실습 개요
-
python안에는 가상환경(conda, Virtualenv 등이 있고 여기서 Requirement.txt안에 입력한 환경대로 설치해줌) 여기서 하위 종속 패키지는 100개 이상 존재
-
Model Service -> MS
Djangorestframework
POST -> Decoretor
Tensorflow Model load
사용자 api -> 질의
- python 가상 환경 사용
- DNN, CNN 모델 생성 여부
- CNN에서 데이터 부족 시 방법?
- 전이 학습 해본 경험
- 모델 서비스 해본 경험
- 모델 배포 여부
등등의 질문에 대한 답변을 하기 위한 실습을 진행 !
1. 기존 모델 학습(Dog/Cat)
1-1 훈련데이터 읽기
#필요한 패키지 불러오기
import zipfile
import glob
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
# zipfile를 통해서 압축을 해제
# data 폴더에 해당 내용을 압축 해제한다.
zip_file = zipfile.ZipFile("./dog_cat.zip", "r")
extract_dir = "./data"
zip_file.extractall(extract_dir)
# training set를 만들기 위해서 압축된 폴더에서 강아지, 고양이 사진을 별도로 읽는다.
IMG_DIM = (150, 150)
train_files = glob.glob('./data/training_set/training_set/dogs/*.jpg')
train_dogs_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_files]
train_files = glob.glob('./data/training_set/training_set/cats/*.jpg')
train_cats_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_files]
train_imgs = np.concatenate((np.array(train_dogs_imgs), np.array(train_cats_imgs)))
# label 데이터 만들기
train_dogs_label = np.ones(len(train_dogs_imgs))
train_cats_label = np.zeros(len(train_cats_imgs))
train_label = np.concatenate((train_dogs_label, train_cats_label))
# 데이터를 255 값으로 나누어 정규화를 시킨다.
train_imgs_scaled = train_imgs.astype('float32')
train_imgs_scaled /= 255zipfile.ZipFile("./dog_cat.zip", "r")-> zip된 파일 읽기모드로 열기glob.glob('./data/training_set/training_set/dogs/*.jpg')-> glob라는 패키지를 활용해서 위 폴더경로에서 .jpg로 끝나는 파일 모두 읽어오기- 마지막 문단 데이터를 255 값으로 나누어 정규화 시키는 이유 : 이미지 데이터의 경우 픽셀 정보를 0~255 사이의 값으로 가지는데, 이를 255로 나누어주면 0~1.0 사이의 값을 가지게 될 것이기 때문 !
1-2 테스트 데이터 읽기
# test set를 만들기 위해서 압축된 폴더에서 강아지, 고양이 사진을 별도로 읽는다.
IMG_DIM = (150, 150)
test_files = glob.glob('./data/test_set/test_set/dogs/*.jpg')
test_dogs_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in test_files]
test_files = glob.glob('./data/test_set/test_set/cats/*.jpg')
test_cats_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in test_files]
test_imgs = np.concatenate((np.array(test_dogs_imgs), np.array(test_cats_imgs)))
test_imgs_scaled = test_imgs.astype('float32')
test_imgs_scaled /= 255
# label 데이터 만들기 (dog는 0, cat는 1)
test_dogs_label = np.ones(len(test_dogs_imgs))
test_cats_label = np.zeros(len(test_cats_imgs))
test_label = np.concatenate((test_dogs_label, test_cats_label))
#훈련데이터 테스트데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(train_imgs_scaled, train_label, test_size=0.2, random_state=42)1-3 모델 설계
#model에 순차적으로 레이어 쌓기
#필요한 패키지 불러오기
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
model = Sequential()
#Sequential 모델 객체를 생성. 이 객체는 레이어들을 선형으로 쌓아서 사용하는 방법
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
#첫 번째 Conv2D 레이어를 추가함. 이 레이어는 3x3 크기의 필터 16개로 입력 이미지에서 특징을 추출. 렐루(Rectified Linear Unit) 활성화 함수를 사용
#첫 번째 맥스 풀링 레이어를 추가함. 이 레이어는 2x2 크기의 필터로 입력 이미지를 다운샘플링.
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
#Convolutional 레이어를 거친 후에 출력된 3D 텐서를 1D 텐서로 평탄화
model.add(Dense(512, activation='relu'))
#512개의 유닛을 가진 Dense 레이어를 추가하고, 이 레이어는 ReLU(정규화된 선형 유닛) 함수를 활성화 함수로 사용
model.add(Dense(1, activation='sigmoid'))
#출력 레이어를 추가하고, 이진 분류 문제를 풀기 위해 sigmoid 함수를 활성화 함수로 사용(따라서 출력값은 0 또는 1)
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model.summary()
#함수는 모델의 레이어, 출력 크기, 파라미터 수 등에 대한 정보를 제공합니다.model.compile()함수에서는 모델을 컴파일합니다.loss매개 변수는 비용 함수를 지정하며, 이진 분류 문제를 다루므로binary_crossentropy를 사용합니다.optimizer매개 변수는 모델의 학습 방법을 지정합니다. 여기서는RMSprop()옵티마이저를 사용합니다.metrics매개 변수는 모델의 성능을 평가할 지표를 지정합니다. 여기서는정확도(accuracy)를 사용합니다.
