Systems Performance - #1 Introduction
Netflix의 Senior Performance Engineer인 Brendan Gregg이 2020년에 Systems Performance: Enterprise and the Cloud 2판을 내놓았다. 양은 다소 많지만 전에 한번 읽었던 책이기도 하고 지금 정리중인 What Every Programmer Should Know About Memory 보다는 훨씬 이해하기 쉽고 친절해 기대가 된다.
Chapter 1 - Introduction
1.1 Systems Performance
Systems performance는 주요 소프트웨어/하드웨어 요소들, 저장 장치부터 어플리케이션까지의 data path, 분산 시스템이라면 여러대의 서버까지를 모두 포함한 컴퓨터 시스템 전체를 아우르는 분야다. 일반적으로 systems performance의 목표는 latency를 줄여 end-user의 경험을 개선시키는 것과 컴퓨팅 비용을 낮추는 것이다. 비효율적인 부분을 없애거나, system throuput을 개선하거나, 일반적인 튜닝을 통해 비용을 낮출 수 있다.
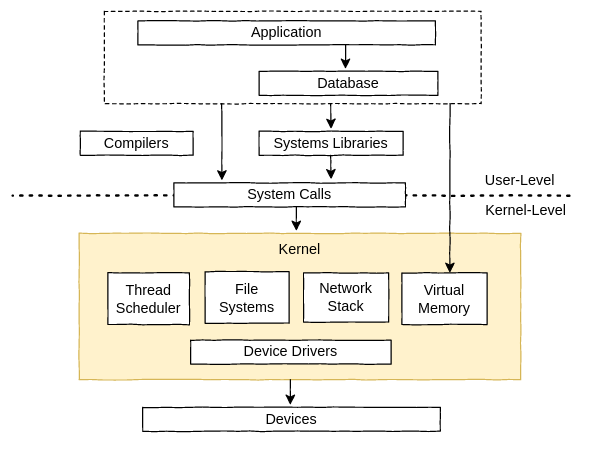
위 그림은 애플리케이션과 OS를 포함한 단일 서버의 일반적인 software stack을 보여준다.
1.2 Roles
Systems performance는 시스템 관리자, SRE 엔지니어, 어플리케이션 개발자, 네트워크 엔지니어, 데이터베이스 관리자, 웹 관리자 등 다양한 직군에서 수행된다. 많은 직군에서 성능은 업무의 일부분일 뿐이다. 몇몇 회사들은 performance engineer를 따로 뽑기도 하는데 그들은 여러 팀과 협업하여 시스템 전체에 대한 분석을 수행한다.
1.3 Activities
Systems performance와 관련된 작업들로는 다음과 같은 것들이 있다:
-
미래의 product를 위한 performance objective와 performance modeling 설정
-
소프트웨어/하드웨어 프로토타입에 대한 performance characterization
-
테스트 환경에서 개발중인 product에 대해 performance analysis 수행
-
새로운 product 버전에 대한 non-regression 테스팅
-
릴리즈된 product에 대한 벤치마킹
-
타겟 production 환경에 대한 Proof-of-concept 테스팅
-
production 환경에 대한 performance tuning 수행
-
서비스중인 production 소프트웨어에 대한 모니터링
-
production 이슈에 대한 performance analysis 수행
-
production 이슈에 대한 사후 분석
-
production analysis를 위한 performance tool 개발
-
canary tesing : production workload의 일부분에서 새로운 소프트웨어를 테스팅
-
blue-green deployment : canary testing 을 서서히 늘려나가며 배포
-
capacity planning : 개발 단계에서 자원의 사용량을 파악해 얼마나 요구사항을 만족하는지 확인. 개발이 끝난 후엔, 자원 사용량을 모니터링 하며 문제 발생을 예측
1.4 Perspectives
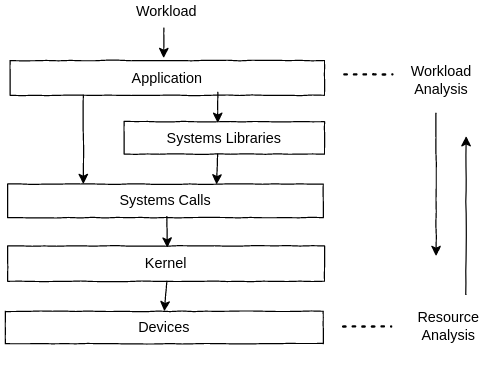
Performance analysis에는 두가지 관점이 있다: workload analysis, resource analysis.
resource analysis는 보통 시스템 자원에 책임이 있는 시스템 관리자가 수행한다.
workload analysis는 workload performance에 책임이 있는 애플리케이션 개발자가 수행한다.
