
용어
- 시작노드 : 루트
- 연결선 : 간선
- 자식노드가 없는 노드 : 리프(나뭇잎)
일반적인 트리 활용 예시
- html DOM
- Network Routing
- Abstract Syntax Tree
- Artificial Intelligence
- Folders in Operating Systems
- Json
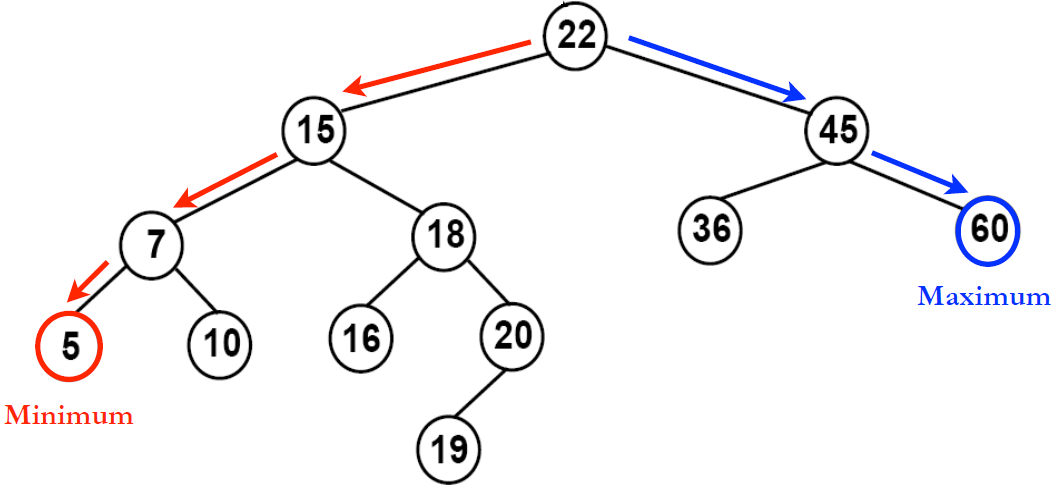
이진 검색 트리의 자식노드는 항상 2가지이고, 좌측의 자식노드 부모노드보다 작아야만 하고, 우측의 자식노드는 부모노드보다 커야만한다. 이렇게 구성되면 노드를 검색할 때 root Node부터 자식과의 값을 비교하는 것을 반복하여 결국 원하는 노드를 찾아낼 수 있게 된다.
이진검색트리를 구현한 코드는 아래와 같다.
이진검색트리
class Node {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
insert(value) {
const newNode = new Node(value);
if (this.root === null) {
this.root = newNode;
return this;
}
let current = this.root;
while (true) {
if (value === current.value) return undefined;
if (value < current.value) {
if (current.left === null) {
current.left = newNode;
return this;
}
current = current.left;
} else if (value > current.value) {
if (current.right === null) {
current.right = newNode;
return this;
}
current = current.right;
}
}
}
find(value) {
if (this.root === null) return false;
let current = this.root,
found = false;
while (current && !found) {
if (value < current.value) {
current = current.left;
} else if (value > current.value) {
current = current.right;
} else {
found = true;
}
}
if (!found) return undefined;
return current;
}
contains(value) {
if (this.root === null) return false;
let current = this.root,
found = false;
while (current && !found) {
if (value < current.value) {
current = current.left;
} else if (value > current.value) {
current = current.right;
} else {
return true;
}
}
return false;
}
}
Big O
이진 검색 트리에서 어떤 노드의 자식노드는 항상 2개가 된다. 즉, 이진검색트리에서 노드의 개수가 기존보다 2배가 증가한다는 것은 모든 노드들이 직계 자식 노드를 2개씩 추가로 가지게 되었다는 것이다.
이 말은 즉슨 2배가 될 때마다 한 세대 아래의 자식들이 생겼다는 것이고, 이는 2배가 될 때마다 검색 과정은 오직 1회만 추가된다는 것이다. 결국 노드의 수가 4배가 되면 2회증가, 8배면 3회 증가, 16배면 4회가 증가된다.
이 때, 트리의 높이(세대의 수)를 h(h는 결국 검색 횟수가 된다.), 노드의 개수를 n이라고 할 때,
=> n = 2^(h+1) - 1
=> 2^(h+1) = n + 1
=> h = log(n+1) - 1
따라서 O(logN)의 시간 복잡도를 가지게 된다.
단, 연결리스트처럼 리니어하게 한 줄로 구성된 이진검색트리는 O(N)의 시간복잡도를 가지게 된다. 이럴 경우에는 root를 다시 잡아서 전체 목록을 다시 구성하거나, 연결리스트를 사용하는 것이 낫다.
트리 순회
BFS (너비우선탐색)
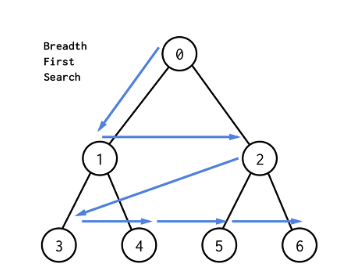
BFS는 그림과 같이 root부터 순회를 시작하여 한층이 완료되면 다음 층으로 넘어가는 식으로 순회한다.
