공부 내용
- Semantic segmentation
- Object detection
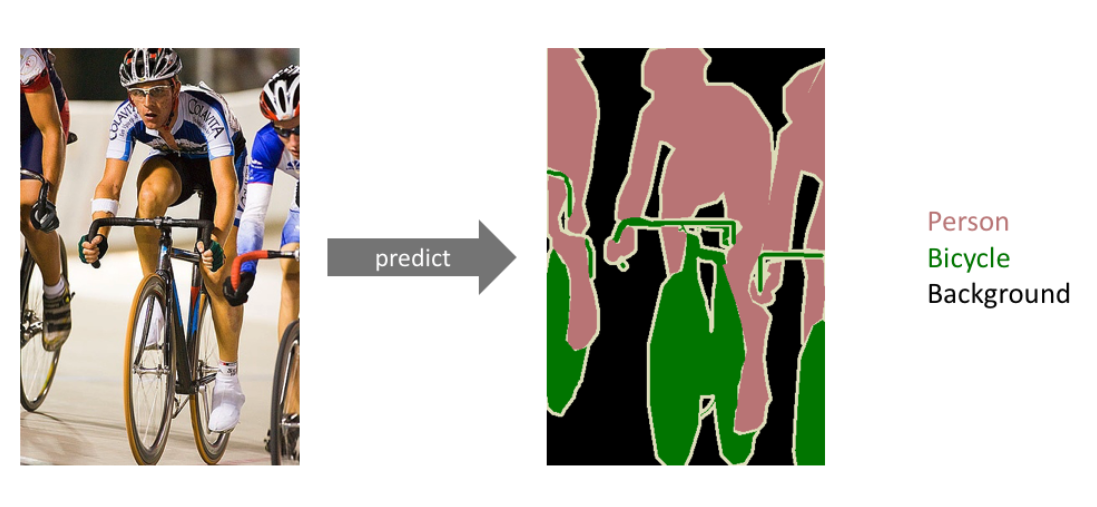
Semantic Segmentation
-
pixel 단위로 class prediction
-> person, Bicycle 등의 객체 검출 -
자율주행 등에서 활용된다.
Fully Convolutional Network
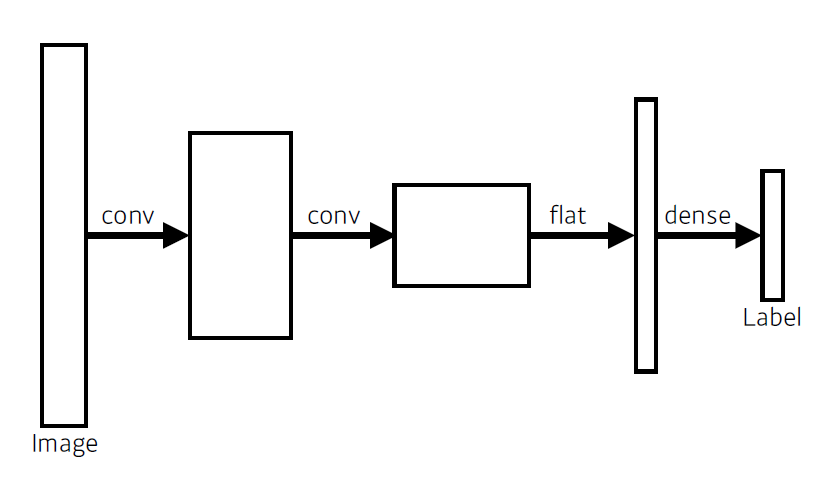
- 기존 Convolutional Neural Network는 다음과 같다.