1.5 Performance is Challenging
1.5.1 Subjectivity
Performance는 종종 주관적이다. performance 이슈가 있더라도 그게 언제 시작해서 언제 끝났는지 파악하기도 애매하다. 누군가에겐 나쁜 performance가 누군가에겐 괜찮은 performance일 수 있기 때문이다.
예를 들어 "평균 디스크 I/O 반응시간이 1ms" 라는 정보가 있을때 이게 좋은건지 나쁜건지 알 수 있을까?
명확한 목표를 정의하여 객관적인 평가를 할 수 있다. 예를 들어, 평균 반응시간이 얼마 아래여야 한다거나 요청의 일정 비율 이상이 특정 latency 범위안에 와야 한다거나 하는 식이다.
1.5.2 Complexity
Performance analysis는 어디서부터 시작해야 할지 분명하지가 않다. Performance 이슈는 종종 각각의 요소를 따로따로 볼땐 괜찮지만 서로 상호작용할때 문제가 되는 경우도 있다. 한 요소가 다른 요소의 performance에 영향을 끼칠 때 cascading failure 로 이어질 수 있다. 시스템 자체가 복잡한것과 별개로 workload가 복잡할때도 있어 production에서 있었던 이슈가 실험 환경에선 재현이 안되는 경우도 있다.
1.5.3 Multiple Performance Issues
Performance 이슈 자체를 찾는것은 큰 문제가 되지 않는다. 좀 복잡한 소프트웨어라면 이미 수많은 performance 이슈가 제보되었을 것이다. 문제는 어떤 이슈가 더 중요한지 식별하는 것이다. 이를 위해선 이슈의 영향범위를 수량화(quantify)하는것이 중요하다. 그리고 단순히 수량화하는것만이 아니라 그것을 해결함으로써 얼마나 더 빨라질지도 가늠해봐야 한다. 이런 정보들은 관리자들이 해당 작업에 얼마나 공수를 투입할지 결정하는데도 도움이 된다.
1.6 Latency
Latency는 기다리는데 소요된 시간이자 performance metric의 근본이다. 어플리케이션 요청, 데이터베이스 쿼리, 파일시스템 작업등에 소요된 시간과 같이 어디에나 광범위하게 사용될 수 있다. metric으로써 latency는 최대 얼마나 속도가 빨라질지 가늠하는데도 사용될 수 있다. 예를 들어 100ms(latency) 걸리는 데이터베이스 쿼리가 있을때 그 중 80ms는 디스크 읽기 때문에 blocked 된것이라 하자. 그럼 캐싱 같은걸 사용해 디스크 읽는 작업을 없애면 배 더 빨라질 수 있다는걸 알 수 있다. 이런 계산은 다른 metric에선 되지 않는다. 예를 들어 IOPS(I/O operations Per Second)는 어떤 종류의 I/O인지에 의존하며 직접적으로 비교가 불가능할때도 많다. 만약 IOPS를 5배 빠르게 만들었다 해도 I/O 크기가 10배 늘어났다면 그게 개선이라 할 수 있을까?
1.7 Observability
Observability는 관측을 통해 시스템을 이해하는 것을 의미한다. 이를 위한 도구들은 counters, profiling, 그리고 tracing 같은 방법을 사용한다. 이때 벤치마킹 도구는 포함되지 않는다. workload 실험을 수행할때 시스템의 상태를 변경시키기 때문이다. Production 환경에서는 observability 도구가 가장 먼저 시도되야 한다.
