첫 취업 준비를 할때 정리해뒀던 내용이 있는데 계속 파일을 어디에 뒀는지 잊어버려서 그냥 블로그에 올려두려 한다.
정리하는 겸 다시 기본 개념들을 복습하는 기회가 될 것 같다.
실제로 질문 받았던 내용은 따로 표시(🟣)했다.
1. 개발 언어
오버라이딩(Overriding)과 오버로딩(Overloading) 🟣
- 오버라이딩(Overriding) : 부모의 메소드를 올라 타는(ride) 것. 상위 클래스의 메소드를 하위 클래스에서 재정의.
- 오버로딩(Overloading) : 매개변수의 타입이나 개수를 변경하여 같은 이름의 메소드를 여러개 사용하는 것.
가상(virtual)함수의 동작 원리 🟣
클래스 내에 가상함수가 포함되어 있을 경우 객체를 생성할 때 각각 고유한 가상 테이블이 생성됨. 이 가상테이블은 클래스 내의 가상 함수를 가리키는 함수 포인터 배열로 되어있음.
부모 클래스로 자식 클래스를 받았을 때 virtual 키워드의 중요성 🟣
animal* a = new dog();
대충 이런 형태일 때 진정한 의미의 다형성을 이룰 수 있다.
a->eat()을 호출했을 때 eat이 virtual로 선언되지 않았다면 dog의 eat이 아닌 animal의 eat을 호출할 것이다.
또한, 상속 클래스는 생성될 때 부모클래스를 먼저 생성한 후 자식클래스를 생성하는데, 소멸될 때는 이 반대의 순서로 이루어진다. 이때, 소멸자가 virtual로 선언되어 있지 않다면 animal의 소멸자만 호출하게 되어 dog에 할당된 메모리가 해제되지 않는다.
순수 가상함수와 가상함수의 차이점
virtual void func() = 0; 의 형태로 표현되는것이 순수가상함수. 가상함수와 달리 선언만 있고 정의는 없는것으로 자식 클래스에서 반드시 재정의해야 함.
추상클래스와 인터페이스
- 추상클래스
추상메소드 혹은 순수가상함수를 하나 이상 가진 클래스.
자신의 생성자로 객체 생성 불가능.
그러나 포인터형으로는 사용 가능.
단일 상속만 가능. - 인터페이스
public 접근제어자만 사용 가능.
추상메소드와 상수만을 멤버로 가짐.
다중 상속이 가능.
[C++]malloc()과 new
둘 다 동적할당을 위해 사용함.
- malloc()
함수.
초기화가 따로 필요함.
realloc()을 사용해서 재할당 가능. 그러나 재할당 실패시 null을 반환하며 기존의 포인터를 잃어버리게 됨. 메모리 누수가 발생하지 않도록 방지하는 프로세스가 함께 있어야 함. - new
연산자.
생성자를 호출해 메모리를 할당하기 때문에 초기화 가능.
[C++]스마트 포인터 🟣
자바와 C#의 가비지 콜렉터 기능을 대신할 수 있는 C++의 메모리 해제 기법. 소유권 개념을 도입.
- uinique pointer
유일한 소유권.
동일한 메모리를 가리키는 두개의 포인터가 존재할 수 없음.
소유권 이전은 가능.
소유권 해제시(포인터변수 소멸시) 메모리 해제. - shared pointer
공유 소유권. 참조 카운트로 관리.
여러 인스턴스가 동시에 동일한 메모리를 가리킬 수 있음.
레퍼런스 카운트가 0이면 즉시 해제. - weaked pointer
shared pointer의 약점을 보완하기 위해 등장. 서로 참조하고있는 순환참조의 경우 레퍼런스카운트가 2로 해제되지 않음.
참조시 레퍼런스카운트에 포함되지 않음.
메모리 해제에 직접적인 영향을 주지 않음.
[C#] 가비지 컬렉터 (GC) 🟣
- 프로그램에서 더이상 필요하지 않은 객체의 할당을 해제하여 메모리를 자동으로 관리하는 프로세스.
- 마크 앤 스윕 알고리즘 : 루트 집합부터 도달 가능한 모든 오브젝트를 순회. 도달되지 않은 모든 오브젝트를 할당 해제함.
[C#] namespace
클래스 이름이 중복되는것을 방지하기 위함
[C#] partial 클래스
클래스의 크기가 커질 경우 파일을 나누어 작성하고자 할 때 사용하는 키워드
[C#] const vs readonly
- const
- 컴파일 타임 상수
👉 변수가 값으로 대체됨
👉 값 변경시 전부 재컴파일
- 스택에 위치
- 내장 자료형만 가능 - readonly
- 런타임 상수
👉 상수에 대한 참조
- 힙에 위치
- 생성자에서 초기화 가능
L-value와 R-value
[C#] 클래스와 구조체의 차이
- 상속 : 클래스는 상속이 가능
- 메모리 할당 : 클래스는 힙에, 구조체는 스택에
- 기본 생성자 : 구조체는 있을 수도 있고 없을 수도 있음. 명시적 초기화가 필요함.
- 복사 : 클래스는 전달되거나 할당될 경우 참조 전달. 구조체는 복사 전달.
[C#] 람다
- 익명 함수. 별도의 선언 없이도 코드 블록을 인라인으로 정의 가능.
- 대리자 대신 사용.
- 변수 캡처. 블록이 종료되어도 둘러싼 블럭에서 접근 및 사용 가능.
- LINQ
2. CS
객체지향의 4가지 특징
- 상속
자식 클래스가 부모 클래스의 멤버를 물려받는것.
자식 is a 부모. - 다형성
하나의 메소드나 클래스가 다양한 방법으로 동작하는 것. - 캡슐화
서로 연관있는 속성과 기능들을 하나의 캡슐(capsule)로 만들어 데이터를 외부로부터 보호하는 것.
접근제어자를 사용해 외부에 드러나지 않도록 함.
직접적으로 접근을 막고 메소드를 사용해 외부와 상호작용. - 추상화
객체의 공통적인 속성과 기능을 추출하여 정의하는것.
불필요한 부분은 숨김.
