Sequential Model
이번 강에서는 Sequential Model 중 Recurrent Neural Network, Long Short Term Memory, Gated Recurrent Unit에 대하여 학습을 진행했다.
00. 학습 내용
- Recurrent Neural Network에 대하여 학습
- Long Short Term Memory에 대하여 학습
- Gated Recurrent Unit에 대하여 학습
01. Recurrent Neural Network
- Sequential Data를 다루는데 중요한 키포인트는 나의 현재는 과거의 정보에 영향을 받는다는 것이다. 따라서 Sequential Data를 다루는 Sequential Model은 과거의 정보를 다룰 수 있게 구성하는 것이 매우 중요하다.
- Sequential Model에는 Naive sequence model, Autoregressive model, Markov model, Latent autoregressive model 등 다양한 종류의 모델이 존재한다.
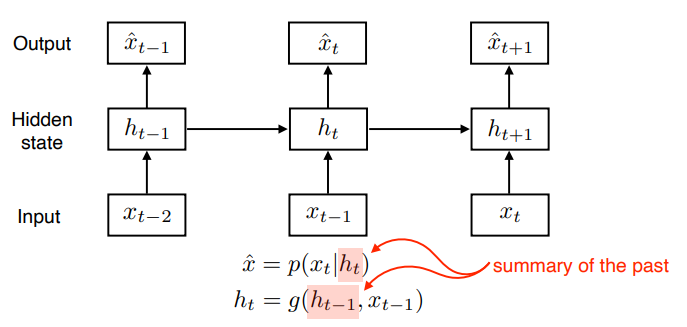
- 우리가 앞으로 다룰 Sequential Model은 Latent autoregressive model의 일종이다.
- Latent autoregressive model은 위 그림처럼 과거의 정보가 요약되어있는 hidden state를 만들어, hidden state를 통해서 과거의 정보에 대한 정보를 얻어서 현재에 예측에 활용하는 모델이다.
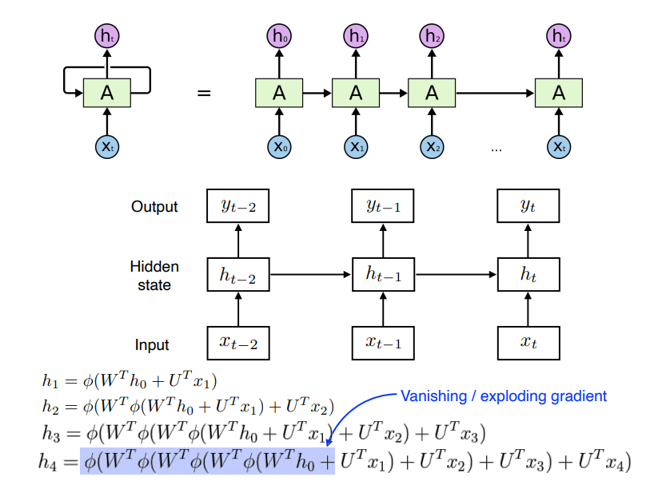
- Recurrent Neural Network, RNN은 위 그림 처럼 과거의 정보가 요약되어 있는 hidden state를 계속 반복적으로 업데이트 하면서 모델링 하는 방식이다.
- RNN의 경우 수식을 통해 알 수 있듯이 hidden state를 인코딩하는 과정에서 반복이 많아진다면, 활성화 함수로 sigmoid를 사용하면 기울기 소실이 발생하기 쉽고, ReLU를 사용하면 기울기 팽창이 발생하기 쉽다는 것을 알 수 있다.
- 이처럼 RNN은 가까운 정보 즉, Short-term dependencies의 경우에는 잘 반영할 수 있지만, 멀리 있는 정보 즉, Long-term dependencies의 경우에는 잘 반영할 수 없다는 단점이 존재한다.
- RNN의 기본 파라미터 수는 hidden_size hidden_size + hidden_size input_feature + hidden_size 이다. 왜냐하면 hidden state를 인코딩 하는 W와 input을 hidden state의 차원만큼 바꿔주는 W, 그리고 bias가 필요하기 때문이다.
