tensorflow
pip install tensorflow
TensorFlow는 구글 브레인 팀에서 개발한 오픈소스 소프트웨어 라이브러리로, 수치 계산과 기계 학습을 위한 다양한 도구를 제공한다.
이를 통해 인공 신경망, 결정 트리 및 기타 알고리즘을 구축하고 학습할 수 있다.
TensorFlow는 매우 유연하며 자연어 처리, 이미지 인식, 강화 학습 등 다양한 분야에서 사용할 수 있다.
또한 Python, C++, Java 등 다양한 프로그래밍 언어를 지원하며, CPU, GPU, TPU 등 다양한 플랫폼에서 실행할 수 있다.
TensorFlow는 가장 많이 사용되는 기계 학습 라이브러리 중 하나이며, 많은 연구자와 개발자들이 AI 분야에서 선택하는 대표적인 라이브러리 중 하나이다.
#딥러닝 모델 구성 및 결과 검증
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
mnist = tf.keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print(len(X_train), len(Y_train))
print(len(X_test), len(Y_test))위 코드는 TensorFlow를 이용하여 MNIST 데이터셋을 불러오고, 딥러닝 모델을 구성하여 결과를 검증하는 예제 코드이다.
import문을 통해 필요한 라이브러리인 TensorFlow, matplotlib, numpy를 불러온다.
mnist = tf.keras.datasets.mnist는 MNIST 데이터셋을 불러오기 위한 코드이다.
TensorFlow에서 제공하는 기본 데이터셋 중 하나인 MNIST는 28x28 크기의 손글씨 숫자 이미지 데이터셋으로, 이를 이용하여 딥러닝 모델을 학습시키는 것이 대표적인 예시 중 하나!
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()는 불러온 MNIST 데이터셋을 학습용과 검증용으로 분할하는 코드이다.
X_train과 Y_train은 학습용 이미지 데이터와 레이블 데이터를 담고 있는 변수이며, X_test와 Y_test는 검증용 이미지 데이터와 레이블 데이터를 담고 있는 변수이다.
print(len(X_train), len(Y_train))과 print(len(X_test), len(Y_test))는 각각 학습용 데이터와 검증용 데이터의 개수를 출력하는 코드이다.
이를 통해 데이터셋이 정상적으로 불러와졌는지 확인할 수 있다.
딥러닝 모델을 구성하고 결과를 검증하기 위해서는 아직 추가적인 코드가 필요함!
위 코드는 데이터셋을 불러오는 부분까지만 포함되어 있다.
print(X_train[0].shape)위 코드는 X_train의 0번째 인덱스에 해당하는 이미지 데이터의 형태를 출력하는 코드이다.
X_train은 MNIST 데이터셋의 학습용 이미지 데이터를 담고 있는 변수이며, X_train[0]은 첫 번째 학습용 이미지 데이터를 나타낸다.
print(X_train[0].shape)은 X_train[0]의 형태(shape)를 출력하는 코드이며, MNIST 이미지 데이터는 28x28 픽셀의 2차원 배열로 이루어져 있으므로 (28, 28)이 출력된다.
#정규화
X_train, X_test = X_train / 255.0, X_test / 255.0
plt.imshow(X_test[0])
plt.show()위 코드는 MNIST 데이터셋의 학습용 이미지 데이터인 X_train과 검증용 이미지 데이터인 X_test를 255로 나누어 정규화하는 코드이다.
MNIST 데이터셋은 각 픽셀 값이 0255 사이의 정수로 이루어져 있다.
이를 정규화하여 01 사이의 실수로 변환하는 것은 딥러닝 모델의 학습을 더욱 안정적으로 만들어주는 효과가 있다.
X_train / 255.0과 X_test / 255.0는 각각 학습용과 검증용 이미지 데이터를 255로 나누어 정규화하는 코드이다. 이를 통해 각 이미지의 픽셀 값이 0~1 사이의 값으로 변환된다.
plt.imshow(X_test[0])은 검증용 이미지 데이터 중 첫 번째 이미지를 시각화하는 코드이다. imshow 함수는 이미지를 보여주는 함수로, X_test[0]에 해당하는 이미지를 화면에 출력한다.
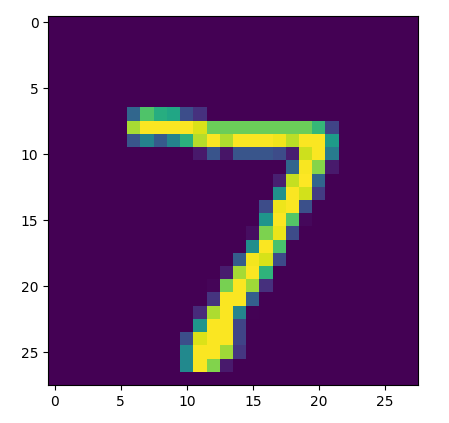
MNIST 데이터셋은 28x28 크기의 흑백 손글씨 이미지로 이루어져 있다.
각 이미지는 0부터 9까지의 숫자 중 하나를 나타내며, 이 숫자가 이미지에 표현된 손글씨의 실제 숫자이다.
따라서 X_test[0]에 해당하는 이미지는 0부터 9까지의 숫자 중 하나가 표현되어 있다.
plt.imshow(X_test[0]) 코드에서 출력된 이미지가 7로 보이는 이유는, X_test[0]에 해당하는 이미지가 손글씨 7을 나타내고 있기 때문!
