엘라스틱서치와 키바나를 결합하면 텍스트 문서로부터 로그 파일, 메트릭, 전자상거래 트래픽, 기업의 비즈니스 트랜잭션에 이르기까지 다양한 데이터를 탐색하고 조사하는 기회를 얻을 수 있다.
소개
키바나를 단순 데이터 시각화 툴로 오해할 수 있는데 키바나는 엘라스틱 스택의 관리, 모니터링, 솔루션을 총괄하는 메인 UI다 키바나의 기능은 아래와 같이 세 가지로 구분할 수 있다.
- 키바나의 주요 기능
- 데이터 분석과 시각화 툴: 오픈소스 기반의 데이터 탐색 및 시각화 도구 제공
- 엘라스틱 관리: 보안, 스냅샷, 인덱스 관리, 개발자 도구 등을 제공
- 엘라스틱 중앙 허브: 모니터링을 비롯해 엘라스틱 솔루션을 탐색하기 위한 포털
여기서는 키바나가 제공하는 기능중 데이터 분석과 시각화 기능을 예제로 알아보자. 키바나는 시스템의 끝단에서 사용자에게 정보를 효율적으로 제공한다. 엘라스틱 서치에서 제공되는 시계열 데이터나 위치 분석같은 다양한 분석 결과를 키바나를 통해 시각화한다.
- 키바나 시각화 기능
- 디스커버: 데이터를 도큐먼트 단위로 탐색해 구조와 관계등을 확인할 수 있다.
- 시각화: 다양한 그래프 타입으로 데이터 시각화를 할 수 있다.
- 대시보드: 그래프, 지도 등을 한 곳에서 확인하면서 다양한 인사이트를 얻을 수 있다.
- 캔버스: 그래프와 이미지 등을 프레젠테이션 슬라이드처럼 구성할 수 있다.
- 맵스: 위치 기반 데이터를 지도 위에 표현할 수 있다.
여기서는 디스커버와 시각화에 대해서만 문서화 하였습니다.
인덱스 패턴
키바나에서 시각화를 하기 위해서는 반드시 엘라스틱 서치 인덱스에 연결되어야만 한다. 그래서 키바나를 범용적인 시각화 툴로 사용하기에는 무리가 있다. 하지만 오픈소스면서 다양한 그래프와 지도를 지원하고 빅데이터 처리가 가능하다는 장점이 있다.
키바나는 데이터 소스를 엘라스틱서치 인덱스에서 가져오는데 이를 인덱스 패턴이라고 한다. 키바나 인덱스 패턴은 인덱스 매핑 정보들을 키바나에 사용하기 적합하게 미리 캐싱해 둔 것으로 여러 개의 인덱스에 대한 메타 데이터를 병합해 저장했다가 검색이나 시각화 생성시 활용한다.
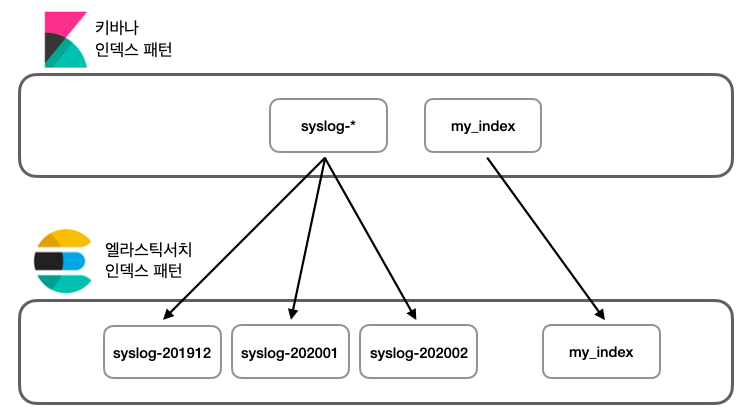
키바나에서 엘라스틱서치 인덱스에 직접 접근하지 않고 syslog-* 인덱스 패턴에 접근해 쿼리를 하고 시각화한다. 이렇게 하는 이유는 복수의 인덱스에 대한 매핑을 사전에 병합해 쿼리 생성이나 시가고하에 활용할 수 있기 때문이다.
예제
(여기서는 kibana_index1, kibana_index2 로된 인덱스가 이미 엘라스틱 서치에 있다고 가정)
키바나는 왼쪽 상단의 토글 메뉴에서 Management -> Stack Management 를 선택한다. 이후 좌측바에서 Kibana -> Index Patterns 에 들어간다.