객체지향의 5원칙 (SOLID)
- S (SRP : Single Responsibility Principle)
클래스는 하나의 기능만 다뤄야 한다. - O (개방/폐쇄 원칙(Open/Closed Principle))
클래스는 확장에는 열려 있어야 하지만 수정에는 닫혀 있어야 한다. 즉, 기존 코드를 수정하지 않고도 새로운 기능을 포함하도록 확장할 수 있어야 한다. - L (Liskov 대체 원칙(Liskov's Substitution Principle))
상위 클래스의 개체를 하위 클래스의 개체로 대체할 수 있어야 한다.. - I (ISP(인터페이스 분리 원칙(Interface Segregation Principle))
클래스는 사용하지 않는 인터페이스를 구현하도록 강요해서는 안 됩니다. - D (DIP(Dependency Inversion Principle))
구현 세부 사항에서 추상화가 분리되는 방식으로 코드를 구성해야 한다.
메모리 구조
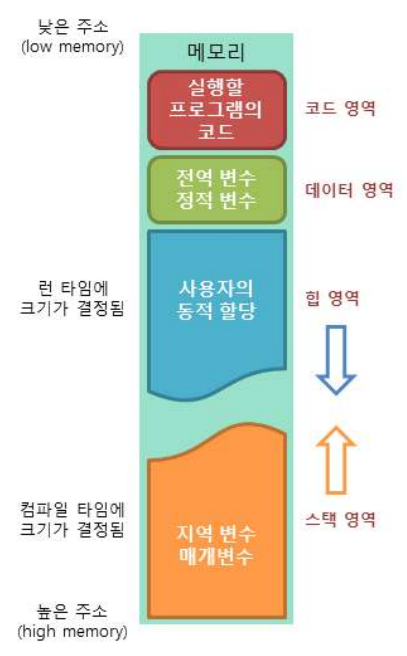
- 코드 영역 : 실행할 프로그램의 코드가 저장되는 영역으로, 텍스트 영역이라고도 한다. 사용자가 프로그램 실행 명령을 내리면 OS가 실행 코드를 하드디스크에서 메모리로 올리고, CPU는 코드 영역에 저장된 명령어를 하나씩 처리하게 된다. / 함수, 제어문, 상수 등에 대한 기계어 코드
- 데이터 영역 : 프로그램의 전역(global)변수와 정적(static)변수가 저장되는 영역이다. 데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료하면 소멸된다.
- 힙 영역 : 프로그래머가 직접 관리할 수 있는 메모리 영역으로, 이 공간에 메모리를 할당하는 것을 동적 할당이라 부른다. Java에서는 가비지 컬렉터가 자동으로 해제한다. 낮은 주
소에서 높은 주소로 메모리가 할당됨. - 스택 영역 : 함수의 호출과 함께 할당되며, 지역변수와 매개변수가 저장되는 영역. 스택 영역에 저장되는 함수의 호출 정보를 ‘스택프레임’이라 부름. 스택 영역은 함수의 호출이 완료되면 소멸한다. 높은 주소에서 낮은 주소로 메모리가 할당됨.
스택 프레임
Call By Value와 Call By Reference 🟣
- Value
인자로 받은 값을 복사.
변경해도 원래 값은 보존됨.
복사해서 넘기기 때문에 메모리 사용량이 늘어남. - Reference
인자로 받은 값의 주소를 참조하여 직접 값에 영향을 줌.
속도가 빠름.
원래의 값이 변경될 수 있는 위험이 있음.
얕은 복사와 깊은 복사
- 얕은 복사 : 디폴트 복사 생성자에 의한 멤버 대 멤버의 복사 방식. 멤버 변수가 힙의 메모리 공간을 참조하는 경우(ex. 포인터) 문제가 발생할 수 있음.
- 깊은 복사 : 복사 생성자를 재정의함으로써 같은 메모리 공간 참조를 막을 수 있음.
프레임워크와 라이브러리
- 라이브러리 : 자주 사용되는 로직을 재사용하기 편리하도록 잘 정리한 일련의 코드 집합. 사용자가 흐름에 대한 제어를 하며, 필요한 상황에 가져다 쓸 수 있다. 톱, 망치, 삽 등과 같은 연장(도구)의 역할.
- 프레임워크 : 전체적인 흐름을 자체적으로 제어한다. 차, 비행기, 탈것과 같은 운송수단의 역할. 내가 직접 조작해야 하지만 목적에 맞게 설계되었기 때문에 대체가 어려움. 다만, 프로그래밍할 규칙이 정해져 있어 그대로 따르면 됨.
동기와 비동기 🟣
- 동기(Synchronous)
요청을 보내고 실행이 끝나면 다음 동작을 처리
순서에 맞춰 진행되기 때문에 제어하기 쉽다.
여러 가지 요청을 동시에 처리할 수 없어 효율이 떨어진다.
(ex) 콜센터 직원 : 한 손님의 응대가 끝난 후에야 다음 손님을 응대할 수 있음 - 비동기(Asynchronous)
요청을 보내고 해당 동작의 처리 여부와 상관없이 다음 요청이 동작
작업이 완료되는 시간을 기다릴 필요가 없기 때문에 자원을 효율적으로 사용할 수 있다.
작업이 완료된 결과를 제어하기 어렵다.
(ex) 이메일 : 답변을 받지 않아도 다시 메일을 보낼 수 있음
디자인패턴
- 디자인 패턴 : 여러 프로그래머들의 경험과 지혜를 모아 공통적인 소프트웨어 디자인 문제를 해결하는데 도움이 되도록 만들어 놓은 것.
- 싱글톤 패턴
단 하나의 인스턴스를 생성하여 사용하는 디자인 패턴.
해당 인스턴스가 절대적으로 하나만 존재할 경우, 동일한 인스턴스를 자주 사용해야 하는 경우.