- 마지막이 Fully connected layer로 구성
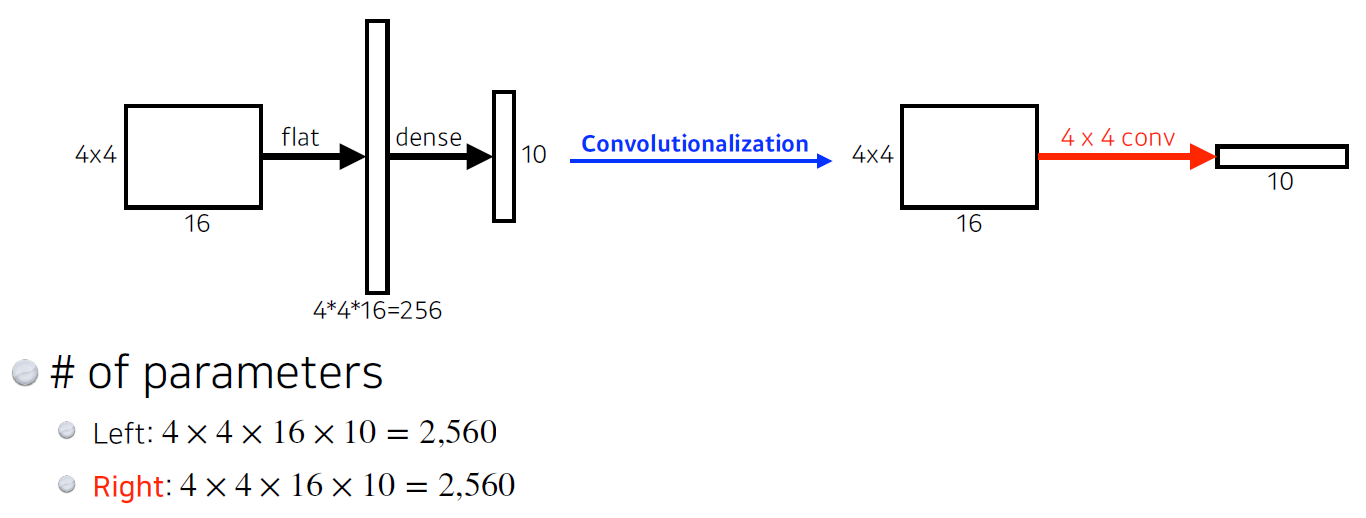
- Segmentation을 하기 위해서는 마지막 layer를 convolutional layer로 바꿔 주어야 한다.
-> fully convolutional Network 사용 - 각 픽셀별로 라벨을 분류한다.

- Fully connected layer를 Conv layer로 바꾸는 작업을 convolutionalization 이라고 한다.
-> 파라미터 수는 같음
- fully connected layer를 convolutional layer로 바꿔 줌으로서(convolutionalization) heatmap 형태의 output을 출력하는 classification net을 만들 수 있다.
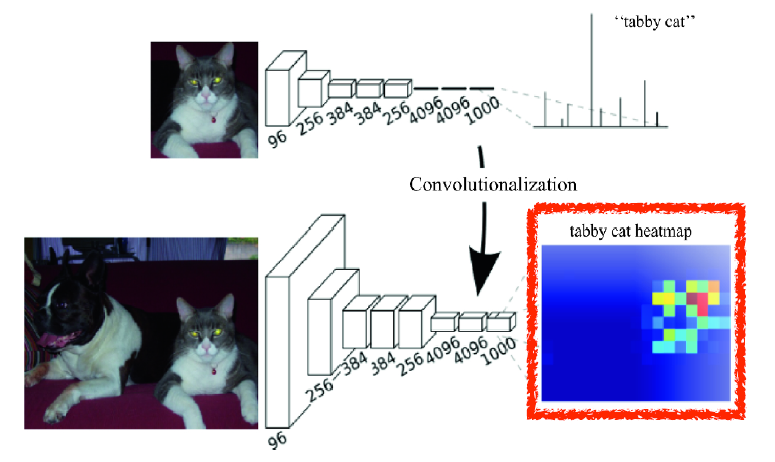
- fully connected layer는 어느 size의 input에서도 실행 가능