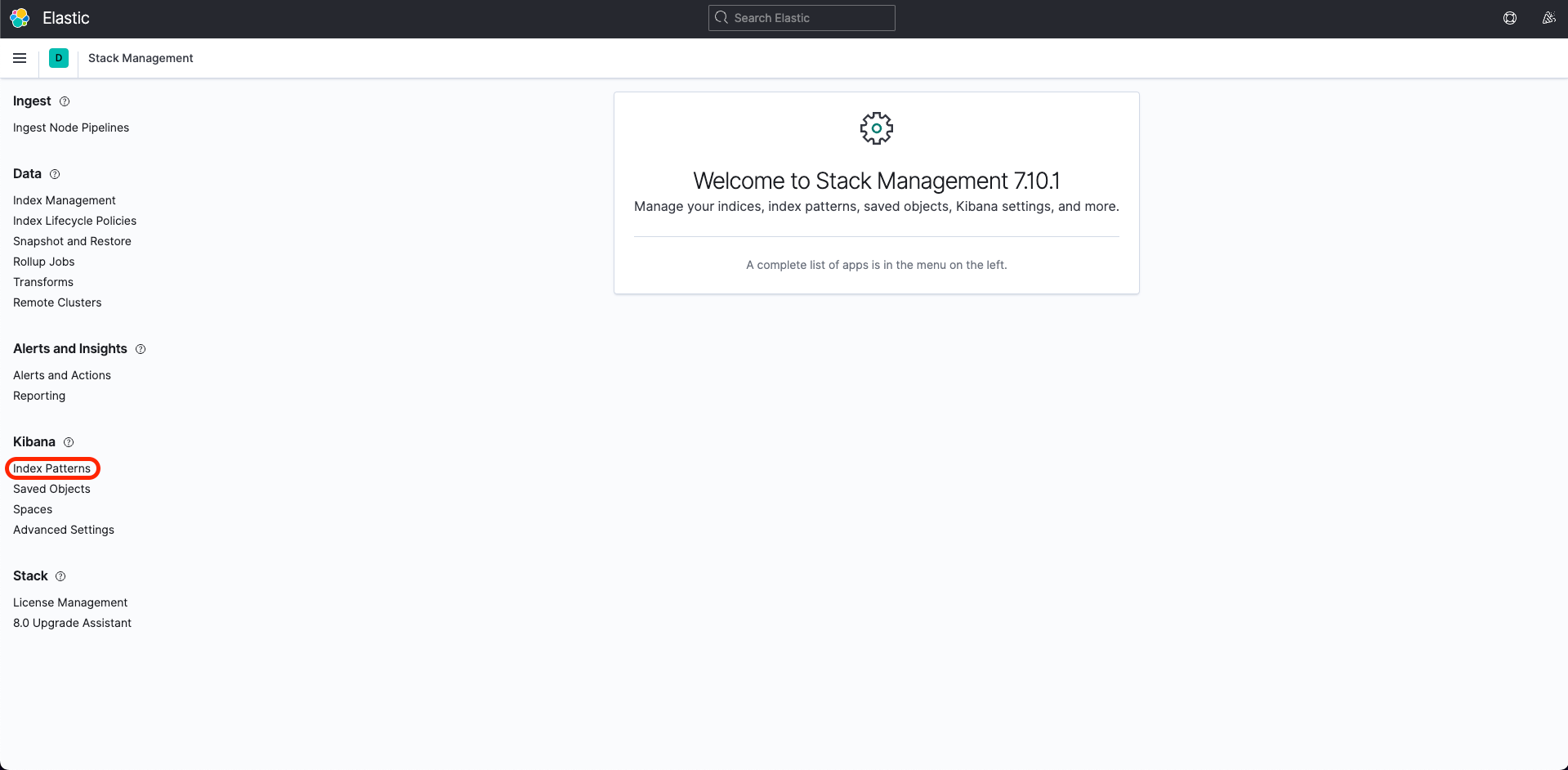
Create Index pattern 을 선택해서 인덱스 패턴을 생성해보자. kibana_ind 까지만 입력하면 kibana_index1, kibana_kibana2 가 같은 인덱스 패턴으로 지정될 수 있다고 굵은 글씨체로 보인다.
인덱스 패턴명에는 와일드 카드(*) 와 쉼표(,)를 사용해 복수의 패턴을 포함할 수 있고, 패턴 앞에 마이너스(-) 기호를 붙여 특정 패턴을 제외할 수도 있다.
Discover 메뉴에서 인덱스 패턴 확인
- Discover 메뉴로 가보면
kibana_index*패턴을 이용해 데이터 탐색이 가능하다.
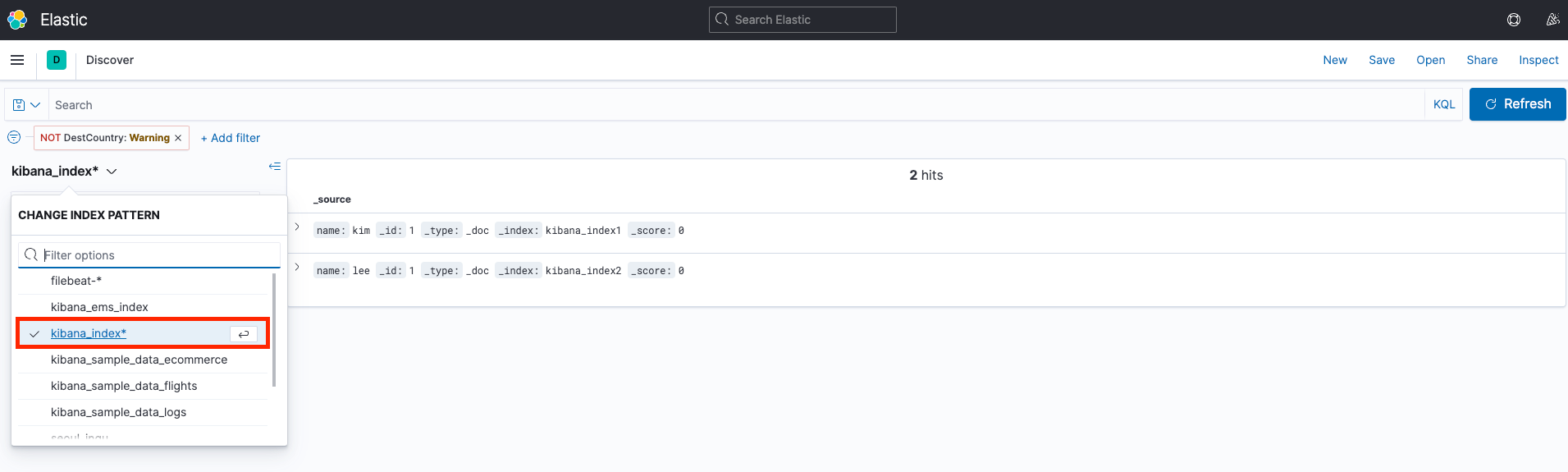
디스커버
Discover 메뉴는 데이터를 확인하고 탐색하기 위한 용도로 사용한다. 문서 / 이벤트 / 도큐먼트 / 로그의 시간에 따른 발생량을 히스토그램으로 보여주기도 하고 데이터 구조나 필드 타입 등을 간단히 확인할 수도 있다. 또한 적절한 쿼리와 필터 등을 이용해 데이터를 탐색해가면서 추후 시각화 등에서 활용할 수 있다.