그러나 객체지향 설계 원칙에 적합하지 않고, LifeCycle의 제어가 힘들다. 멀티스레드 환경에서는 여러개가 생성될 수도 있음. - 전략 패턴
3. 알고리즘과 자료구조
배열/리스트/스택/큐/트리/힙이란? 🟣
- 배열 : 각 원소의 주소는 연속적으로 할당. index를 통해 O(1)에 접근 가능. 삽입/삭제는 O(N)
- 링크드리스트 : 노드들의 연결로 이루어진 자료구조. 원소 접근은 O(N), 삽입/삭제는 O(1)
- 스택 : 세로로 된 바구니와 같은 구조로, 후입선출(LIFO) 구조이다. top()
- 큐 : 가로로 된 통과 같은 구조로, 선입선출(FIFO) 구조이다.
- 트리 : 정점과 간선을 이용해 사이클을 이루지 않도록 구성한 Graph의 특수한 형태로, 계층이 있는 데이터를 표현하기에 적합하다. = 사이클이 없는 무방향 그래프
- 완전이진트리 : 마지막 레벨의 노드를 제외하고는 모두 두 개의 자식 노드가 있고, 마지막 레벨에서는 왼쪽부터 차례대로 노드가 있는 트리
- 힙 : 최대/최소값을 찾아내는 연산을 쉽게 하기 위해 고안된 구조로, 각 노드의 키 값이 자식의 키 값보다 작지 않거나/크지 않은 완전이진트리이다.
해시 테이블 🟣
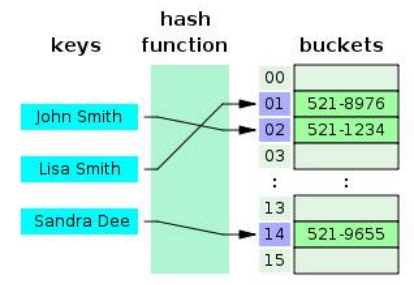
[key, value]로 데이터를 저장하는 자료구조.
빠른 데이터 검색에 유리. 평균적으로 O(1).
key값에 해시함수를 적용해 고유한 index를 생성하여 저장된 값을 꺼내오는 구조.
해시 값의 충돌이 발생할 경우 해당 index에 연결된 데이터를 전부 조회하기 때문에 탐색 시간이 증가할 수 있음.
- 해싱 충돌 해결법
1) 이중 해시법 (재해싱) : 추가적인 해시 함수를 사용
2) 체이닝 : 고정된 개수의 슬롯 대신 유동적인 크기를 갖는 연결 리스트 사용
3) 선형조사법 : 충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장
우선순위 큐
가장 우선순위가 높은(최대/최소) 데이터를 먼저 꺼내기 위해 고안된 자료구조.
힙을 사용해서 구현.
이진 탐색 트리 (Binary Search Tree) 🟣
데이터의 삽입/삭제/탐색 등이 자주 발생하는 경우에 효율적이다.
같은 값을 갖는 노드가 없어야 하고, 정렬되어 있어야 한다.
노드의 왼쪽은 노드보다 작은 값, 오른쪽은 노드보다 큰 값.
균형잡힌 이진트리 (AVL)
한쪽으로 치우치는 BST의 한계점을 보완하기 위해 만들어짐.
항상 좌/우로 균형잡힌 상태를 유지하기 위해 추가 연산을 진행함.
레드 블랙 트리
자가 균형 이진 탐색 트리.
- 새 노드를 삽입할 때에는 항상 레드로 삽입.
=> 더블 레드를 방지하기 위해 추가 연산을 진행함.
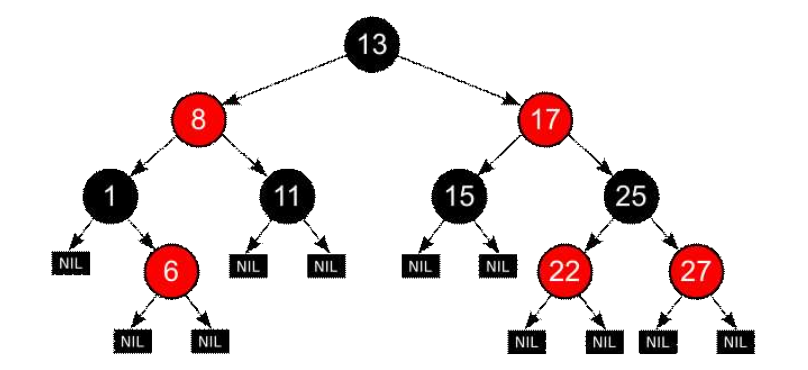
- 루트와 모든 리프(NIL)노드는 블랙.
- 레드의 자식노드는 항상 블랙. 즉, 레드 노드는 연속으로 나타날 수 없으며 블랙 노드만이 레드 노드의 부모가 될 수 있음.
- 어떤 리프 노드로부터 시작해 루트 노드에 도달하는 경로에는 모두 같은 개수의 블랙 노드가 존재.
- (루트 노드로부터 가장 먼 리프 노드까지의 거리) <
(가장 가까운 리프 노드 까지의 거리) * 2
=> 최단경로 : 모두 블랙노드 / 최장경로 : 블랙,레드 교차
[C++] array vs vector vs list vs deque
- 배열 (array) 🟣
정적 할당. 크기가 고정되어 있음. (스택 할당) - 벡터 (vector) 🟣
배열과 유사하지만 크기가 동적으로 변함. (힙 할당)
임의 접근(인덱스를 사용) 가능.
연속적인 메모리 구조에 저장함.
중간 데이터의 삽입/삭제가 용이하지 않음.
할당받은 영역이 다 찼을때 재할당이 일어나는 비용이 큼. - 리스트 🟣
양방향 linked list를 템플릿으로 구현한 것.
임의 접근 불가능.
어느 위치에서든 삽입/삭제 용이. - 덱, 디큐 (deque)
double ended queue.
앞/뒤 데이터의 삽입/삭제가 용이함.
동적 할당.
임의 접근 가능.
연속된 메모리를 사용하지 않음. chunk 단위로 쪼개져 있음.
포인터 연산 사용 불가능.
[C#] 배열과 리스트 차이 🟣
빅오 표기법
- 알고리즘의 효율성을 표기해주는 표기법. 상한을 기준으로 표기하지만 상한이 꼭 최악의 경우는 아닐 수 있다.
