기본
1) 인덱스와 도큐먼트
엘라스틱 서치를 이해하기 위해서는 인덱스와 도큐먼트가 무척 중요하다.
- 인덱스: 도큐먼트를 저장하는 논리적 구분자
- 도큐먼트: 실제 데이터를 저장하는 단위
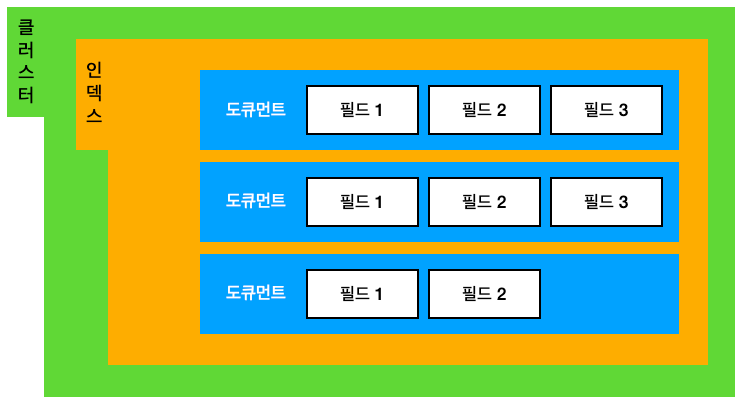
도큐먼트
도큐먼트는 엘라스틱 서치에서 데이터가 저장되는 기본 단위로 JSON 형태이며, 하나의 도큐먼트는 여러 필드와 값을 갖는다. 아래와 같은 데이터가 있다고 가정해보자.
name: mike
age: 25
gender: male만약, RDB라면 member라는 테이블에 name, age, gender 컬럼을 가진 스키마가 있어야 하고, 하나의 레코드로 데이터를 저장한다.
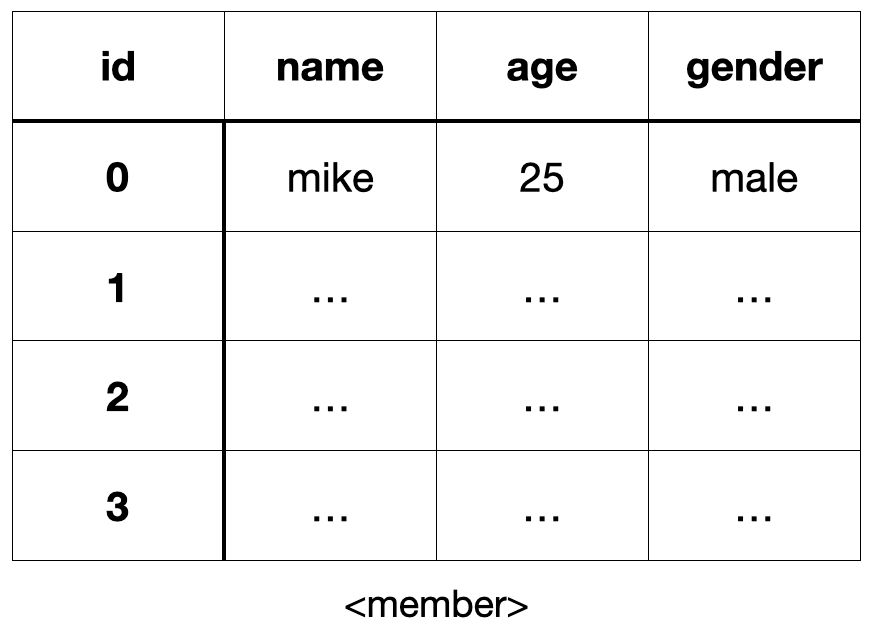
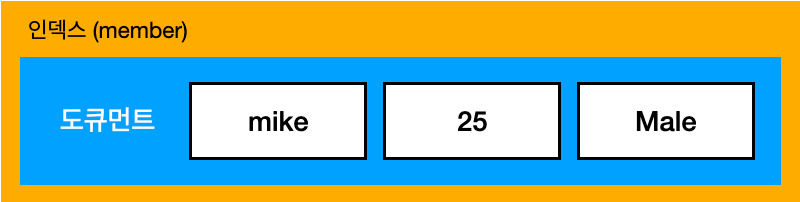
반면, 엘라스틱 서치는 데이터를 JSON 형태로 저장한다.
- name, age, gender 를 필드라고 하며, "mike", 25, "male" 을 값이라고 한다.
- 여기서 name, gender 필드는 텍스트 타입, age 필드는 정수 타입으로 매핑이 되었다.
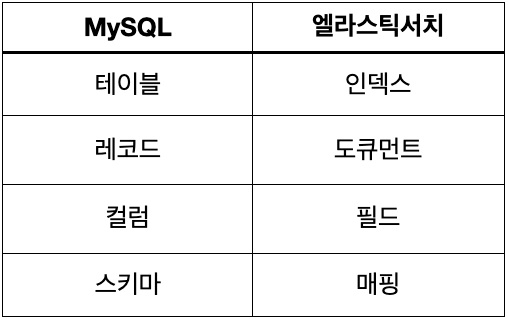
일반적인 데이터베이스(RDB) 와 비교하면 다음과 같다.