디스커버 화면구성
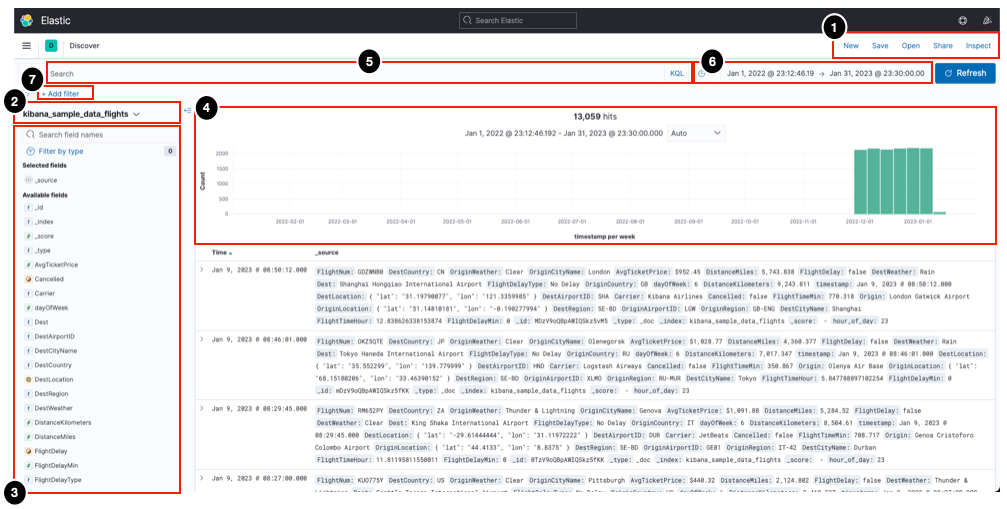
-
툴바: 결과를 저장하고 불러오는 등의 기능 버튼이 위치한다.
-
인덱스 패턴: 탐색할 인덱스 패턴을 선택할 수 있다.
-
사이드 바: 필드 타입과 필드명을 볼 수 있고 데이터 구조를 확인할 수 있다. 데이터가 너무 많다면 특정 필드만 선택해서 볼 수도 있다.
-
시계열 히스토그램: 히스토그램 형태로 시간에 따른 발생량을 확인할 수 있다. 인덱스 패턴에 시간 / 날짜 필드가 없는 경우에는 보이지 않는다.
-
쿼리바: 쿼리를 이용해 데이터를 검색할 수 있다.
-
타임 피커: 시계열 데이터의 시간 범위를 조정할 수 있다.
-
필터바: 쿼리를 필터처럼 사용할 수 있다.
쿼리바
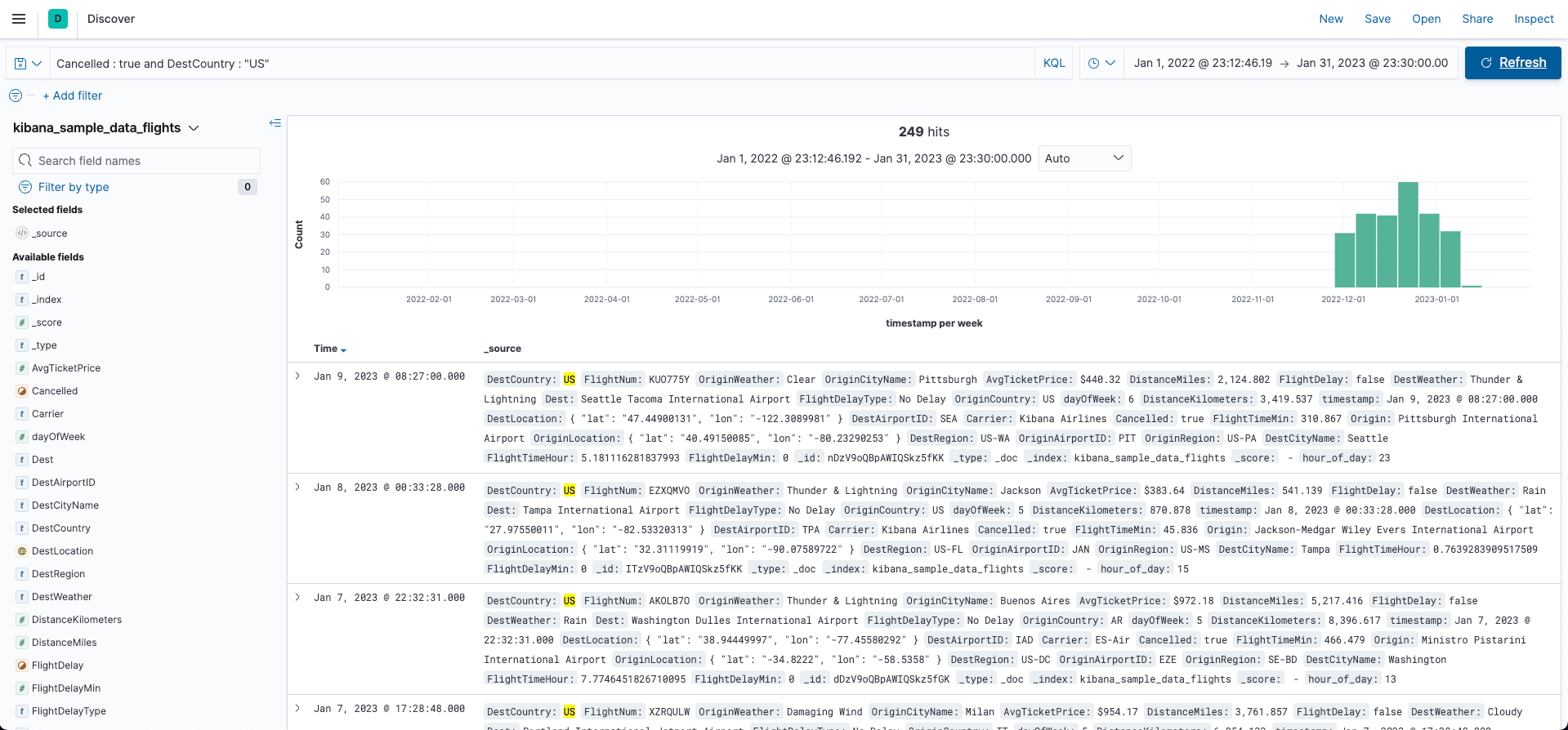
쿼리바는 기본적으로 KQL 언어를 이용한다. 아래의 그림은 특정 인덱스 패턴에 대하여 쿼리를 적용하여 특정 데이터만 검색한 예제이다.
