5주차 숙제 리뷰
try/except 사용시 유의할 점
try/except 사용시 except에 raise를 사용해서 어떤에러가 발생했는지 밝혀주는 것이 좋음
try:
cur.execute(create_sql)
cur.execute("commit;")
except Exception as e:
cur.execute("ROLLBACK;")
raiseexcept 에서 raise를 호출하면 발생한 원래 exception이 위로 전파된다
에러가 있다는 것을 raise를 통해 분명히 밝혀줘야함
ETL 관리 입장에서 어떤 에러가 감춰지는 것 보다는 명확히 밝혀지는 것이 좋음
DAG에서 task를 어느 정도로 분리하는 것이 좋을까?
- task 너무 많으면
- 전체 dag 실행 오래걸리고 스케줄러에 부하
- task 너무 적으면
- 모듈화가 안되고, 실패시 재실행 시간이 오래 걸림(clear)
Airflow Deepdive 2
dag_dir_list_interval = 300
300초 5분마다 dags_folder를 스캔한다
5분마다 dag모듈이 포함된 모든 파일을 실행함??
airflow가 dag를 식별하는 방법
from airflow import DAG
이 있다면 에어플로우는 이 파일을 dag로 인식한다.
그래서 엉뚱한 파일에 이 코드가 적혀있으면 dag로 인식하는 실수를 저지를 수 있음
나도 모르게 계속 실행된다거나
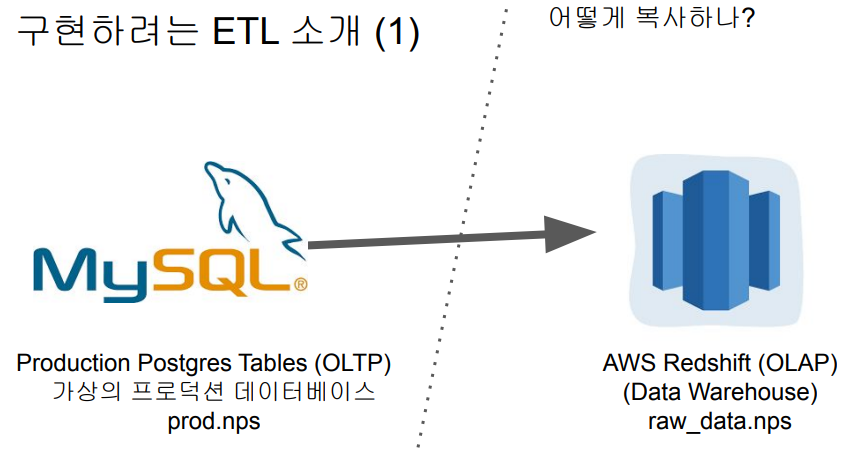
MySQL 테이블 복사하기
프로덕션 데이터베이스 (MySQL) -> 데이터 웨어하우스 (Redshift)
- 프로덕션db
- 온라인 서비스에서 서비스를 운영하기 위해 필요한 데이터가 저장되는 db를 의미함
- 매출 정보, 사용자 정보, 상품 정보 등등
- OLTP
- 속도가 중요함 → 사용자들에게 빠른 응답속도가 중요하기 때문임\
- 주로 서버 1개로 운영
- 데이터 웨어하우스 DW
- OLAP
- 큰 데이터 → 여러 서버 사용
- 속도보다 양이 중요
-
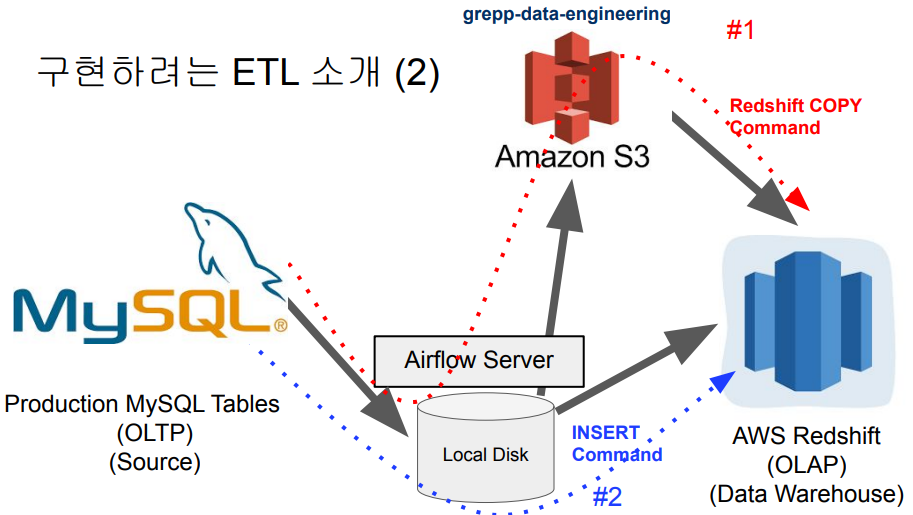
어떻게 Production DB → DW ?
