회귀분석 프로젝트
야구선수 데이터를 가지고 선수의 내년 연봉을 예측해보겠습니다~
데이터
https://statiz.sporki.com/ 스탯티즈 사이트에서 야구 선수에 대한 데이터를 가지고 왔습니다.
데이터 불러오기
picher_file_path = './picher_stats_2017.csv'
batter_file_path = './batter_stats_2017.csv'
picher = pd.read_csv(picher_file_path)
batter = pd.read_csv(batter_file_path)
print(picher.head())
print(picher.columns)
print(picher['연봉(2018)'].describe())
picher['연봉(2018)'].hist(bins=100)
데이터를 불러와서 시각화를 해보니
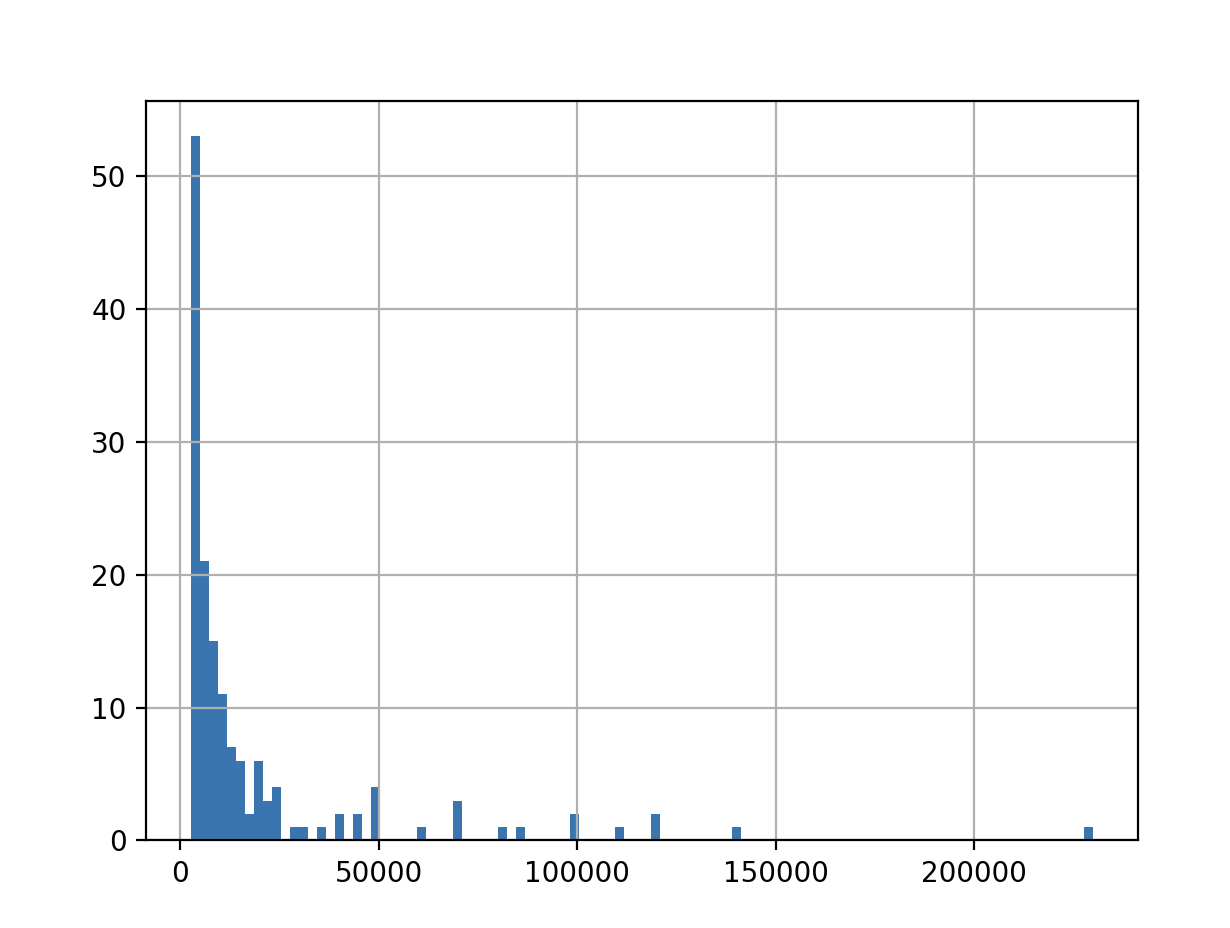
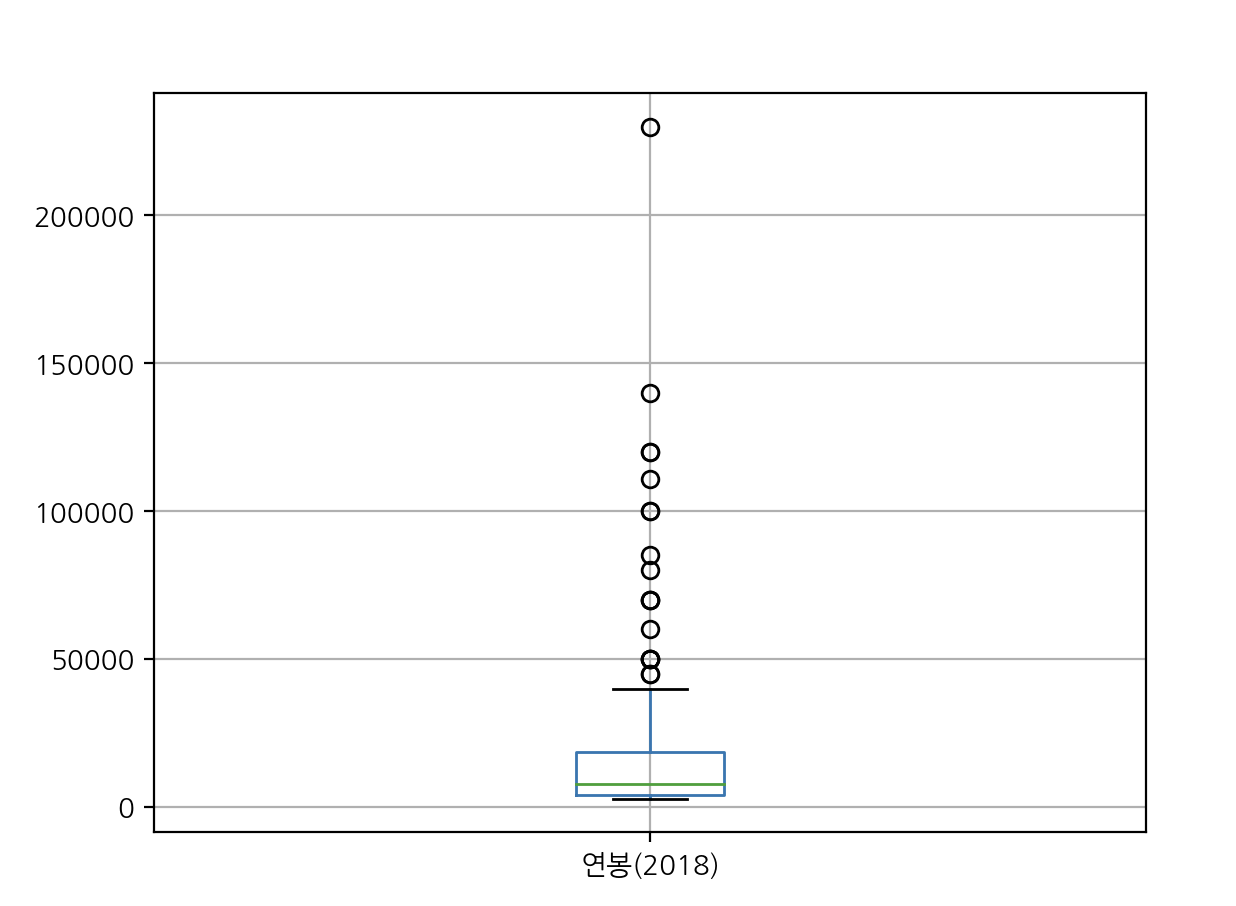
이렇게 보입니다
회귀분석
그럼 회귀분석을 진행해보겟습니다~
사용할 피처들은
picher_features_df = picher[['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR',