- 인덱스: 비행기 항공 정보
- 쿼리:
Cancelled: true and DestCountry: "US"Cancelled: 예약 취소 여부DestCountry: 목적지
필터바
필터바는 쿼리바와 하는 역할이 비슷하지만 필드를 개별적으로 처리할 수 있다.
예를 들어, 위와 다르게 Cancelled : true 결과와 DestCountry : "US" 를 따로 보려고 한다고 해보자. 쿼리바로 이를 구현하려면 매번 KQL 형태로 쿼리를 작성해야 한다. 쿼리바는 쿼리를 저장하는 기능이 있지만 어쨌든 쿼리를 실행할 때는 쿼리를 재작성하는 것이 원칙이다. 하지만 필터바는 개별적으로 필드를 제어할 수 있다.
- 필터 사용 예제1
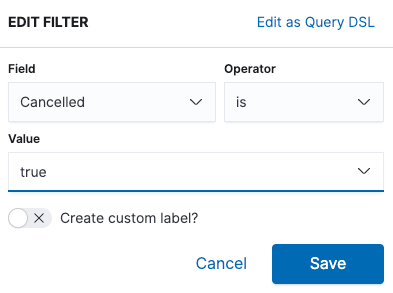
- 아래는 이전의
Cancelled : true쿼리를 필터바로 구현한 것이다.
- 아래는 이전의
- 필터 사용 예제2
- 아래 필터바에 2개의 쿼리가 AND 로 연산되어 있고 이는 이전의 KQL 과 같은 결과가 나온다.
- 2개의 쿼리가 분리되어 있지만 분리된 쿼리는 AND 연산으로 묶이기 때문이다.
- 생성된 필터를 조합하면 강력한 기능을 구현할 수 있다.
시각화
Visualize 메뉴는 엘라스틱 서치에 저장된 데이터를 그래프나 표, 지도 등 다양한 타입으로 보여주는 역할을 한다. 라인, 바, 파이 차트부터 맵 등 다양한 시각화 타입을 지원한다. 데이터를 가장 효과적으로 보여줄 수 있는 방법을 떠올리고 그에 맞는 타입을 선택하면 된다.
Visualize 메뉴는 사용이 어렵지 않지만, 엘라스틱서치의 기능을 활용해 가공한 데이터를 보여주는 것이므로 다음의 개념을 알고 있으면 좋다.
- 메트릭 집계: 평균 / 최소 / 최대 같은 수량을 계산한다.
- 버킷 집계: 특정 기준에 맞춰 데이터를 분리한다.
- 파이프라인 집계: 집계 결과를 입력으로 받아 다시 집계를 한다.
1) 막대그래프
- X 축 버킷 집계 종류
- Data Histogram:
날짜 / 시간데이터 타입을 가진 필드만 사용. 일정한 주기를 기준으로 버킷을 구분 - Data Range:
날짜 / 시간데이터 타입을 가진 필드만 사용 가능. 사용자가 임의의 범위를 지정해 버킷을 구분 - Filters: 필터 적용 가능
- Histogram: 일정한 주기를 기준으로 버킷을 구분
- Ipv4 Range: ip 타입을 가진 필드만 사용 가능. ip 범뤼를 임의 지정해 버킷을 구분
- Range: 사용자가 임의의 범위를 지정해 버킷을 구분
- Significant Terms: 필드의 유니크한 값 중 통계적으로 의미있는 용어를 기준으로 구분
- Terms: 필드의 유니크한 값을 기준으로 구분
- Data Histogram:
아래의 예제는 항공 관련 데이터 샘플을 사용하였다.
