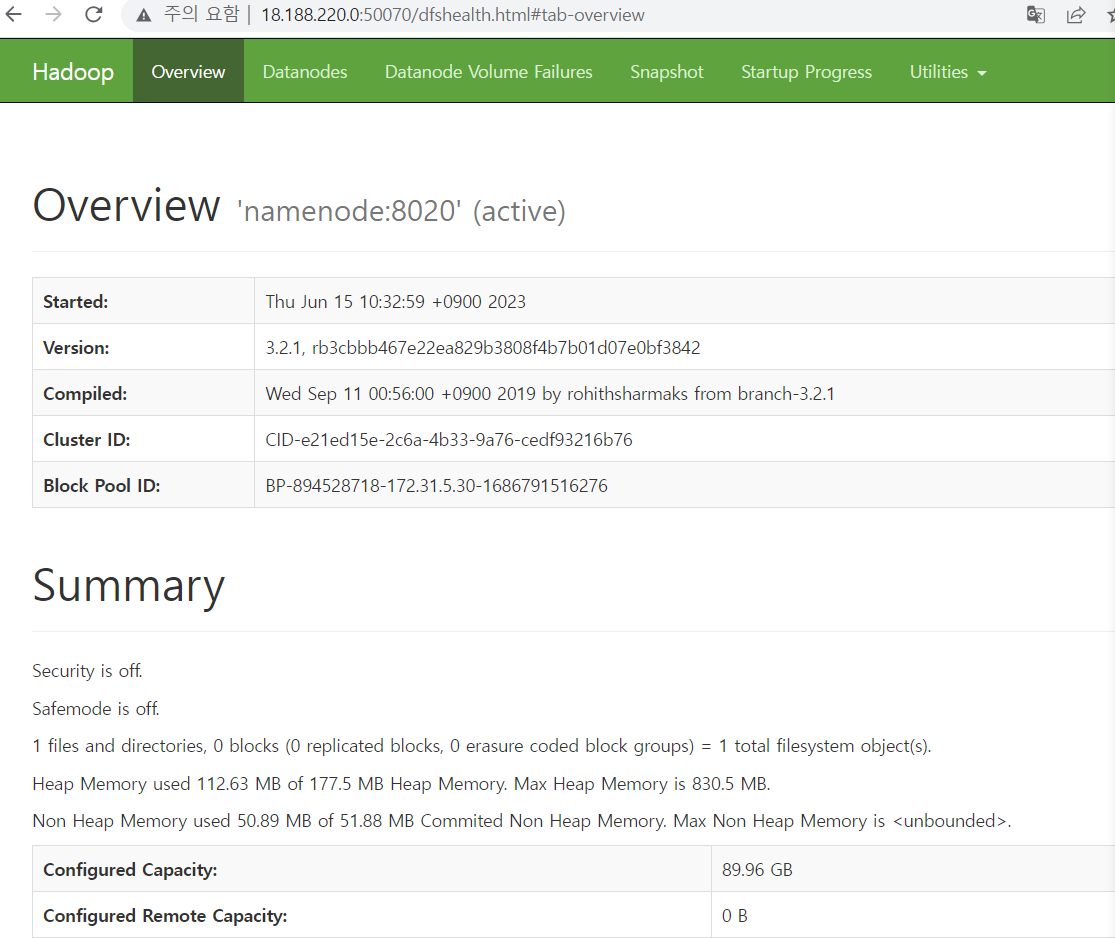
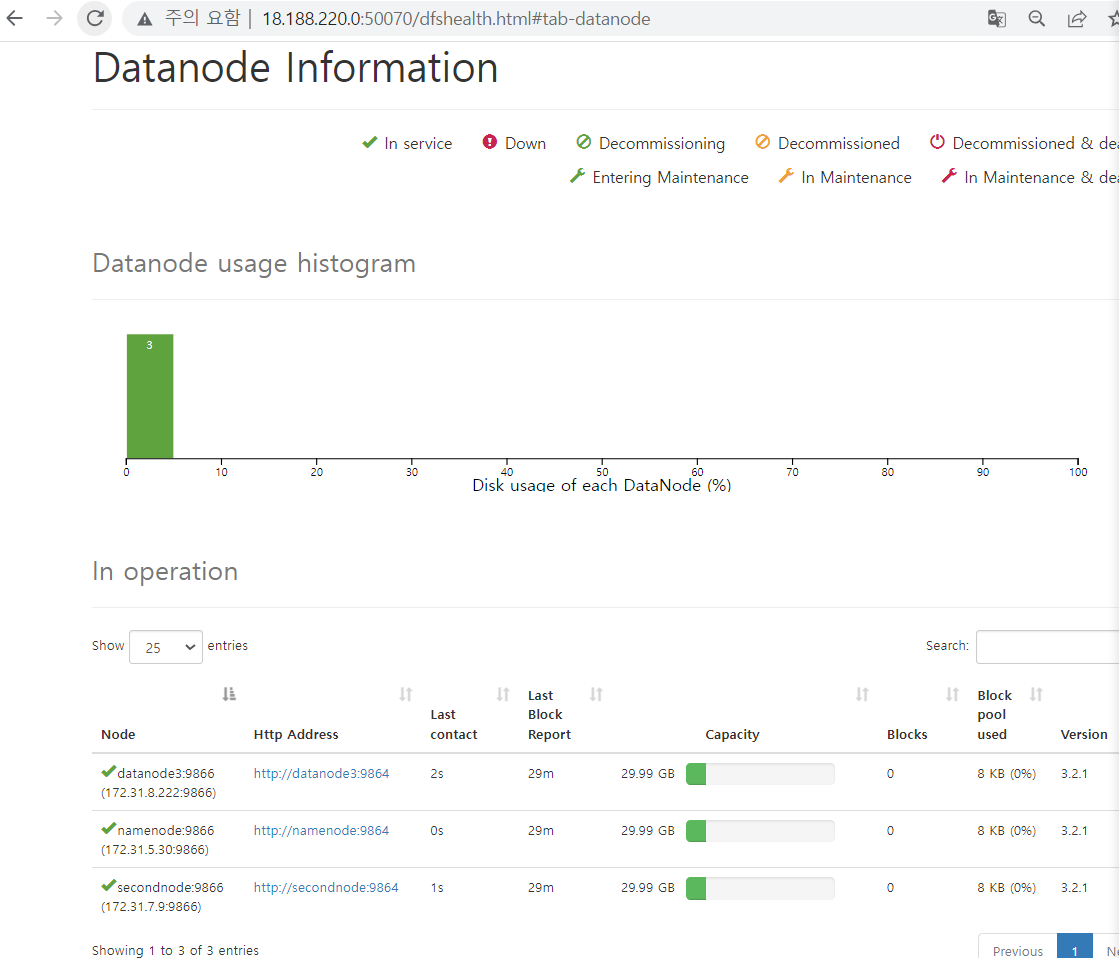
- 이제 datanode 세개의 현재상태를 웹에서 시각적으로 확인이 가능해짐 !
