WEPSKAM[1~2] - Commodity Hardware Today
Red Hat의 Ulrich Drepper씨가 2007년에 쓴 논문이다. likely/unlikely 매크로를 정리하다보니 읽게되었는데 양이 많아 이것도 같이 정리해보면 좋을것 같다. 작성 시기가 시기인만큼 아래 나올 "오늘날"은 2007년을 이야기 하는것으로 이해할 것. 생략된 부분도 많고 오역된 부분도 있을 수 있다. 도저히 이해가 되지 않는 부분은 괄호에 TODO로 남겨두었다. 특히 이번장은 하드웨어와 관련된 이야기가 많이 나와 힘들었다..
잘못된 내용이 있다면 댓글로 피드백 주세요. 감사합니다.
CPU는 점점 더 빨라지고 더 많아지면서 대부분 프로그램의 병목은 메모리 접근이 되었다. 하드웨어를 설계하는 사람들은 최적화를 위해 CPU 캐시같은것들을 고안했지만 이런 방법들은 프로그래머의 도움없이는 최적의 성능을 발휘하기 어렵다. 안타깝게도, 대부분의 프로그래머가 메모리의 구조와 접근 비용, CPU 캐시들에 대해 잘 이해하지 못하고 있다. 본 논문은 왜 CPU 캐시가 구현되었고, 어떻게 동작하는지, 그리고 이들을 최대한 활용하기 위해 어떻게 해야하는지 설명한다.
1. Introduction
초창기의 컴퓨터들은 훨씬 단순해서 각각의 컴포넌트들을 따로 개발하는 대신 한꺼번에 개발했고 어느정도 밸런스가 있었다. 그러나 컴퓨터가 고도화되며 각각의 서브시스템들을 집중적으로 최적화하기 시작했고 그 과정에서 다른 컴포넌트의 개발에 비해 뒤처지고 성능상의 병목이 되는 컴포넌트들이 생겨났다. 특히 대용량 저장장치와 메모리와 같이 비용상의 문제로 다른 컴포넌트들에 비해 상대적으로 느리게 발전한 것들이 해당된다.
대용량 저장장치가 느린건 대부분 소프트웨어로 해결된다. OS는 자주 쓰는(그리고 자주 쓸것 같은) 데이터는 메인 메모리에 남겨 훨씬 빠르게 접근할 수 있게 해준다. 또 저장 장치 자체에도 캐시 스토리지를 따로 두어 성능향상을 꾀했다.
그러나 저장장치와 달리 메모리의 병목현상을 없애는 일은 훨씬 어려우며 대부분의 해결책이 하드웨어의 변경을 요구한다. 오늘날 이러한 변경들은 주로 다음과 같은 것들이다:
- RAM 하드웨어 설계
- 메모리 컨트롤러 설계
- CPU 캐시
- Direct memory access(DMA)
본 논문에서는 주로 CPU 캐시와 메모리 컨트롤러 설계의 결과에 대해 알아볼 것이다.
2. Commodity Hardware Today
스케일링은 더이상 수직적이지 않다. 빠르고 성능 좋은(그리고 아주 비싼) 하드웨어보다 조금 느리더라도 싼 하드웨어를 여러개 이어 붙이는 수평적 스케일링이 더 효과적이고 경제적이기 때문이다. 수년동안 PC와 작은 서버들은 두가지 파트로 칩셋을 표준화 했다. 그림 2.1의 Northbridge와 Southbridge다.
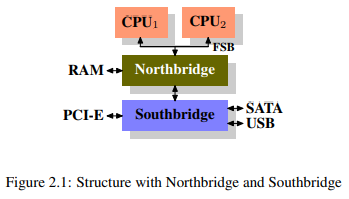
모든 CPU는 common bus(Front Side Bus, FSB)를 통해 Northbridge로 연결된다. Northbridge에는 메모리 컨트롤러가 포함되어 있는데 이것에 따라 컴퓨터가 사용할 수 있는 RAM의 종류가 결정된다. 다른 장치들에 접근하기 위해서 NorthBridge는 SouthBridge와 연결되어야 한다. Southbridge는 종종 I/O bridge로 불리는데, 요즘에는 PCI, PCIe, SATA, USB 버스같은 것들을 처리한다.
정리하면,
- CPU간 모든 데이터 전송은 Northbridge와 데이터를 주고 받을때 쓰는 버스를 같이 쓴다.