예제1
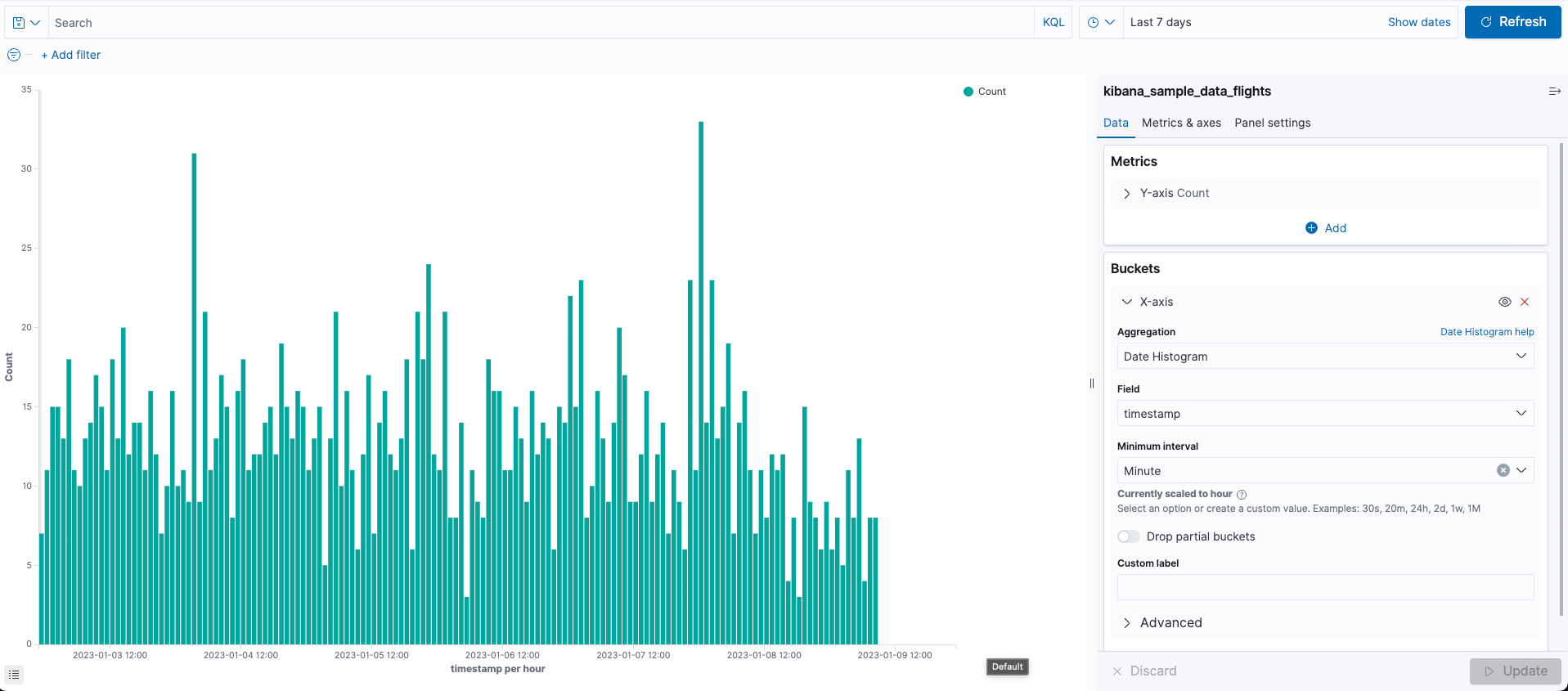
- Metrics > Y-axis Count
- Bucket
- X-axis
- Aggregation: Date Histogram
- Field: timestamp
- Minimum interval: Minute
- X-axis
예제2
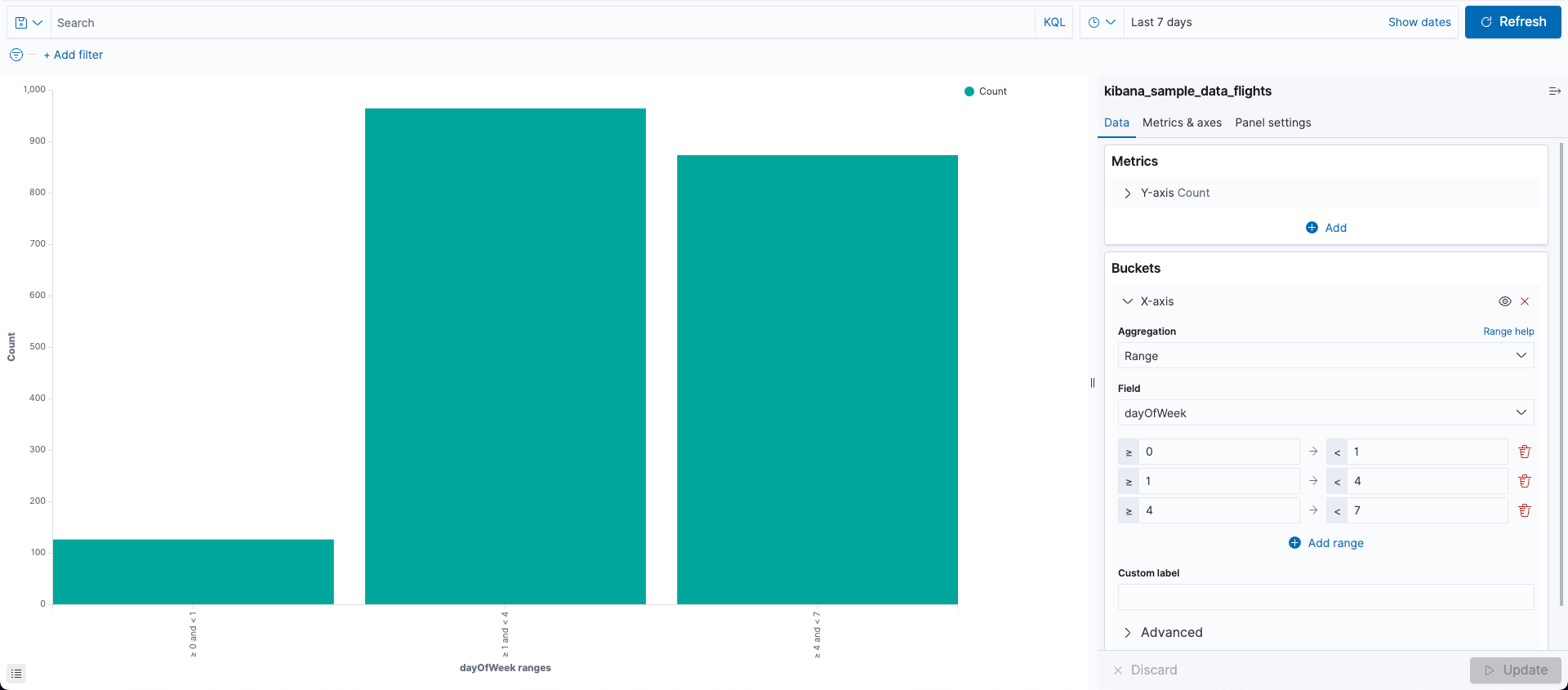
- Metrics > Y-axis Count
- Buckets
- X-axis
- Aggregation: Range
- Field: dayOfWeek
- 0, 1