- 주소창에
하둡 로그 확인
-
cd hadoop/logs에서 log를 확인할 수 있음 -
대문자 G 하면 맨끝으로가고 맨 처음으로 가려면 gg
-
tail을 맨 앞에 붙이면 해당 파일의 끝부분만 보여줌, 끝에 3줄만 보고 싶으면 명령어 맨 뒤에
-n 3를 붙여줌 -
log파일을 vim으로 열어서 error가 뜨는 부분을 확인
명령어 쉽게 사용하기
- 앞서 실행한
ssh namenode stop-dfs.sh,ssh secondnode start-yarn.sh같은 명령어를 쉽게 사용하려면 환경파일(bashrc)에서 별칭 설정을 해줘야 함 !
vim ~/.bashrc입력하고 아래 부분을 추가alias start-dfs="ssh namenode start-dfs.sh" alias start-yarn="ssh secondnode start-yarn.sh" alias stop-dfs="ssh namenode stop-dfs.sh" alias stop-yarn="ssh secondnode stop-yarn.sh" alias start-mr="ssh namenode mr-jobhistory-daemon.sh start historyserver" alias stop-mr="ssh namenode mr-jobhistory-daemon.sh stop historyserver"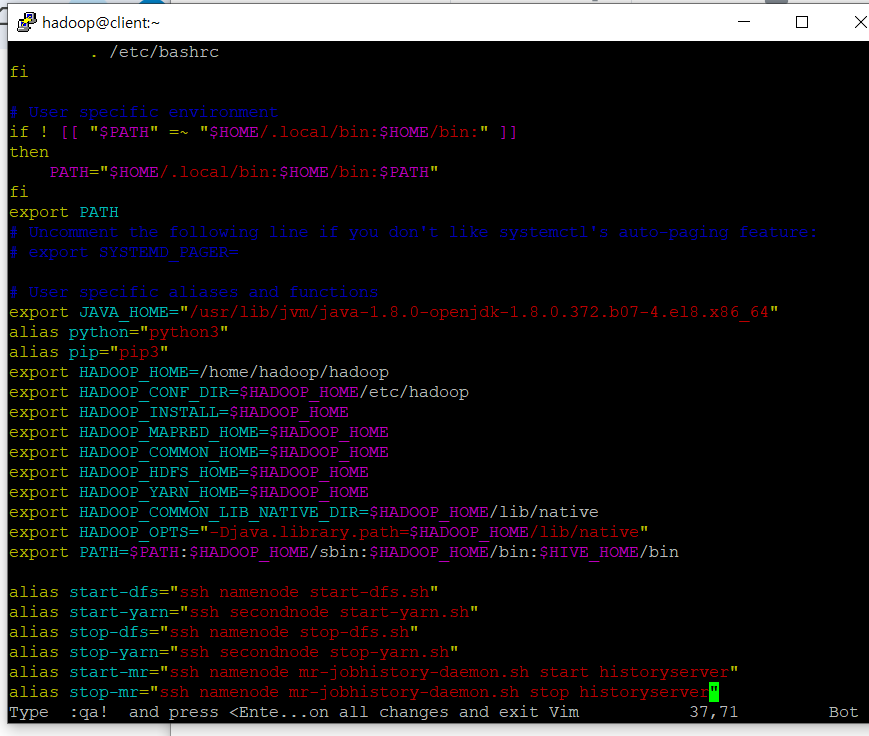
- 그럼 이제 어느 노드에서나
start-dfs,start-yarn,start-mr명령어를 사용해서 위의 작업을 수행할 수 있다 !!
format시 발생하는 에러
-
hadoop namenode -format할때마다 data 폴더 안에 존재하는 파일도 삭제할건지 물어보고(y/n) + 위의 start 명령어 세가지를 모두 실행했는데 namenode, secondnode, datanode3에서 jps하면 datanode만 안뜰때 !!-
이 경우 namenode, secondnode, datanode3 서버의
data폴더가 비어있지 않거나, format시 제대로 format이 안돼서 발생하는 문제였다. -
그래서 나의 경우 세 서버 모두
rm -rf data로data폴더를 삭제하고 format -> start-dfs -> start-yarn -> start-mr 순으로 실행 -
만약 start 명령어를 실행했을 때 이미 running 중이라고 뜬다면 stop-dfs, stop-yarn, stop-mr을 먼저 하고 다시 start 하기 !
-
