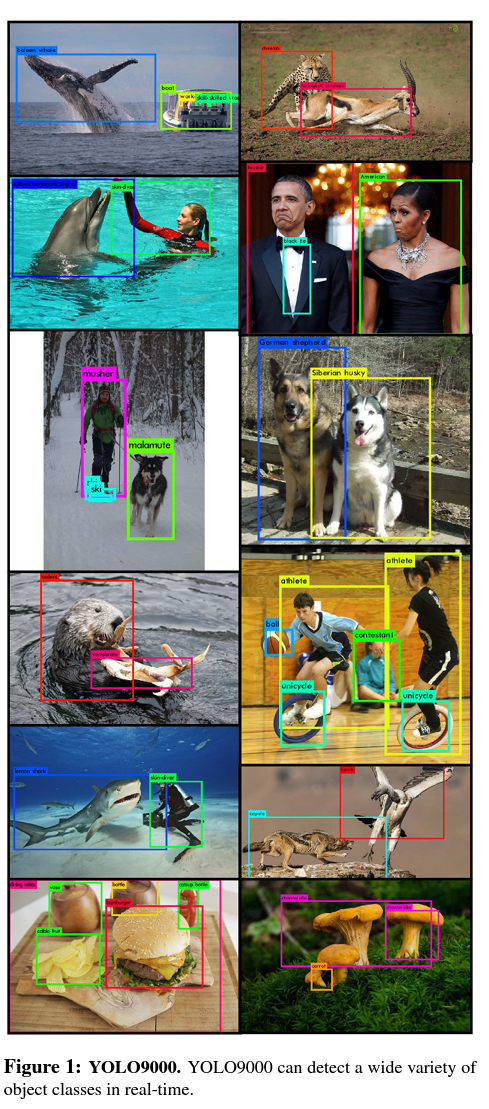
논문 정보
Title
YOLO9000: Better, Faster, Stronger
Citation
Joseph Redmon, Ali Farhadi; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263-7271
Abstract
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster RCNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don't have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. YOLO9000 predicts detections for more than 9000 different object categories, all in real-time.
- 가장 정확하고 가장 빠른 디텍션 모델을 제시
- classification 데이터셋과 detection 데이터셋을 동시에 활용하여 학습을 진행할 수 있는 방법을 제시 -> YOLO9000
✏️논문 내용 정리
1. Introduction
- 현재 디텍션 데이터셋은 다른 이미지 데이터셋에 비해 많이 부족함
- 디텍션 데이터셋은 만드는데에는 많은 비용이 들기 때문에 미래에도 이미지넷처럼 아주 큰 데이터셋이 있지 않을 것임
- 따라서 classification 데이터셋을 활용하여 학습할 수 있는 방법은 제안
- YOLO9000은 YOLOv2를 코코 데이터셋을 활용하여 학습시킴
2. Better
- 기존의 YOLO모델은 박스의 위치를 지정하는데(localization error) 문제가 많았으며 재현율(recall)이 낮았음 → v2에서는 이 두 문제를 해결하기 위해 집중
아래의 그림은 YOLOv1에 있는 에러를 분석한 Figure임
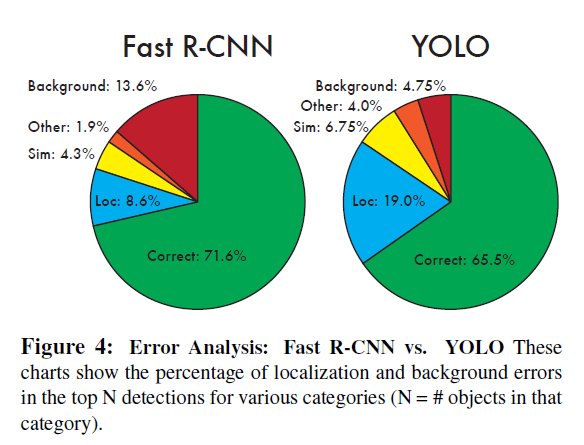
- 많은 연구들이 성능을 높이기 위해서 네트워크의 크기를 늘리지만 (scale-up), YOLOv2에서는 속도를 유지하기 위해서 네트워크를 단순화하고 표현(representation)을 더 배울 수 있도록 만듦
Batch Normalization
- 배치 정규화는 다른 정규화 없이도 정답(글로벌 미니마)에 잘 수렴할 수 있도록 이끄는 중요한 요소
- 욜로에서는 드랍 아웃을 없애면서도 오버 피팅을 방지할 수 있게 됨 (mAP 2% 상승)
High Resolution Classifier
- AlexNet 이후의 모델들은 인풋을 256보다 작게 하는 경우가 많았음.
- 그러나 YOLOv1에서는 pretrained만 256, 디텍션 부분에서는 448을 사용했는데..
