3, 4 일차 pass

인공 지능 : 인간의 지능을 기계로 구현
머신 러닝 : 인공 지능을 구현하는 구체적 접근 방식
딥 러닝 : 완전한 머신 러닝을 실현하는 기술
머신러닝


supervised learning : 지도 교육
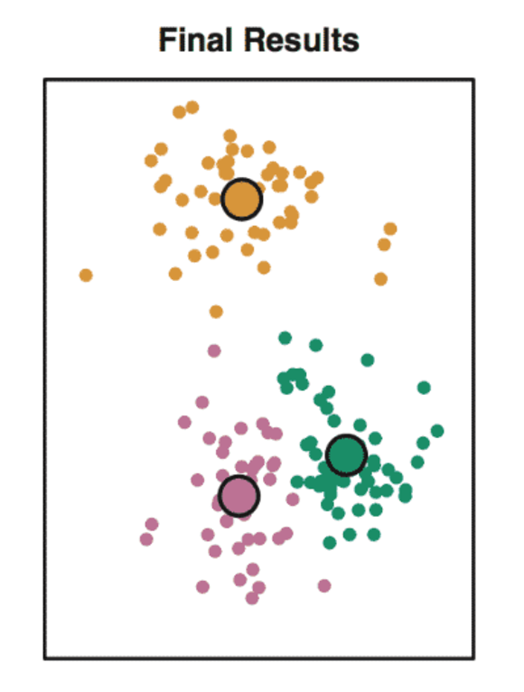
unsupervised learning
: 비지도교육 중 군집화(clustering) -> 사진들을 때려 박아서 군집화 하는 것
효율 : 지도학습 >>> 넘사 >>> 비지도학습(학습데이터를 만들 때 사용됨)
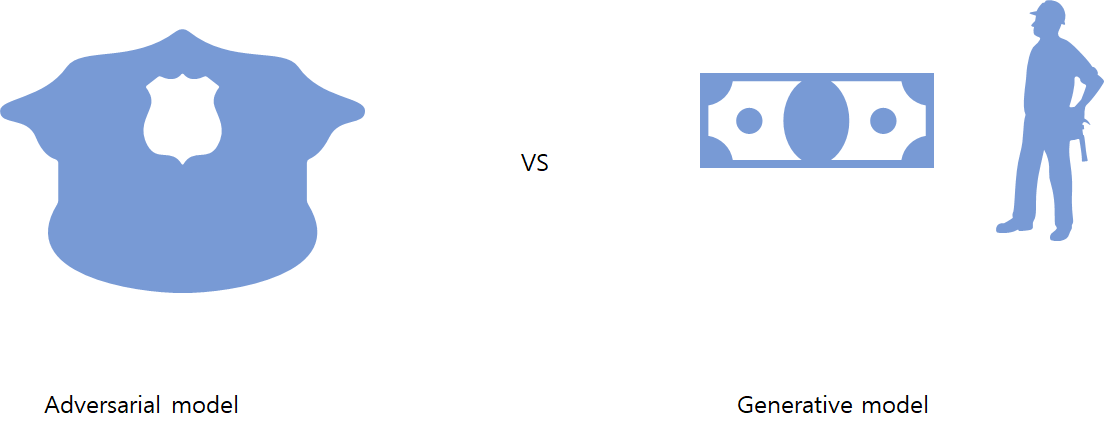
Semi-supervised leaning(GAN) :
ex) 지폐와 위조지폐
판별자 모델과 생성자 모델있음 -> 생성자가 위조지폐을 만듦 -> 판별자가 판단(지폐 구별시) -> 생성자가 피드백 받고 더 정교한 위조 지폐를 만듦 -> 또 만들어서 판별자가 확인함(지폐 구별x) -> 판별자가 피드백 받고 learning함