02. Long Short Term Memory
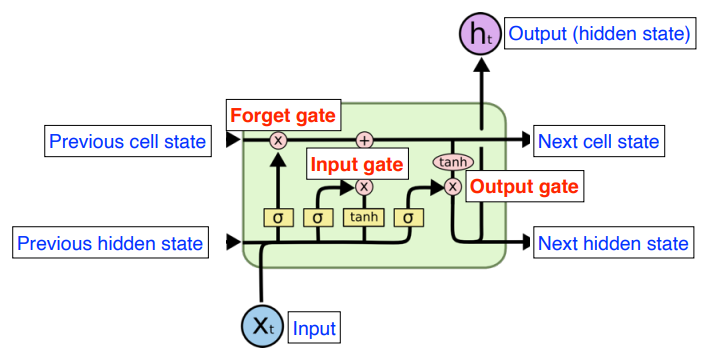
- Long Short Term Memory, LSTM은 RNN의 단점이었던 Long-term dependencies의 정보를 반영하기 어렵다는 점을 해결하기 위해 위처럼 Forget Gate, Input Gate, Output Gate를 추가한 구조의 모델이다.
- LSTM의 중요 아이디어는 cell state라고 할 수 있는데, 컨베이어 벨트처럼 필요한 정보만 cell state에서 빼서 쓸 수 있게, cell state에는 과거의 모든 정보가 요약되어 있다.
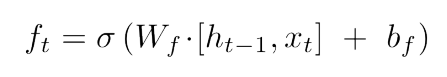
- Forget Gate는 위 식으로 구성되어 있고, 이름 그대로 버릴 정보를 결정하는 Gate 이다.
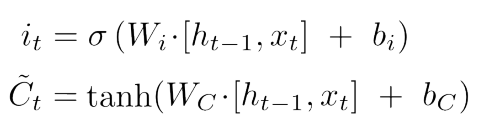
- Input Gate는 위 식으로 구성되어 있고, 이름 그대로 Cell state에 넣을 정보를 결정하는 Gate 이다.
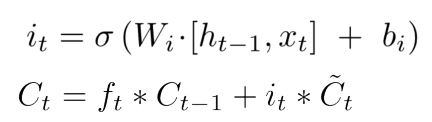
- Forget Gate와 Input Gate에 나온 output을 바탕으로 위와 같은 식을 통하여 Cell state가 Update 된다.
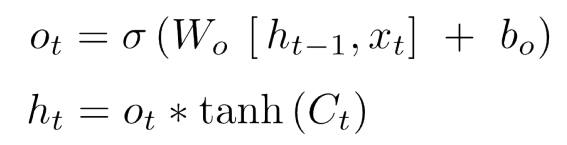
- Output Gate는 위 식으로 구성되어 있고, 현재의 Cell state와 현재의 input 정보를 바탕으로 output이 생성된다.
- LSTM의 경우 위처럼 다양한 Gate가 존재하기 때문에, 각 Gate에 해당하는 파라미터가 존재해, 생각보다 파라미터의 수가 많은 편이다.
03. Gated Recurrent Unit
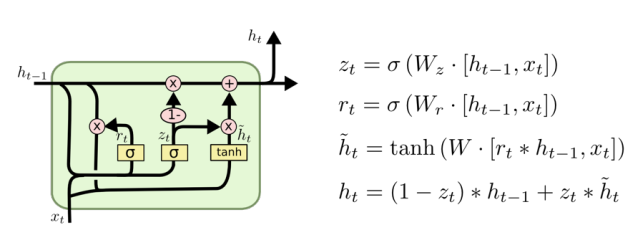
- Gated Recurrent Unit, GRU는 LSTM의 Gate를 줄인 형태의 모델로 위와 같은 형식으로 구성되어 있다.
- LSTM의 경우 Cell state를 이용했지만, GRU는 단순히 hidden state만을 사용하고 hidden state를 또한 Output으로 활용하여 Output Gate를 없앴다.
- GRU는 단순히 Reset Gate와 Update Gate 단 2개의 Gate만을 남겨놓아, LSTM보다 적은 파라미터를 가지고 있다.

Machine Learning Engineer at Konan Technology