- RAM과 데이터를 주고 받을때는 Northbridge를 거쳐야 한다.
- RAM은 하나의 포트만을 가진다. (특수한 경우 제외)
- CPU와 Soutchbridge에 붙어있는 장치간의 통신은 Northbridge를 거쳐야 한다.
여기서 벌써 몇가지 병목을 눈여겨 볼 수 있다. 첫번째는 RAM에 대한 접근이다. 예전에는 어느 장치에서건 데이터를 주고받기 위해 CPU를 거쳐야 했기에 시스템 성능에 부하가 걸릴 수 밖에 없었다. 이 문제를 해결하고자, Direct Memory Access(DMA)을 만들었고 DMA는 Northbridge의 도움을 받아 CPU의 개입없이 RAN에 직접 접근할 수 있게 되었다. 그러나 RAM에 접근하기 위해 DMA와 CPU끼리 Northbridge 대역폭 경쟁을 하게 되어 다른 문제가 생기고 말았다.
두번째는 Northbridge에서 RAM으로 가는 버스다. 예전에는 모든 RAM chip들에 단 한개의 버스만 존재했기에 병렬 접근을 할 수 없었다. 하지만 최근 기술일수록 더 많은 버스를 추가하고 있는 추세므로 이 병목은 2022년 현재는 크게 해당되지 않을것 같다.
Northbridge 바깥에 외장 메모리 컨트롤러를 연결한 시스템도 있다.
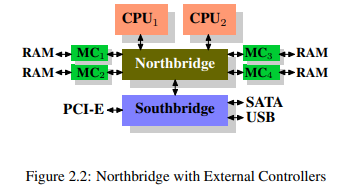
이러한 구조의 장점은 메모리 버스가 늘어나 그만큼 전체 대역폭도 늘어나고 더 많은 메모리를 사용할 수 있다는 것이다. 이러한 구조의 주된 병목은 Northbridge 내부다.
외장 메모리 컨트롤러 대신 메모리 컨트롤러와 메모리를 각 CPU에 바로 붙이는 방식도 있다.
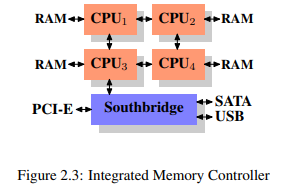
이러한 구조에서는 사용 가능한 메모리 뱅크가 프로세서 갯수에 비례하게 된다. 예로 쿼드코어 CPU에서는 Northbridge에 많은 대역폭을 필요로 하지 않고도 메모리 대역폭이 4배가 되는 셈이다. 하지만 단점도 있다. 모든 메모리는 모든 프로세서에서 접근할 수 있어야 하기에 메모리는 더이상 uniform하지 않다.(따라서 NUMA - Non-Uniform Memory Architecture라는 이름이 붙었다) 로컬 메모리는 일반적인 속도로 접근할 수 있으나 그림 2.3의 CPU1에서 CPU4에 붙어있는 메모리에 접근하려면 두 개의 interconnect를 거쳐야 한다. 이처럼 멀리 떨어져있는 메모리에 접근하기 위한 오버헤드를 NUMA계수라 한다.
2.1 RAM Types
2.1.1 Static RAM
SRAM은 DRAM에 비해 속도는 훨씬 빠르지만 비용적인 면에서 불리하다. 이때 비용은 생산하는 비용과 사용하는 비용 모두를 일컫는다.
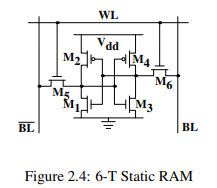
셀 하나는 6개의 트랜지스터로 되어있고 0과 1 두개의 상태를 가지며 Vdd에 전원이 인가되는 동안은 안정하다. 값을 읽을때는 를 활성화하고 과 에서 값을 읽으면 되고 쓸때는 과 을 원하는 상태로 만들고 을 활성화 하면 된다.
정리하면,
- 하나의 셀은 6개의 트랜지스터가 필요하다. (4개 짜리도 있지만 그에 따른 단점도 있음)
- 안정적인 상태를 유지하기 위해선 지속적인 전원이 필요하다.
- 셀의 상태는 즉각적으로 갱신되어, 신호가 구형파의 꼴을 갖는다.
- 안정적인 상태덕에 refresh cycle을 필요로 하지 않는다.
2.1.2 Dynamic RAM
DRAM은 SRAM에 비해 훨씬 간단하다. 하나의 트랜지스터와 하나의 커패시터로 구성된다.
