
<IT엔지니어를 위한 네트워크 입문> 책을 함께 읽는 스터디를 진행하며 올리는 포스팅입니다.
스터디 repository
Intro
지난 포스팅에서 2계층 장비인 스위치에 대해 알아보았습니다.
스위치는 MAC 주소를 보고 통신해야 할 포트를 지정해 내보내는 역할을 하는 장비로, 같은 네트워크, 즉 LAN 안에서 동작하는 장비였습니다.
그렇다면 다른 네트워크, 즉 원격지 네트워크와 통신하기 위해서는 어떤 장비가 필요할까요?
그리고 거대한 인터넷 세상의 주소 정보들을 어떤 식으로 관리하며, 어떻게 최적의 경로를 찾아내는 걸까요?
이번 포스팅에서는 3계층 장비인 라우터(Router)에 관해 알아보겠습니다.
라우터의 동작방식
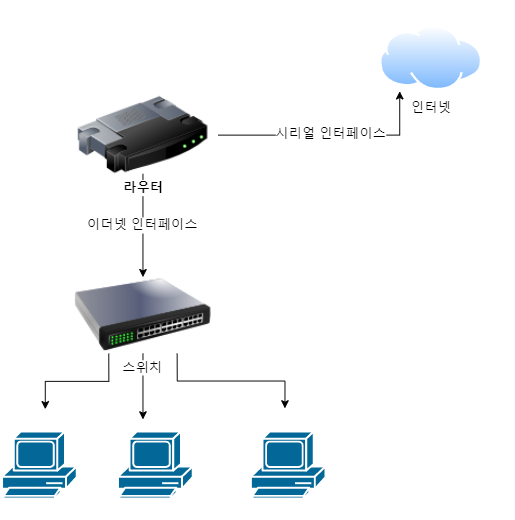
라우터는 3계층에서 동작하는 네트워크 장비로, 들어오는 패킷의 목적지 IP 주소를 확인하고 자신이 가진 라우트 정보를 이용해 패킷을 최적의 경로로 포워딩합니다.
라우터의 동작 방식은 아래와 같이 3가지로 나눌 수 있습니다.
- 경로 지정
- 최적의 경로를 라우팅 테이블에 저장한 뒤, 패킷이 들어오면 도착지 IP 주소와 라우팅 테이블을 비교해 최선의 경로로 패킷을 내보냅니다.
- 브로드캐스트 컨트롤
- 들어온 패킷의 목적지 주소가 라우팅 테이블에 없으면 패킷을 버립니다.
- 프로토콜 변환
- 패킷 포워딩 과정에서 기존 2계층 헤더 정보를 버리고, 새로운 2계층 헤더를 만듭니다.
하나씩 살펴보겠습니다.
경로 지정
라우터는 알고 있는 주소가 아닌 목적지를 가진 패킷이 들어오면 해당 패킷을 버리기 때문에, 경로 정보를 충분히 수집하고 있어야 정상적으로 동작합니다.
라우터의 경로 지정은 다시 경로 정보를 얻는 역할, 얻은 경로 정보를 확인하고 패킷을 포워딩하는 역할의 두 가지로 나눌 수 있습니다.
먼저 라우터는 다양한 방법으로 경로 정보를 얻는데, 아래의 세 가지 방법으로 나눌 수 있습니다.
- IP 주소를 입력하면서 자연스럽게 인접 네트워크 정보를 얻는 방법
- 관리자가 직접 경로 정보를 입력하는 방법
- 라우터끼리 서로 경로 정보를 자동으로 교환하는 방법
브로드캐스트 컨트롤
스위치는 패킷의 도착지 주소를 몰라도 플러딩을 하여 패킷을 모든 포트에 전송합니다.
반면 라우터는 분명한 도착지 정보가 있을 때만 통신을 허락합니다.
인터넷 연결은 대부분 지정된 대역폭만 빌려 사용하므로 쓸모없는 통신을 최대한 막아야 합니다. 따라서 라우터는 멀티캐스트 정보를 습득하지 않고, 브로드캐스트 패킷을 전달하지 않습니다. 이 기능을 브로드캐스트 컨트롤/멀티캐스트 컨트롤 이라 합니다.