- 데이터 입력값 N이 충분히 크다고 가정하기 때문에 상수항이나 영향력이 없는 항은 생략하고 표기한다
- 성능 (상수 < 로그 < 선형 < 다항 < 지수)
(빠름) O(1) < O(logN) < O(N) < O(N·logN) < O(N²) < O(2ⁿ) (느림) - O(1) : 스택의 push, pop
- O(logN) : 이진트리
- O(N) : for문
- O(N·logN) : 퀵/병합/힙 정렬
- O(N²) : 이중 for문, 삽입/버블/선택 정렬
- O(2ⁿ) : 피보나치 수열
정렬
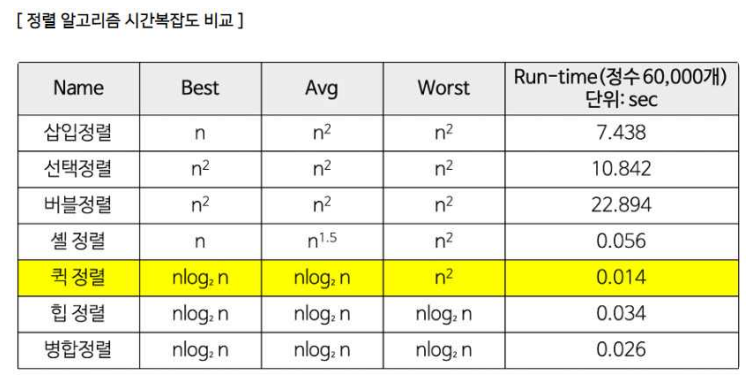
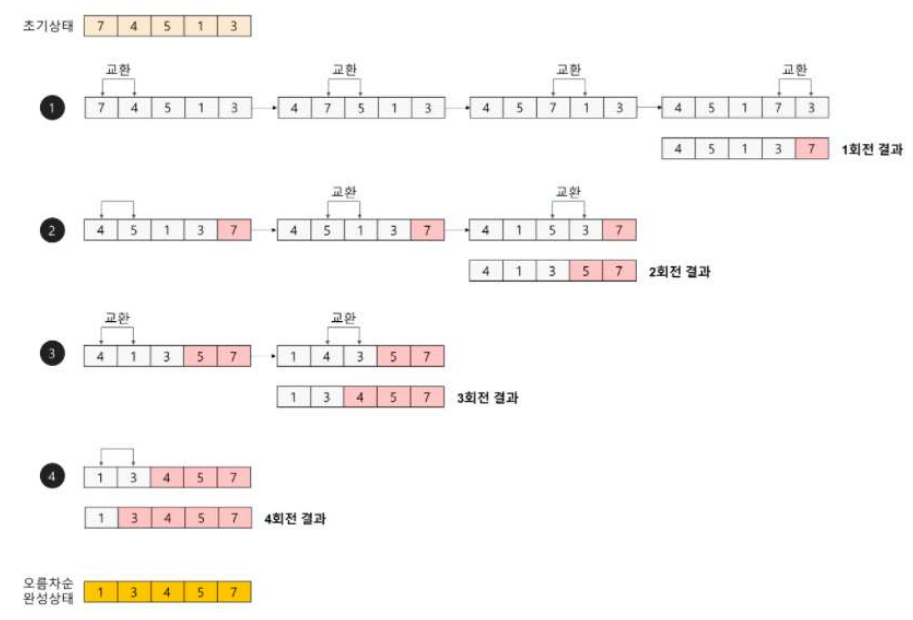
- 버블정렬 : 서로 인접한 두 원소를 비교하여 정렬하는 알고리즘입니다. 0번 인덱스부터 n-1번 인덱스까지 모든 인덱스를 비교하며 정렬합니다. 시간 복잡도는 O(n²)입니다.
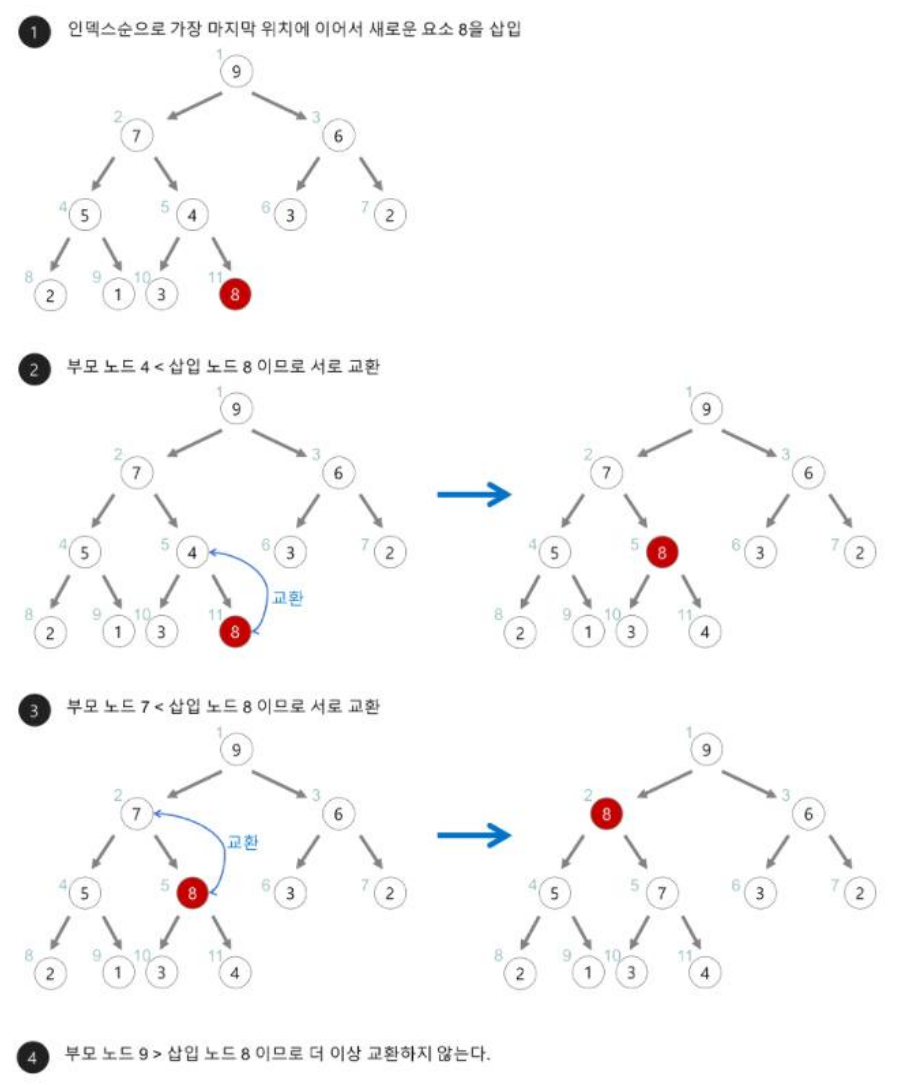
- 힙정렬 : 주어진 데이터를 힙 자료구조로 만들어 최대/최소값부터 하나씩 꺼내서 정렬하는 알고리즘입니다. 힙소트가 가장 유용한 경우는 전체를 정렬하는 것이 아니라 가장 큰 값 몇 개만을 필요로 하는 경우입니다. 시간복잡도는 O(n·log₂n)입니다.