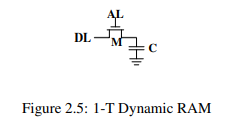
DRAM 셀은 캐패시터 에 상태를 기록하고 트랜지스터 이 해당 상태에 대한 접근을 제어한다. 값을 읽을 때는 을 활성화 시키는데, 커패시터의 상태에 따라 로 전류가 흐르거나 흐르지 않는다. 반대로 값을 쓸때는 을 설정하고 을 활성화시켜 커패시터를 충전하거나 방전시킨다.
값을 읽는 행위가 커패시터의 방전을 야기하기에, 어느 순간에는 재충전이 필요하다. 더욱이 요즘과 같이 메모리의 집적도가 올라가게 되며 커패시터의 용량도 매우 낮아지게 되었다. 완전히 충전된 커패티서는 수만개의 전자를 가질 수 있는데 이마저도 완전히 방전되기 까지 짧은 시간이 걸린다. 이러한 문제를 leakage(누출)라 부른다.
DRAM이 지속적으로 refresh 되어야 하는 이유가 leakage 때문이다. 오늘날 대부분의 DRAM 칩은 매 64ms마다 refresh가 이뤄진다. 이 refresh cycle동안에는 메모리 접근이 불가능 하다.
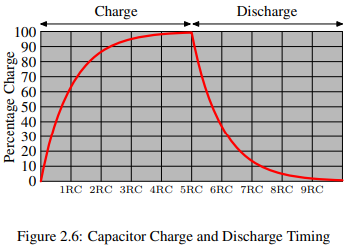
또한 커패시터를 충전하고 방전하는것이 즉각적으로 이뤄지지 않기에, 신호가 구형파의 꼴을 갖지 않는다. 이 활성화 되면 바로 값을 읽을 수 있는 SRAM과 달리 DRAM은 커패시터가 충분히 방전되기 까지 기다려야만 한다. 이 대기 시간이 DRAM의 주요 병목이다.
이렇게 간단한 구조덕에 같은 공간에 더 많이 더 싸게 칩을 생성할 수 있게 되었다는 점에 유의하고 나머지도 읽어보자.
2.1.3 DRAM Access
프로그램은 가상 주소를 사용해 메모리 위치를 특정한다. 프로세서는 이를 물리주소로 변환하고 최종적으로 메모리 컨트롤러가 해당 주소에 해당하는 RAM 칩을 선택하게 된다. 4GB RAM이 개의 address line이 필요한데 메모리 컨트롤러에서 이를 하나하나 각각 다루는 것은 실용적이지 않다. 대신 address line의 더 작은 집합만을 사용하여 이진수로 인코딩된 주소를 전달한다. 이렇게 DRAM 칩에 전달받은 주소는 먼저 demultiplexed 되야 한다. N개의 address line을 가지는 demultiplexer는 개의 출력을 가지며 이 출력들은 메모리 셀을 선택할때 사용된다. 작은 용량에선 이러한 접근법이 큰 문제가 되지 않는다.
그러나 셀의 갯수가 늘어나게 되면 문제가 된다. 1 Gbit 용량을 가진 칩은 30 개의 address line과 개의 select line이 필요한데 demultiplexer는 속도를 희생하지 않고서는 input 갯수에 대해 크기가 지수함수적으로 커지기 때문이다. 30개의 address line을 가지는 demultiplexer는 칩 전체를 차지하고도 남을 것이며 시간적 공간적 복잡도 면에서도 불리하다.
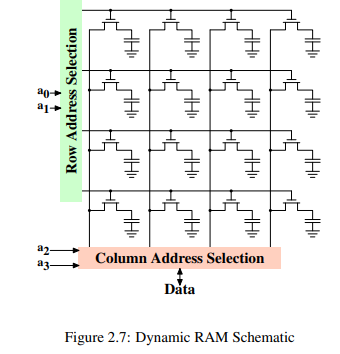
그림 2.7은 매우 추상화한 DRAM 칩을 보여준다. 행, 열로 배치하는 대신 길게 나열할수도 있지만 demultiplexer의 복잡도가 증가한다. 와 은 row address selction() demultiplexer를 사용해 임의의 행을 선택하고 값을 읽을때는 column address selection() multiplexer를 사용한다. address line 와 를 가지고 DRAM 칩 data pin에 임의의 열의 정보를 조회한다. 이 작업은 수많은 DRAM 칩에서 data bus 크기만큼 병렬로 수행된다. 값을 쓸때는 셀이 와 로 선택될때 data bus에 값을 넣어준다.