프로토콜 변환
라우터를 사용하면 서로 다른 프로토콜로 구성된 네트워크를 연결할 수 있습니다.
라우터에 패킷이 들어오면 2계층까지의 헤더 정보를 벗겨내고 3계층 주소를 확인한 후, 2계층 헤더 정보를 새로 만듭니다. 이 때 다른 프로토콜의 헤더로 변경되어 프로토콜 변환이 일어나는 것입니다.
경로 지정
라우터는 서브넷 단위로 라우팅 정보를 습득하고, 이를 최적화하기 위해 서머리 작업을 통해 여러 개의 서브넷 정보를 뭉쳐 전달합니다. 따라서 패킷의 목적지 주소와 라우팅 테이블 정보가 정확히 일치하지 않더라도 목적지에 가장 근접한 정보를 찾아 패킷을 포워딩합니다.
라우팅 동작
라우터에서 '최적의 경로'를 지정한다는 것은 목적지까지의 경로를 모두 책임지는 것이 아니라, 인접한 라우터까지의 경로를 의미합니다.
네트워크를 한 단계씩 뛰어넘는다는 의미로 이 기법을 홉-바이-홉(Hop-by-Hop) 라우팅이라 합니다. 그리고 인접한 라우터를 넥스트 홉(Next Hop)이라 합니다. 즉, 라우터는 최적의 넥스트 홉을 선택해 보내주는 것입니다.
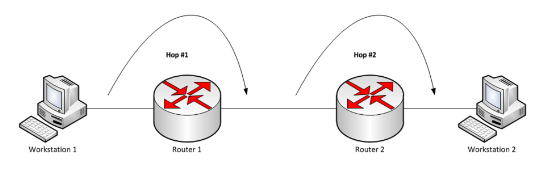
라우터가 넥스트 홉을 지정할 때는 일반적으로 아래 세 가지 방법을 사용합니다.
- 다음 라우터의 IP를 지정하는 방법(넥스트 홉 IP 주소)
- 라우터의 나가는 인터페이스를 지정하는 방법
- 위의 둘 다 지정하는 방법
이 때, 일반적으로는 상대방 라우터의 인터페이스 IP 주소를 지정하는 방법을 사용하고, 특수한 경우에만 나가는 인터페이스를 지정합니다.
라우팅 테이블을 만들 때는 목적지 정보만 수집해, 이를 확인 후 패킷을 넥스트 홉으로 포워딩합니다.
라우팅 테이블에는 아래와 같은 정보가 포함됩니다.
- 목적지 주소
- 넥스트홉 IP 주소, 나가는 로컬 인터페이스(생략 가능)
패킷의 출발지 주소를 이용해 라우팅하는 PBR(Policy-Based Routing) 기능도 존재하지만, 별도 설정이 필요합니다. 관리가 어렵기 때문에 특별한 목적으로만 사용합니다.
라우팅 루프와 TTL
3계층 IP 헤더에는 TTL(Time to Live)이라는 필드가 있습니다. 이는 패킷이 네트워크에 살아있을 수 있는 시간(홉)을 제한합니다.
