Level2 P-Stage 영화 추천 대회 회고
드디어 4주 간의 Level2 P-Stage 영화 추천 대회가 끝났다. 대회 기간 동안 다양한 실험을 진행했고 프로젝트를 진행하면서 배운 것도 많아서 회고글을 작성하려고 한다.
1. 프로젝트 소개

위 그림에서 하나의 행이 유저의 영화 평가 Sequence이라고 한다면, 이 Sequence를 가지고 각 유저가 선호할 10개의 영화를 예측하는 것이 본 프로젝트의 목표였다.
본 프로젝트에서 주어진 데이터는 Implicit Feedback으로 이루어졌고, sparsity ratio는 97.6%로 꽤 dense한 데이터였다.
2. 프로젝트 수행 절차
- 효과적인 Validation Set 구축
- 유저 별로 10개의 영화를 random sampling하여, 주어진 Task와 비슷한 validation set을 구축했다.
- 실제로 validation set에서 성능이 오르면 리더 보드에서도 동일하게 성능이 오르는 것을 확인하였고, 이 덕분에 빠르게 다양한 모델의 성능 평가와 피드백이 가능했다.
- 효과적으로 validation set을 구축한 덕분에 다른 팀 보다 훨씬 삐르게 0.16을 넘을 수 있었던 것 같다. 추가로 대회 종료 3일 전 까지 계속 1등을 유지했다.
- 모델 선정
- 본 대회에서 실험한 모델은 크게 MLP, GNN, Transformer, AutoEncoder 기반의 모델이다.
- MLP 기반의 모델은 MLP Layer를 이용해 유저-아이템 상호 작용을 표현할 수 있는 함수를 모델링하여, 해당 아이템의 선호 확률을 예측 하는 모델이다. 본 모델은 BPR을 활용하여 모델을 학습시키기 때문에 full-ranking 계산에 많은 시간이 걸렸다.
- GNN 기반의 모델은 영화와 유저를 node로 하는 이분 그래프를 이용해, 유저간의 상호 작용을 Layer로 모델링하여 영화와 유저 임베딩을 학습시키고, 학습된 임베딩을 바탕으로 유사한 영화를 추천해주는 모델이다. 본 모델 또한 BPR을 활용하여 모델을 학습시키기 때문에 full-ranking 계산에 많은 시간이 걸렸다.
- Transformer 기반의 모뎅은 유저의 영화 평가 Sequence를 Embedding하여 미래에 유저가 선호할 영화를 예측하는 모델이다. 본 모델 또한 BPR을 활용하여 모델을 학습시키기 때문에 full-ranking 계산에 많은 시간이 걸렸다.
- AutoEncoder 기반의 모델은 유저-아이템 상호작용 데이터를 복원할 수 있는 Parameterized Function을 만들어, 복원된 유저-아이템 상호작용 데이터을 이용해 Top-N개의 아이템을 추천해주는 모델이다. 본 모델은 한번 학습에 유저의 전체 Sequence를 행렬 형태로 사용하기 때문에 학습이 다른 모델 보다 월등히 빨랐다.
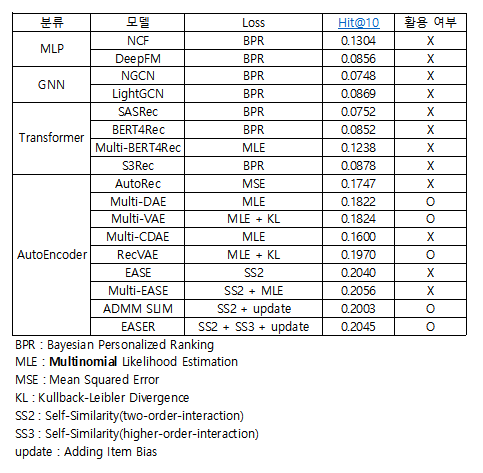
- 목적 함수 선정
- 내가 사용한 목적 함수는 크게 BPR과 Multinomial Likelihood 이다.