'연봉(2018)', '연봉(2017)']]이렇게 있고 각 피처들에 대한 히스토그램을 확인해보겠습니다
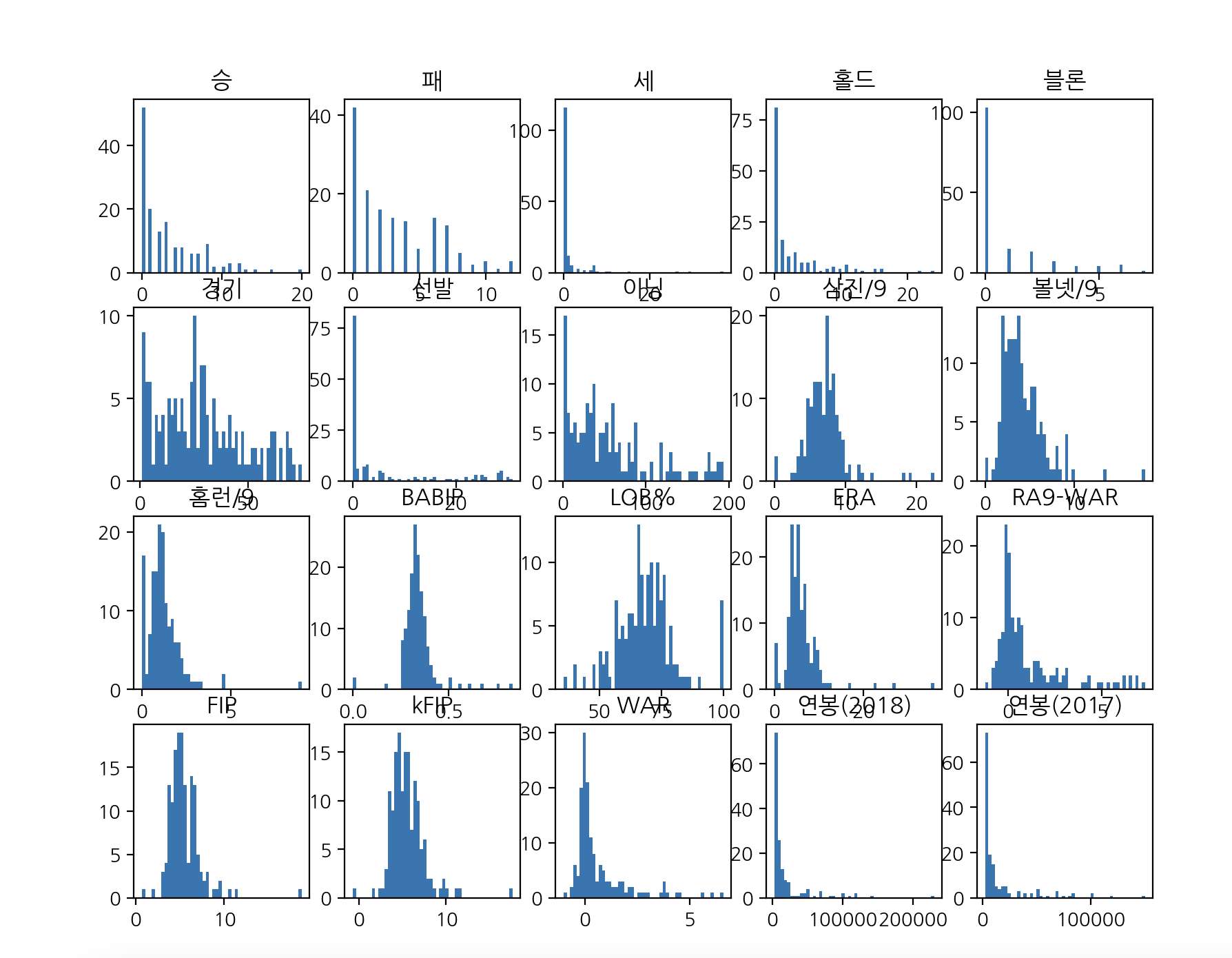
이렇게 확인할 수 있습니다
학습하기
먼저 피처들을 스케일링 해줍니다
def standard_scaling(df, scale_columns):
for col in scale_columns:
series_mean = df[col].mean()
series_std = df[col].std()
df[col] = df[col].apply(lambda x: (x-series_mean)/series_std)
