stable diffusion
https://github.com/camenduru/stable-diffusion-webui-colab
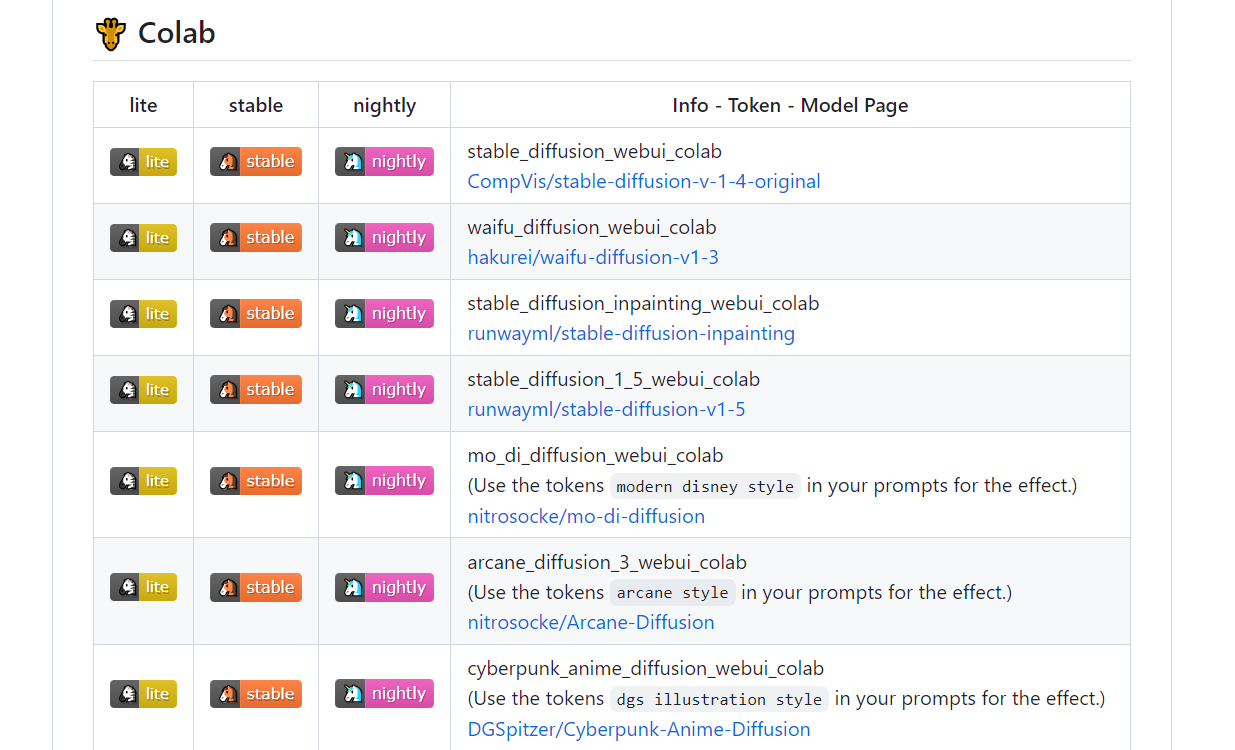
위의 github 링크로 들어가서 아래로 스크롤을 내리면 google colab에서 실행가능한 코드가 나온다. 이 중 맨 위 stable(가운데꺼) 클릭 !