- BPR을 사용하는 모델들은 대체적으로 성능이 좋지 않았는데, 그 이유는 아마 pair-wise 방식의 특성상 긍정과 긍정, 부정과 부정 아이템 간의 Ranking을 고려할 수 없었기 때문이라고 생각했다.
- Multinomial Likelihood를 사용하는 모델들이 대부분의 경우에서 성능이 좋았는데, 그 이유는 아마 list-wise 방식의 특성상 전체 아이템의 Ranking을 고려하여 모델을 학습이 가능하고, 이 방식이 Top-N Ranking을 뽑아야 하는 우리의 Task와 매우 동일했기 때문이라고 생각한다.
- 실제로 BERT4Rec을 변형한 Multi-BERT4Rec을 만들었을 때도 성능 향상과 학습 시간 단축이라는 결과를 얻을 수 있었다.
- 데이터 특성 파악
- AutoEncoder 기반 모델의 경우 모델이 복잡할 수록 성능이 하락한다는 것을 발견했는데, 이를 통해서 현재 주어진 데이터의 user-item 간의 interaction이 매우 복잡하지 않다는 생각을 했다.
- 이에 단순한 모델로도 충분히 본 데이터를 표현할 수 있다고 생각하여, 선형 결합으로 item-item similarity 표현하는 EASE 모델을 실험했고, 결과적으로 AutoEncoder 기반 모델보다 이상의 더 우수한 성능을 보였다.
- 추가로 파악한 데이터 특성을 바탕으로 파라미터 튜닝 시 Layer는 더 얕게, 규제는 더 강하게 줌으로써 모든 모델의 성능을 향상 시켰다.
- re-ranking
- 모델 별 후보 집단을 뽑고, 해당 후보 집단의 합집합으로 hit를 확인했을 때 10개 중에 3개의 아이템이 본 후보 집단 안에 들어있다는 것을 확인했다. 그래서 본 후보 집단 내에서 개인화 re-ranking을 적용하기 위한 방법을 고민했다.
- MF 모델을 통해서 Item Embedding을 만들어 ML 모델의 feature로 활용하는 방식, 유저별로 ML 모델을 만들어 re-ranking을 하는 방식 등 다양한 re-ranking을 시도했지만, 단순히 모델 별로 아이템 score 값을 계산하여 sum을 하는 방식의 성능을 넘지 못했다.(주어진 데이터에서 사용할 수 있는 feature가 너무 적어 아쉬움)
- 모델 별 candidate 아이템의 순위를 바탕으로 1 / log2(rank + 1)을 계산하여 모델 별 아이템 score 값을 구했고(log 함수의 특성 덕분에 단순한 1/rank 보다 조금 더 스무스한 점수가 매겨짐), score 값을 sum하여 candidate 집단에서 re-ranking을 진행했다.
- 추가로 모든 모델이 동일한 가중치와 신뢰도를 가지는 것은 아니라고 생각하여, 모델 별로 가중치를 두어 re-ranking을 했고(MF 논문에 Confidence-level에서 영감을 얻음) 더 높은 성능을 얻었다.
- 거기에 실험한 모델 중 가장 효과적인 조합을 찾기 위해 Model Best Combination Serch를 진행하여 더 높은 성능을 얻었다.