마주보는 두 대의 라우터의 넥스트 홉이 상대방으로 구성될 경우 라우팅 루프가 일어나는데, 이 때 TTL 값이 0이 되면 네트워크 장비에서 패킷이 버려집니다. 이 때 TTL은 홉을 칭하며, 하나의 홉을 지날 때마다 TTL이 1씩 줄어듭니다.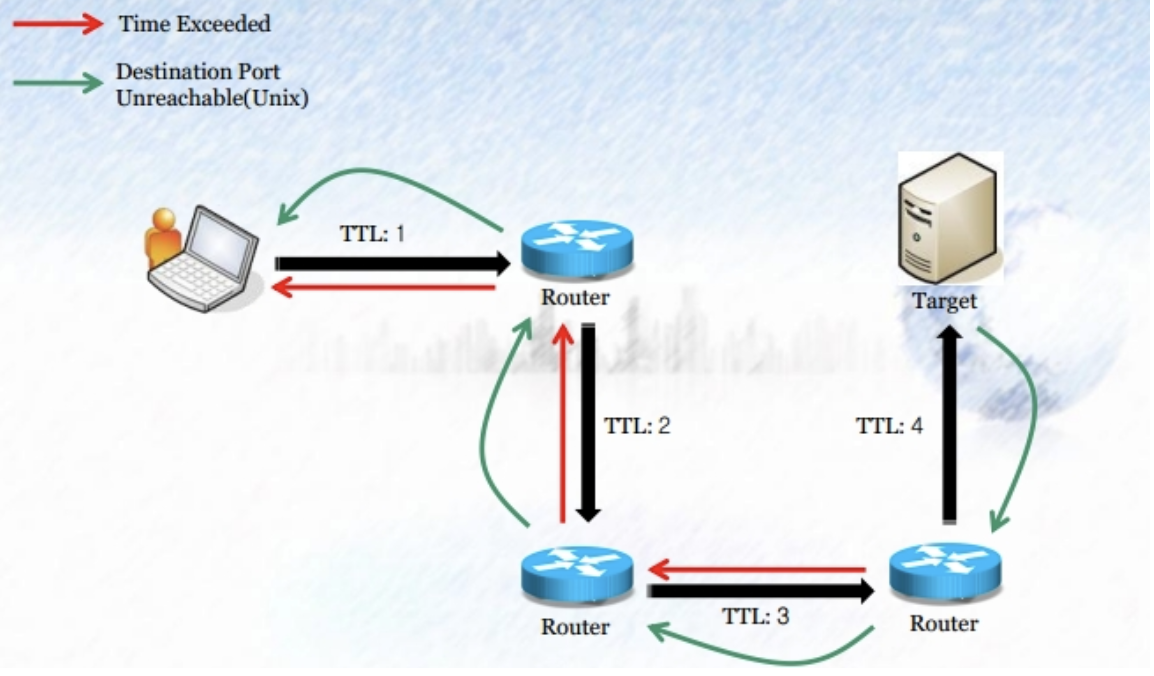
라우팅
라우터가 경로 정보를 얻는 방법은 아래의 3가지입니다.
- 다이렉트 커넥티드
- 스태틱 라우팅
- 다이나믹 라우팅
하나씩 자세히 알아보겠습니다.
다이렉트 커넥티드
IP 주소를 입력할 때 사용된 IP 주소와 서브넷 마스크로 해당 IP 주소가 속한 네트워크 주소를 알 수 있는데, 이 정보를 통해 해당 네트워크에 대한 라우팅 테이블을 자동으로 만듭니다. 이 경로 정보를 다이렉트 커넥티드라 합니다.
이 정보는 강제로 지울 수 없고, 해당 네트워크 설정을 삭제하거나 해당 네트워크 인터페이스가 비활성화되면 자동으로 사라집니다.
스태틱 라우팅
스태틱 라우팅(Static Routing)이란, 관리자가 목적지 네트워크와 넥스트 홉을 라우터에 직접 지정해 경로 정보를 입력하는 것을 말합니다.
이 때 연결된 인터페이스 정보가 삭제되거나 비활성화되면 연관된 스태틱 라우팅 정보가 자동 삭제됩니다.
다이나믹 라우팅
스태틱 라우팅으로는 라우터 너머의 다른 라우터 상태를 파악할 수 없습니다. 따라서 장애 발생 시 장애 상황을 파악하고, 대체 경로로 패킷을 보낼 수 없습니다.
다이나믹 라우팅은 이러한 단점을 보완해주는 방법입니다. 라우터끼리 자신이 알고 있는 경로 정보나 링크 상태 정보를 교환해 전체 네트워크를 학습하는 방법이 다이나믹 라우팅(Dynamic Routing)입니다.
주기적으로 혹은 상태 정보 변경 시 경로 정보가 교환되므로 장애 발생 시 이를 인지하고 대체 경로로 패킷을 포워딩할 수 있습니다.
라우터는 이렇게 얻은 경로 정보를 체계적으로 데이터베이스화하고, 순위를 적절히 부여해 최선의 경로 정보만 수집합니다.