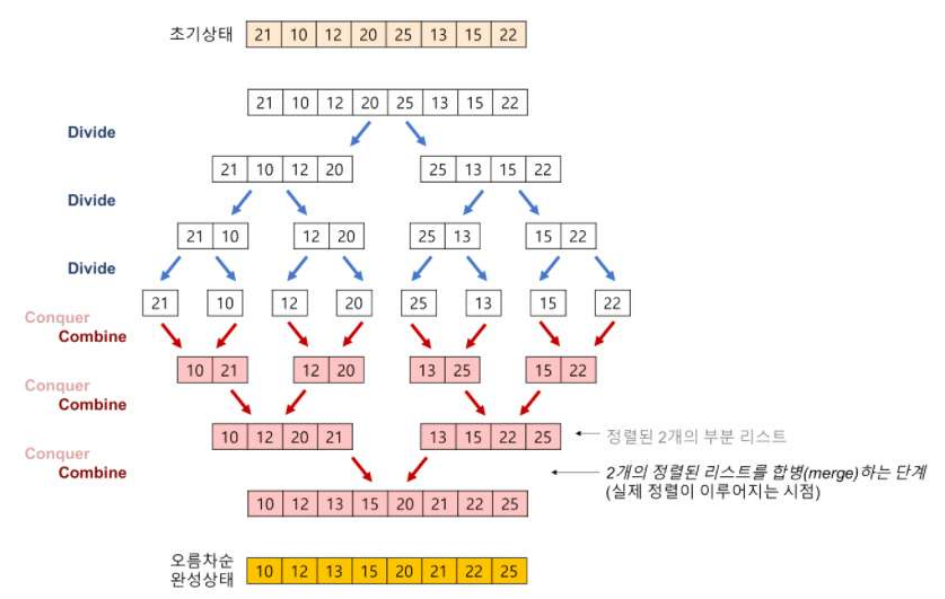
- 머지정렬 : 주어진 배열을 크기가 1인 배열로 분할하고 합병하면서 정렬을 진행하는 분할/정복 알고리즘입니다. 시간복잡도는 O(n·log₂n)입니다.
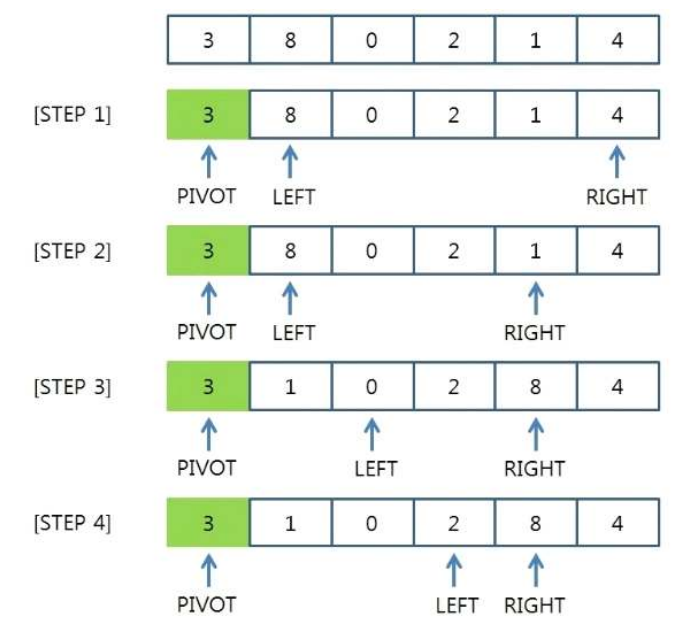
- 퀵정렬 : 매우 빠른 정렬 속도를 자랑하는 분할 정복 알고리즘 중 하나로, 합병정렬과 달리 리스트를 불균등하게 분할합니다. pivot을 설정하고, pivot보다 큰 값과 작은 값으로 분할하여 정렬합니다. 시간복잡도는 O(n·log₂n)이며, 리스트가 계속해서 불균등하게 나눠지는 경우 O(n²)까지 나빠질 수 있습니다.
- 삽입정렬 : 두 번째 값부터 시작하여 그 앞에 존재하는 원소들과 비교하여 삽입할 위치를 찾아 삽입하는 정렬 알고리즘입니다. 삽입 정렬의 평균 시간복잡도는 O(n²)이며, 빠른 경우 O(n)까지 높아질 수 있습니다.

동적프로그래밍 (DP)
문제를 여러 하위 문제로 나누어 푼 다음, 그것을 결합하여 해결.
부분 문제가 다른 문제를 해결하는데에 재사용. 속도 향상.
- 조건
1) 중복되는 부분 문제 : 주어진 문제는 같은 부분 문제가 여러번 재사용된다.
2) 최적 부분구조 : 새로운 부분 문제의 정답을 다른 부분 문제의 정답으로부터 구할 수 있다.
이진탐색 🟣
- 정렬된 리스트의 탐색 범위를 절반씩 줄여가며 데이터를 탐색하는 방법.
- 구현시 start/end/mid 혹은 min/max/avg 를 사용해 중간에 위치한 데이터를 반복적으로 비교한다.