- 정확한 비교는 아니나, 이해의 편의성을 위해...
2) 분석기
엘라스틱 서치는 전문검색을 지원하기 위해 역인덱싱 기술을 사용한다. 전문검색은 장문의 문자열에서 부분검색을 수행하는 것이며, 역인덱싱은 장문의 문자열을 분석해 작은 단위로 쪼개어 인덱싱하는 기술이다.
역인덱싱을 이용한 전문 검색에서 양질의 결과를 얻기 위해서는 문자열을 나누는 기준이 중요하며, 이를 지원하기위해 엘라스틱 서치는 아래와 같이 캐릭터 필드, 토크나이저, 토큰 필터로 구성되어 있는 분석기 모듈을 가지고 있다.
캐릭터 필터: 입력받은 문자열을 변경하거나 불필요한 문자들을 제거한다.(ex 문자 끝의 공백)토크나이저: 문자열을 토큰으로 분리한다. 분리할때 토큰의 순서나 시작, 끝 위치도 기록한다. 분석기에는 하나의 토크나이저가 반드시 포함되어야 한다.토큰 필터: 분리된 토큰의 필터 작업을 한다. 대소문자 구분, 형태소 분석 등의 작업이 가능하다.
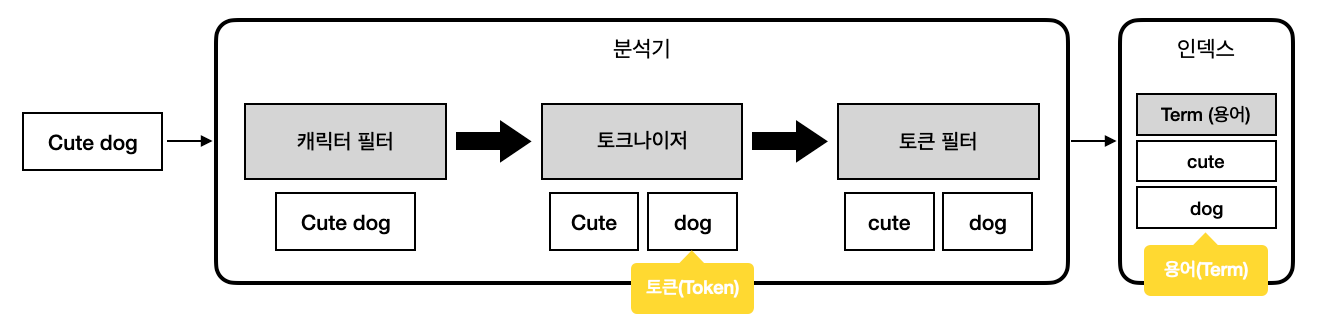
토큰과 용어
'Cute dog' 라는 문자열이 분석기를 거쳐 인덱스에 저장된다고 가정해보자. 분석기는 먼저 캐릭터 필터를 통해 원문에서 불필요한 문자들을 제거한다. 이 과정까지는 문자열 자체가 분리되지 않기 때문에 그저 필터링된 문자열 정도로 볼 수 있다.
이후 분석기는 토크나이저를 이용해 필터링된 문자열을 자르는데, 이때 잘린 단위를 토큰이라고 한다. 이런 토큰들은 복수의 토큰 필터를 거치며 정제되는데, 최종적으로 역인덱스에 저장되는 상태의 토큰들을 용어(term)라고 한다. 토큰은 분석기 내부에서 일시적으로 존재하는 상태이고, 인덱싱 되어 있는 단위, 또 검색에서 사용되는 단위는 모두 용어라고 할 수 있다.
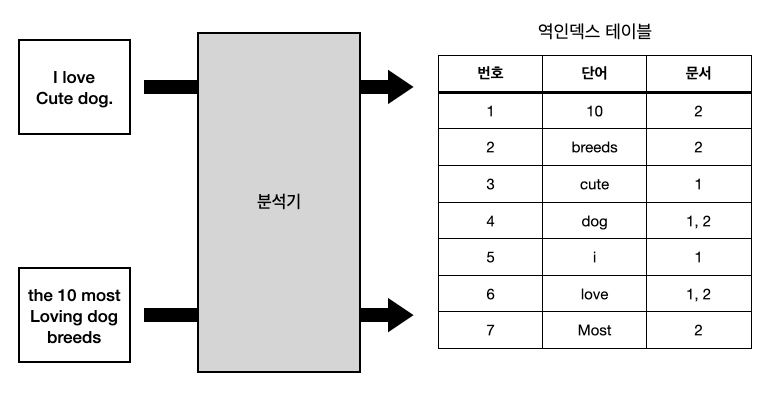
역인덱싱
분석기는 문자열을 토큰화하고 이를 인덱싱하는데 이를 역인덱싱이라고 한다. 아래의 그림은 엘라스틱에서 역인덱스를 만드는 과정을 예시한다.
- 2개의 문서가 분석기를 거치면서 역인덱싱 되고있다.
- 역인덱스 테이블은 용어가 어떤문서에 속해있는지 기록되어 있어서 손쉽게 문서를 찾을 수 있다.

잘 읽었습니다. 좋은 정보 감사드립니다.