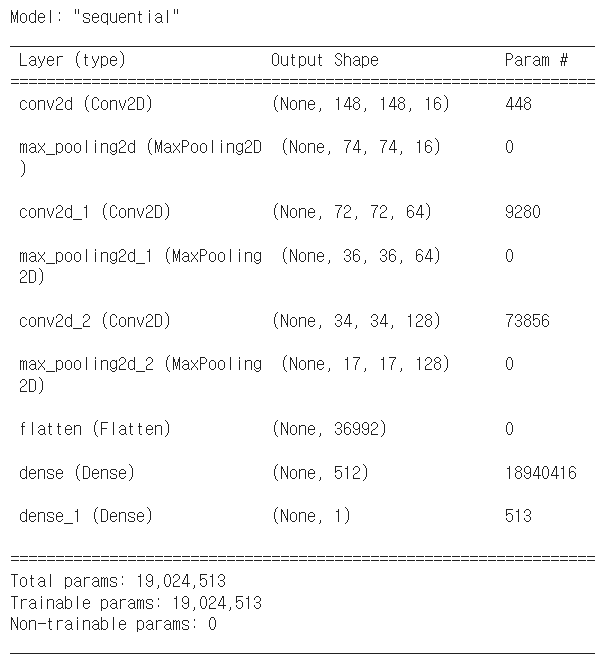
#실행 결과 해석
conv2d의 파라미터수 -> {3 * 3 * 3 * 16 + 16} = 148
두번째 conv2d의 파라미터수 -> {16 * 3 * 3 * 64 + 64} = 9280
세번째 conv2d의 파라미터수 -> {64 * 3 * 3 * 128 + 128} = 73856
flatten으로 펼치면 -> {17 * 17 * 128} = 369921-4 모델 실행
#모델 생성
history = model.fit(x=X_train, y=y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=epochs,
verbose=1)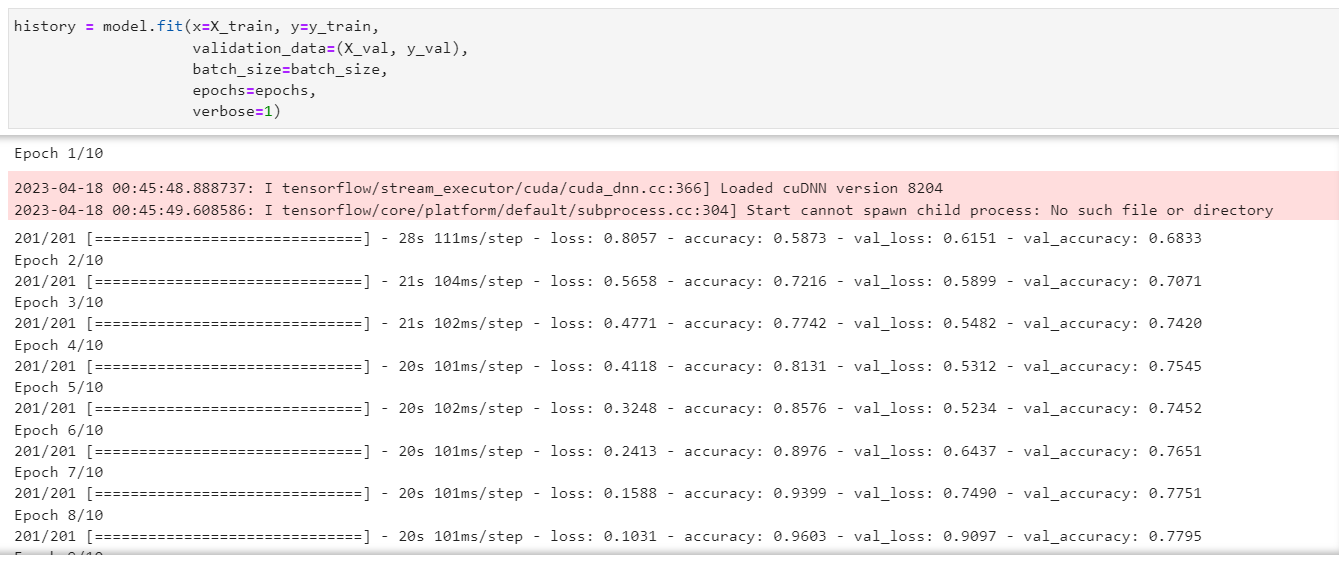
-
위의 코드를 실행하면 모델을 1epochs씩 학습하면서 나오는 출력 화면에서는 4가지 변수 값이 함께 출력된다.
loss: 훈련 과정에서 각 epoch(에폭, 전체 데이터셋을 한 번씩 학습하는 단위)마다의 훈련 손실 값
accuracy: 훈련 과정에서 각 epoch마다의 훈련 정확도 값
val_loss: 훈련 과정에서 각 epoch마다의 검증 데이터셋(validation data)에 대한 손실 값
val_accuracy: 훈련 과정에서 각 epoch마다의 검증 데이터셋에 대한 정확도 값 -
accuracy와 val_accuracy의 차이?