이 때, 라우터가 수집한 경로 정보의 원시 데이터를 토폴로지 테이블이라 하고, 이 경로 정보 중 최적의 경로를 저장하는 테이블을 라우팅 테이블이라고 합니다.
스위칭
경로 정보를 얻어 만든 라우팅 테이블을 참조하고 최적의 경로를 찾아 라우터 외부로 포워딩하는 작업을 스위칭이라 합니다.
패킷의 목적지가 라우터 테이블에 있는 정보와 일치하지 않는 경우, 라우터는 롱기스트 프리픽스 매치 기법을 이용해 갖고 있는 경로 정보 중 가장 가까운 경로를 선택합니다.
예를 들어 10.1.1.9 IP를 목적지로 가진 패킷이 들어온 경우 라우팅 테이블이 아래와 같다면
- 목적지 10.0.0.0/8, 인터페이스 Eth 1
- 목적지 10.1.0.0/16, 인터페이스 Eth 3
- 목적지 10.1.1.0/24, 인터페이스 Eth 2
10.1.1.0/24 가 목적지와 더 많은 정보가 매치되기 때문에 최선의 정보가 되어, 패킷이 Eth 2로 포워딩됩니다.
이러한 부정확한 정보 중 비슷한 경로를 찾는 작업은 많은 리소스를 소모하는 일이기 때문에, 한 번 스위칭 작업을 수행한 정보는 캐시에 저장하고 이후 캐시를 먼저 확인합니다. 네트워크에서 데이터를 보낼 때 동일한 출발지 IP, 동일한 목적지 IP, 포트번호로 여러 개의 패킷을 연속적으로 보내기 때문입니다.
우선순위
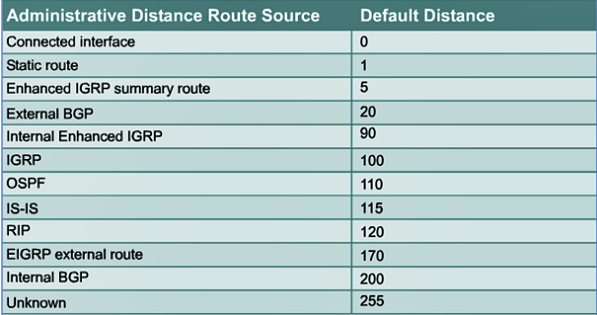
토폴로지 테이블에서 좋은 경로 정보의 우선순위는 경로 정보를 받은 방법과 거리를 기준으로 정합니다. 이러한 우선순위를 AD(Administrative Distance)라 합니다.
먼저 앞서 살펴본 3가지의 경로 수집 방법은 다이렉트 커넥티드 - 스태틱 라우팅 - 다이나믹 라우팅 순으로 우선순위가 높습니다. 이 때, 필요에 따라 관리자가 우선순위를 조정해 라우팅 경로를 조정할 수 있습니다.
경로 정보 관련 가중치 값이 동일한 경우에는 코스트 값으로 우선순위를 정하고, 코스트 값이 동일할 때는 ECMP(Equal-Cost Multi-Path) 기능으로 동일한 코스트 값을 가진 경로 값 정보를 모두 활용해 트래픽을 분산합니다.
라우팅 설정 방법
다이나믹 커넥티드
라우터나 PC에 IP 주소, 서브넷 마스크를 입력하면 다이렉트 커넥티드 라우팅 테이블이 생성됩니다. 이 때 다이나믹 커넥티드 라우팅 테이블만 있으면 외부 네트워크와 통신이 불가능합니다.
따라서 스태틱 라우팅 설정이 필수적입니다.
스태틱 라우팅
원격지 네트워크와 통신하기 위해서는 라우터에 직접 연결되지 않은 네트워크 정보를 입력해야 합니다. 이 때 스태틱 라우팅을 사용해 경로를 직접 제어할 수 있습니다.