- 1, 4
- 4, 7
- X-axis
예제3
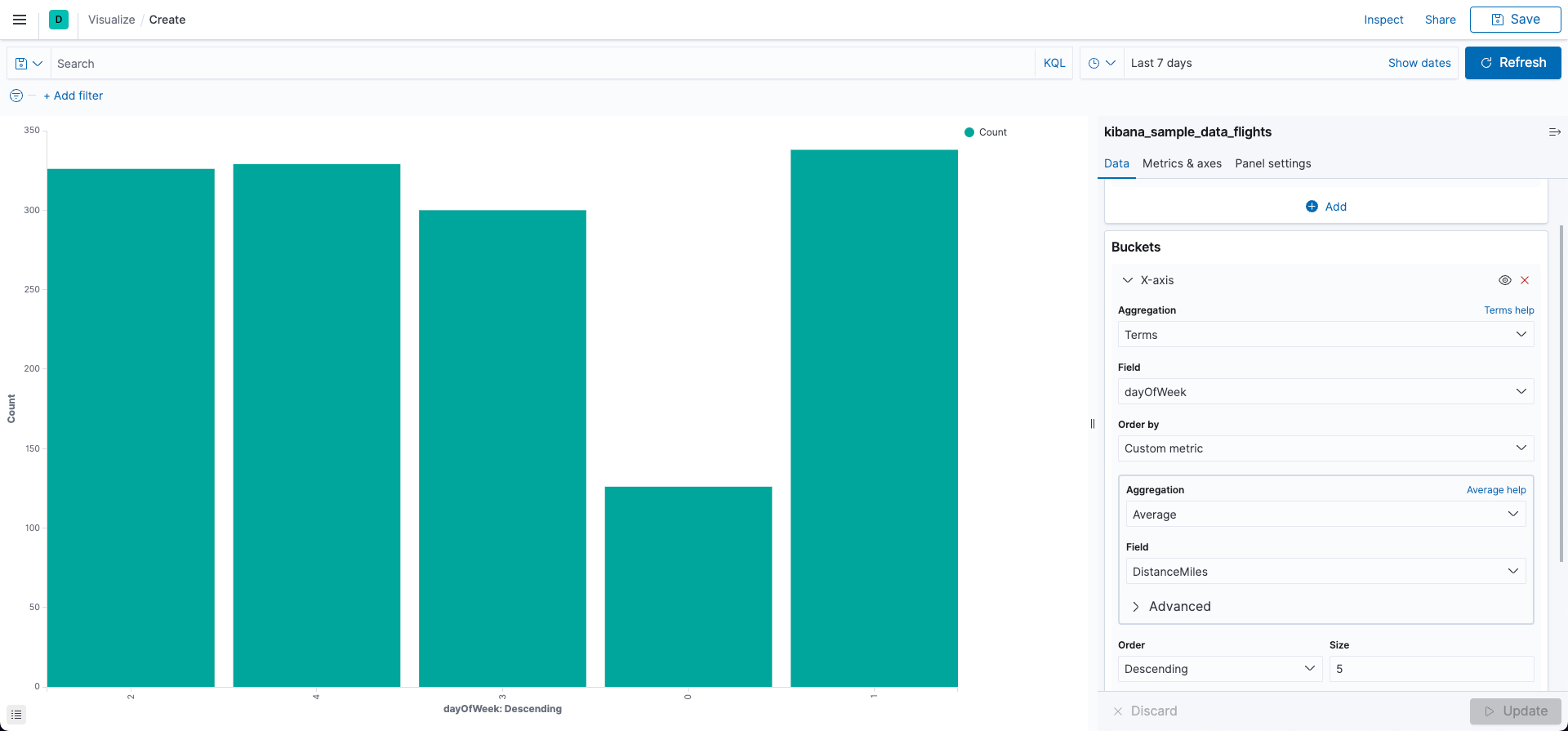
- Metrics > Y-axis Count
- Buckets
- X-axis
- Aggregation: Terms
- Field: dayOfWeek
- Order by: Custom metric
- Aggregation: Average
- Field: DistanceMiles
- Order: Descending
- Size: 5
- X-axis
예제4
-
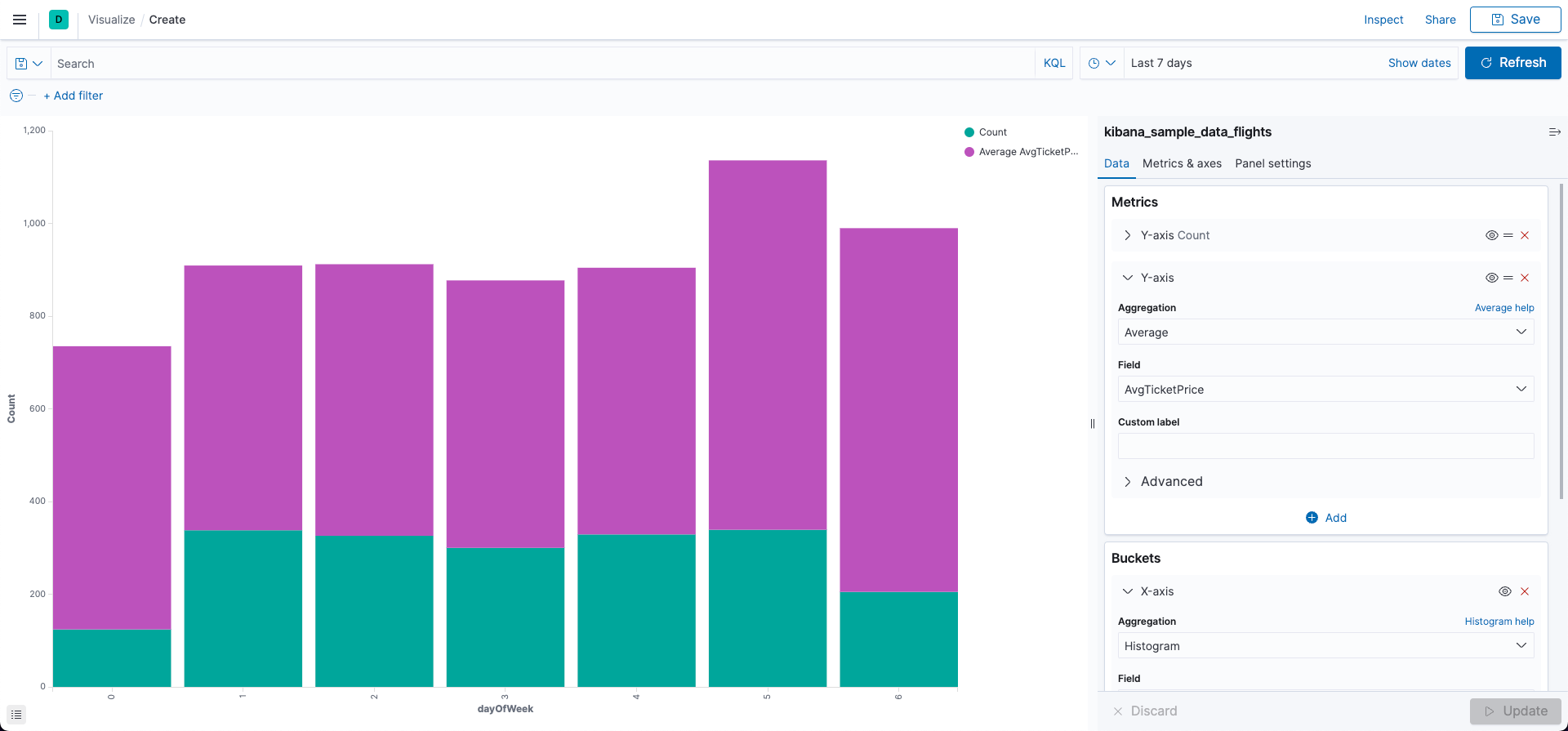