-> output 차원은 보통 subsampling에 의해 감소함 - coarse output(드문드문 떨어져 있는)을 원래의 dense pixel로 바꿔 줘야 함
-> upsampling 필요(deconv, unpooling 등 활용)
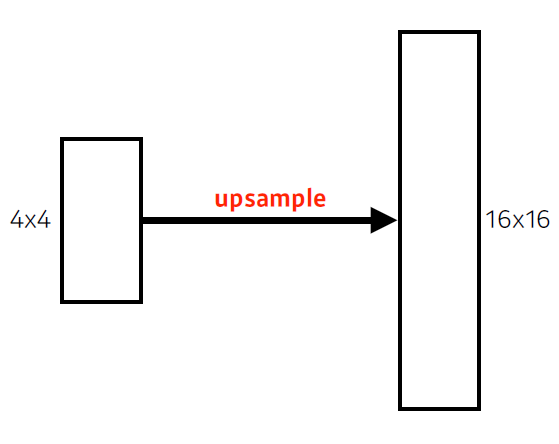
Deconvolution
- 직관적으로는 convolution의 역연산
-> spatial dimention을 키워주게 됨 - convolution의 역으로 복원하는 건 사실 불가능
-> 두 수의 덧셈값을 다시 원래의 두 수로 복원할 수 없는 것과 같음
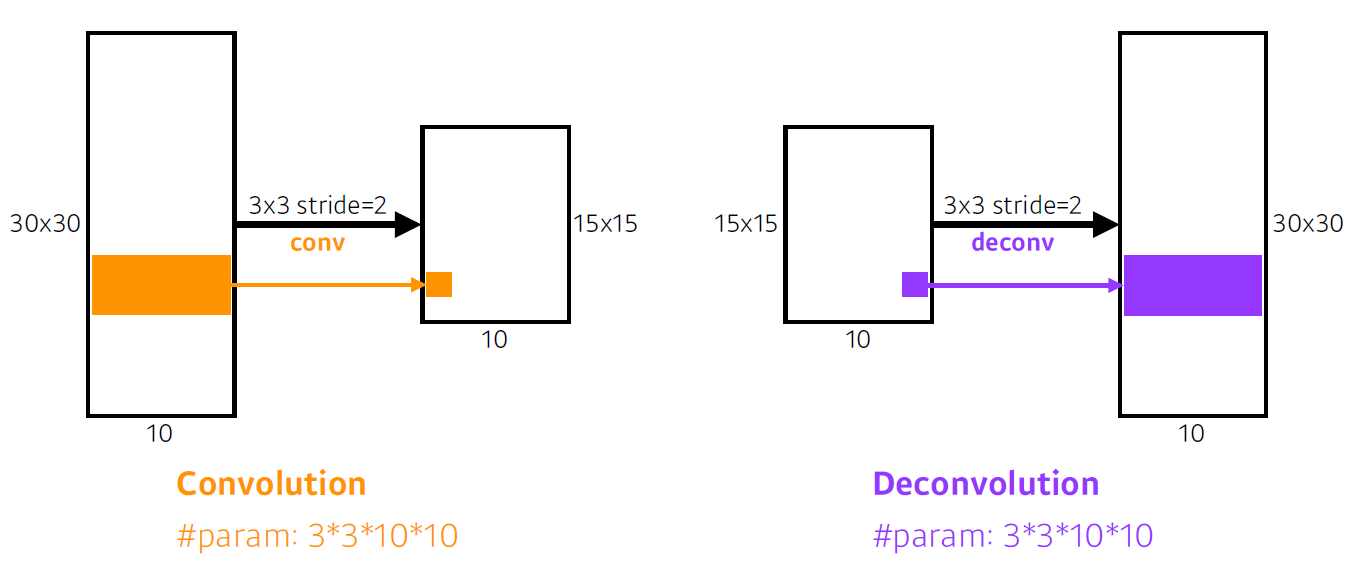
- Deconvolutional 연산은 Convolutional 연산에 Padding을 많이 준 것
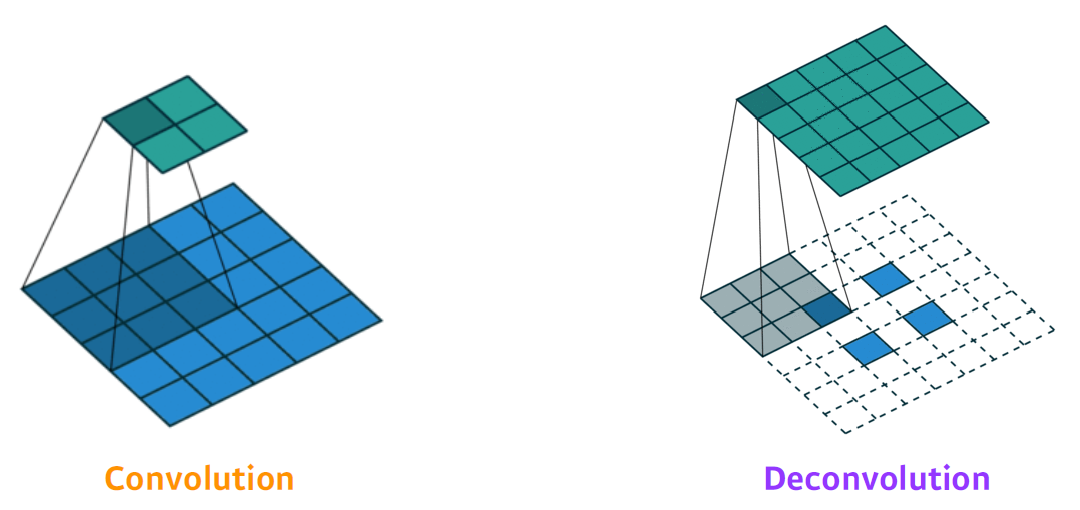
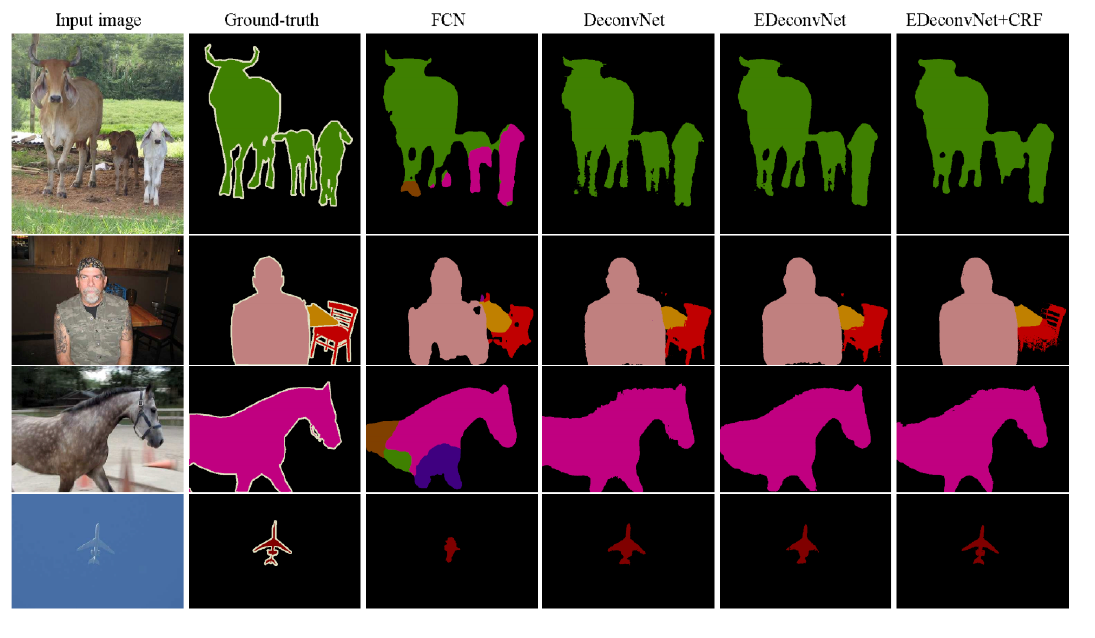