reinforce learning
reward를 받기위해 알아서 플레이 함 -> 모델 중 제일 좋은 모델로 계속 돌려서 좋은 값을 받을 수 있도록 함
딥러닝
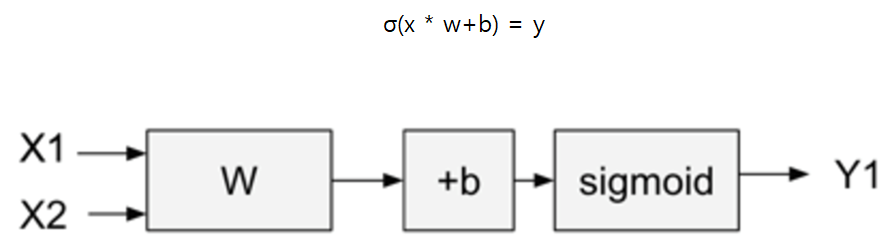
퍼셉트론 단층레이어
sigmod를 이용해 y값을 예측하는 것 w,b 는 학습을 통해 얻어짐 그리고 선형임
or/and 은 되지만 xor은 안됨
MLP(multi-layer perception)
MLP -> deep learning 이 됨

선형회귀법 같이 cost func을 이용해서 cost 값을 0으로 줄이는 것이 굳(아마도 오차)
중요 요소 : 딥러닝 모델 /학습&정답데이터 /손실함수(loss func) /최적화함수(Optimizer)
Tensorflow
tensorflow 확정성 굳 -> 이거 써

model.add 할때 input 값과 output 값이 있어야됨(지금은 1차원 입력 /1차원 출력)
vector mat < mat(벡터의 모음) < tensor(매트릭스의 모음)
SGD -> optimizer SGD 방식(중요함) / mse -> mean square error
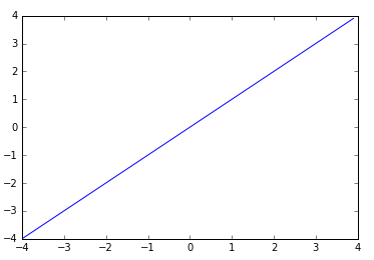
x축: input 값, y축: 함수



sigmoid
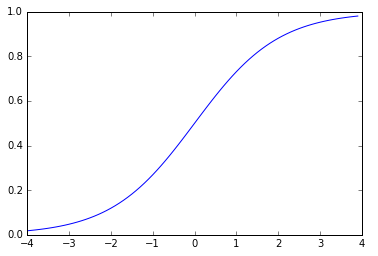
비선형이고 히든 레이어가 선형을 비선형으로 만들어줘서 다양한 추론을 할 수 있게 됨(선형은 선형으로만 답이 나옴)
x축 : 실수 / y축: 0~1 사이의 값
sigmoid가 hidden layer에 있을때
- 비선형으로 만들어줌
- nomalize 해줌
sigmoid가 output layer에 있을때
- 두개의 카테고리를 선택할 때 (0~1사이를 선택하는 특징 때문에 /3가지 이상 카테고리는 안됨)
단점 : gradient vanishing 문제를 야기함
softmax

n개의 요소를 예측할때 사용(2가지 이상일 때/ 2개일때 사용 가능하나 비효율 ->2개일 때는 sigmoid가 있음)
전체 카테고리에 대해서 다 계산함
tanh
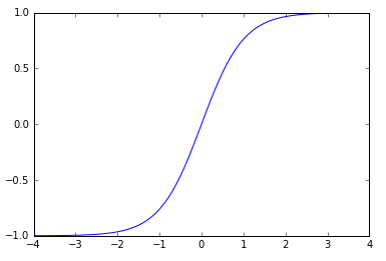
hidden layer -> vision쪽에서는 -1 ~ 1 값을 많이 사용함 or 의류쪽
3~4 에서 값이 변하지 않기 때문에 layer을 거치면서 값이 유용하지 않음
relu

입력이 < 0 이면 0, > 0 이면 linear
sigmoid and tanh보다 빠름 -> 비교연산만 하면 됨
hidden layer에서 깊어지면 깊어질수록 relu를 많이 사용함
자연어 처리에서 gradient vanishing 문제를 해결 도움 -> 음수는 없앰
최근에 다양한 자식들이 나옴
loss function
카테고리 문제가 큼 -> detect 하는 것이 힘듦
MSE
mean square error func
cross rntrophy

활률 값 | y값 | 정답
softmax를 사용했음 why? -> 카테고리를 찾는 건데 값이 높은 게 답인데 확률을 한 번 더 하는 이유?
인베딩 한다. -> 벡터화 한 것
-(0log(0.3) + 0log(0.3) + 1*log(0.4))
gradient descent(경사 하강법)