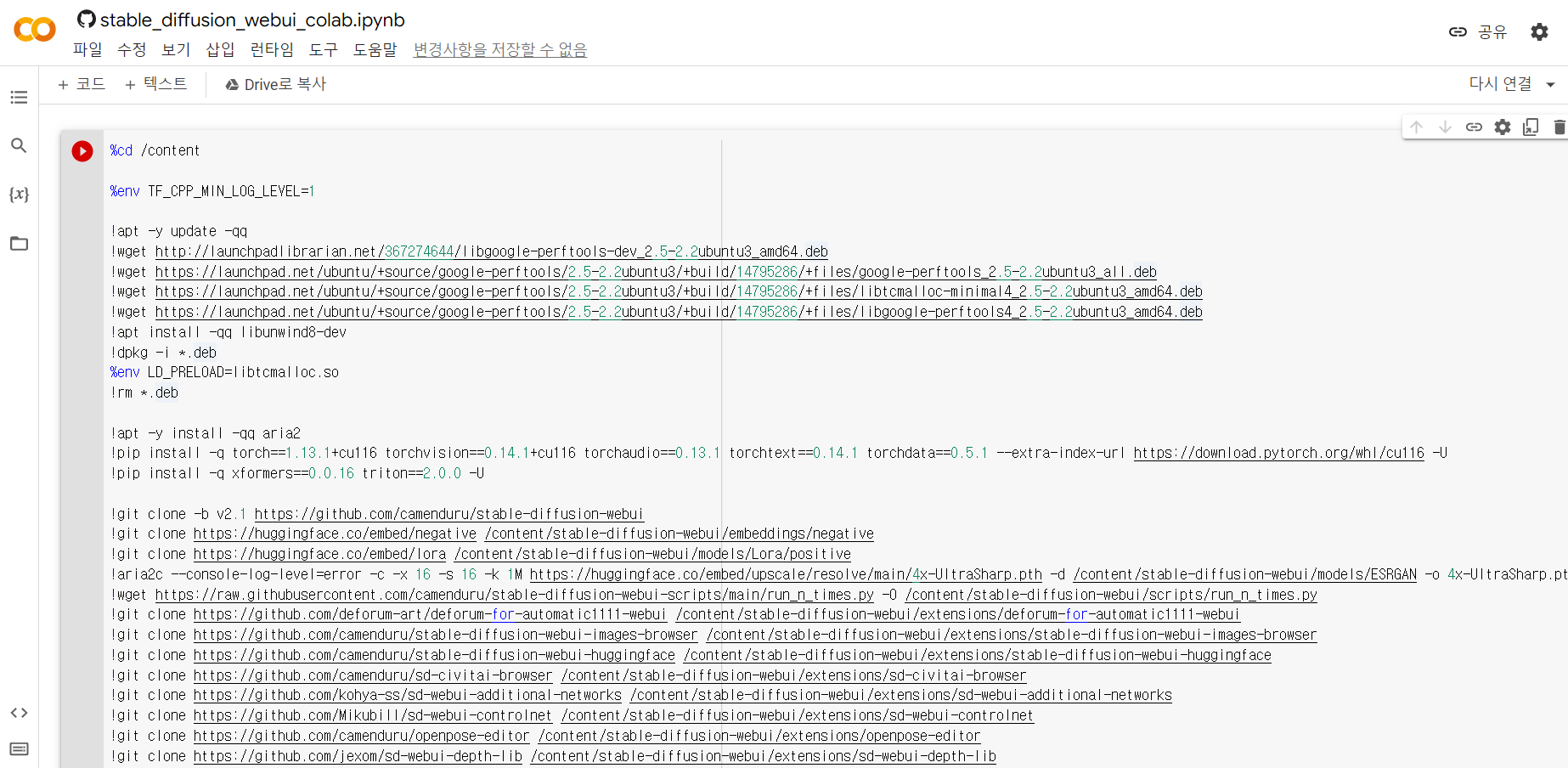
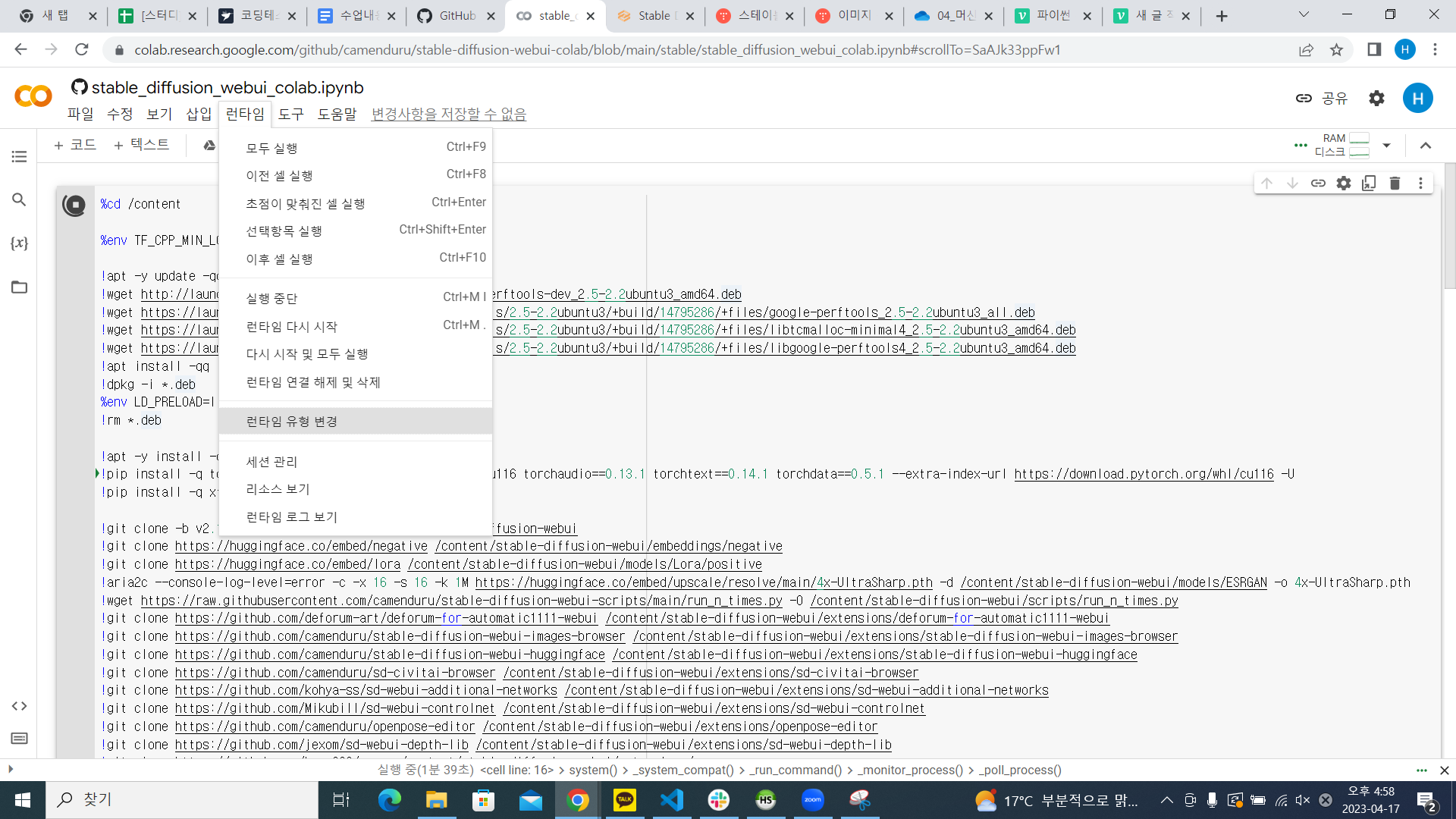
코랩 실행 시 결과 화면에서 두번째 링크 클릭

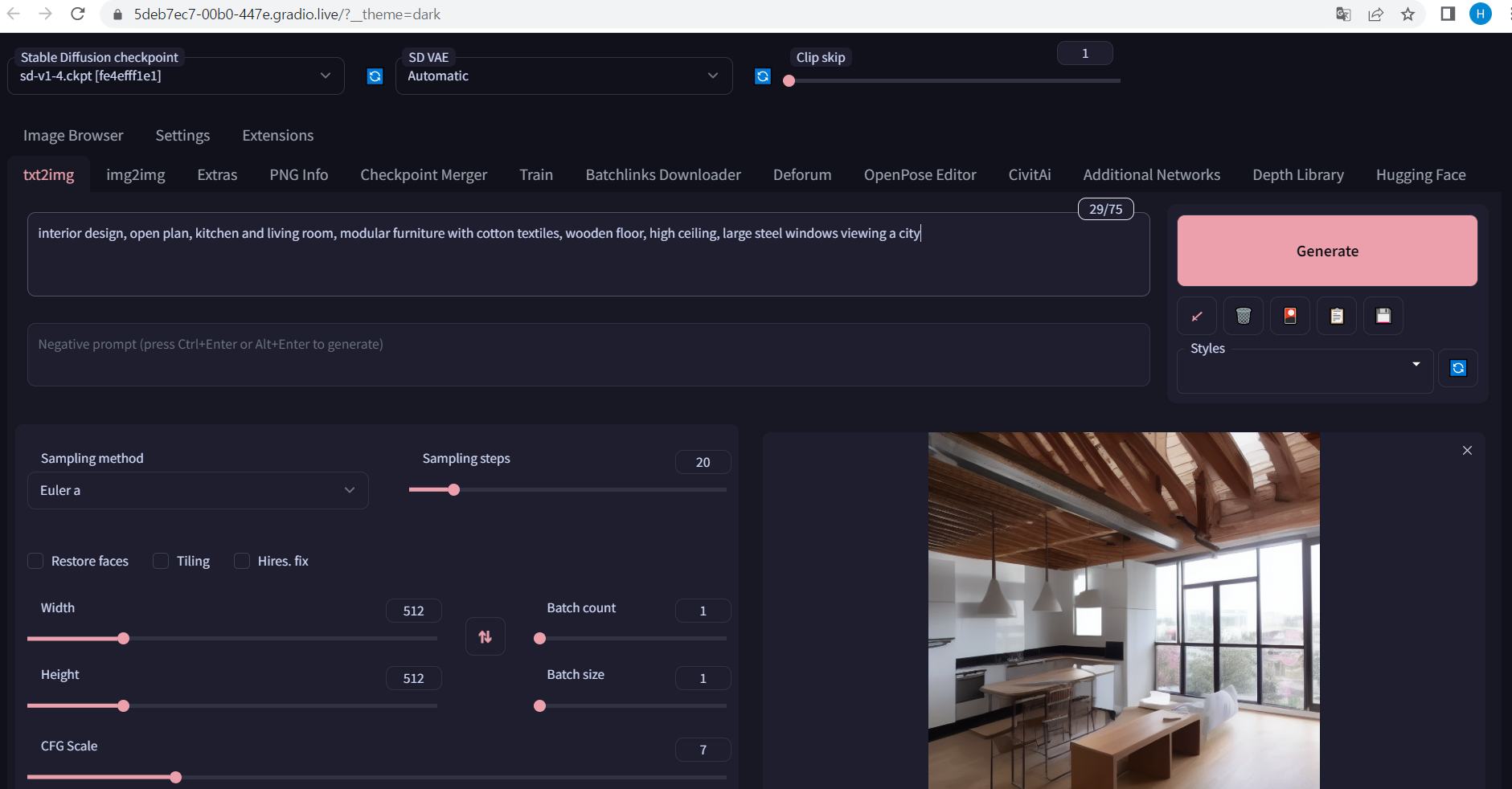
위의 창에서 prompt에 검색하고 싶은 이미지를 표현하는 단어 입력 시
머신러닝을 통해 만든 이미지를 보여줌
basic CNN Model
import glob
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_imgIMG_DIM = (150, 150)
train_dogs_files = glob.glob(r'.\dog_cat\training_set\training_set\dogs\*.jpg')
train_cats_files = glob.glob(r'.\dog_cat\training_set\training_set\cats\*.jpg')
train_dogs_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_dogs_files]
train_cats_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_cats_files]train_imgs = np.concatenate((np.array(train_dogs_imgs), np.array(train_cats_imgs)))
train_dogs_label = np.ones(len(train_dogs_imgs))
train_cats_label = np.zeros(len(train_cats_imgs))
train_label = np.concatenate((train_dogs_label, train_cats_label))from matplotlib import pyplot as plt
from PIL import Image
img = Image.open(r".\dog_cat\training_set\training_set\cats\cat.1.jpg")
img.show()
#PIL은 이미지를 출력할때 많이 활용하는 라이브러리
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(train_imgs, train_label, test_size=0.2, random_state = 42)
#val는 검증데이터로 쓸 용도
X_train_scaled = X_train.astype('float32')
X_train_scaled /= 255
X_val_scaled = X_val.astype('float32')
X_val_scaled /= 255# 모델 설계
