공부 내용
- 추천 시스템의 평가 지표
- 인기도 기반 추천
2. 추천 시스템의 평가 지표
2.1 개요
- 비즈니스 / 서비스 관점
- 매출, 페이지 방문자 수(PV) 증가
- 추천 아이템에 대한 유저의 CTR 상승
-> 사용자가 좋아하는 아이템이면 클릭 확률 상승
- 품질 관점
- 연관성(Relevance) : 추천된 아이템이 유저에게 관련이 있는가?
-> ex) 40대 남자에게는 화장품보다는 골프용품 추천 - 다양성(Diversity) : 얼마나 다양한 category의 아이템을 추천하는가?
-> ex) 노트북만 추천하기 보다는 다양한 형태의 아이템 추천 - 새로움(Novelty) : 얼마나 새로운 아이템이 추천되고 있는가?
-> 페이지를 새로고침 할 때마다 다른 아이템을 추천하면 좋음 - 참신함(Serendipity) : 유저가 기대하지 않은 상품이 추천되는가?
-> 연관성과 충돌할 수도 있음
- 연관성(Relevance) : 추천된 아이템이 유저에게 관련이 있는가?
CTR : click 수 / 노출 수
2.2 Offline Test
Offline test?
- 추천 모델을 검증하기 위해 가장 먼저 수행되는 단계
- 머신러닝 task에서 test 데이터의 성능을 평가하는 것과 동일
-> user로부터 수집한 데이터를 train/valid/test로 split하여 성능 평가 - offline test에서 성능이 좋다고 online test에서 성능이 좋다는 보장은 없음
-> serving bias로 인해 다양한 결과 나올 수 있음
serving bias?
- offline test
- data를 통해 모델이 학습 -> user에게 추천 결과 제공
- 이미 데이터가 구성되어 있음 -> 추천 성능 구할 수 있음
- online test
- user가 소비한 data가 log system을 통해 data로 추가
- 새로운 모델이 추가된 data를 추가 학습
- 새로운 모델이 만들어지고 모델이 발전됨 -> 결과가 다양해짐
성능 지표
- ranking : Precision@K ,Recall@K, NDCG@K, Hit Rate
- prediction : RMSE, MAE
Precision/Recall @K
- Precision@K
- 실제 유저가 관심있는 아이템 / 추천된 K개 아이템
- Recall@K
- 추천된 아이템 중 관심있는 아이템 / 유저가 관심있는 전체 아이템
- example
- 우리가 추천한 아이템 수 : 5(=K)
- 추천한 아이템 중 유저가 관심있는 아이템 수 : 2
-> Precision@K = 2/5 - 유저가 관심있는 아이템의 전체 개수 : 3
-> Recall@K = 2/3
아이템 추천 순위는 상관 없음
Mean Average Precision(MAP) @K
- AP@K
-
추천된 K개의 아이템의 순서에 따라 지표가 달라짐
-> 관련 아이템을 더 높은 순위에 추천할수록 점수 상승 -
Precision@1부터 Precision@K의 평균값
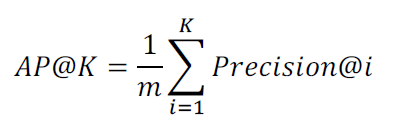
-
- MAP@K
-
전체 유저에 대한 AP@K의 평균
-> AP@K는 1명의 유저에 대해서만 반영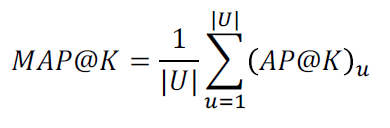
-
Normalized Discounted Cumulative Gain(NDCG)
- 원래는 검색에서 등장한 지표 -> 하지만 추천 시스템에서 많이 사용됨
MAP와 비교
- 공통점