- 둘 다 높은 성능을 가진 모델이 가장 좋은 모델입니다. 하지만, 만약 validation set의 성능이 training set의 성능보다 현저하게 떨어진다면, 모델이 overfitting되었다고 볼 수 있습니다. 따라서, 모델을 평가할 때는, accuracy와 val_accuracy 모두를 고려하여야 합니다.
-
loss랑 val_loss의 차이?
- 일반적으로 학습과정에서 모델의 성능을 평가할 때, validation loss와 validation accuracy가 더 중요합니다. 따라서 validation loss는 낮을수록 좋습니다.
- 일반적으로 overfitting이 발생하지 않은 경우 validation loss는 train loss와 비슷하거나 낮은 값을 보여주며, overfitting이 발생하면 train loss는 낮아지고 validation loss는 높아집니다. 이때 validation loss가 train loss보다 높아지는 지점이 overfitting이 시작되는 시점입니다. 따라서 validation loss가 train loss에 비해 일정 비율 이상 높아지면 overfitting이 발생한 것으로 판단할 수 있습니다.
결론: 넷을 비교해서 overfitting의 여부를 판단할 수 있음
#만든 모델 저장
model.save('cats_dogs_basic_cnn_1.h5')
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
#만든 모델 검증
epoch_list = list(range(1,11))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 11, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 11, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
1-5 모델 검증
#model.predict는 왜하는지?
model1_out = model.predict(test_imgs_scaled)
#모델 정확도 평가
model.evaluate(test_imgs_scaled, test_label)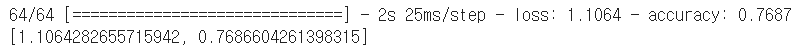
-> 기존 CNN 모델의 경우 정확도가 77% 정도 나옴
2. Dropout 적용하기
2-1 Dropout의 개념
- Dropout이란?

-
Drop out은 Alexnet이라는 딥러닝모델에서 처음 제안된 기술
-
기존까지 사용하고 있던 Neural netwoek방식은 FCNN(Fully Connected Neural Network)로써, 모든 노드들이 전부 연결되어있음
-
이에 반해 Drop Out 방식은 오른쪽 그림처럼, 중간중간의 노드들을 죽여버리고 랜덤하게 연결해 학습을 진행하는 방식임
-
딥러닝은 항상 왜?보다는 더 좋은 성능의 방법이 뭐야?로 접근하는 학문,,, 따라서 훨씬 더 좋은 성능을 보여준 Drop Out을 보통 사용하고 있음.
- 이 기술은 연산량이 많은 CNN에서 특히 엄청난 성능 효과를 보임. 연산량 감소와 성능 증가를 모두 잡는 기술이어서 많이 사용되어지는 중
-
주의해야 할 점은, 학습할때는 Drop out을 해주지만, 검증할때는 Drop out이 없는 FCNN 상태로 진행해야함 !
<참고>
https://limitsinx.tistory.com/45
2-2 모델 설계(drop out)
model2 = Sequential()
model2.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Flatten())
model2.add(Dense(512, activation='relu'))
model2.add(Dropout(0.3))
model2.add(Dense(512, activation='relu'))
model2.add(Dropout(0.3))
model2.add(Dense(1, activation='sigmoid'))
model2.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model2.summary()- 앞서 기존 모델과 모델 설계에 있어 차이점: 평탄화 작업 후 입출력층 사이에
model2.add(Dropout(0.3))라는 구문을 입력함. 이는 30%의 노드를 무작위로 제거(dropout)해 오버피팅(overfitting)을 방지하는 함수를 추가하겠다라는 의미 -> 과적합 방지를 위한 dropout 실행
2-3 모델 실행(drop out)
history = model2.fit(x=X_train, y=y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=20,
verbose=1)
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,21))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 21, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 21, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")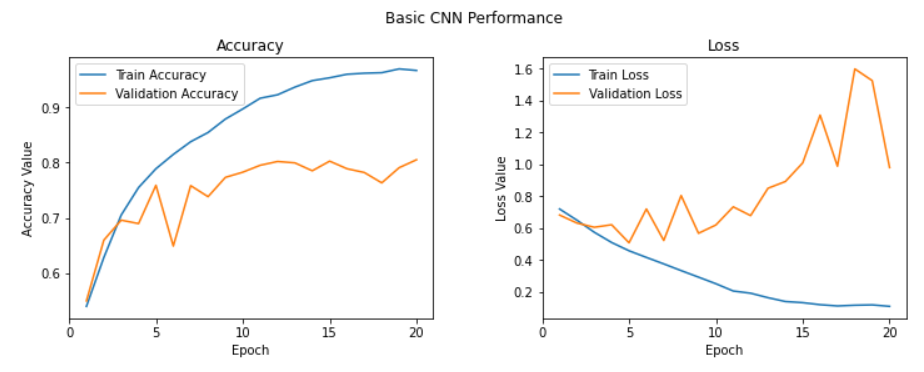
2-4 모델 검증(drop out)
model2.save('cats_dogs_basic_cnn_2.h5')
model2.evaluate(test_imgs_scaled, test_label)
-> 정확도 81%로 향상
3. 전이학습 적용하기
3-1 전이학습 개념
-
전이 학습이란?