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
# 하이퍼파라미터 값 설정
batch_size = 30
num_classes = 2
epochs = 30
input_shape = (150, 150, 3)
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model.summary()#출력 결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 16) 448
max_pooling2d (MaxPooling2D (None, 74, 74, 16) 0
)
conv2d_1 (Conv2D) (None, 72, 72, 64) 9280
max_pooling2d_1 (MaxPooling (None, 36, 36, 64) 0
2D)
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
max_pooling2d_2 (MaxPooling (None, 17, 17, 128) 0
2D)
flatten (Flatten) (None, 36992) 0
dense (Dense) (None, 512) 18940416
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 19,024,513
Trainable params: 19,024,513
Non-trainable params: 0
_________________________________________________________________#모델 학습
history = model.fit(x=X_train_scaled, y=y_train,
validation_data=(X_val_scaled, y_val),
batch_size=batch_size,
epochs=epochs,
verbose=1)Epoch 1/30
214/214 [==============================] - 184s 852ms/step - loss: 0.6908 - accuracy: 0.5784 - val_loss: 0.6259 - val_accuracy: 0.6602
Epoch 2/30
214/214 [==============================] - 179s 835ms/step - loss: 0.5887 - accuracy: 0.6924 - val_loss: 0.5837 - val_accuracy: 0.6902
Epoch 3/30
214/214 [==============================] - 179s 837ms/step - loss: 0.5240 - accuracy: 0.7278 - val_loss: 0.4970 - val_accuracy: 0.7533