위 설계는 매우 직관적이지만 현실에서는 고려해야할 부분이 많다. 먼저 이전 장에서 봤듯이, 커패시터의 방전은 즉각적으로 이뤄지지 않기 때문에 신호를 받고 실제로 값을 읽기전에 얼마나 기다려야 하는지도 알아야한다. 셀에서 나오는 신호는 매우 약하기 때문에 증폭이 필요하다. 값을 쓸때도 커패시터의 충전에 얼마나 많은 시간이 필요한지 결정해야 한다. 이러한 타이밍 상수는 DRAM 칩 성능에 큰 영향을 미친다.
부차적인 스케일링 문제로, 모든 RAM chip에 연결된 30개의 address line을 가지는것은 구현하기 어렵다는 점이 있다. 30개의 address line을 가지는, 8개의 RAM 모듈(RAM 칩의 집합)에 병렬 접근을 할때, 메모리 컨트롤러는 240+개의 핀이 필요하게 되기 때문이다. 이러한 문제를 해결하고자 DRAM은 이전부터 자체적으로 주소를 multiplex 해왔다. 즉 주소를 두 파트로 나눠 전송해, 첫번째 파트의 address bit들이(그림 2.7의 와 ) 행을 선택하고 두번째 파트의 address bit들이(와 )이 열을 선택하는 식이다. 와 의 신호를 언제 사용 가능한지 결정할 line이 추가로 더 필요하지만 전체 address line이 절반으로 줄은 것 치고는 싼 편이다.
2.1.4 Conclusions
이번 절을 정리하면,
- 모든 메모리가 SRAM이 아닌 이유가 있다.
- address line의 갯수는 메모리 컨트롤러, 마더보드, DRAM 모듈 그리고 DRAM 칩의 비용을 결정한다.
- DRAM에서 값을 읽고 쓰기 전에 잠시 기다려야 한다.
2.2 DRAM Access Technical Details
앞서 우리는 DRAM이 address들을 multiplex하여 address pin 갯수를 줄인것을 배웠다. 또한 DRAM 셀에 접근하는 것도 커패시터가 안정적인 신호를 만들때까지 즉각적으로 방전되지 않기 때문에 시간이 걸린다고 배웠다. 그리고 DRAM 셀은 반드시 refresh가 필요하다는것도 배웠다. 이제 이것들을 종합하여 DRAM 접근이 어떻게 이뤄지는지 보자.
Asynchronous DRAM과 그 친척들, Rambus DRAM(RDRAM) 같은 기술은 여기서 생략하고 대신 Synchronous DRAM(SDRAM)과 뒤따라 나온 기술 Double Data Rate DRAM(DDR)을 집중적으로 다룬다.
Synchronous DRAM은 그 이름에서부터 알 수 있듯이 시간에 따라 동작한다. 메모리 컨트롤러는 clock을 제공하고 이 clock의 주파수는 Front Side Bus(FSB)의 속도를 결정한다. 2007년에는 800MHz, 1066MHz, 1333MHz 정도의 속도가 나와있었지만 버스의 속도가 이만큼 높은건 아니었다. 대신 오늘날의 버스들은 한 cycle마다 보내는 데이터를 2배, 4배 늘리는 방식을 사용한다. 숫자가 높으면 잘 팔리기 때문에 제조사들은 4x 200MHz 버스를 800MHz 버스로 광고하곤 한다.
오늘날의 SDRAM은 각 data는 8byte씩 전송되는데 따라서 FSB의 전송 속도는 버스 주파수의 8배이다.(4x 200MHz 버스에서 6.4GB/s) 이는 burst speed이며 더 이상 넘을 수 없는 한계 속도이다. RAM 모듈과 통신하기 위한 프로토콜은 많은 downtime을 가지는데 이를 이해하고 최소한으로 줄여 최적의 성능을 얻어보자.