전이학습(Transfer learning)은 어떤 목적을 이루기 위해 학습된 모델을 다른 작업에 이용하는 것을 말합니다. 즉 모델의 지식을 다른 문제에 이용하는 것으로 볼 수 있습니다. 아래 그림은 간단한 전이 학습이 사용되는 예시를 나타내고 있습니다.
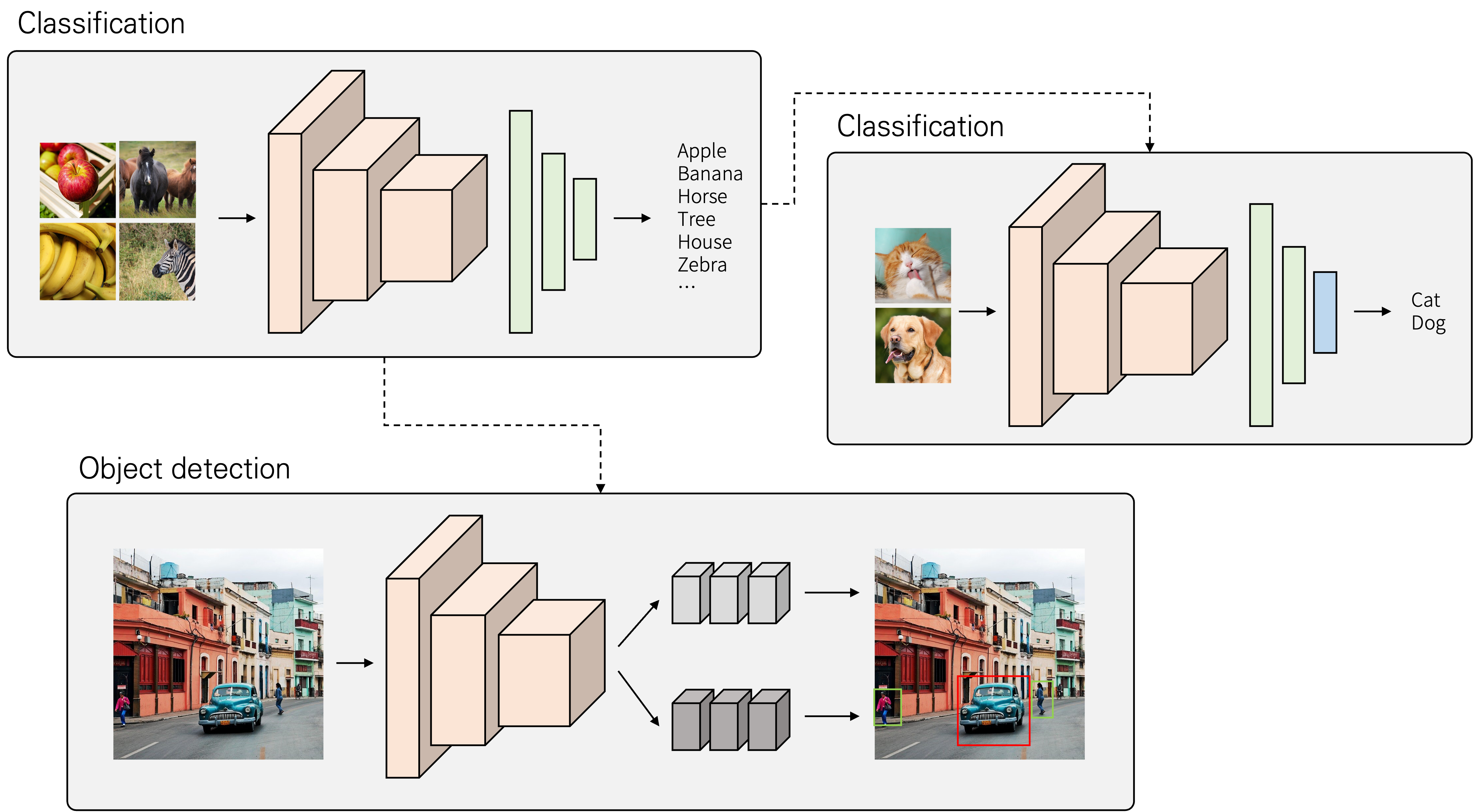
-
전이 학습을 수행하기 위해서는 학습된 모델이 필요합니다. 여기서는 1000개의 클래스로 구별하기 위해 큰 데이터셋으로 학습된 모델을 사용하고자 합니다. 그리고 개와 고양이를 분류하기 위해 새로운 작은 데이터셋을 준비해 학습할 때, 학습된 모델을 모두 가져오고, 제일 마지막 레이어만 새로 학습을 할 수 있습니다.