하지만 네트워크 규모가 매우 커지거나 인터넷 연결을 해야 할 때는 라우팅을 처리하는 데 어려움이 있습니다. 특히 인터넷에 존재하는 너무 많은 라우팅 정보를 처리하기 위해서는 대용량의 인터넷 라우팅 전용 라우터가 필요합니다. 이러한 인터넷 라우팅 전용 라우터는 인터넷 사업자가 운영합니다.
일반적인 회사에서는 인터넷의 모든 라우팅 정보를 가질 만큼의 라우터를 사용하지 못합니다. 이런 경우, 스태틱 라우팅을 확장한 디폴트 라우팅을 사용하여 문제를 해결합니다.
모든 패킷을 인터넷 사업자에게 보내기 위해 스태틱 라우팅을 만들기 위해서는 매우 많은 스태틱 라우팅이 필요합니다. 이 때 서브넷 마스크가 모두 0인 스태틱 라우팅, 즉 디폴트 라우팅을 사용합니다.
서버에서 디폴트 라우팅을 설정하면 서버의 라우팅 테이블에 디폴트 라우팅이 생성됩니다.
다이나믹 라우팅
간단한 네트워크 구조에서는 스태틱 라우팅으로 망을 유지하지만, 일반적으로는 SPoF를 없애기 위해 두 개 이상의 경로를 유지합니다. 따라서 장애 시 자동으로 대체 경로를 사용하기 위해 다이나믹 라우팅을 사용합니다.
라우터끼리 자신들의 프로토콜로 정보를 교환하며 경로 정보를 최신으로 유지하고, 문제 발생 시 대체 경로를 빠르게 찾을 수 있는 방법입니다.
이러한 다이나믹 라우팅 프로토콜은 여러 기준으로 분류할 수 있습니다.
역할에 따른 분류
일반적으로 라우팅 프로토콜은 유니캐스트 라우팅 프로토콜입니다.
인터넷에는 AS(Autonomous System)이라는 자율 시스템이 존재하는데, 인터넷 사업자가 한 개 이상의 AS를 운영합니다.
AS 내부에서 사용하는 라우팅 프로토콜을 IGP(Interior Gateway Protocol), AS 간 통신에 사용하는 라우팅 프로토콜을 EGP(Exterior Gateway Protocol)이라 합니다.
AS 내부에서는 자체적으로 규칙을 세워 운영할 수 있지만, AS끼리의 연결을 조직 간 정책과 인터넷 사업자간 이해관계의 영향을 받습니다.
동작 원리에 따른 분류
IGP 라우팅 프로토콜은 동작 원리에 따라 아래의 두 가지로 나뉩니다.
- 디스턴스 벡터(Distance Vector)
- 인접한 라우터에서 경로 정보를 습득하는 라우팅 프로토콜
- 링크 스테이트(Link-State)
- 라우터에 연결된 링크 상태를 서로 교환하고 각 네트워크 맵을 그리는 라우팅 프로토콜
디스턴스 벡터는 인접한 라우터에서 이미 계산한 결과물인 라우팅 테이블을 전달받아 계산합니다. 따라서 라우팅 정보 처리에 많은 리소스가 필요하지 않아 간단한 네트워크 구축에 많이 사용되었습니다. 이 때, 인접 라우터만 정보를 교환하기 때문에 멀리 떨어진 라우터 정보를 얻는 데에는 많은 시간이 필요합니다.
링크 스테이트 라우팅 프로토콜은 라우터들에 연결된 링크 상태를 교환합니다. 교환된 정보를 통해 토폴로지 데이터베이스를 만들고, 이 정보를 다시 SPF(Shortest Path First) 알고리즘을 이용해 최단 경로 트리를 만듭니다. 이를 이용해 최적의 경로를 선정한 뒤 라우팅 테이블에 그 정보를 추가합니다.
네트워크 규모가 커지면 네트워크 경로 파악에 많은 리소스를 소모하기 떄문에, 네트워크를 AREA 단위로 분리하여 분리된 AREA 내에서만 링크 상태 정보를 교환합니다.
AREA 외부의 라우터와는 가공된 라우팅 테이블 형태로 정보를 전달합니다.