Epoch 4/30
214/214 [==============================] - 190s 887ms/step - loss: 0.4688 - accuracy: 0.7745 - val_loss: 0.6284 - val_accuracy: 0.6939
Epoch 5/30
214/214 [==============================] - 182s 850ms/step - loss: 0.4147 - accuracy: 0.8086 - val_loss: 0.4708 - val_accuracy: 0.7770
Epoch 6/30
214/214 [==============================] - 191s 891ms/step - loss: 0.3505 - accuracy: 0.8403 - val_loss: 0.5456 - val_accuracy: 0.7377
Epoch 7/30
214/214 [==============================] - 187s 877ms/step - loss: 0.2743 - accuracy: 0.8835 - val_loss: 0.4846 - val_accuracy: 0.7889
Epoch 8/30
214/214 [==============================] - 181s 846ms/step - loss: 0.1755 - accuracy: 0.9316 - val_loss: 0.5730 - val_accuracy: 0.7695
Epoch 9/30
214/214 [==============================] - 177s 830ms/step - loss: 0.1002 - accuracy: 0.9639 - val_loss: 0.6314 - val_accuracy: 0.7776
Epoch 10/30
214/214 [==============================] - 176s 821ms/step - loss: 0.0660 - accuracy: 0.9789 - val_loss: 0.9279 - val_accuracy: 0.7683
Epoch 11/30
214/214 [==============================] - 173s 807ms/step - loss: 0.0435 - accuracy: 0.9858 - val_loss: 1.1253 - val_accuracy: 0.7639
Epoch 12/30
214/214 [==============================] - 172s 803ms/step - loss: 0.0273 - accuracy: 0.9906 - val_loss: 1.1585 - val_accuracy: 0.7814
Epoch 13/30