2.2.1 Read Access Protocol
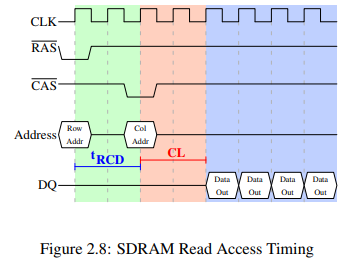
그림 2.8은 DRAM 모듈의 커넥터들 중 하나를 세 단계로 나눠 보여준다. 읽기 cycle은 메모리 컨트롤러가 address bus의 Row Addr를 준비하고 신호를 내리는것으로 시작된다. 모든 신호는 CLK의 rising edge에서 읽히므로 신호가 완전한 구형파일 이유는 없고 읽히는 시간에만 안정적이면 된다.
신호는 (-to- 지연) clock cycle 후에 보내진다. address bus에 Col Addr를 준비하고 신호를 내린다. 여기서 우리는 어떻게 주소를 두 개로 나누어 같은 address bus로 전송할 수 있는지 볼 수 있다.
RAM 칩은 값을 읽는데 시간이 좀 걸리는데 이를 보통 Latency ()라 한다. 그림 2.8의 Latency는 2다. 2.5라면 falling flank부터 값을 읽을 수 있을 것이다.
만약 우리가 필요한게 단지 1 word(프로세서가 다루는 데이터 기본 단위) 뿐이라면 이런 작업들은 자원 낭비가 될 수 있기에, DRAM 모듈은 메모리 컨트롤러가 얼마나 많은 데이터가 전송될 것인지 명시할 수 있도록 한다. 보통은 2, 4, 8 word 중 하나다. 덕분에 새로운 / sequence 없이 캐시의 전체 라인을 채울 수 있다. 또 Row Addr이 바뀌지 않는다면 이를 생략하고 바로 신호를 보낼 수도 있어서, 연속적인 메모리 주소에 접근하는 것이 훨씬 빠른 편이다.
이 예제에서는 SDRAM이 한 cycle마다 1 word를 출력하는데 이게 1세대가 했던 방식이다. DDR은 한 cycle에 2 word를 전송할 수 있다. 이 방식은 latency는 그대로 두면서 전송시간은 반으로 줄일 수 있었다. 원론적으로는 DDR2는 같은 방식으로 동작하지만 실제로는 아니며 자세한 내용은 생략한다. 여기서는 DDR2가 더 빠르고 싸고 안정적이며 더 효율적이라는 것만 알아두면 충분하다.
2.2.2 Precharge and Activation
그림 2.8은 전체 cycle이 아니라 단지 DRAM에 접근하는 cycle만 보여주었을 뿐이다. 새로운 가 보내지기전에 현재 latched된 row가 먼저 deactivated되고 새로운 row가 prechared되야 한다.
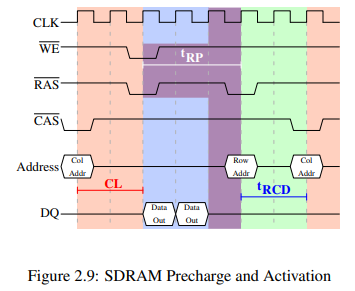
그림 2.9는 신호부터 다른 row의 신호까지의 과정을 담고 있다. 첫번째 신호로 요청된 데이터는 전과 같이, CL cycle 후에 받아볼 수 있다. precharge 명령이 들어오면 해당 row를 사용가능할 때 까지 cycle만큼 기다린다. 여기서는 데이터 전송과 같이 병렬하여 2 cycle을 절약했지만 여전히 가 전송시간보다 커 다음 신호가 한 cycle만큼 지연되었다.
이 다이어그램에서 계속 다음 데이터 전송까지 연장한다면 다음은 5 cycle후에 데이터를 받아볼 수 있을 것이다. 말인 즉슨, data bus는 전체 7 cycle 중에 오직 2 cycle만을 사용한다는 뜻이다. 이를 FSB 속도와 계산하면 이론적으로는 800MHz 버스에서 6.4GB/s가 1.8GB/s 밖에 되지 않아 개선이 필요하다. 6절에서 더 자세히 알아보도록 한다.
SDRAM 모듈은 신호를 받고 다른 row를 precharge하기 전에 기다려야 하며 이를 라 한다. 보통 이 값은 의 2~3배로 매우 큰 편이다. 만약 신호 뒤에 신호 하나만 오고 데이터 전송이 몇 cycle만에 끝난다면 병목이 될 것이다. 그림 2.9에서 처음 신호가 신호 바로 다음에 왔고 가 8이라고 하자. 그러면 precharge 명령은 추가로 한 cycle을 더 기다려야 한다. , 그리고 를 다 더 하면 7 cycle이기 때문이다.