AREA 단위로 네트워크를 구분하고 확장하는 OSPF는 AREA0으로 불리는 Backbone AREA를 통해 모든 AREA를 연결합니다. Backbone AREA와 다른 AREA를 연결시키는 경계 라우터는 ABR(Area Border Router)이라 하며, OSPF가 아닌 다른 외부의 정보를 OSPF와 연결해주는 외곽 라우터를 ASBR(Autonomous System Border Router)라 합니다.
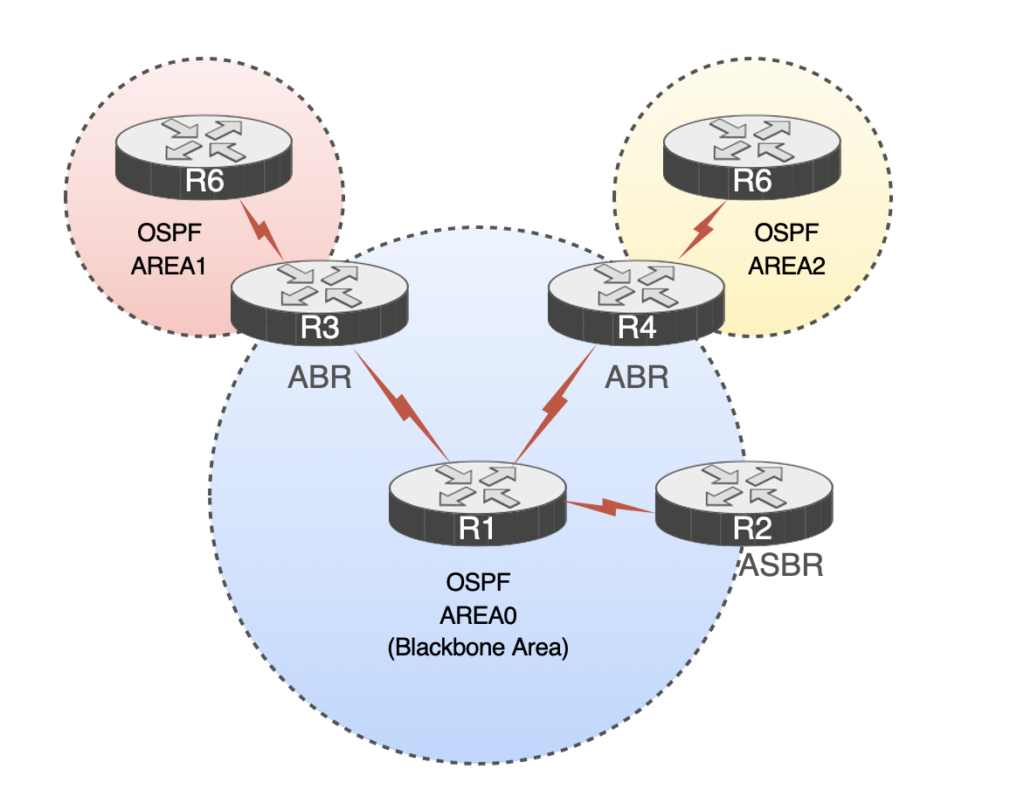
대부분 IGP로 OSPF(링크 스테이트)와 BGP(디스턴스 벡터)가 많이 사용되고, EGP로 BGP가 많이 사용됩니다.
끝
이미지 출처 & 레퍼런스
- Router : https://chunggaeguri.tistory.com/entry/Network-%EB%9D%BC%EC%9A%B0%ED%84%B0-Router-%EB%9E%80
- Hop-by-Hop : https://velog.io/@jiyaho/CS-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-IP-%EC%A3%BC%EC%86%8CARP-%ED%99%89%EB%B0%94%EC%9D%B4%ED%99%89-%ED%86%B5%EC%8B%A0-IP-%EC%A3%BC%EC%86%8C-%EC%B2%B4%EA%B3%84
- TTL : https://velog.io/@sms8377/Network-Traceroute-%EC%9D%98-%EC%9E%91%EB%8F%99-%EC%9B%90%EB%A6%AC
- AD : https://peemangit.tistory.com/5
- OSPF : https://orhanergun.net/ospf-area-types