Metric > Y-axis Count
- Y-axis
- Aggregation: Average
- Field: AvgTicketPrice
- Y-axis
-
Bucket
- X-axis
- Aggregation: Histogram
- Field: dayOfWeek
- interval: 1
- X-axis
예제5
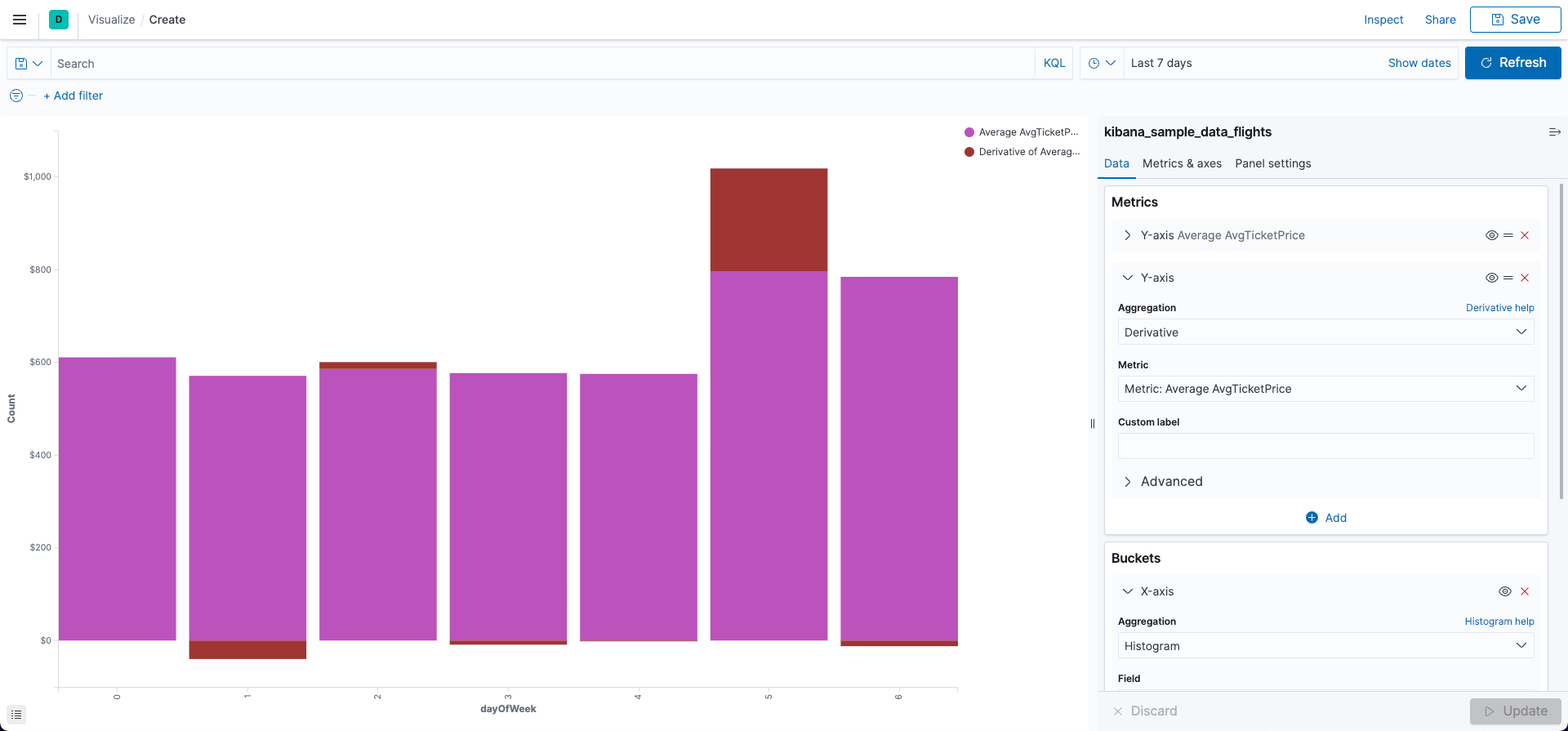
여기서는 미분(Derivative) 집계를 사용했다. 부모 파이프라인 집계의 경우 부모가 되는 집계가 필요한데 여기서는 이전 예제에서 만든 Metric 을 사용했다.