1.7.1 Counters, Statistics, and Metrics
애플리케이션과 커널은 일반적으로 현재 상태나 작업중인 내용에 대한 데이터를 제공한다: 작업 횟수, 바이트 갯수, 측정된 latency, 자원 활용도(utilization), 그리고 에러율. 이것들은 일반적으로 counters 라 불리는 정수로 구현된다. 몇몇은 계속 누적되어 performance tool에 의해 시차를 두고 읽혀져 statistics 를 계산하는데 이용된다: 시간에 따른 변화량, 평균, 백분위 등.
dongho@dongho-arch in ~
$ vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 5898636 677836 7224620 0 0 1 25 7 24 1 2 97 0 0
2 0 0 5891076 677836 7231768 0 0 0 0 54242 120831 5 17 77 0 0
5 0 0 5884524 677836 7238628 0 0 0 248 52355 115729 5 18 77 0 0
2 0 0 5879028 677836 7245496 0 0 0 0 51673 114006 5 19 76 0 0
4 0 0 5872176 677836 7252140 0 0 0 0 50170 111101 5 18 77 0 0예를 들어 vmstat(8)은 /proc 파일시스템의 커널 카운터에 기반하여, 가상 메모리 통계에 대한 요약을 출력한다. 위 예시는 부팅 후 지금까지 평균적으로 CPU Utilization은 3%(cpu us + sy 열)지만 지금은 22~25% 정도라는 것을 나타낸다.
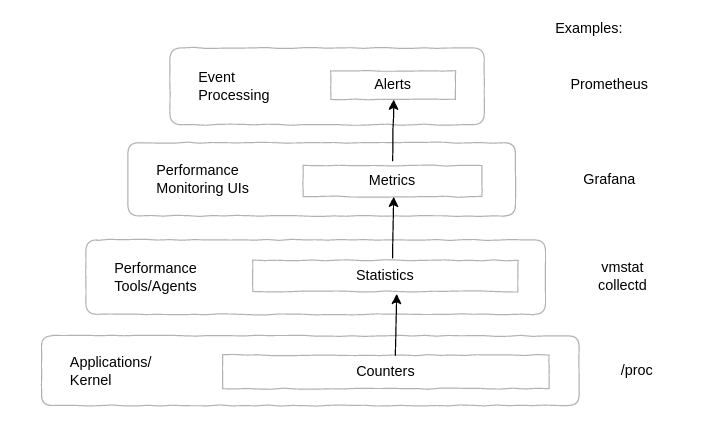
counters 부터 alerts까지의 계층은 정리하면 아래 그림과 같다.
1.7.2 Profiling
Systems performance에서 profiling 이란 용어는 일반적으로 performance sampling을 수행하는 도구를 사용함을 의미한다. sampling이란 타겟의 큰그림을 보기위해 관측값들의 일부(sample)만 본다는 뜻이다. CPU는 일반적인 profiling 대상으로 보통 on-CPU code path의 timed-interval sample을 구하는것으로 profile될 수 있다.
CPU profile의 효과적인 가시화는 flame graph 다. CPU flame graph는 CPU 이슈뿐만 아니라 다른 종류의 이슈들도 그것들이 남기는 CPU 자취를 통해 파악할 수 있다. spin path에서의 CPU time으로 lock contention을 찾거나, 메모리 할당 함수에 너무 많은 CPU time이 소요된 부분을 찾거나, legacy code path에서 소요된 CPU time으로 잘못 설정된 네트워크를 찾거나 하는 등이 있겠다.
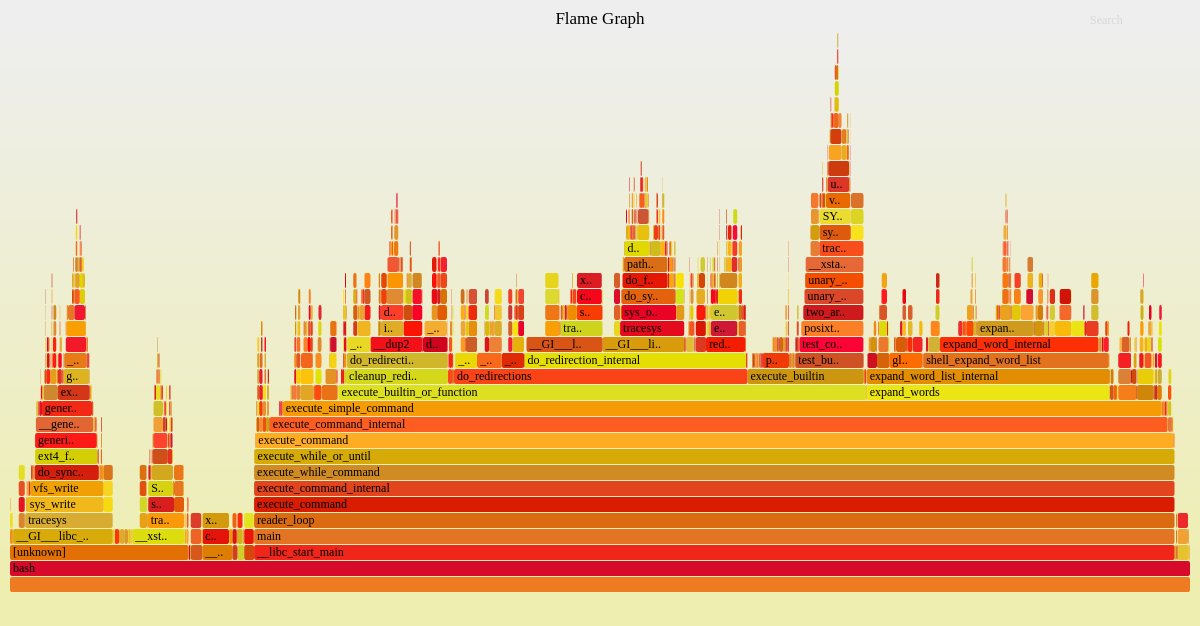
위 그림은 flamegraph 예시다. FlameGraph에 가면 더 자세한 내용을 볼 수 있다.