- Top K 리스트를 만들고 유저가 선호하는 아이템과 순위를 비교
- 추천 순서에 따라 가중치를 두어 성능 평가 -> 1에 가까울수록 좋음
- 차이점
- 연관성을 이진(binary)값이 아닌 수치로도 사용
-> 유저에게 얼마나 더 관련있는 아이템을 상위로 노출하는지 알 수 있음
- 연관성을 이진(binary)값이 아닌 수치로도 사용
NDCG Formula
-
Cumulative Gain(CG)
-
상위 K개 아이템에 대한 관련도를 더함
-> 추천 순서에 따라 Discount 하지 않음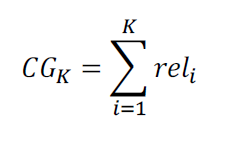
-
-
Discounted Cumulative Gain(DCG)
-
상위 K개 아이템에 대한 관련도를 더할 때 순서에 따라 Discount
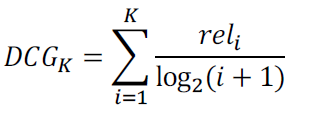
-
-
Ideal DCG(IDCG)
-
이상적인 추천이 일어났을 때의 DCG
-> 가능한 DCG 중 최댓값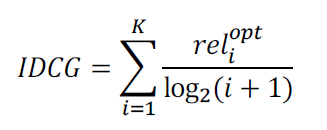
-
-
Normalized DCG
-
최종 NDCG
-> 추천 결과에 따라 구해진 DCG를 IDCG로 나눔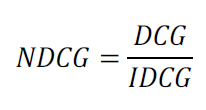
-
NDCG example
NDCG@5 값 구하는 example
-
Ideal Order : [C(3), A(3), B(2), E(2), D(1)]
-> relevance의 내림차순으로 정렬 -
실제 추천 Order : [E, A, C, D, B]
-
DCG@5 계산 -> E, A, C, D, B 순
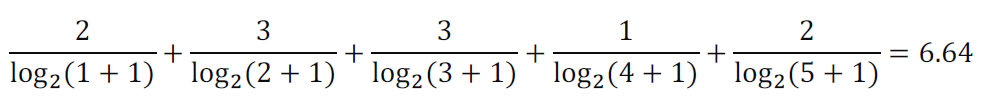
-
IDCG@5 계산 -> C, A, B, E, D 순
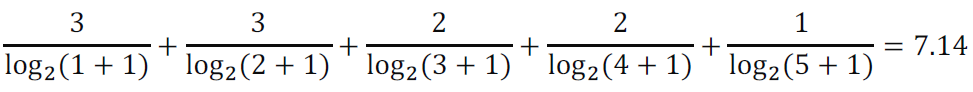
-
NDCG@5 계산
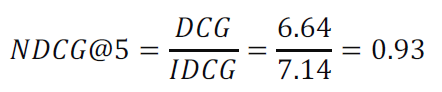
2.3 Online Test
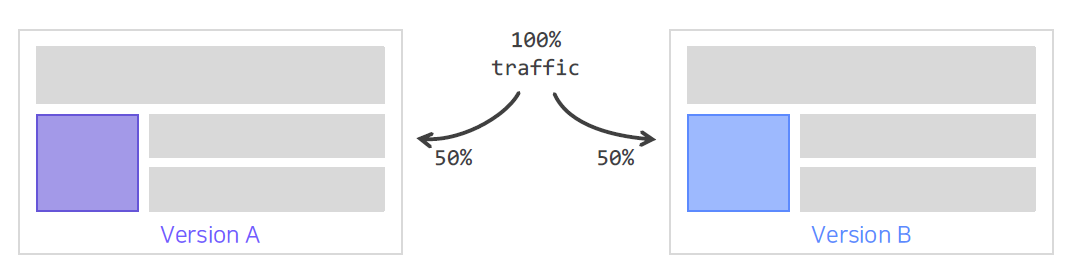
Online A/B Test?
- offline을 통해 검증된 추천 모델을 online 환경에 배포
-> 실제 추천 결과를 serving하여 성능 평가 - 동시에 대조군 A와 실험군 B의 성능을 평가
- 시간 전후로 비교하지 않음
- 대조군과 실험군의 환경이 최대한 동일해야 함
- 실제 서비스에서 얻어지는 결과를 통해 최종 의사결정
실제 현업에서는 매출, CTR 등의 비즈니스/서비스 지표 활용하여 성능 평가
3. 인기도 기반 추천
3.1 개요
인기도 기반 추천?
- 머신러닝이 아닌 통계적으로 사용자들에게 좋은 평가를 받은 아이템을 추천
- 가장 인기있는 아이템을 추천
- 서비스 초반에 주로 활용
-> 데이터 부족하거나 추천 모델 구축이 안 되었을 때
- 개인화된 추천과 함께 인기도 기반 추천도 활용
-> 단순하지만 강력하기 때문
인기도의 척도
조회수, 평균 평점, 리뷰 개수, 좋아요/싫어요 수
Example
- 네이버 쇼핑 랭킹 순
-> 통계적인 인기도 지표 조합 - 다음 뉴스, 댓글 추천
- 좋아요/싫어요 활용
- 연령별 추천
- 레딧 Hot 추천
- 좋아요 기반 추천
- 글 게시 시간 반영 -> 최신 글일수록 추천 가능성 높음
인기도 score 계산법
- 조회수가 가장 많은 아이템 추천(Most Popular)
