1️⃣ 첫번째 로그인 처리 방식
✔️ 로그인 기본 처리과정
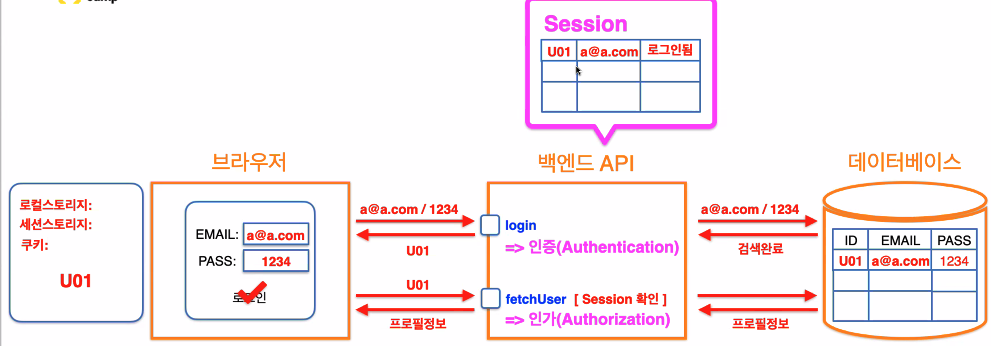
브라우저에서 특정 email과 password를 가지고 로그인하면
로그인 할 때 2가지의 요청이 이뤄짐.
- 로그인하는 API가 있을 거고
- 프로필정보를 가져다주는 fetchuser 요청API도 있을 것임.
(이때, DB를 해킹당할 수 있기 때문에 1234 그대로 저장하지 않는다.
따라서 fetchPassword 이런건 존재할 수 없음!
그 누구도 풀 수 없게 암호화해야함!)입력 후 로그인 버튼 누르면 백엔드로 loginAPI 요청이 날라감.
백엔드에서는 해당 유저가 있는지 DB에 확인 후
만약 데이터베이스에서 정보가 없다면? 에러나 뭔가를 보내주겠지있으면? session이라는 객체를 만들어놓고 메모리에 저장!(변수에 저장)
그 후 특정한 id를 부여해서 브라우저로 보내줌(uuid가능!)
누군지 식별가능하도록 id를 함께 넣어서 보내준다
로그인 증표를 브라우저에 보내준다!브라우저는 이걸 어딘가에 저장이 가능한데
로컬,세션,쿠키,변수 네가지에 아이디 저장이 가능함!========================================>이 과정에서 인증이 끝난 것
그럼 로그인증표를 가지고 있는 상태가 되고 프로필 정보요청을 날린다.
(http요청이 되는 것임!)
그 안에 헤더와 바디가 있고
헤더에다가 세션아이디를 추가해서 같이 요청하게 된다.그리고 메모리세션에서 먼저 검증을 해본다.
만약에 없다면 로그인을 먼저 해주세요 에러 뱉고
브라우저는 로그인페이지로 이동
근데 세션에서 찾앗따?
아 이사람 너 맞구나!하고 확인하게 되고
그 다음 디비에서 실제 정보를 가지고 와서 돌려주게 된다.곧 그 증표를 통해 로그인을 확인한다!
로그인할래! -> 인증(authentication)작업
로그인한거 맞으니까 맞는지 검사 끝나면
프로필 정보갖다줘! 해서 fetchuser(authorization) 인가 가 이뤄짐
- authentication(인증) : 로그인을해서 토큰을 받아오는 과정
- authorization(인가) : 리소스에 접근 할 수 있도록 토큰을 확인하는 과정
❗️ 문제점
만약 1억명이라면, 접속이 계속해서 이뤄질 때 각 함수를 요청하게 될거고
그 안에서 이뤄지는 것들(변수만들기 -> 메모리에 저장)이
Cpu/ram/disk관점에서 봤을 때 어딘가에 저장하려고 할때 램이 부족하게 된다.
세션 객체에도 저장하기에 메모리가 부족하다.
즉, 한번에 여러명의 정보를 받기엔 한계가 있음. 서버터짐??
💡 해결방법
백엔드 컴퓨터 자체의 성능(cpu, memory)를 업그레이드하게 됨(예를 들어 64기가로)
이걸 scale-up 이라고 함!
하지만
메모리가 계속해서 부족하면 또 업그레이드 again again 해야함.또한, 세션은 전역객체로 만든 전역변수 백엔드에서 만든 것!
그럼 맨날 해당하는 컴퓨터에만 접속해야됨.어떤 컴퓨터서버에가도 될 수 있도록 해줘야 한다!
그렇기에 메모리세션은 좋지 않은 방법!