return df
# 피처 각각에 대한 scaling을 수행합니다.
scale_columns = ['승', '패', '세', '홀드', '블론', '경기', '선발', '이닝', '삼진/9',
'볼넷/9', '홈런/9', 'BABIP', 'LOB%', 'ERA', 'RA9-WAR', 'FIP', 'kFIP', 'WAR', '연봉(2017)']
picher_df = standard_scaling(picher, scale_columns)
picher_df = picher_df.rename(columns={'연봉(2018)': 'y'})
picher_df.head(5)그 후 one-hot-encoding으로 단위를 통일 시킵니다
team_encoding = pd.get_dummies(picher_df['팀명'])
picher_df = picher_df.drop('팀명', axis=1)
picher_df = picher_df.join(team_encoding)
team_encoding.head(5)
picher_df.head()학습데이터와 테스트 데이터를 분리해보겠습니다
X = picher_df[picher_df.columns.difference(['선수명', 'y'])]
y = picher_df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)회귀분석 계수를 학습시킵니다
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)모델 정확성 평가
y_pred = lr.predict(X_test)
# 평균 제곱 오차(MSE)를 계산합니다.
mse = mean_squared_error(y_test, y_pred)
rmse = sqrt(mse)
print(f'평균 제곱 오차(MSE): {mse}')
print(f'루트 평균 제곱 오차(RMSE): {rmse}')
값이 크다보니 숫자가 좀 커진 것 같습니다.
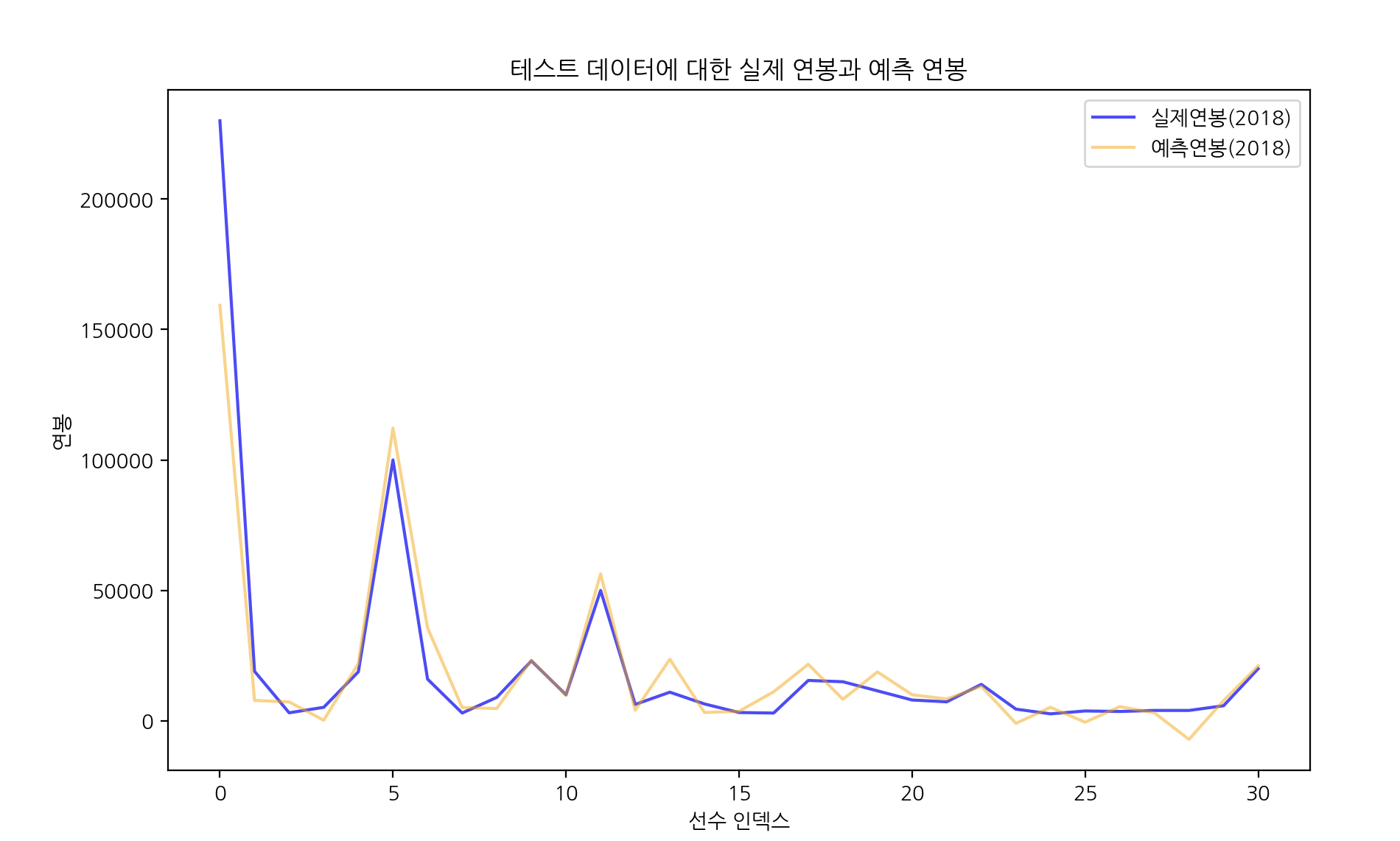
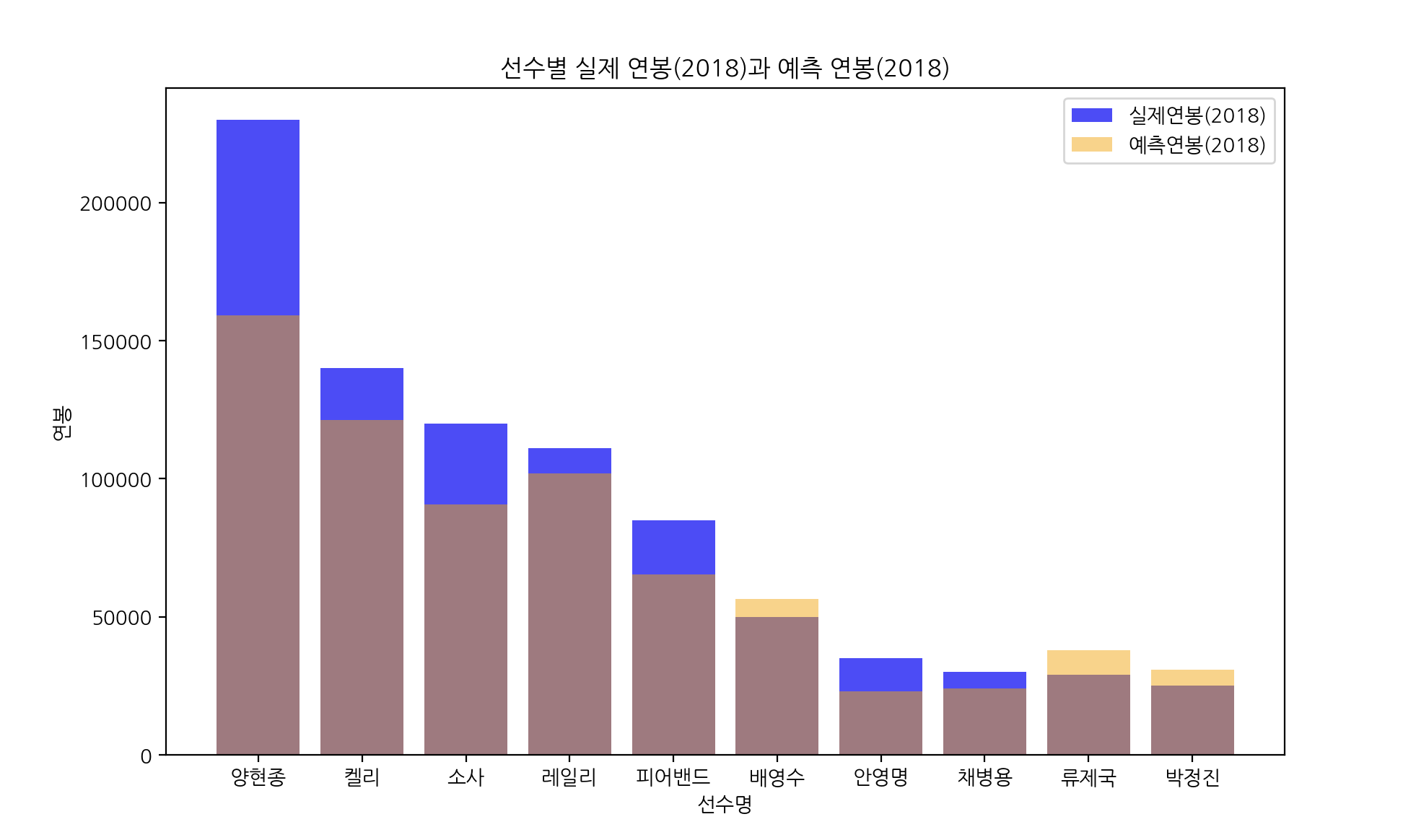
그럼 마지막으로 실제 내년 연봉과 예측한 내년 연봉에 대한 시각화를 해보았습니다