DFS와 BFS 🟣
- DFS
깊이 우선 탐색.
그래프를 탐색할 때 끝 노드까지 검사 후 다른 경로를 탐색.
사용 자료구조 : - BFS
너비 우선 탐색.
그래프를 탐색할 때 같은 깊이에 해당하는 노드부터 탐색.
사용 자료구조 :
길찾기 알고리즘
- 크루스칼 (MST, 최소 신장 트리)
그래프 내의 모든 정점들을 가장 적은 비용으로 연결.
신장트리 : 그래프의 모든 정점을 포함 + 정점 간 서로 연결이 되며 사이클이 존재하지 않는 그래프 - A*
출발점과 도착점이 모두 주어졌을 때 최단경로 구하기.
휴리스틱(각 정점 간의 추정 거리를 알 수 있다) 기반. => 목적지에 얼마나 가까운 정점인지를 고려함. - 다익스트라(Dijkstra)
최단 경로 알고리즘.
BFS와 유사함. 그리디+DP의 형태
양의 가중치를 갖는 그래프에서 최단경로를 찾을때 사용.
가중 그래프에서 간선 가중치의 합이 최소가 되는 경로를 찾음.
특정 한 노드에서 다른 모든 노드까지의 최단거리를 구하는 알고리즘. - 벨만-포드 (Bellman Ford)
가중 '유향' 그래프에서 특정 한 노드로부터 다른 노드까지의 최단 경로를 구하는 알고리즘.
음의 가중치를 가질 경우 사용하지 못하는(순환구조를 가질 경우) 다익스트라의 단점을 해결하기 위해 등장.
다익스트라는 출발 노드에 연결된 노드만 탐색, 벨만포드는 모든 노드가 한번씩 출발점이 되어 다른 노드까지의 최소 거리를 구함. - 플로이드 와샬 (Floyd Warshall)
모든 노드 간의 최단거리.
음의 가중치가 있더라도 최단 경로 구할 수 있음. 그러나 음의 사이클이 존재한다면 벨만포드 사용해야 함.
각 단계마다 특정 노드 k를 거쳐가는 경우를 확인함. => i에서 j로 가는 것과 i에서 k, k에서 j로 가는 것 중 어느 것이 최소인지 검사.
4. 네트워크
OSI 7계층
통신 접속에서 완료까지의 과정을 7단계로 정의한 국제 통신 표준 계약
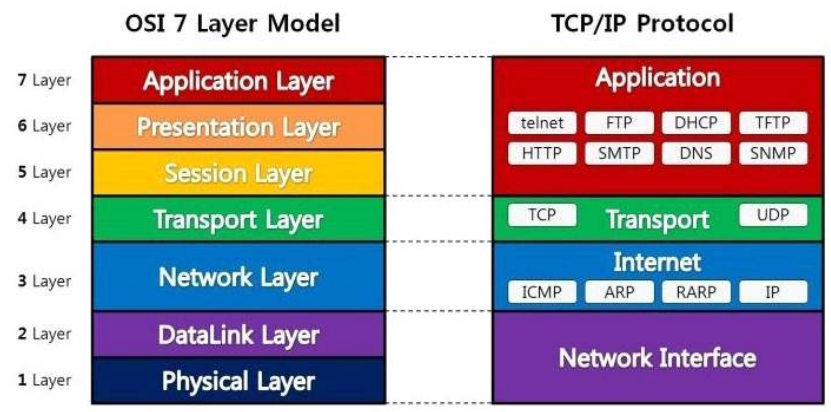
- 7계층(응용 계층) : 사용자와 직접 상호작용하는 인터페이스(응용 프로그램)를 제공
- 6계층(표현 계층) : 데이터의 형식(Format)을 정의하는 계층, 데이터 구분
- 5계층(세션 계층) : 컴퓨터끼리(양 끝단끼리) 통신을 하기 위해 세션을 만드는 계층
- 4계층(전송 계층/세그먼트) : 최종 수신 프로세스로 데이터의 전송을 담당하는 계층, TCP/UDP를 결정, 포트번호 구분
- 3계층(네트워크 계층/패킷) : 패킷을 목적지까지 가장 빠른 길로 전송하기 위한 계층
- 2계층(데이터링크 계층/프레임) : 데이터의 물리적인 전송과 에러 검출, 흐름 제어를 담당
하는 계층 - 1계층(물리 계층/비트) : 데이터를 비트로, 비트를 전기 신호로 바꾸어주는 계층
TCP/IP 4계층
- LINK 계층 : 물리적인 영역의 표준화에 대한 결과. 네트워크 표준과 관련된 프로토콜을 정의함.
- IP 계층 : 경로 검색. IP 자체는 비연결지향적이며 신뢰할 수 없는 프로토콜이다. 데이터를 전송할 때마다 거쳐야 할 경로를 선택하지만, 그 경로는 일정하지 않다. 도중에 문제가 발생하여 다른 경로를 선택해야 할 경우 그 과정에서 데이터가 손실되거나 오류가 생길 수 있으나 해결법은 없다.
- TCP/UDP(전송) 계층 : 데이터의 실제 송수신을 담당. TCP가 데이터를 보낼 때 기반이 되는 프로토콜이 IP이며, IP의 신뢰성 문제를 해결해주는 것이 TCP이다.
- APPLICATION(응용) 계층
TCP와 UDP 🟣
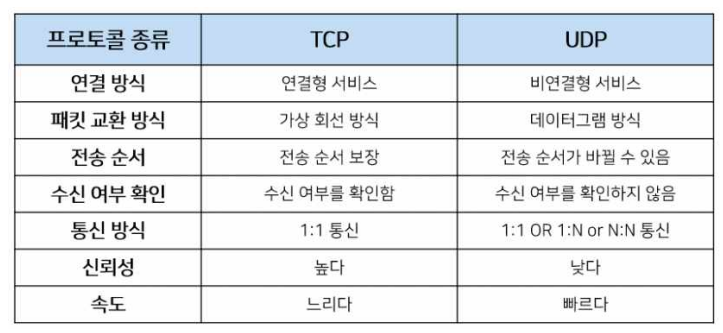
- TCP
연결형 서비스.