Result
Object Detection
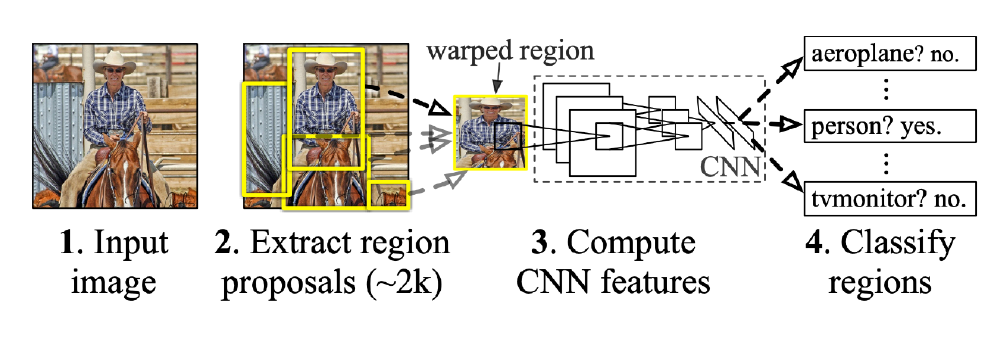
R-CNN(Regional CNN)
- object detection 과정
- input image 입력
- 약 2,000개의 region을 뽑아 냄(Selective search)
-> 각 region은 크기가 다름- 크기가 다른 region의 크기를 맞춤(CNN에 학습시키기 위해)
- 각 region에 대해서 feature 계산(AlexNet 사용)
- linear SVM 사용해서 분류
- 각 conversion feature map을 뽑기 위해 AlexNet 2000번 돌려야 함
-> 시간 오래 걸림 - 뽑은 feature map에 대한 분류 또한 진행해 줘야 함
SPPNet(Spatial Pyramid Pooling Network)
- R-CNN은 한 이미지에 대해서 CNN을 2,000번 이상 실행시켜야 한다.