// 트리에 BFS method추가
BFS() {
const res = [];
let node = this.root;
const queue = [node];
while (queue.length) {
node = queue.shift();
res.push(node.value);
if (node.left) queue.push(node.left);
if (node.right) queue.push(node.right);
}
return res;
}
const tree = new BinarySearchTree();
tree.insert(10);
tree.insert(6);
tree.insert(15);
tree.insert(3);
tree.insert(8);
tree.insert(20);
log(tree.BFS()); // [ 10, 6, 15, 3, 8, 20 ]DFS (깊이 우선 탐색)
전위탐색
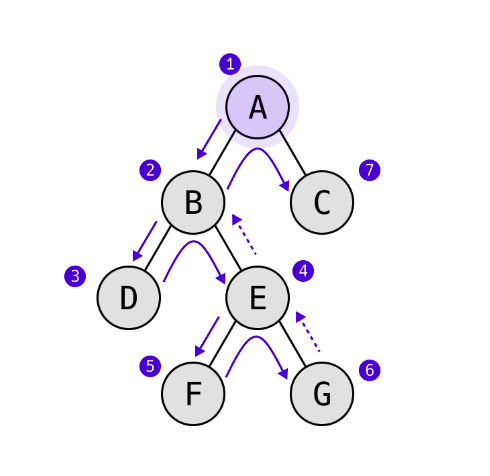
전위탐색은 루트 노드를 먼저 탐색하고, 자식 노드를 탐색하는 방식이다.
DEFPreOrder() {
const res = [];
function traverse(node) {
res.push(node.value);
node.left && traverse(node.left);
node.right && traverse(node.right);
}
traverse(this.root);
return res;
}
const tree = new BinarySearchTree();
tree.insert(10);
tree.insert(6);
tree.insert(15);
tree.insert(3);
tree.insert(8);
tree.insert(20);
log(tree.DEFPreOrder()); // [ 10, 6, 15, 3, 8, 20 ]
후위탐색는 왼쪽 자식 노드를 탐색하고, 오른쪽 자식 노드를 탐색하고, 루트 노드를 탐색하는 방식이다.
후위탐색은 코드에서 전위탐색과 배열로 push하는 시점만 다르다.
DEFPostOrder() {
const res = [];
function traverse(node) {
node.left && traverse(node.left);
if (node.right) traverse(node.right);
res.push(node.value);
}
traverse(this.root);
return res;
}
const tree = new BinarySearchTree();
tree.insert(10);
tree.insert(6);
tree.insert(15);
tree.insert(3);
tree.insert(8);
tree.insert(20);
log(tree.DEFPostOrder()); // [ 3, 8, 6, 20, 15, 10 ]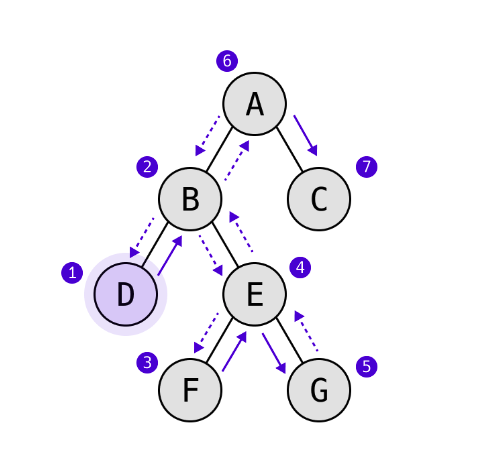
정위탐색는 왼쪽 자식 노드를 탐색하고, 루트 노드를 탐색하고, 오른쪽 자식 노드를 탐색하는 방식이다.
정위탐색은 전위와 후위와 마찬가지로 배열에 push하는 시점만 다르다.
DEFInOrder() {
const res = [];
function traverse(node) {
node.left && traverse(node.left);
res.push(node.value);
node.right && traverse(node.right);
}
traverse(this.root);
return res;
}
const tree = new BinarySearchTree();
tree.insert(10);
tree.insert(6);
tree.insert(15);
tree.insert(3);
tree.insert(8);
tree.insert(20);
log(tree.DEFInOrder()); // [ 3, 6, 8, 10, 15, 20 ]어떤 탐색을 사용할까?
BFS vs DFS
우선 모든 노드를 탐색하는 것이기 때문에 시간 복잡도는 동일하다.
깊이보다 너비가 넓은 트리의 경우에는 DFS가 더 적은 공간을 점유한다. 반대로 깊이가 더 넓은 경우에는 BFS가 유리하다. 이를 고려하여 선택하면 된다.
전위 vs 중위
먼저 정위로 깊이 우선 순회를 하면 결과가 오름차순으로 나오게 된다. 이 경우는 리스트를 받아서 데이터베이스에 넣는경우, 순서대로 무언가 작업을 해야 한다면 도움이 될 수 있다.
전위로 깊이 우선 순회를 하면 첫번째 노드가 루트인 것을 알 수 있고, 그 뒤에 나오는 인자들의 크기를 비교하면 원래 트리 형태를 알 수 있다. 이를 활용하면 "트리 평탄화 -> 파일이나 db에 저장 -> 다시 트리화" 이런 방식의 작업에 유리하다.