DDR 모듈은 종종 w-x-y-z-T와 같은 특별한 표기법을 사용하는데 예를 들어 2-3-2-8-T1과 같은 식이다.

이외에도 명령을 받고 수행하는데 걸리는 시간에 영향을 미치는 요소들이 더 많지만 위 5개의 상수가 실질적으로 모듈의 성능을 결정하므로 나머지는 생략하도록 한다. FSB와 SDRAM 모듈의 속도와 함께 이 정보들은 컴퓨터의 속도를 결정하는 중요한 역할을 한다. 이것들을 모두 튜닝해볼 수 있는 BIOS도 있으므로 궁금하면 한번 해보자.
2.2.3 Recharging
2.1.2절에서 설명했듯이, DRAM 셀은 주기적으로 refresh가 필요하다. row가 재충전되는 동안에는 어떠한 접근도 불가능 하다. [3]의 연구에 의하면 DRAM refresh 방식은 성능에 큰 영향을 미친다고 한다.
JEDEC(Joint Electron Device Engineering Council) 명세에 의하면 각 DRAM 셀은 매 64ms마다 refresh되어야 한다. 만약 DRAM array가 8192개의 row를 가진다면 메모리 컨트롤러는 refresh 명령을 매 평균 7.8125µs 마다 수행해야 한다. refresh 명령을 어떻게 스케줄링 할것인지는 메모리 컨트롤러의 역할이다.
2.2.4 Memory Types
SDR(Single Data Rate) SDRAM은 DDR(Double Data Rate) SDRAM의 기초가 되는 메모리로 구조는 매우 간단하다. 메모리 셀과 데이터 전송 속도는 동일하다.
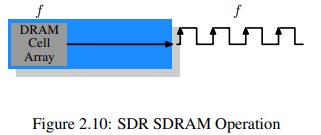
그림 2.10의 DRAM cell array는 메모리 버스가 전송할 수 있는 속도에 맞춰 결과를 출력할 수 있다. 만약 DRAM cell aray가 100MHz 속도로 동작한다면 단일 cell 버스의 데이터 전송 속도도 100Mb/s가 될 것이다. 클럭 속도 는 모든 컴포넌트에서 동일하다. 클럭 속도의 증가와 함께 에너지 소모도 커지므로 DRAM chip의 처리량을 늘리는 것은 비싸다. 수많은 array cell들인 경우에는 말도 안되게 비싸진다. () DDR SDRAM은 클럭 속도를 늘리지 않고도 처리량을 개선했다.
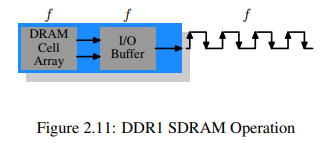
SDR과 DDR1의 차이는 그림 2.11에서 볼 수 있듯이, 한 사이클마다 전송할 수 있는 데이터가 두배라는 점이다. 다시말해 DDR은 rising/falling edge 두 지점에서 데이터를 전송할 수 있고 이를 double-pumped 버스라 한다. 클럭 속도의 증가 없이 이를 해결하기 위해선 버퍼가 필요하다. 버퍼는 data line마다 두 비트를 담아두며, 결과적으로는 그림 2.7의 cell array가 2개의 line을 갖도록 요구한다.
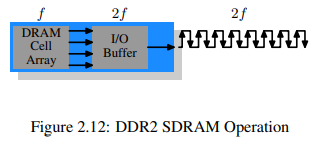
DDR2는 버스의 클럭 속도를 2배로 올렸다. 두배의 클럭 속도는 두배의 대역폭을 의미한다. DRAM cell array의 클럭 속도를 2배로 올리는것은 경제적이지 않기 때문에 각 clock cycle마다 I/O 버퍼가 4bit씩 받을 수 있도록 한다. 이는 DIMM의 I/O 버퍼만 변경하면 되기 때문에 비교적 쉽고 에너지 소모도 그리 늘어나지 않는다.
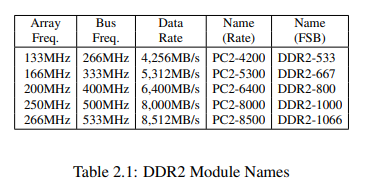
표 2.1은 마케터들이 어떻게 DDR2의 이름을 지었는지 보여준다. CPU, 마더보드 그리고 DRAM 모듈에서 사용하는 FSB 속도는 실질 클럭 속도로 명세된다. 즉, clock cycle의 두 flank에서 데이터가 전송되는 것을 고려하여 그 값이 뻥튀기 되는 것이다. 그래서 266MHz 버스를 가지는 133MHz 모듈은 533MHz 클럭 속도의 FSB를 갖게 된다.