1.7.3 Tracing
Tracing은 이벤트를 기록하고 캡쳐된 데이터는 나중에 분석을 위해 저장되거나 다른 작업을 위해 실시간으로 consume되어 custom summary를 제공할 수 있다. system call을 tracing하기 위한 strace(1), 네트워크 패킷을 tracing하기 위한 tcpdump(8), 그리고 모든 소프트웨어/하드웨어 이벤트들을 분석할 수 있는 범용 tracing 도구인 ftrace, bcc, bpftrace 같은것들이 있다. 이런 all-seeing tracer들은 다양한 event source들을 활용하는데, 특히 static/dynamic instrumentation 그리고 프로그래밍을 위한 BPF가 있다.
Static Instrumentation
Static instrumentation은 소스 코드에 직접 하드코딩된 software instrumentation point를 의미한다. Linux kernel에는 디스크 I/O, 스케쥴링, 시스템 콜 등등을 위한 수백개의 point들이 있다. 이런 kernel static instrumentation들을 tracepoints 라 한다. user-space 소프트웨어의 static instrumentation들은 user statically defined tracing (USDT)라 하고 libc 같은 라이브러리에 사용되어 라이브러리 호출을 instrument할때 활용할 수 있다.
static instrumentation을 활용하는 도구의 예로는, execve(2) 시스템 콜의 tracepoint를 instrument하여 새로 생성되는 프로세스들을 출력하는 execsnoop(8)이 있다. 다음은 i3wm에서 rofi로 chrome을 실행시키는 것을 tracing한 예이다.
dongho@dongho-arch:~
$ sudo execsnoop
PCOMM PID PPID RET ARGS
sh 864 1 0 /bin/sh -c rofi -show run
rofi 864 1 0 /usr/bin/rofi -show run
sh 872 1 0 /bin/sh -c rofi -show run
rofi 872 1 0 /usr/bin/rofi -show run
google-chrome-s 880 1 0 /usr/bin/google-chrome-stable
google-chrome 880 1 0 /opt/google/chrome/google-chrome
readlink 881 880 0 /usr/bin/readlink -f /opt/google/chrome/google-chrome
dirname 882 880 0 /usr/bin/dirname /opt/google/chrome/google-chrome
mkdir 883 880 0 /usr/bin/mkdir -p /home/dongho/.local/share/applications
cat 885 880 0 /usr/bin/cat
cat 884 880 0 /usr/bin/cat
chrome 880 1 0 /opt/google/chrome/chrome
...이 도구는 top(1)에서 놓칠수 있는 short-lived 프로세스들을 파악하는데도 유용하다.
Dynamic Instrumentation
Dynamic instrumentation은 소프트웨어가 실행된 이후에, in-memory instruction을 수정하여 instrumentation routine을 추가하는 방식으로, instrumentation point를 생성한다. 디버거가 실행중인 소프트웨어에서 임의의 함수에 breakpoint를 거는 방식과 유사하다.