214/214 [==============================] - 172s 805ms/step - loss: 0.0240 - accuracy: 0.9928 - val_loss: 1.2120 - val_accuracy: 0.7776
Epoch 14/30
214/214 [==============================] - 173s 808ms/step - loss: 0.0237 - accuracy: 0.9928 - val_loss: 1.2548 - val_accuracy: 0.7864
Epoch 15/30
214/214 [==============================] - 173s 810ms/step - loss: 0.0185 - accuracy: 0.9939 - val_loss: 1.4499 - val_accuracy: 0.7733
Epoch 16/30
214/214 [==============================] - 172s 802ms/step - loss: 0.0117 - accuracy: 0.9978 - val_loss: 2.6514 - val_accuracy: 0.7283
Epoch 17/30
214/214 [==============================] - 172s 805ms/step - loss: 0.0226 - accuracy: 0.9936 - val_loss: 1.4799 - val_accuracy: 0.7851
Epoch 18/30
214/214 [==============================] - 173s 808ms/step - loss: 0.0146 - accuracy: 0.9950 - val_loss: 1.5890 - val_accuracy: 0.7795
Epoch 19/30
214/214 [==============================] - 173s 808ms/step - loss: 0.0162 - accuracy: 0.9944 - val_loss: 1.7416 - val_accuracy: 0.7758
Epoch 20/30
214/214 [==============================] - 173s 806ms/step - loss: 0.0184 - accuracy: 0.9933 - val_loss: 1.7413 - val_accuracy: 0.7720
Epoch 21/30
214/214 [==============================] - 174s 813ms/step - loss: 0.0120 - accuracy: 0.9964 - val_loss: 1.8902 - val_accuracy: 0.7814
Epoch 22/30