Optimizer -> w와 b를 값을 가질 때 지도해주는 것 (제일 중요)
Optimizer와 함께 이해하는 것이 중요!!!(2개를 알아야 딥러닝을 아는 것)
optimizer 중 adam이 제일 좋음

CNN
특징을 추출하는데 특징이 있음 (cnn -> layer에 해당됨)(perceptron의 자식들 CNN, RNN)

filter -> 다 weight 값임
이미지 -> 숫자/체계(feature을 잡아냄) -> 카테고리 분류
CNN은 카테고리 분류하기 쉽게 특징을 잡아주는 것/ Dense들이 찾아주는 것
filter 씌우면 작아지는 것을 방지하기 위해 padding -> zero로 채움
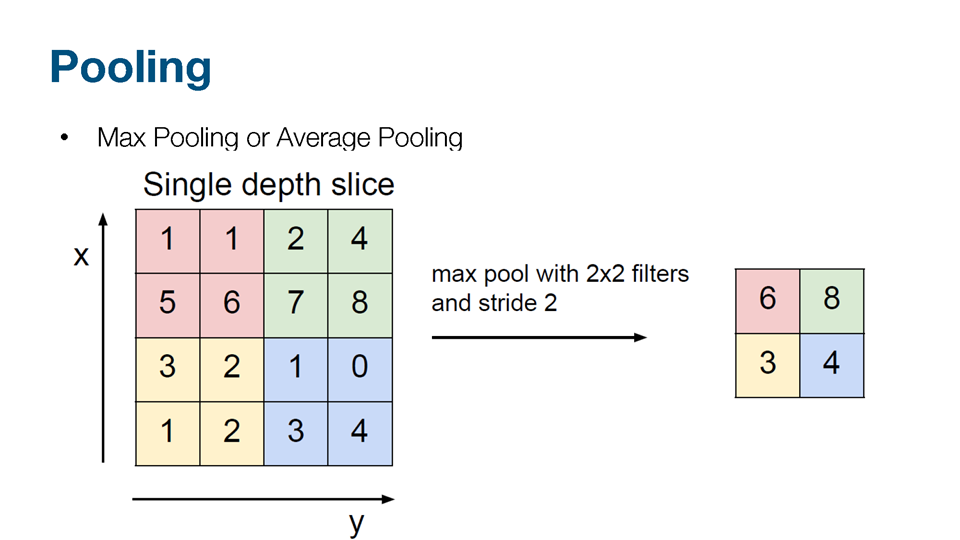
max pooling 마스크에서 최고 값을 뽑아냄
stride값이 1이면 한 칸 이동 2이면 두 칸 이동(이동하는 정도)
MNIST
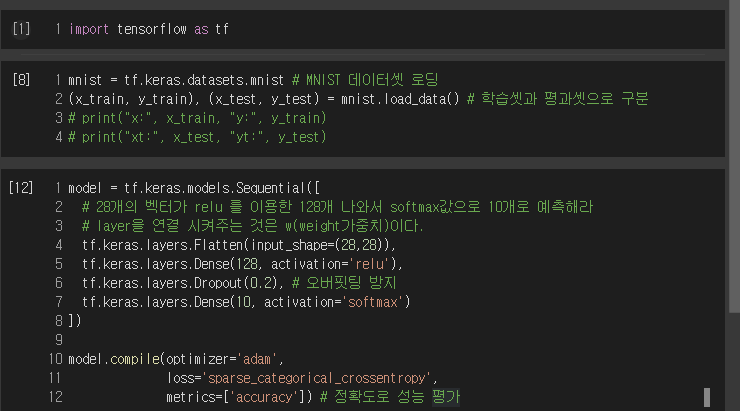

flatten2 -> 784개 나옴 /dense4 -> 128개 나옴 (784*128=100480개) /dropout /dense5 -> 10개 (1290개)

TIP💖
논문 : https://paperswithcode.com/sota
오버핏팅 : 특정부분만 보고 단정지어 버리는 것(ex: 돼지 코만 보고 형태를 보지 않음)

와우 잘 정리된 글이네요^^