BPF
BPF는 원래 Berkeley Packet Filter의 약자였지만 지금은 그 패킷 필터 그 이상의 역할을 해주고 있어 BPF는 그냥 BPF라 보면 된다. 옛날 BPF는 cBPF(classic), 요즘 BPF는 eBPF(extended)라 하는 경우도 있는것 같지만 예전 Berkeley Packet Filter의 cBPF를 썼던 tcpdump(8)도 이제 eBPF로 대체되어 그냥 요즘은 다 BPF라 하는 추세다.
BPF는 현재 Linux의 dynamic tracing tool들의 기반이다. 원래 tcpdump(8)의 표현식을 더 빠르게 평가하기 위한 mini in-kernel virtual machine에 기원한 BPF는 2013년 그 기능이 확장되어 generic in-kernel execution environment가 되었다. 앞에서 본 execsnoop(8)도 BCC tool중 하나다.
1.8 Experimentation
observability tool과 별개로 experimental tools도 있다. 대부분 벤치마킹에 사용되는 이것들은 시스템에 인위적인 workload를 돌리고 performance를 측정하는 식으로 동작한다. 이런 도구들은 테스트 하는 시스템(Systems Under Test, SUT)의 성능을 요동치게 할 수 있으므로 주의가 필요하다.
-
macro-benchmark tools : 어플리케이션 요청과 같은 실세계에 있을법한 workload를 simulate
-
micro-benchmark tools : CPU, disk, network와 같은 특정 요소를 테스트
1.9 Cloud Computing
클라우드 컴퓨팅은 instance 라 하는 작은 가상 시스템 여러개에 어플리케이션을 배포하여 신속한 스케일링을 가능하게 해준다. 덕분에 capacity planning 에 써야할 공수가 많이 줄어들었고 대신 performance analysis에 더 많은 관심을 가질 수 있게 해주었다. 왜냐하면 클라우드는 보통 사용한만큼 돈이 나가는 방식이기에, 성능을 최적화 하면 할수록 사용하는 자원도 줄어들고 그만큼 비용도 절약되기 때문이다. 데이터센터와 비교해보면, 이러한 최적화가 실질적인 비용절감으로 이어지는 것은 계약이 끝나고 나서야 될것이다.
클라우드 컴퓨팅과 가상화의 새로운 문제는 다른 사용자들에 의해 영향을 받는다는 것이다. 예를 들어 시스템을 적절하게 관리했을지라도 해당 호스트를 공유하는 다른 사용자에 의해 disk I/O contention으로 성능이 안좋게 나올 수 있다. 특히 클라우드처럼 물리적인 자원이 직접적으로 보이지 않는 경우 이슈 파악에 어려움을 겪을 수 있다.
1.10 Methodologies
방법론은 systems performance에서 다양한 작업들을 수행하기 위해 권장되는 일련의 과정들을 정리한 것이다. 방법론이 없다면 performance investigation은 낚시여행이 될것이다. 뭔가 잡히길 바라며 아무거나 낚아보는것처럼, 이런식의 접근 방식은 시간은 시간대로 쓰게되고 비효율적이며 중요한 부분을 놓칠 수 있다.
1.10.1 Linux Perf Analysis in 60 seconds
첫 60초동안에 Linux tool들로 해볼 수 있는 performance issue investigation 체크리스트들을 아래 정리했다.
-
uptime: 부하가 늘어나고 있는지 줄어들고 있는지 식별하기 위해 load average 확인 -
dmesg -T | tail: OOM 이벤트를 포함한 커널 에러 확인 -
vmstat -SM 1: run queue 길이, swapping, 전체 CPU 사용량등의 통계 확인 -
mpstat -P ALL 1: CPU 하나만 바쁜 경우는 thread scaling이 제대로 되지 않았음을 시사한다. 이를 위해 CPU간 밸런스 확인 -
pidstat 1: CPU자원을 사용중인 원치않는 무언가가 있는지와 각 프로세스의 user/system CPU time을 식별하기 위해 프로세스당 CPU 사용량 확인 -
iostat -sxz 1: IOPS, throughput, 평균 대기 시간, percent busy 같은 disk I/O 통계 확인 -
free -m: 파일 시스템 캐시를 포함한 메모리 사용량 확인 -
sar -n DEV 1: 패킷과 throughput등 네트워크 장치 I/O 확인 -
sar -n TCP,ETCP 1: connection rates, retransmits등 TCP 통계 확인 -
top: 전체적인 개요 파악
1.10 Case Studies
사례연구를 통해 systems performance에서 언제/왜 어떤 작업이 수행되어야 하는지 알아보자. 여기서 나온 방법이 유일한 정답은 아니니 참고할 것
1.11.1 Slow Disks
데이터베이스 팀에서 데이터베이스 서버중 하나의 디스크가 느리다는 이슈가 제보되었다. 처음에 문제 정의를 위해 여러가지 정보를 모았지만 이게 데이터베이스 이슈인지 아닌지 확인하기에 충분치 않다. 그래서 다음과 같은 질문들을 던져본다:
-
현재 데이터베이스 성능에 문제가 있느가? 어떻게 측정되었는가?