#딥러닝 모델 구성 및 결과 검증
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
mnist = tf.keras.datasets.mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print(len(X_train), len(Y_train))
print(len(X_test), len(Y_test))
print(X_train[0].shape) #x_train의 0번째 인덱스의 형태를 알려줘
#정규화
X_train, X_test = X_train / 255.0, X_test / 255.0
plt.imshow(X_test[0])
plt.show()#모델 작성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
#모델 시각화
print(model.summary()) #모델 구성 요약 정보를 출력
# 이 요약 정보에서는 모델 구성에 대한 자세한 내용과 파라미터 개수, 각 레이어에서 출력되는 텐서의 크기 등을 확인할 수 있다.-
tf.keras.models.Sequential 클래스를 이용하여 모델을 구성하고 있다.
이 모델은 4개의 레이어를 가지고 있다. -
tf.keras.layers.Flatten : 입력 데이터를 1차원 배열로 변환한다.
이 모델에서는 MNIST 데이터셋으로부터 28x28 크기의 이미지를 입력으로 받기 때문에, 이 레이어를 이용하여 28x28 크기의 이미지를 784(=28*28)개의 픽셀로 구성된 1차원 배열로 변환한다. -
tf.keras.layers.Dense : 128개의 노드를 가지는 fully-connected 레이어
이 레이어에서는 ReLU 활성화 함수를 사용한다. -
tf.keras.layers.Dropout : 20%의 확률로 입력값을 0으로 만드는 dropout 레이어
이 레이어를 이용하여 모델이 오버피팅을 방지하도록 한다. -
tf.keras.layers.Dense : 10개의 노드를 가지는 fully-connected 레이어
이 레이어에서는 softmax 활성화 함수를 사용하여 결과값을 출력한다. -
model.compile() 메소드를 이용하여 모델을 컴파일한다.
이 메소드에서는 최적화 알고리즘, 손실 함수, 평가 지표를 설정한다.
이 모델에서는 'adam' 최적화 알고리즘, 'sparse_categorical_crossentropy' 손실 함수, 'accuracy' 평가 지표를 사용한다.
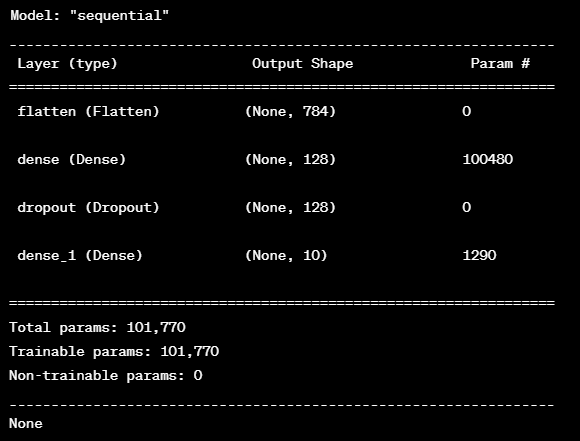
위 코드에서 model.summary() 함수를 호출하여 출력된 결과는 모델 구성에 대한 요약 정보를 보여준다.
총 3개의 레이어로 구성되어있다.
-
입력 레이어: Flatten 레이어로 2차원 배열 형태의 이미지 데이터를 1차원으로 펼쳐줍니다.
-
은닉 레이어: Dense 레이어로 128개의 뉴런으로 구성되어 있으며, ReLU 활성화 함수를 사용합니다.
-
출력 레이어: Dense 레이어로 10개의 뉴런으로 구성되어 있으며, softmax 활성화 함수를 사용합니다.
각 레이어에서 출력되는 텐서의 크기는 (None, 784), (None, 128), (None, 10)으로 나타내어졌다. None은 배치 크기(batch size)를 의미하며, 배치 크기는 모델 학습 시에 지정된다.
모델이 총 101,770개의 파라미터를 가지고 있으며, 이 중 100,480개는 입력 레이어와 은닉 레이어 사이의 연결 가중치(weight) 개수이다.
#모델 학습 및 평가
model.fit(X_train, Y_train, verbose=2)
model.fit(X_train, Y_train, epochs=5)model.fit(X_train, Y_train, verbose=2)은 X_train과 Y_train 데이터를 사용하여 모델을 학습하고, 학습 과정에서 로그 정보를 출력한다.
verbose 매개변수가 2로 설정되어 있으므로, 한 epoch이 끝날 때마다 로그 정보가 출력된다.
model.fit(X_train, Y_train, epochs=5)는 X_train과 Y_train 데이터를 사용하여 모델을 5번 학습하며, epoch마다 모델이 어떻게 개선되는지를 출력하지 않는다.
위 코드에서는 model.fit() 함수를 두 번 호출하는데, 첫 번째 호출에서는 로그 정보를 출력하고 두 번째 호출에서는 epochs 매개변수를 지정하여 모델을 학습한다.
이렇게 하면 첫 번째 호출에서 로그 정보를 확인한 후, epochs 매개변수를 조정하여 더 많은 epoch을 학습할 수 있다.
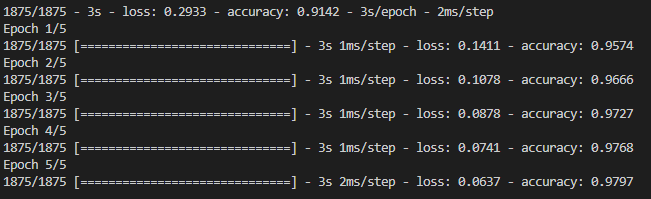
즉, 첫 번째 출력 결과는 model.fit() 함수가 호출되어 학습이 진행되는 동안, 각 epoch마다의 손실(loss)과 정확도(accuracy)를 보여준다.
총 1875개의 batch가 학습되며, 최종적으로 91.42%의 정확도를 달성하였다.
두 번째 출력 결과는 model.fit() 함수가 호출되어 5 epoch 동안 학습이 진행된다.
각 epoch마다의 손실과 정확도가 출력되며, 최종적으로 5 epoch 학습 후 97.97%의 정확도를 달성하였다.