-
전이학습의 아이디어는 고립된 학습 패러다임을 극복하고 하나의 과제에서 습득한 지식을 활용해 관련된 새로운 과제를 해결하자는 것
-
전이학습은 사람이 여러 과제를 넘나들면서 지식을 활용하는 것보다 직접적이고 한 단계 더 발전된 방식으로 데이터를 배워 나갑니다.
-
따라서 전이학습은 다른 관련된 과제에 대한 지식이나 모델을 재사용하는 하나의 방법
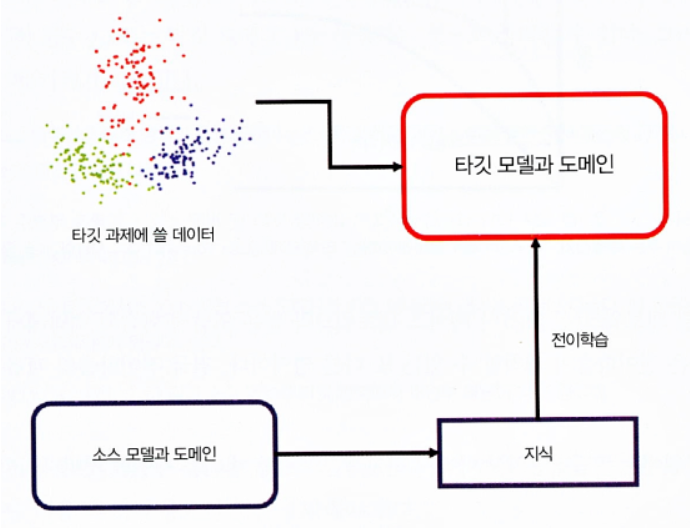
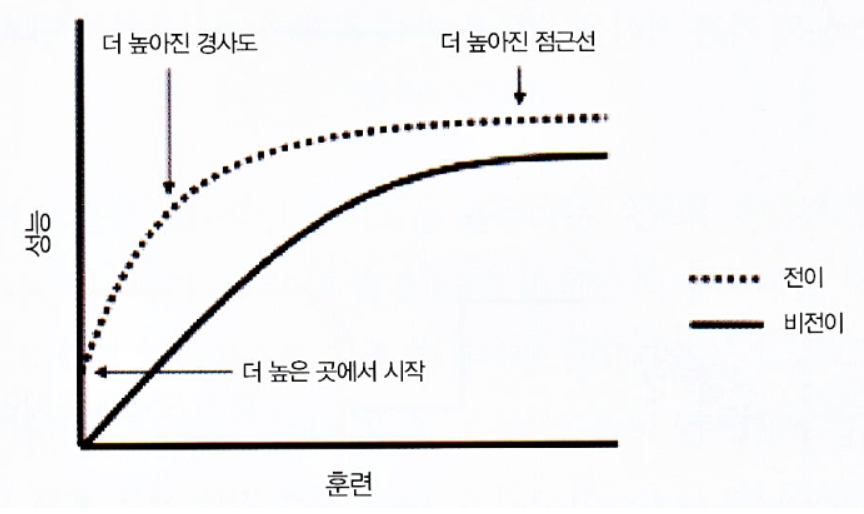
전이 학습을 사용하는 이유
큰 데이터셋을 활용해 학습을 할 때 얻은 지식을 활용했을 때 다음과 같은 장점들이 있습니다.
-
학습이 빠르게 수행될 수 있습니다. 이미 입력되는 데이터에 대해 특징을 효율적으로 추출하기 때문에, 학습할 데이터에 대해 특징을 추출하기 위한 학습을 별도로 하지 않아도 되기 때문입니다.
-
작은 데이터셋에 대해 학습할 때 오버피팅을 예방할 수 있습니다. 적은 데이터로 특징을 추출하기 위한 학습을 하게 되면, 데이터 수에 비해 모델의 가중치 수가 많을 수 있어 미세한 특징까지 모두 학습할 수 있습니다. 전이 학습을 이용해 마지막 레이어만 학습하게 한다면, 학습할 가중치 수가 줄어 과한 학습이 이루어지지 않게 할 수 있습니다.
전이학습의 방법
특성 추출
- 딥러닝의 체계는 서로 다른 층에서 서로 다른 특성을 학습하는 층이 있는 아키텍처
- 이 층은 최종 출력을 얻기 위해 마지막 층(분류의 경우 보통 전체가 연결된 층)에 연결
- 이 층 아키텍처 덕분에 최종 층에서 고정된 특성 추출기 없이 사전 훈련된 네트워크(V3 or VGG같은 모델)를 활용해 작업할 수 있다.