3 way handshaking 과정을 통해 연결을 설정.
(A가 B에게 SYN(M) 패킷을 보냄 → B는 SYN(M) 패킷을 받았다는 표시로
ACK(M+1)와 다음으로 보낼 목적지인 SYN(N) 패킷을 보냄 → A는 ACK(M+1)을 받았다고 확인한 후 SYN(N)으로 ACK(N+1)을 보냄 → 중간에 ACK 응답신호가 오지 않는다면 손실됐다고 생각하여 다시 전송)
높은 신뢰성을 보장하지만 속도가 느림.
파일 교환과 같은 경우에 사용. - UDP
비연결형 서비스.
신뢰성이 떨어지지만 수신 여부를 확인하지 않기 때문에 속도가 빠름.
데이터의 순서나 유실되는 것들이 보장되지 않음.
실시간이 중요한 스트리밍에 주로 사용. - 통신상태가 좋지 않은 환경에서는 어떤 프로토콜을 사용? : UDP
HTTP 와 HTTPS
- HTTP (Hyper Text Transfer Protocal)
서버/클라이언트 모델을 따라 데이터를 주고받기 위한 프로토콜.
응용 계층의 프로토콜로, TCP/IP 위에서 작동.
평문 데이터 전송 프로토콜. 보안이 낮음. - HTTPS
암호화가 추가된 프로토콜.
자신의 공개키를 갖는 인증서를 발급하여 보내는 메세지를 공개키로 암호화.
개인키를 가지고 있어야만 복호화가 가능하기 때문에 기업을 제외한 누구도 데이터를 얻을 수 없음.
5. 운영체제
프로세스와 스레드 🟣
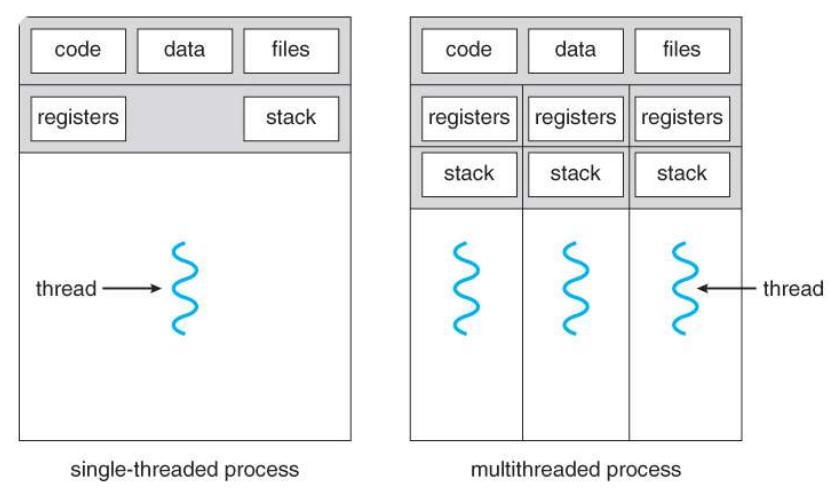
- 프로세스
- 메모리에 올라와 실행되고 있는 프로그램의 인스턴스 = 실행중인 프로그램
- 운영체제로부터 독립된 메모리 영역을 할당받는다. (다른 프로세스 자원에 접근 X)
- 프로세스들은 독립적이기 때문에 통신하기 위해 IPC를 사용해야 함.
- 프로세스는 최소 1개의 스레드(메인 스레드)를 가지고 있음 - 스레드
- 하나의 프로세스 내에서 할당받은 자원을 공유하며 실행되는 독립적인 작업단위
- 스레드는 프로세스 내에서 Stack만을 따로 할당 받고, Code, Data, Heap 영역은 공유함. → Stack에는 함수의 호출 정보가 저장되기 때문
- 스레드는 프로세스의 자원을 공유하기 때문에 새로운 자원을 할당받을 필요가 없어 실행속도가 빠름.
- 프로세스 내에 존재하며, 프로세스가 할당받은 자원을 이용해 실행.
멀티 프로세스와 멀티 스레드
- 멀티 프로세스
- 하나의 프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 1개의 작업을 처리하도
록 함
- 1개의 프로세스가 죽어도 자식 프로세스 이외의 다른 프로세서들은 계속 실행됨
- Context Switching을 위한 오버헤드(캐시 초기화, 인터럽트 등)가 발생한다.
- 프로세스는 각각 독립적인 메모리를 할당받았기 때문에 통신하는 것이 어렵다. - 멀티 스레드
- 하나의 프로세스를 여러 개의 스레드로 구성하여 각 스레드가 1개의 작업을 처리하도록
함
- 프로세스를 위해 자원을 할당하는 시스템 콜이나 Context Switching의 오버헤드를 줄일 수
있음.
- 스레드는 메모리를 공유하기 때문에 통신이 쉽고, 자원을 효율적으로 사용할 수 있음
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받음
- 여러 스레드가 하나의 자원에 동시에 접근하는 경우 자원 공유(동기화)의 문제가 발생
데드락(DeadLock, 교착상태) 🟣
- 한정된 자원을 여러 프로세스가 사용하고자 할 때 발생하는 상황으로, 프로세스가 자원을 얻기 위해 무한하게 대기하는 상태.
(ex) P1이 자원 A를 가진 채로 자원 B를 원하고, P2가 자원 B를 가진 채로 자원 A를 원할 때. - 발생 조건
- 상호 배제 : 한 프로세스가 사용하는 자원을 다른 프로세스가 사용할 수 없는 상태
- 점유 : 자원을 할당받은 상태에서 다른 자원을 할당받기를 기다리는 상태
- 비선점 : 어떤 프로세스도 다른 프로세스의 자원을 강제로 빼앗지 못하는 상태
- 순환 : 프로세스들이 사이클 형태로 자원을 대기하는 상태
세마포어와 뮤텍스
- 세마포어(Semaphore)
- Signaling 메커니즘으로 락을 걸지 않은 스레드도 signal을 사용해 락을 해제할 수 있음. 세마포어의 카운트를 1로 설정하면 뮤텍스처럼 활용할 수 있다.