ex) 뉴스 추천 -> 다른 유저들도 많은 관심을 갖는 핫한 이슈를 보고싶어 함 - 평균 평점이 가장 높은 아이템 추천(Higly Rated)
ex) 맛집 추천 -> 평점이 높은 맛집일수록 음식이 맛있을 것이라 판단
3.2 Most Popular
Score Formula
-
가장 많이 조회된 뉴스 or 좋아요가 가장 많은 뉴스 추천
-
뉴스의 경우 최신성이 가장 중요한 속성
-> 뉴스 작성 시간(age)도 score에 반영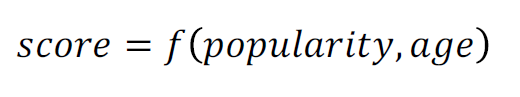
-
score 공식
- (좋아요 - 싫어요) - time_elapsed
- 조회수 - time_elapsed
time_elapsed : 게시 이후 시간이 얼마나 많이 지났는가
-
시간이 지나면 감점을 통해 score가 낮아지도록 유도
-
하지만 score 공식이 너무 단순함 -> 정교한 수식 필요
- pageview가 급격하게 늘어나면 score가 급격하게 높아지는 현상 발생
-> 시간이 지나도 같은 글이 Top Rank에 존재하게 됨
Hacker News Formula
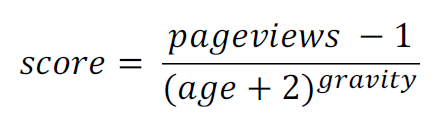
- pageview가 급격하게 늘어나면 score가 급격하게 높아지는 현상 발생
-
조회수가 높은 뉴스가 score가 높은 것은 동일
-
시간이 지날수록 age가 점점 증가하므로 score는 작아짐
-
gravity 함수를 통해 시간에 따라 줄어드는 score 조정
-> gravity = 1.8 -
pageview 분자값 상승 속도보다 age 분모값 상승 속도가 빠름
-> 결국 오래된 뉴스는 score가 0에 가까워짐Reddit Formula
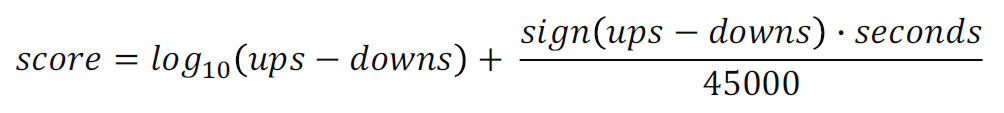
-
첫 번째 term은 좋아요/싫어요 반영(popularity)
-
두 번째 term은 글이 게시된 절대 시간
-> 최근에 게시된 글일수록 절대시간(seconds)이 크므로 더 높은 score 가짐 -
log값 적용을 통해 첫번째 vote에 대해서 가장 높은 가치 부여
- vote가 늘어날 수록 score 증가 폭이 작아짐
- 좋아요 수 폭발적으로 늘어났을 때 score 폭발적인 상승 방지
-> 오래된 글일수록 상대적으로 더 많은 vote 필요
3.3 Highly Rated
Score Formula
- 가장 높은 평점을 받은 영화 혹은 맛집 추천
-> 신뢰할수 있는 평점인지, 평가 개수가 충분한지 여부 중요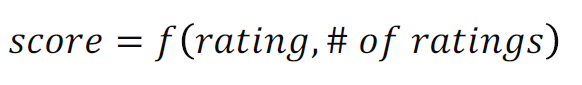
Steam Rating Formula
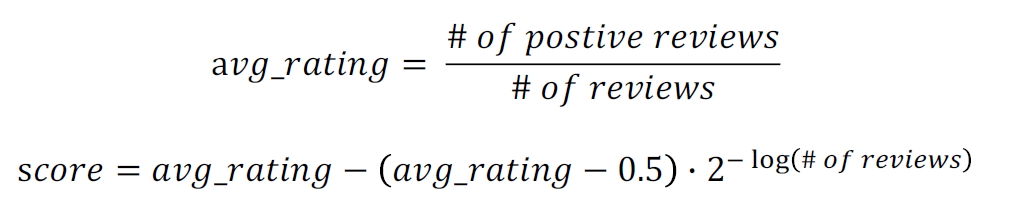
- rating은 평균값(avg_rating) 사용 -> 전체 리뷰 중 좋아요를 한 리뷰의 개수
- 전체 review 개수에 따라 rating 보정 -> review의 개수가 너무 적을 경우
- 0.5보다 avg_rating가 낮을 때는 높게, 높을 때는 낮게 보정
- review의 개수가 아주 많으면 score는 avg_rating과 비슷함
Steam Rating Formula to Movie Rating
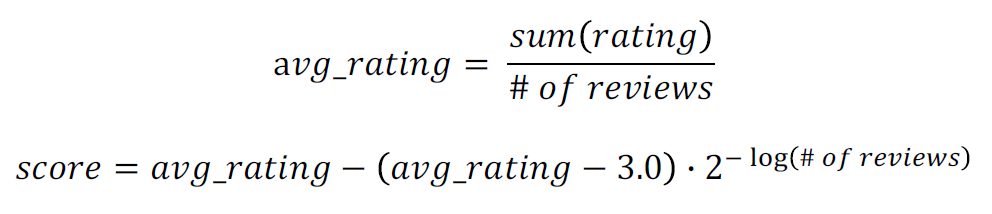
- 영화 평점은 1.0부터 5.0의 범위를 가짐
- avg_rating으로 1.0 ~ 5.0 사이의 중앙값인 3.0 사용
-> 3.0 대신 전체 평점 평균을 사용해도 됨 - 전체 review 수가 많아지면 score는 avg_rating과 비슷해짐