-> CPU 기준 이미지당 약 1분 소요 - 하지만 SPPNet은 CNN을 1번만 돌리면 된다.
- object detection 과정
- 이미지 안에서 bounding box 뽑음
- 이미지 전체에 대해서 convolutional feature map 생성
- 뽑힌 bounding box 위치에 해당하는 convolutional feature map의 tensor만 가져옴
- spatial pyramid pooling : 뜯어온 feature map을 잘 활용해서 하나의 vector로 만듦

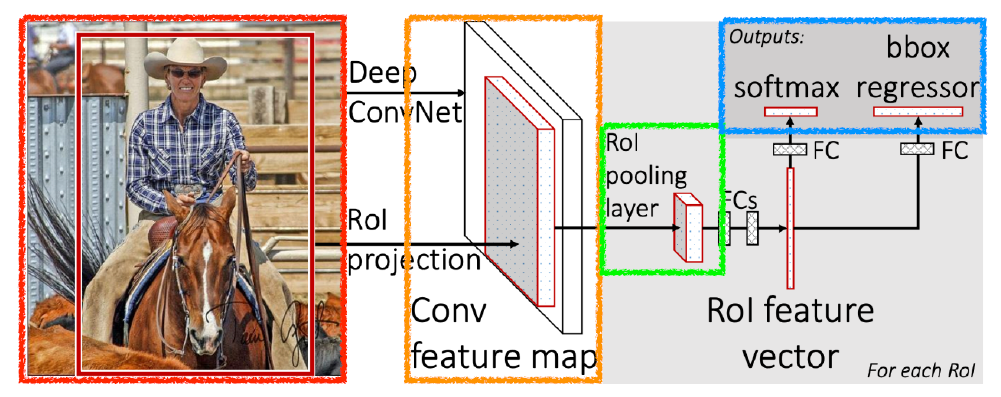
Fast R-CNN
- object detection 과정
- input image 입력받고 bounding box 2,000개 정도 뽑음(selective search)
- convolutional feature map을 한 번 얻음
- 각 region에 대해서, 고정된 길이 feature를 뽑음(ROI pooling 통해서)
- class와 bounding-box regression(bounding box 어떻게 움직이면 좋을지) 얻어냄
-> Fully Connected layer 활용
- RoI feature vector와 Fully Connected layer를 활용한 것이 특징
Faster R-CNN
- Regional Proposal Network + Fast R-CNN
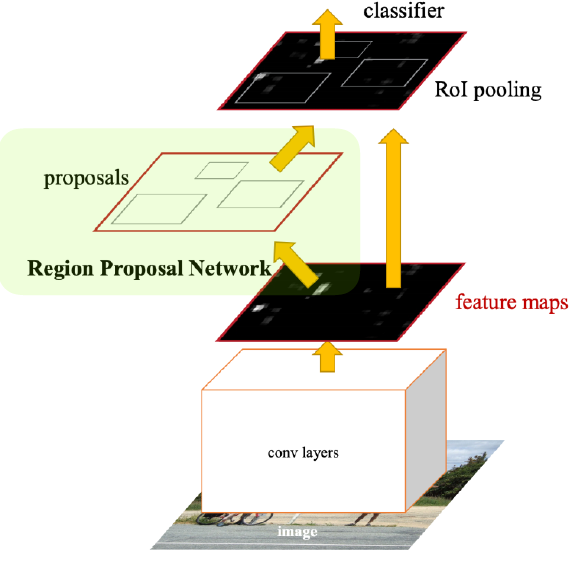
Regional Proposal Network
- 이미지를 통해서 bounding box candidate를 뽑아내는 것을 학습하는 네트워크
-> selective search는 임의의 방법으로 뽑는 것일 뿐이기 때문에 detection에 맞지 않음 - 이미지의 특정 영역 patch가 bounding box로서 의미가 있는지 물체가 있는지 찾음
-> 물체가 무엇인지는 뒤의 네트워크가 담당 - Anchor box 활용
-> 미리 정해놓은 크기의 detection box
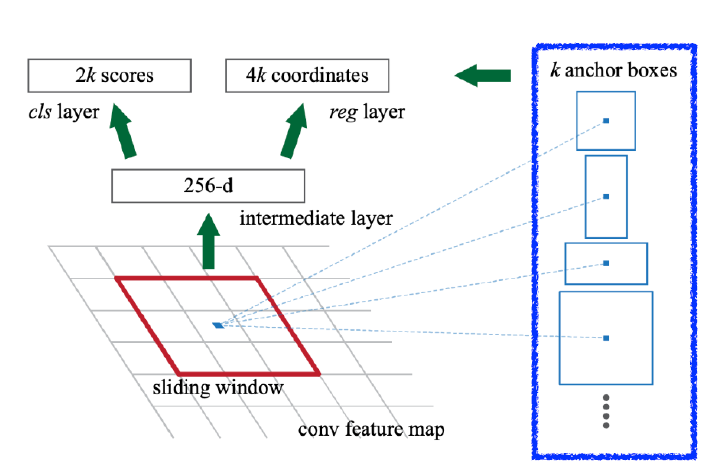