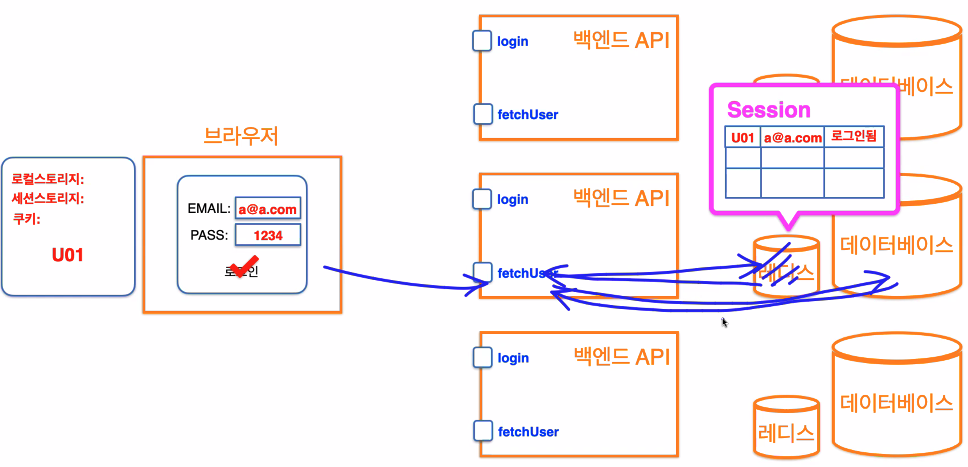
2️⃣ 두번째 로그인 처리 방식
💡 해결방법
백엔드 컴퓨터를 복사하자!!
어떻게?
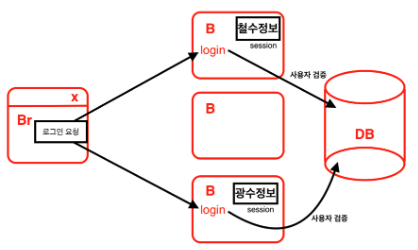
수평확장! scale-out 형태로 컴퓨터를 놓는다.
똑같은 API가 각각에 있어서 똑같은 서버(로그인, fetchUser)가 실행이 될 수 있도록 함.
쉽게 생각해서
알바생 혼자 하던걸 알바생을 더 구해서 일을 나눠함그리고
메모리세션을 잘봐바! 객체지만 테이블처럼 생겼잖아?
그럼 디비에 가져다 놓을까?
기존에 있던 세션테이블을 삭제!하고
디비에 세션테이블을 갖다 놓음.이렇게 하면 손님이 어떤 알바생한테 요청해도 (어디에 로그인해서 접속해도)
원하는 걸 받아오는데 문제 없어짐(디비의 세션테이블에 저장이 되서
API를 받아오는데 문제가 없어짐!)즉 똑같은 성능의 컴퓨터를 추가해서 부화를 분산시켜서 조금 나아졌다!
이걸 scale-out 이라고 한다.
❗️ 문제점
하지만 이 방법 또한 문제가 있다.
백엔드 컴퓨터를 복사할때는 세션까지 scale out이 안되기 때문에
기존의 로그인 정보를 가지고 있던 백엔드 컴퓨터가 아니면, 로그인 정보가 없다.또한 백엔드 컴퓨터를 복사해도 DB는 하나이기 때문에
결국 DB로 또 부하가 몰리는 병목현상(bottle-neck)이 일어난다.보완을 위해 “DB를 복사하면 안되나?” 라고 생각할 수 있지만,
DB를 복사하는 방법은 비용문제가 발생하기 때문에 비효율적!
3️⃣ 세번째 로그인 처리 방식
💡 해결방법
따라서 어떻게 해결했느냐?
user 테이블이 있다고 했을 때
아이디 이메일 패스워드 에이지 등등 정보가 있을 것임
이 유저테이블을 나누는 방법을 생각하게 됨어떻게 나누는데?
데이터베이스를 쪼개는 2가지 방법 (현재 많이 쓰이는 방법)
- 수직으로 쪼개는
수직파티셔닝- 수평으로 쪼개는
수평파티셔닝(샤딩)예를들어 1부터 100까지의 유저를 따로 빼서 묶음
100부터 200까지의 유저
그리고 나서 유저1테이블을 디비1에 넣고
유저2를 디비2에 넣는것
❗️ 문제점
DB는 컴퓨터를 껏다 켜도 날아가지 않기 때문에 데이터들이 disk에 저장된다.
따라서 안전하지만 느림. -> Disk I/O
이렇게 disk에 저장된 데이터를 추출해 오는 현상을 DB를 긁는다고(scrapping) 함.