-
이슈가 얼마나 오래 지속되었는가?
-
최근 데이터베이스에 무언가 변경이 있었는가?
-
왜 disk가 문제라고 생각했는가?
데이터베이스 팀에서 "우리는 1,000ms보다 느린 쿼리 로그를 갖고있다. 이런 일은 보통 일어나지 않지만 지난주동안 시간당 수십건으로 늘어났고 AcmeMon을 통해 디스크가 busy했음을 확인했다" 라고 답변이 왔다.
정말 데이터베이스에 이슈가 있음을 확인했지만 disk가 원인이라는 가설은 아직 추측에 불과해보인다. AcmeMon은 회사의 기본적인 서버 모니터링 시스템으로 표준 OS metric에 기반해 performance graph를 제공한다. USE method로 시작해 어느 자원에 병목이 있는지 빠르게 확인한다. 데이터베이스팀에서 말한대로 disk utilization이 80%로 높게 나왔다. CPU, network 같은 자원은 매우 낮은 상태였다. 지난 이력을 보면 CPU utilization은 일정했던 반면, 디스크 utilization은 지난주부터 꾸준히 증가하고 있는것을 알 수 있었다. AcmeMon은 disk에 대한 saturation이나 error는 제공해주지 않아 USE method를 마저 수행하기 위해 직접 서버에 들어가 몇가지 명령을 내린다.
/sys에서 disk error counter를 확인 (여기서 말하는 disk error counter가 뭔지는 파악되지 않는다. 아마 /sys/block/sda/device/ioerr_cnt? 그러나 block device error count in Linux의 내용과 같이 이 값이 유효한지는 모르겠다) 했고 값이 0임을 확인. iostat(1)을 interval 1초로 돌려 utilization과 saturation metric 확인. AcmeMon은 80% utilization이라고 했지만 그건 interval 1분일때의 얘기였다. 1초 단위에서 보니 디스크 utilization이 요동치는것을 볼 수 있었다. 종종 100%까지 올라가 saturation과 디스크 I/O latency 증가까지 이어지는것 같다.
offcputime(8)이라는 BCC/BPF tracing tool을 사용해 데이터베이스가 커널에 의해 descheduled 될때의 stack trace와 off-CPU에 소요된 시간을 캡쳐했다. 그 결과 데이터베이스가 쿼리를 처리하는 동안 파일시스템을 읽을때 자주 blocked 되는것을 볼 수 있었다.
왜 그런걸까? disk performance 통계는 많은 부하가 들어왔을때도 일정했다. 더 자세히 알아보기 위해 workload characterization을 수행하자. iostat(1)로 IOPS, throughput, 평균 디스크 I/O latency 그리고 읽기/쓰기 비율을 측정한다.
지금까지의 내용을 정리하면, 디스크에 높은 부하가 걸려 I/O latency가 증가하고 쿼리가 느려졌다. 하지만 그 디스크는 그 정도의 부하에서 무리없이 동작했다. 데이터베이스팀에 의하면 데이터베이스의 부하는 늘어나지 않았고 시간당 쿼리수도 일정했다고 하니 CPU utilization이 일정한것과도 일치한다.
CPU utilization은 영향이 없는데 디스크 I/O load를 증가시키는 요인이 또 뭐가 있을까? 파일 시스템 단편화가 그럴 수 있지만 현재 환경은 전체 용량의 30%만을 사용중이다. 무엇이 디스크 I/O를 만드는지, 이제 drill-down analysis로 알아볼 시간이다. 커널 I/O 스택에 대한 지식을 기반으로 이것저것 찾아보다가 파일시스템 캐시(page cache) 참조에 실패할때 디스크 I/O가 발생할 수 있다는게 기억났다.
cachestat(8)을 사용해 파일시스템 캐시를 확인해봤더니 91%로 나왔다. 이전 이력이 없으니 이게 괜찮은 수치인지는 모르겠다. 비슷한 workload를 처리하는 서버에서도 확인해보니 다른곳은 98% 이상이었다. 이제 관심을 파일시스템 캐시와 메모리 사용량으로 옮겨보자. 그랬더니 어떤 개발프로젝트에서 띄운 프로토타입 어플리케이션이 계속 메모리를 잡아먹고 있었던걸 발견했다. 여기서 메모리를 잡아먹는 바람에 파일시스템 캐시가 충분치 못했고 hit rate도 낮아지고 더 많은 디스크 읽기로 이어지게 된것이다.