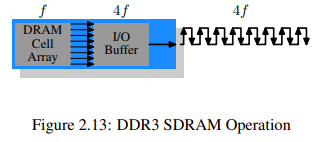
DDR3에서는 전압 사용량이 DDR2의 1.8V에서 1.5V로 줄었다. 전력 소모량에서 전압은 제곱을 취하고 있으므로 실제로는 30% 정도의 개선 효과가 있다. 여기에 추가로 die 크기도 줄이고 기타 다른 개선도 같이 해서, 동일한 클럭 속도에 절반의 전력만을 사용할 수 있게 되었다. 아니면 같은 전력을 사용하되 더 높은 클럭 속도를 사용하는 방식도 있다. DDR3 모듈의 cell array는 8 bit I/O 버퍼를 필요로 하는 외부 버스 속도의 로 동작한다.
모든 DDR 메모리는 한가지 문제를 갖고 있다. 버스 클럭 속도가 높아질수록 병렬 데이터 버스를 만들기 어려워진다는 것이다. (TODO A DDR2 module has 240 pins. All connections to data and address pins must be routed so that they have approximately the same length.) 더 문제는 만약 하나이상의 DDR 모듈이 같은 버스에 daisy chain 방식으로 연결될 경우 모듈이 늘어날수록 신호가 뭉개진다는 것이다. DDR2 명세는 버스 하나에 모듈 2개를 허용하고 있고, DDR3 명세는 1개만을 허용하고 있다. 채널당 240핀을 사용하는 단일 Northbridge는 2개보다 더 많은 채널을 사용할 수 없고 이에 대한 대안으로 그림 2.2처럼 외장 메모리 컨트롤러를 사용하는 방식이 있지만 비싸다는 문제가 있다. 그래서 상용 마더보드는 최대 4개의 DDR2 또는 DDR3 모듈을 사용할 수 있게 제약이 걸려있다.
이런 문제를 해결하기 위해 각 프로세서마다 메모리 컨트롤러를 달아주는 방식이 있다. AMD의 Opterion 라인이 그랬고 Intel도 CSI를 활용하여 그렇게 했다. 이걸 NUMA 아키텍처라 할때도 있는데 이에 따른 단점도 있어 다른 해결책이 필요하다. Intel의 방법은 Fully Buffered DRAM(FB-DRAM)이다. FB-DRAM 모듈은 비교적 싼 오늘날의 DDR2 모듈과 같은 메모리 칩을 사용한다. 차이점은 메모리 컨트롤러와의 연결이다. 병렬 데이터 버스 대신, FB-DRAM은 직렬 버스를 활용한다. 직렬 버스는 훨씬 더 높은 클럭 속도에서 동작할 수 있으며 대역폭도 늘릴 수 있다. 직렬 버스를 사용해 얻을 수 있는 이점으로는:
1. 채널당 더 많은 모듈을 사용할 수 있다.
2. Northbridge/메모리 컨트롤러당 더 많은 채널을 사용할 수 있다.
3. Fully-duplex로 동작한다.
4. Differential bus(각 방향마다 라인 2개)를 충분히 구현할 정도로 싸다.
DDR2가 240개 핀을 쓰는거에 비해, FB-DRAM은 69개핀만 쓴다. Daisy chaining FB-DRAM의 명세는 채널당 최대 8개의 DRAM 모듈을 지원한다. Northbridge에 듀얼 채널과 비교해 더 적은 핀으로 더 많은 채널을 사용할 수 있게 되었다: 2 240개 vs 6 69개. 각 채널마다의 연결도 훨씬 간단해져서 마더보드의 비용을 낮추는데도 도움이 된다.