214/214 [==============================] - 173s 808ms/step - loss: 0.0150 - accuracy: 0.9961 - val_loss: 2.3505 - val_accuracy: 0.7701
Epoch 23/30
214/214 [==============================] - 173s 809ms/step - loss: 0.0152 - accuracy: 0.9958 - val_loss: 2.1114 - val_accuracy: 0.7695
Epoch 24/30
214/214 [==============================] - 173s 809ms/step - loss: 0.0082 - accuracy: 0.9964 - val_loss: 2.2899 - val_accuracy: 0.7633
Epoch 25/30
214/214 [==============================] - 173s 811ms/step - loss: 0.0096 - accuracy: 0.9973 - val_loss: 2.2120 - val_accuracy: 0.7695
Epoch 26/30
214/214 [==============================] - 174s 813ms/step - loss: 0.0110 - accuracy: 0.9963 - val_loss: 2.0620 - val_accuracy: 0.7620
Epoch 27/30
214/214 [==============================] - 173s 806ms/step - loss: 0.0131 - accuracy: 0.9970 - val_loss: 2.4283 - val_accuracy: 0.7570
Epoch 28/30
214/214 [==============================] - 179s 835ms/step - loss: 0.0258 - accuracy: 0.9939 - val_loss: 2.4736 - val_accuracy: 0.7701
Epoch 29/30
214/214 [==============================] - 190s 887ms/step - loss: 0.0100 - accuracy: 0.9967 - val_loss: 2.3406 - val_accuracy: 0.7726
Epoch 30/30
214/214 [==============================] - 186s 869ms/step - loss: 0.0107 - accuracy: 0.9972 - val_loss: 2.4030 - val_accuracy: 0.7751
->학습하는 과정 출력 대략 1시간 가량 소요
공부합시당