개발팀에 연락해 해당 어플리케이션을 종료할 것을 부탁하고 확인하니 느린 쿼리가 0으로 줄어든것을 확인했고 이슈는 해결되었다.
1.11.2 Software Change
개발팀에서 새로운 기능을 내놓으려 하는데 이 기능 때문에 성능에 문제가 되는건 없을지 고민중이다. production에 배포하기 전에 non-regression 테스팅을 해보자.
테스팅을 위해 빈 서버를 준비하고, client workload simulator를 찾았다. 이전에 개발팀에서 하나 만든게 있긴한데 버그가 좀 있었다. 일단 현재 production workload를 잘 simulate하는지 알아보기로 했다. 서버를 현재 배포 설정에 맞추고 다른 시스템에서 client workload simulator를 돌렸다. client workload는 access log로 characterized될 수 있다. 그리고 production 서버의 시간대별 log도 같이 비교해봤더니 client simulator가 평균적인 production workload는 잘 반영하지만 편차는 반영하지 못하고 있었다.
stress testing 을 위해 부하를 계속 높혀 client simulator가 어디까지 가능한지 알아보기로 했다. 동시에 active benchmarking으로 limiting factor도 파악한다. 서버 자원과 스레드는 노는것 처럼 보였고 client simulator의 throughput은 초당 700건 정도에서 멈췄다.
개발팀에서 새로 개발중인 버전에서도 테스트를 진행했더니 이 역시 700 언저리에서 멈췄다. 하지만 liming factor는 찾지 못했다.
x축을 부하, y축은 요청처리속도로 놓고 그래프를 그려보니 둘 다 갑자기 멈추는 부분이 있었다. 새로운 기능이 성능을 크게 해치지 않는다는것은 알았지만 limiting factor가 무엇인지 모른다는게 신경 쓰인다. 지금까지 서버 자원만 확인했지만, 어쩌면 어플리케이션 로직이 문제거나 네트워크 또는 client simulator가 문제일 수 있다. client simulator를 초당 700건정도로 맞춰놓고 자원 소모량을 비교하니 32개 CPU의 평균 utilization이 현재 버전은 20%, 새 버전은 30%로 regression이 있음이 확인 되었다.
왜 700건에서 멈추는걸까? 부하를 더 높이고 클라이언트 workload 생성기, 클라이언트 시스템, 네트워크를 포함한 data path의 모든 요소들을 확인해봤다. 서버와 클라이언트에 대해서 drill-down analysis도 해봤다.
클라이언트 소프트웨어도 보기 위해 thread state analysis를 해보니 그게 단일 스레드로 돌아가고 있음을 알게되었다. 그 스레드는 100%를 on-CPU에 쓰고 있었는데 이게 바로 limiter로 보인다. 검증을 위해 여러 다른 클라이언트 시스템에서 클라이언트 소프트웨어를 병렬로 실행시켜보니 현재 버전과 새 버전의 CPU utilization이 100% 까지 올릴 수 있었다. 현재 버전은 초당 3,500건, 새 버전은 2,300건 으로 이전에 파악한 자원소모량과도 일치한다.
개발팀에게 새로운 버전에 regression이 있음을 알리고 CPU profiling과 flamegraph로 어떤 code path가 성능 저하를 유발하는지 찾아냈다. 그리고 client workload generator가 단일 스레드라 제대로 테스트 되지 않는다는것도 제보했다. 이렇게 이번 이슈도 해결되었다.
Systems Performance의 1장 Introduction의 내용에서 중요하다 생각되는 부분만 정리해봤는데 워낙 내용이 알차서 넘길 부분이 많이 없었다. 특히 사례연구에서 나온 이야기들은 실전에서 있을법한 일들이라 더욱 와닿았다.