옛날 DRAM 모듈에서 Fully-duplex 병렬 버스는 너무 비쌌었다. 직렬 라인(FB-DRAM의 differential bus일지라도)은 그렇게 비싸지 않아 full duplex로 설계되었다. 덕분에 이론적으로는 몇몇 경우에 대역폭이 2배가 된다는 것이다. FB-DRAM 컨트롤러가 최대 6개 채널까지 사용할 수 있기 때문에 더 적은 RAM을 가지고도 더 많은 대역폭을 사용할 수 있다. 모듈 4개짜리 DDR2 시스템이 채널 2개를 가지는 경우에 FB-DRAM 컨트롤러를 사용하면 같은 용량을 채널 4개로 사용할 수 있다. 직렬 버스의 실제 대역폭은 FB-DRAM 모듈에 사용된 DDR2(또는 DD3) 칩에 의존한다.

장점을 정리하면 위와 같다. 만약 DIMM 여러개가 채널 하나에 사용되면 문제가 생긴다. 체인의 각 DIMM당 신호가 지연되고 결국엔 latency의 증가로 이어진다. 두번째 문제는 직렬 버스를 제어하는 칩이 상당한 양의 에너지를 소모한다는 점이다.(매우 높은 클럭 속도와 버스를 제어해야 하기 때문에) 하지만 같은 클럭 속도에 같은 양의 메모리라면 FB-DRAM이 항상 DDR2나 DDR3보다 빠르다. 왜냐하면 최대 4개의 DIMM이 자신만의 채널을 가질 수 있기 때문이다. 메모리를 많이 쓰는 시스템에서라면 상용 컴포넌트를 가지고는 DDR로 답이 없다.
2.2.5 Conclusions
이 절에서는 DRAM에 무작위로 막 접근하는게 빠르지 않다는걸 배웠다. 최소한 프로세서 속도나 레지스터와 캐시에 접근하는 속도보다는 빠르지 않다. CPU와 메모리 클럭 속도의 차이도 중요하다. 2.933GHz로 동작하는 Intel Core 2 프로세서와 1.066GHz FSB는 11:1의 클럭비를 가진다.(1.066GHz 버스는 quad-pumped됨. ) 메모리에서 1 cycle의 stall이 프로세서에서는 11 cycle의 stall로 이어진다는 것이다.
읽기 명령의 타이밍 차트를 보면 DRAM 모듈은 높은 데이터 전송속도를 지속적으로 제공할 수 있는걸 볼 수 있다. 전체 DRAM 행들은 stall 하나 없이 데이터를 전송할 수 있고 data bus의 이용률은 100%까지 될 수 있다. DDR 모듈에서는 2개의 64bit 워드를 매 cycle마다 전송할 수 있다는 뜻으로, 채널 2개짜리 DDR2-800 모듈에서는 12.8GB/s가 된다.
하지만 DRAM 접근이 항상 sequential한건 아니다. 연속적이지 않은 메모리에 접근하려면 precharging과 새로운 신호가 필요하다. 이 때문에 메모리의 처리 속도가 늦춰지게 되며 미리 precharging하고 신호를 보낸다면 실제 해당 행이 사용될때 딜레이를 줄일 수 있다. 하드웨어와 소프트웨어의 prefetching이 이러한 stall을 줄이는데 사용될 수 있다.
2.3 Other Main Memory Users
CPU 말고도 메인 메모리에 접근할 수 있는 컴포넌트들이 있다. 네트워크, 대용량 저장장치 컨트롤러 같은 고성능 카드들은 CPU를 통해 주거나 받을 데이터들을 파이프에 다 담지 못한다. 대신 DMA로 메인 메모리에 직접 데이터를 읽고 쓴다. 그림 2.1에서 카드들이 Southbridge/Northbridge를 거쳐 메모리와 직접 데이터를 주고 받을 수 있음을 볼 수 있다. USB같은 다른 버스들 또한 DMA를 쓰지 않더라도 FSB 대역폭을 필요로 한다. (TODO the Southbridge is connected via the Northbridge to the processor through the FSB, too.)
DMA가 확실히 이득인 부분도 있지만, FSB 대역폭을 가지고 더 많이 경쟁해야 된다는 문제도 있다. DMA 트래픽이 많아지면 CPU는 메인 메모리에서 데이터를 기다릴때 평소보다 더 많이 stall될 수 있다.
이것으로 What Every Programmer Should Know About Memory의 2장을 정리했다. 모르는 내용도 많고 아무리 읽어도 이해되지 않는 부분이 있어 그런 부분은 생략하거나 TODO로 남겨 두었다. 본격적인 내용은 6장부터라는데 아직 갈길이 멀어 보인다. 중간중간 다른 글들도 쓰며 재충전의 시간이 필요해 보인다.