💡 해결방법
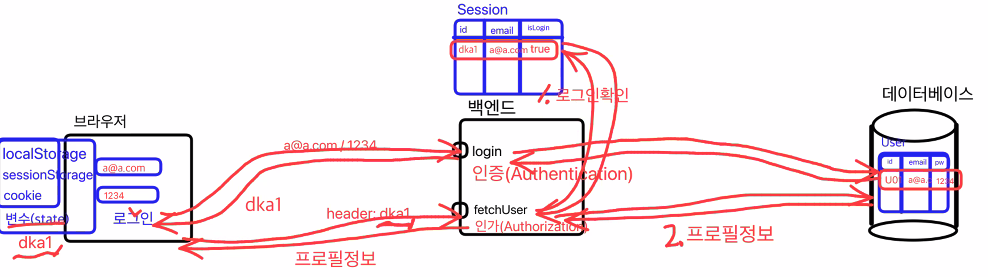
Redis라는 메모리에 저장하는 임시 데이터베이스에 저장한다.
redis는 메모리에 저장하기 때문에 디스크 보다 빠르다.이렇게 저장된 특정 ID(토큰)을 다시 브라우저로 돌려주게 된다.
돌려받은 토큰은 브라우저 저장공간에 토큰을 저장해두고 어떤 행동을 할때 토큰을 같이 보내주어 사용자가 누구인지 식별한다.
- stateless → 백엔드 컴퓨터에 상태를 가지고 있지 않음(scale-out하는데 편리해짐)
- stateFull → 메모리 세션이 백엔드에 포함되어 있는 과정(상태를 가진다)
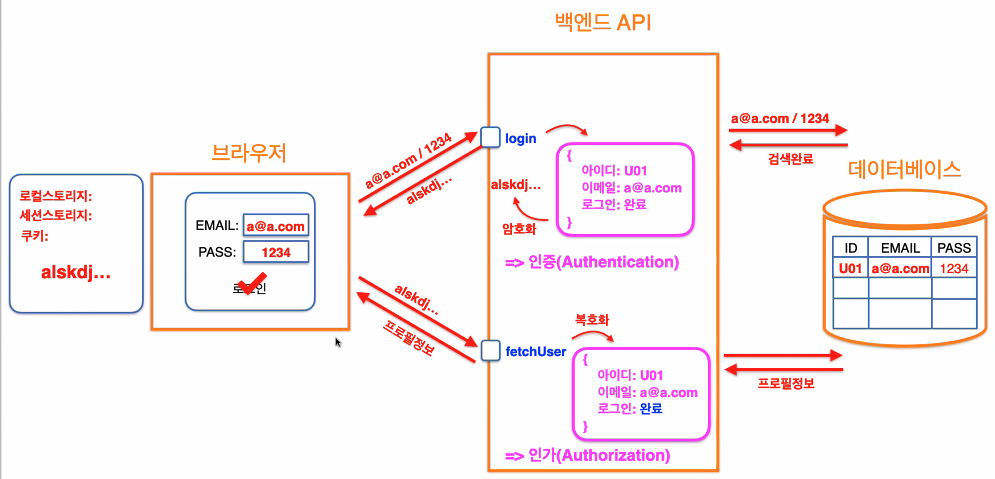
4️⃣ JWT 로그인(네번째 로그인)
로그인 정보를 굳이 서버나 DB에 저장해야 할까?
JWT 토큰은 유저 정보를 담은 객체를 문자열로 만들어 중괄호 다 포함해 맵핑하여 암호화한 후
const qqq = { id: adf @ velog.com isLogin: true }암호화된 키(accessToken - 접근시 필요한 토큰) 를 브라우저에 준다.
생긴게 세션아이디랑 비슷하게 생겼으니까 세션이랑 퉁치자! 해서
이걸 토큰이라고 부르자! 인증토큰!
토큰이란 어떤 문자열의 잘린 부분임
이걸 스테이트에 저장!받아온 암호화된 키는 브라우저 저장소에 저장해두었다가 유저의 정보가 필요한 API를 사용할 때 보내주게 되면,
해당 키를 백엔드에서 fetchUser할 때 복호화해서 사용자를 식별한 후 접근이 가능하도록 한다.JWT토큰에는 해당 토큰이 발급 받아온 서버에서 정상적으로 발급을 받았다는 증명을하는 signature를 가지고 있다.
따라서 사용자의 정보를 DB를 열어보지 않고도 식별할 수 있게 됨
자바스크립트 객체 표기법으로 웹에서 사용할 수 있는 JWT토큰을 만들었다!
하지만 accessToken과의 직접적인 관련은 없음!
✔️ 로그인 발전과정 정리
1단계
2단계
3단계