- 운영체제 또는 프로그램 내에서 공유 자원에 대한 접속을 제어하기 위해 사용되는 신호. 공유자원에 접근할 수 있는 최대 허용치만큼 동시 사용자 접근이 가능. - 스레드들은 자원 접근 요청을 할 수 있고, 세마포어에서는 카운트가 하나씩 줄어들게 되며 리소스가 모두 사용중인 경우(=카운트 0) 다음 작업은 대기. - 뮤텍스(Mutex)
- Locking 메커니즘으로 락을 걸은 스레드만이 임계 영역을 나갈 때 락을 해제할 수 있음
- 상호배제. 임계영역에 하나의 스레드만을 허용하기 때문에 해당 영역에 접근하려는 다른 스레드들을 강제로 막음으로써 허용된 스레드가 영역을 빠져나올 때 까지 대기
컨텍스트 스위칭(Context Switching)
- 인터럽트를 발생시켜 CPU에서 실행중인 프로세스를 중단하고, 다른 프로세스를 처리하기 위한 과정.
현재 실행중인 프로세스의 상태(Context)를 먼저 저장하고, 다음 프로세스를 동작시켜 작업을 처리한 후 이전에 저장된 프로세스의 상태를 다시 복구한다.
(ex) A 프로세스가 진행하던 내용들을 PCB에 기록하고 B 프로세스로 전환. 다시 A 프로세스가 실행될 때에는 PCB에 기록된 내용을 바탕으로 진행. - 인터럽트 : CPU가 프로세스를 실행하고 있을 때 입출력 하드웨어 등의 장치나 예외상황이 발생하여 처리가 필요함을 CPU에게 알리는 것.
6. 수학
벡터의 내적과 외적 🟣
- 내적
- 어떤 물체가 각도 범위내에 들어와있는지 확인하고 싶을 때.
- A·B = |A||B|cosθ
- A·B > cosθ 이면 B는 θ 범위 내에 있음.
- 평면과 점(A) 사이의 거리를 구할 때 : 평면 위 임의의 점 B와 A의 방향벡터와 평면의 단위벡터를 내적
- 교환법칙 성립 - 외적
- 교환법칙 성립 안함. 대신 크기(평행사변형)는 같음.
- 두 벡터에 모두 수직한 벡터를 구함.
- 오른손 법칙.
- 발판을 위(오른쪽)에서 부딪혔는지 아래(왼쪽)에서 부딪혔는지 확인 가능.
- 평면의 법선벡터를 구할 때.
7. 유니티 엔진 관련
MonoBehabvior
유니티에서 제공하는 기본 클래스.
유니티에서 동작하는 오브젝트는 모두 상속받아야 함.
Start(), Update() 등의 메소드가 포함됨.
.Net
NGUI, UGUI
- NGUI
- 차세대 UI.
- 드래그 패널, 스크롤 뷰, 버튼, 라벨 등
- 스프라이트 기반. 아틀라스를 사용하여 드로우콜을 줄임.
- 이벤트 시스템
- 정렬 및 배치 기능 - UGUI
- 유니티 내장 UI
- 캔버스
- 이벤트 시스템
코루틴
단일 스크립트 내에서 코드를 비동기적으로 실행할 수 있는 기능.
Dotween
게임 최적화 방법
- 오브젝트 풀링
- 드로우콜 줄이기
- 프로파일러 사용
가비지 컬렉터 (GC)
박싱, 언박싱 🟣
- 박싱 : 값 타입을 참조 타입으로 변환. 힙에 할당됨.
- 언박싱 : 참조 타입을 값 타입으로 변환
상태머신
리플렉션
https://shung2.tistory.com/1109
Mono와 IL2CP
Unity 게임 엔진에서 사용되는 스크립팅 백엔드(백엔드 컴파일러).
-
Mono: Mono는 Unity의 기본 스크립팅 백엔드 중 하나입니다. C# 코드를 중간 언어로 컴파일하고 실행할 수 있는 플랫폼 중립적인 환경을 제공합니다. 이는 C# 코드를 해당 플랫폼에서 실행 가능한 기계어로 변환하기 위한 JIT(Just-In-Time) 컴파일러를 사용합니다. Mono는 Unity가 여러 플랫폼에서 실행될 수 있도록 하는 데 기여하고 있습니다.
-
IL2CPP: IL2CPP는 Unity의 다른 스크립팅 백엔드 중 하나로, C# 코드를 C++ 코드로 변환하여 더 빠른 성능을 제공합니다. IL2CPP는 C# 소스 코드를 중간 언어(IL)로 컴파일하고, 이후 해당 IL을 특정 플랫폼의 네이티브 코드로 변환하여 실행합니다. 이 방식은 게임의 성능을 최적화하고 메모리 사용량을 줄이는 데 도움을 줄 수 있습니다.
드로우콜과 배치
드로우 콜 (Draw Call):
드로우 콜은 GPU에게 렌더링할 오브젝트를 그리라고 명령하는 것을 의미합니다.
각각의 드로우 콜은 오브젝트의 한 번의 렌더링을 나타냅니다.
게임 엔진은 화면에 보이는 요소들을 렌더링하기 위해 드로우 콜을 사용합니다.
많은 수의 드로우 콜이 있으면 그만큼 GPU가 그려야 할 렌더링 작업이 많아져 성능에 영향을 줄 수 있습니다.
배치 (Batching):
배치는 GPU에서 처리할 작업을 최소화하여 성능을 향상시키는 기술입니다.
정적 배칭(Static Batching)과 동적 배칭(Dynamic Batching)으로 나뉩니다.
정적 배칭은 게임 오브젝트가 변경되지 않는 경우에 적용되며, 유니티에서는 유사한 속성을 가진 정적 오브젝트들을 하나의 배치로 합쳐 성능을 향상시킵니다.
동적 배칭은 런타임 중에도 게임 오브젝트가 변경되어도 적용되는 방식입니다. 유니티에서는 GPU 인스턴스화, 스크립트로 배칭 처리하는 등의 방법으로 이를 구현할 수 있습니다.
렌더링 파이프라인
https://shung2.tistory.com/511
👀 기타 참고 자료
정성스럽게 정리해주신 분들이 많다.