- 아래 그림은 특성 추출을 기반으로 한 심층 전이를 표현한 것
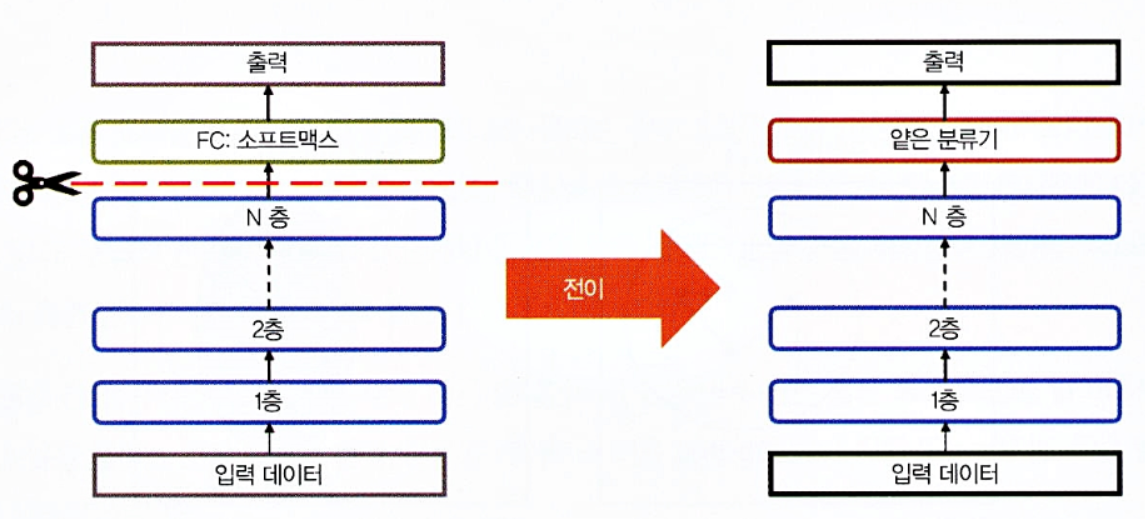
미세 조정
전이 학습을 하기 위해서는 학습된 모델과 새로 학습할 데이터셋이 필요합니다. 여기서 학습된 모델을 만드는 과정을 사전 학습(pre-training)이라고 합니다.
- 미세 조정(fine -turning)은 좀 더 복잡한 기술로, 단순히 최종 층을 대체하는 것뿐만 아니라 이전층의 일부를 선택적으로 재훈련시키기도 함
- 심층 신경망은 다양한 하이퍼 파라미터를 통해 변경이 가능한 아키텍처
- 초기 층은 일반적인 특성을 포착하는 반면, 나중 층은 특정 작업에 더 초점을 맞춤
- 재훈련하는 동안 특정 층을 고정(가중치를 고정)하거나 필요에 맞게 나머지 층을 미세 튜닝 가능
- 이 경우 네트워크의 전체 아키텍처 지식을 활용해 재훈련 단계의 시작점으로 사용합. 결국, 이는 더 적은 학습 시간으로 더 나은 성과를 달성하는데 도움이 됨
전이 학습이 잘 되기 위한 조건
사전 학습된 모델은 새로 학습할 데이터에도 적용할 수 있는 지식을 추출할 수 있어야 합니다. 전이 학습이 잘 이루어지기 위해 사전 학습된 모델의 조건은 크게 두 가지가 있습니다.
-
사전 학습에 사용한 데이터와 새로운 데이터가 비슷한 형태를 가지고, 새로 학습할 데이터에도 비슷한 특징을 활용할 수 있어야 합니다. 많이 다른 형태의 데이터를 사전 학습된 모델에 적용한다고 해도 특징의 재추출이 필요할 것이기 때문입니다.
-
일반적으로 새로운 데이터보다 많은 데이터로 사전 학습이 수행되었어야 합니다. 새로운 데이터가 사전 학습에 사용된 데이터가 많으면, 해당되는 지식의 의미 자체가 없어질 수 있기 때문입니다.
<참고>
3-2 전이학습 시 활용할 모델(VGG-Visual Geometry Group)
VGG(Visual Geometry Group)
- VGG-16 모델로 옥스퍼드 대학의 VGG가 만든 것이다.
- 이 그룹은 대규모 시각 인지를 위한 심층 합성곱 네트워크 구축에 특화돼 있다.
- 이미지넷 대규모 시각 인지 대회(ILSVRC)는 대규모 객체 탐지와 이미지 분류를 위한 알고리즘을 평가하는데, VGG의 이 모델이 이 콘테스트에서 자주 1등을 차지했다.
- VGG-16과 같은 사전 훈련 모델은 이미지넷의 다양한 이미지 범주가 포함된 거대한 데이터 세트에서 이미 훈련된 모델이다.
- VGG-16 모델의 이해
- 이지멧 데이터베이스에 구축된 16계층 네트워크
- 이미지넷 데이터베이스는 이미지 인식과 분류를 목적으로 제작되었습니다.