- COPY 명령어
- INSERT 명령어
-
필요한 Connections 목록
- airflow - mysql
- airflow - s3
- airflow - redshift
각 Operator의 파라미터만 정확하게 입력해주면, 해당operator의 기능을 활용할 수 있음
- MySQLToS3Operator
- mysql 테이블의 데이터를 파일(default : *.csv)로 만들어서 s3에 업로드해주는 오퍼레이터
- S3ToRedshiftOperator
- s3의 파일을 redshift의 copy명령어를 사용하여 적재함
코드리뷰
- v1
- 각 Operator의 파라미터를 입력해주고 mysql task → redshift task 를 순서대로 실행
- v1으로 간다면 s3 파일명 중복 에러가 발생함
- s3에 이미 존재하는 파일명으로 덮어 씌우는 것은 불가능하다 → 기존 파일은 제거하고 다시 파일을 생성하는 방법이 좋음
- v2
- v1의 문제를 해결하기 위해 S3DeleteObjectsOperator를 사용하여 s3에 존재하는 기존 csv파일을 삭제하는 task를 맨 앞에 먼저 실행함
- v3
Backfill
- 커맨드 라인에서 실행하는 방법
airflow dags backfill [dag이름] -s [start_date] -e [end_date]start_date, end_date 내가 읽고싶은 데이터의 날짜를 의미함
그리고 backfill 실행하려면 catchUp = True 이어야함
- backfill 준비하기 1
- 모든 dag가 backfill이 필요하지는 않다
- full refresh라면 backfill은 의미가 없음
- backfill은 시간별/일별 업데이트를 의미함
- 데이터 크기가 커지면 backfill 기능 구현이 필수
- backfill 준비하기 2
- 데이터 소스가 backfill 방식을 지원하는지 체크하기 → 가장 중요
- 테이블에서 modified(timestamp)같은 flag로 활용할만한 컬럼이 존재한다 : backfill 가능
- flag로 활용할 컬럼이 없다 : backfill 불가능
- execution_date를 사용하여 업데이트할 데이터를 결정함
- catchup=True 이어야함
- 데이터 소스가 backfill 방식을 지원하는지 체크하기 → 가장 중요
Incrumental Update
- 구현 방법은 여러가지가 있을 수 있으나, 여기서는 가장 최근 시각 or 가장 큰 레코드ID를 기반으로 구현한다.
- 구현 과정
- DW에서 해당 데이터의 마지막 timestamp 혹은 ID를 읽어온다
- 데이터 소스에서는 위에서 읽어온 데이터 이후에 만들어지거나 변경된 레코드만 읽어온다
- 이를 DW의 테이블에 추가한다 (append)
- 변경이 생긴 레코드들의 경우 중복이 존재하기에 이를 제거한다. 가장 나중에 추가된 레코드만 남기고 나머지는 제거
- full refresh → daily update → hourly update 방식으로 구현하는 것이 일반적임
- 처음에는 전체 읽어오고, 점점 실시간에 가까운 데이터를 요구하게 될 경우 더 세분화해서 업데이트 한다
Summary Table 구현
- 간단히 말하면 CTAS하는 것임
- 데이터 소스에서 일부 데이터를 읽어와서 요약하는 테이블을 만드는 것
- 이것을 주기적으로 처리하도록 만들 예정
- 이 부분을 DBT로 구현하는 회사도 많음 → DBT는 마지막주에 추가설명할 예정
- Build_Summary.py 코드 분석
-
schedule_interval = '@once': 주기적으로 실행되는 것이 아니라, 내가 원할 때만 실행하도록 대기하고 있도록 만드는 방법dag = DAG( dag_id = "Build_Summary", start_date = datetime(2021,12,10), schedule_interval = '@once', catchup = False )
-
숙제
1번 : Mysql dag와 Summary SQL 실행하기
- schema 본인 스키마로 변경
- v1, v2, v3 3가지 버전 코드 분석해보기
- connections : mysql, s3 연결하기
- dag돌아가는 것 캡쳐해서 제출
2번 : Mysql v3를 backfill로 실행하기
- 지금까지는 full refresh였지만, execution_date를 사용해서 해당하는 날만 읽어오게 변경
- command line에서 backfill 실행해보기
이건 아직 못함
3번 : summary table
-
SQL 작성해서 제출
-
작성한 SQL을 기반으로 nps_summary라는 테이블 구성하는 dag작성 → Build_Summary.py를 수정해서 작성 가능
-
NPS
- Net Promoter Score
- 우리 서비스를 주위 사람들에게 얼마나 추천할 수 있는지 묻는 지표?
- 0~10점으로 평가
- 9,10점 : 긍정적인 소비자로 간주
- 7,8점 : 중립적인 소비자로 간주
- 0~6점 : 부정적인 소비자로 간주
-
NPS 계산법 출처
NPS = 추천 고객의 % – 비추천 고객의 %
이 공식을 더 수월하게 이해하기 위해 다음의 예를 살펴보죠.
NPS 질문에 150개의 응답을 수집했습니다. 점수가 분포되어 있는 정도는 다음과 같습니다.
-
등급 9나 10을 선택한 고객 80명
-
등급 7이나 8을 선택한 고객 30명
-
등급 0에서 6을 선택한 고객 40명
이는 추천 고객이 80명, 중립 고객이 30명, 비추천 고객이 40명이라는 뜻입니다. 추천 고객의 비율을 계산하려면 다음의 공식을 사용하면 됩니다.
추천 고객의 % = (추천 고객의 수 / 응답자 수) x 100
비추천 고객의 비율을 알아보기 위해 동일한 공식을 사용할 수 있습니다. 이 경우, 추천 고객의 수를 비추천 고객으 수로 대체하면 됩니다.
여기서 추천 고객은 80 / 150 * 100% = 53%이고 비추천 고객은 40 / 150 * 100% = 27%인 것을 알 수 있습니다.
다음과 같이 추천 고객의 비율에서 비추천 고객의 비율을 빼면 Net Promoter Score가 나옵니다.
53% – 27% = 26
이 예에서는 점수가 양수로 나왔지만 항상 양수가 되는 것은 아닙니다. Net Promoter Score 범주는 점수 및 분포도에 따라 -100에서 100까지입니다.
-
10번 슬라이드 보니까 진짜 nps계산을 내가 정말 멍청하게 했구나 싶다