- Fully Conv layer 활용 feature map 생성
- 채널 수 : 9 * (4 + 2) = 54
- 9 : 3개의 다른 size의 3개의 다른 ratio의 anchor region size
- 4 : bounding box를 얼마나 키우고 줄일지 판단하는 regression parameter(x, y, w, h)
- 2 : 해당 bounding box가 쓸모 있는지 없는지 classification
- 채널 수 : 9 * (4 + 2) = 54
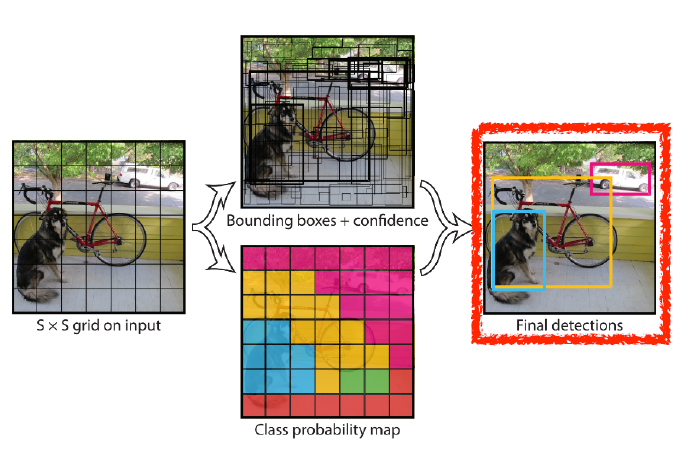
YOLO
- YOLO(v1)은 매우 빠른 object detection 알고리즘
- baseline : 45fps(frame per second) / smaller ver. : 155fps
- 이미지 한 장에서 바로 output이 나오기 때문에 빠름 (you only look once)
- 여러 bounding box와 class 확률을 동시에 예측
-> bounding box sampling 과정이 없음
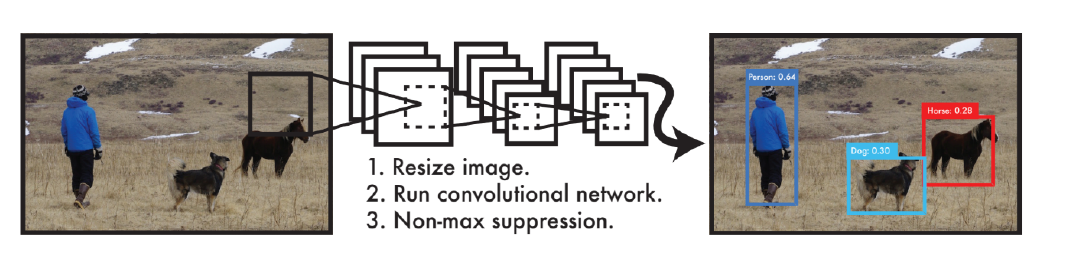
- object detection 과정
- 이미지가 들어오면 이미지를 S S grid로 나눈다.
-> 찾고싶은 물체의 중앙이 해당 grid 안에 들어가면, 그 grid cell이 해당 물체 bounding box와 해당 물체가 무엇인지 같이 예측해야 한다.- 각 cell은 B개의 bounding box를 예측하게 됨
- 각 bounding box가 예측하는 것
- x좌표, y좌표, width, height
- box가 쓸모 있는지 여부
- 동시에 각 grid cell은 cell에 속한 object의 각 class 확률 예측
- bounding box 정보와 class 정보 취합
- tensor size(channel 수) : S S (B*5+C)
- SS : grid cell의 개수
- B*5 : B bounding box의 offset(x,y,w,h)과 box 사용 여부
- C : C개의 class 확률