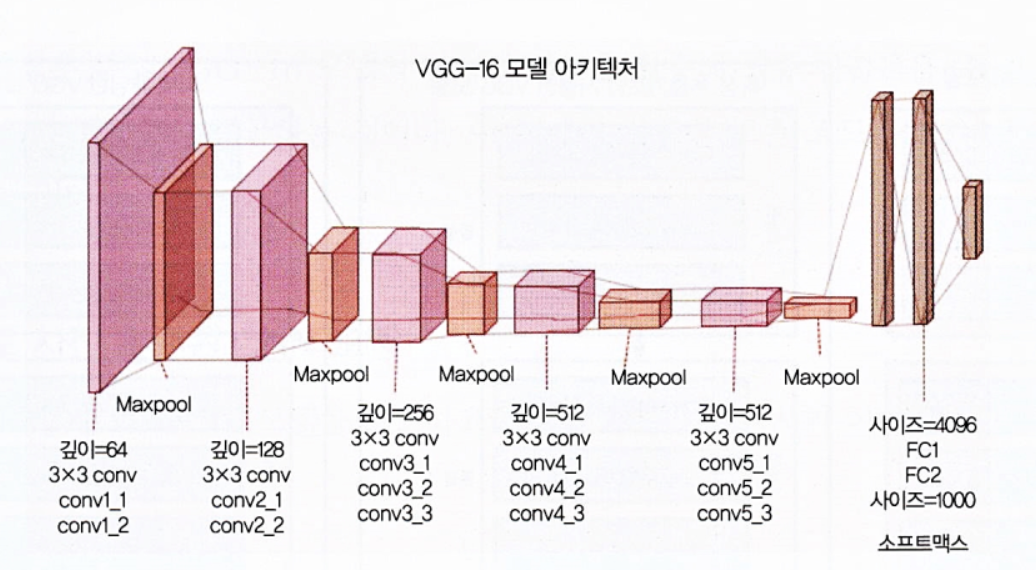
- 3x3 합성곱 필터로 이루어진 총 13개의 합성곱층은 다운 샘플링을 위한 최대 풀링층, 4096유닛과 전체가 연결된 2개의 은닉층, 그리고 연속된 1000개 유닛의 밀집층이로 이루어짐
- 여기서는 전체가 연결된 밀집층에서 이미지가 개인지 고양이인지만 예측할 것이기 때문에 마지막 세개의 층은 필요 없습니다.
- 처음 5개 블록에만 더 신경을 써서 VGG 모델을 효과적인 특성 추출기로 활용하겠습니다.
- 모델 하나에서는 각 에포크 후에 가중치가 업데이트되지 않도록 5개의 모든 합성곱 블록을 동결시켜서 간단한 특성 추출기로 사용합니다.
- 마지막 모델의 경우, 동결하지 않은 끝의 두 블록(블록4와 블록5)의 VGG 모델에 미세튜닝을 적용해서 모델을 훈련할 때(데이터 배치당) 각 에포크에서 가중치가 업데이트되도록 할 것
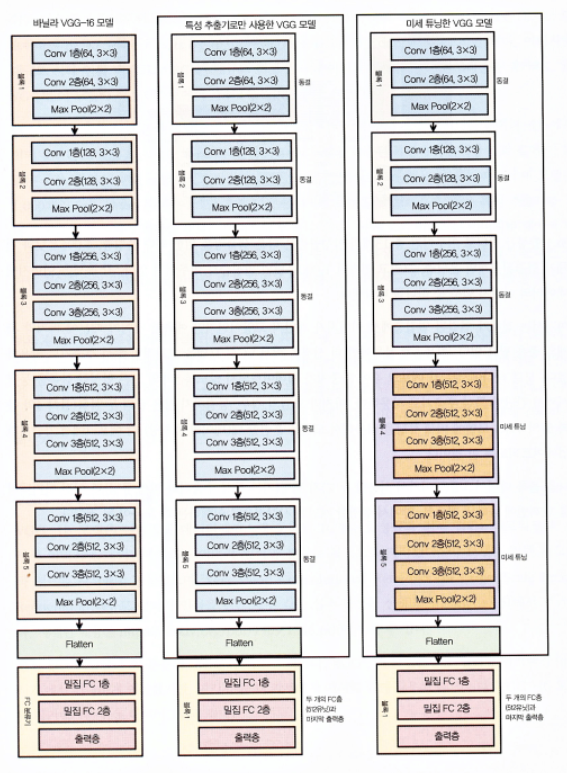
3-3 모델 설계(전이학습-VGG)
from tensorflow.keras.applications import vgg16 as vgg
base_model = vgg.VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
# VGG16 모델의 세 번째 블록에서 마지막 층 추출
last = base_model.get_layer('block3_pool').output
from tensorflow.keras.layers import Dropout, Flatten, Dense, GlobalAveragePooling2D,BatchNormalization
from tensorflow.keras import Model
# 전이학습을 통해 새로운 분류기를 추가하는 과정
x = GlobalAveragePooling2D()(last)
#이 층의 출력값을 입력으로 받는 새로운 분류기를 만들기 위해, GlobalAveragePooling2D 레이어를 추가
x= BatchNormalization()(x)
#입력값의 평균과 분산을 조정하여, 그래디언트 소실 문제를 해결하고 모델의 안정성을 높이는 모델을 레이어에 추가
x = Dense(256, activation='relu')(x)
x = Dense(256, activation='relu')(x)
#출력 뉴런의 수를 256개로 지정하고, 활성화 함수로 ReLU를 사용하는 레이어 추가
x = Dropout(0.6)(x)
#60%의 뉴런을 무작위로 선택하여 제거, 이를 통해 모델의 일반화 성능을 높이고 과적합을 방지
pred = Dense(1, activation='sigmoid')(x)
#출력 뉴런의 수를 1개로 지정하고, 활성화 함수로 시그모이드 함수를 사용. 이를 통해 이진분류모델 해결
model3 = Model(base_model.input, pred)
#Model 함수를 사용하여 base_model의 입력과 새로운 분류기를 연결하여 새로운 모델인 model3을 생성
for layer in base_model.layers:
layer.trainable = False
model3.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(lr=0.01),
metrics=['accuracy'])
model3.summary()-
전이학습 시 VGG16 모델의 세 번째 블록에서 마지막 층만 추출하는 이유는 ?