- Metrics
- Y-axis
- Aggregation: Average
- Field: AvgTicketPrice
- Y-axis
- Aggregation: Derivative
- Meric: Average AvgTicketPrice
- Y-axis
- Bucket
- X-axis
- Aggregation: Histogram
- Field: dayOfWeek
- interval: 1
- X-axis
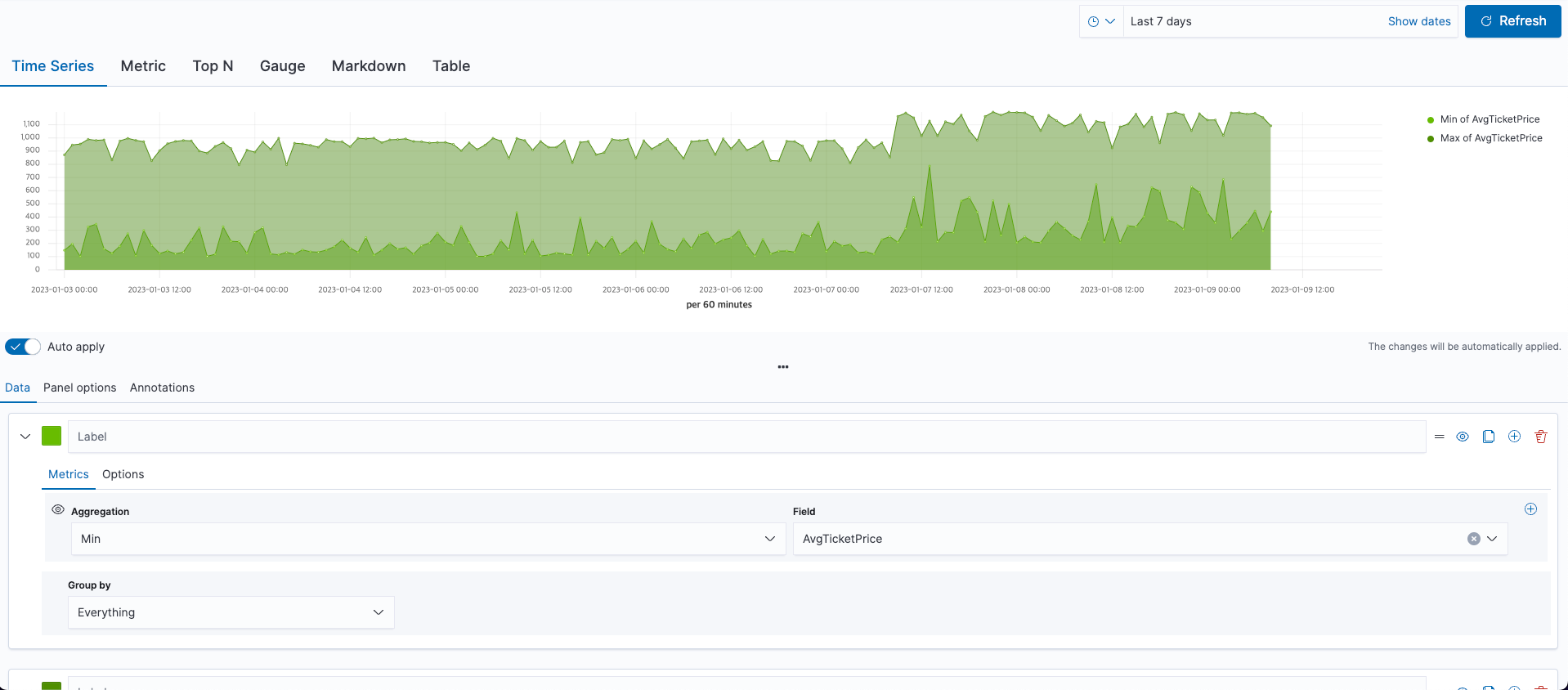
2) TSVB(Time Series Visual Builder)
시계열 데이터를 처리하기 위한 메뉴로, 로그 모니터링이나 시간 범위 내의 특정 동작을 시각화하는데 유용한다. TSVB를 통해 시계열 데이터 통계 정보, n 번째 상위 값, 게이지 등을 변하게 확인할 수 있다.
- Panel Options
- Index pattern: kibana_sample_data_flights
- Tiem Field: timestamp
- Data
- Metric
- Aggregation: Min
- Field: AvgTicketPrice
- Metric
- Aggregation: Max
- Field: AvgTicketPrice
- Metric