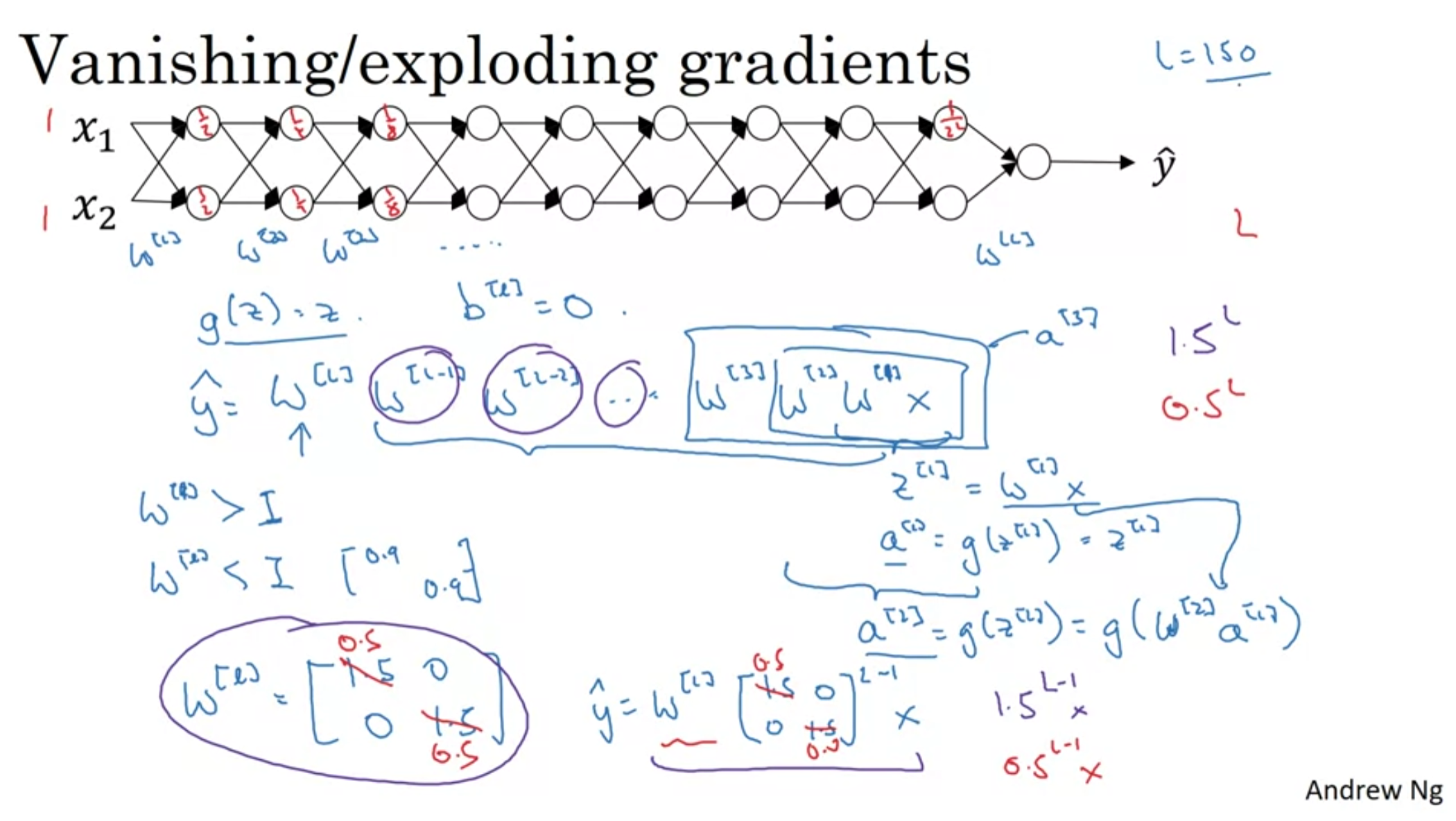
- Assume that b = 0 and we use linear activation functions throughout all the nodes.
- Then, y_hat becomes the multiplication of W matrices and the input matrix X.
- So, if the values in W are smaller than 1, the result(y_hat) would be very small and vice versa.
- If W is greater than 1, y_hat would be too big.
- If W is smaller than 1, y_hat would be too small.
-
This also results in unstable/difficult training.
- Setting W smaller than 1 brings about activations/gradients decreasing exponentially
- Gradient Descent will take tiny little steps making the learning process too long.
-
There is no complete solution to this problem but a partial solution that is related to initialization of the weights

yozzum