3. 프로젝트 수행 결과
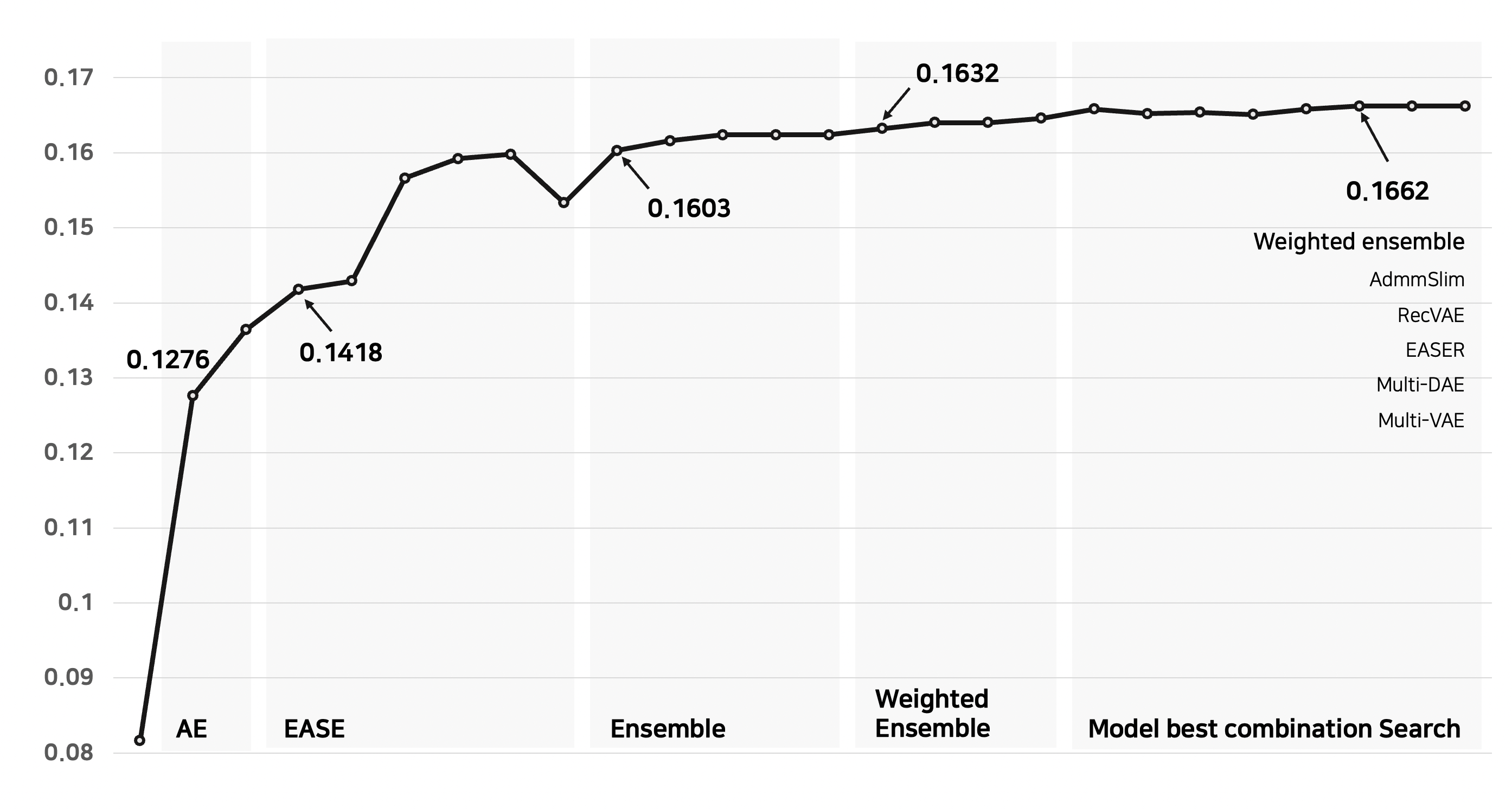
- 상위 3팀과 달리 우리 팀은 Sequence 모델을 사용하지 않았고, public - 3위 (0.1662) / private - 4위 (0.1663) 에 성적을 얻었다. (만약 Sequence 모델을 사용했다면, 더 높은 성적을 얻었을 수도?)
4. 새롭게 배운 내용
- 검증 데이터 셋에서 성능이 좋지 않은 모델이라도, 서로 다른 특성을 가진 모델이라면 다양성 측면에서 같이 Ensemble을 하는 것이 좋다는 것을 이번 대회를 통해서 배웠고, 다음 부터는 이를 인지하여 성능 보다는 모델의 특성을 고려한 Ensemble을 시도해볼 예정이다.(근데 데이터 샘플링 방법 때문에 본 대회에만 해당하는 방식일 수도 있음)

Machine Learning Engineer at Konan Technology