VGG16 모델의 마지막 층인 fully connected layer는 1000개의 클래스를 분류하기 위해 학습되었기 때문에, 이 층을 그대로 사용할 경우 새로운 문제에 적용하기가 어려울 수 있습니다. 따라서 일반적으로는 전이학습에서 출력층을 제외한 모든 층의 가중치를 동결(freeze)시키고, 새로운 데이터셋에 맞는 출력층을 새롭게 추가하여 fine-tuning하는 것이 보다 효과적입니다.
그리고 VGG16 모델의 세 번째 블록에서 마지막 층은 14x14x512 사이즈의 출력을 내기 때문에, 이 출력을 feature로 사용할 경우 새로운 데이터셋에서 좀 더 일반화된 특징을 추출하기에 적합합니다. 또한 이렇게 한 번 feature를 추출한 후에는, 새로운 데이터셋에 따라 출력층을 수정하는 일만으로도 새로운 분류 모델을 만들 수 있기 때문에 보다 빠르고 쉽게 모델을 개발할 수 있습니다. -
for layer in base_model.layers:
layer.trainable = False위 코드는 VGG16 모델의 모든 층을 동결(freeze)하는 역할을 합니다. 동결된 층은 모델 학습 시 가중치가 업데이트되지 않으므로, 모델 파라미터가 고정됩니다. 따라서 전이학습에서 동결된 층은 미리 학습된 특징을 추출하는 역할을 하며, 모델의 나머지 부분(출력층 등)은 새로운 데이터에 맞게 학습됩니다. 이는 새로운 데이터셋에서 과적합(overfitting)을 방지하고, 더 높은 성능을 내기 위한 전략 중 하나입니다.
3-4 모델 실행(전이학습-VGG)
history = model3.fit(x=X_train, y=y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=20,
verbose=1)
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,21))
ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 21, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 21, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")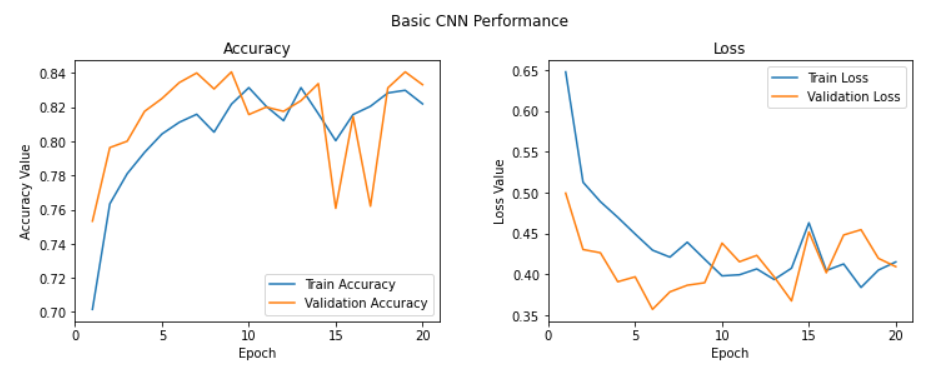
3-5 모델 검증(전이학습-VGG)
model3.evaluate(test_imgs_scaled, test_label)
model3.save('cats_dogs_basic_cnn_3.h5')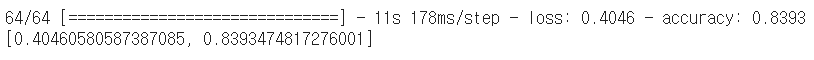
-> 모델 정확도 84%로 가장 향상