- v2에서는 pretrained을 448로 파인튜닝하여 사용함 (mAP 4% 상승)
Convolution With Anchor Boxes
- Faster RCNN에서 앵커 박스를 사용하는 것에서 아이디어를 얻음
- 448의 인풋을 416 인풋으로 변경하였는데 이는 마지막 feature mape을 홀수개로 만들기 위함
- 큰 객체들은 사진 가운데 몰려 있는 경향이 있어 가운데에 셀을 만들었음
- 앵커 박스를 사용하면서 98개만 만들어지던 BB가 천개 이상으로 늘어나서 정확도가 미세하기 떨어짐
- 그러나 recall이 좋아져서 발전 가능성이 있는 것으로 판단함
Dimension Cluster
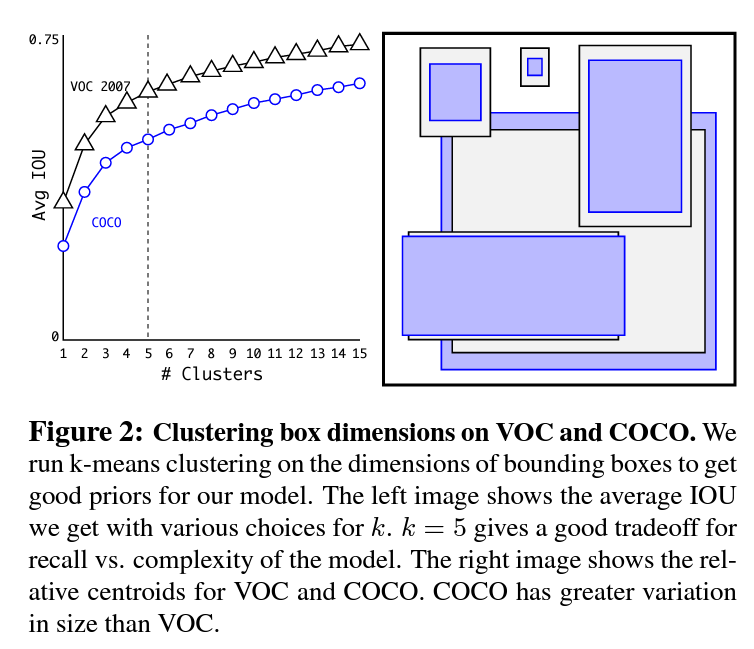
- k-means를 사용해서 앵커박스의 개수를 결정함
- 결론부터 말하면 k=5로
- 단순거리로 k-means를 계산하면 박스 크기가 큰 객체의 조금만 멀어져도 영향을 많이 받아, 1-IOU로 거리를 설정함
- k=5로 결정한 이유는 복잡도와 리콜의 트레이오프 속에서 적당하고 판단 (k가 증가하면 정확도도 올라가지만 연산량도 같이 상승)
Direct location prediction
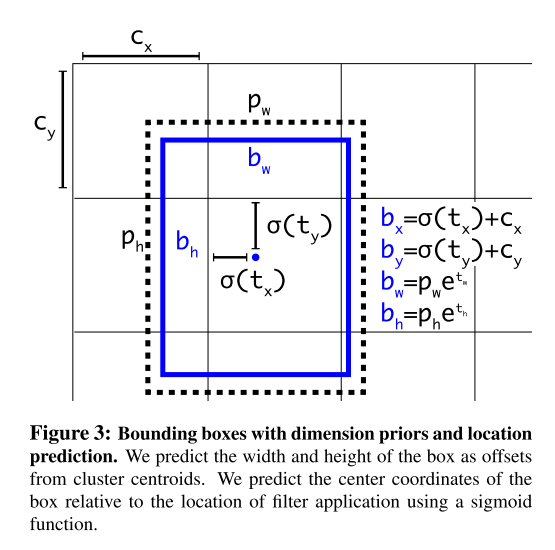
- 앵커박스가 이미지 어디에나 존재할 수 있었으나 수식의 제한을 두어 값이 0~1 사이로 나오도록 유도함 (이 부분이 이해가 잘 안됨)
- 앵커박스의 갯수와 방식을 조절해서 mAP를 5%이상 상승시킴
Fine-Grained Features
- 기존 욜로는 작은 오브젝트를 잘 탐지하지 못한다는 문제점이 있었음
- 이는 마지막 피처맵이 13*13이므로 작은 객체를 탐지하기에 어려움이 있는 것임
- 이를 해결하기 위해 26*26 에서 피처를 가지고 와서 마지막에 합침
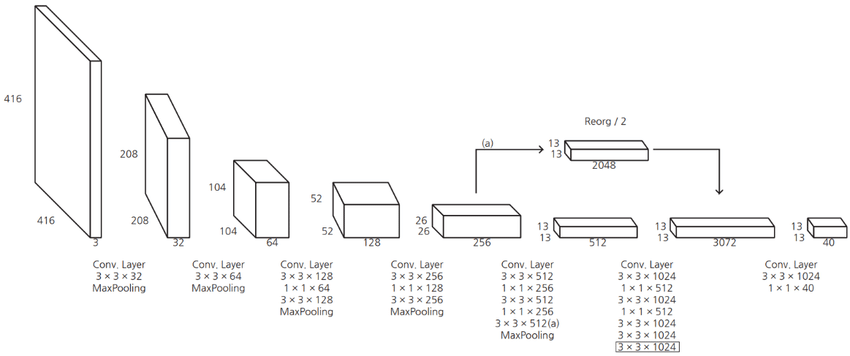
- 근데 26x26x512를 어떻게 13x13x2048로 만들었는지 말을 안해주네
- 성능을 1% 상승
Multi-Scale Training
- 원래 448인것을 앵커박스로 인해서 416으로 조절함
- 저자는 YOLO가 다양한 이미지 사이즈에도 견고하기를 원함
- 따라서 10배치마다 인풋 차원을 랜덤하게 결정함 (320부터 608까지 32배수로)
- 32배수로 결정한 이유: 아웃풋사이즈x32 = 인풋사이즈
- 이는 한 모델이 다양한 인풋에 대응할 수 있게된 것
3. Faster
Darknet-19
- 인셉션 기반의 모델에서 욜로에 적합한 새로운 모델을 개발함
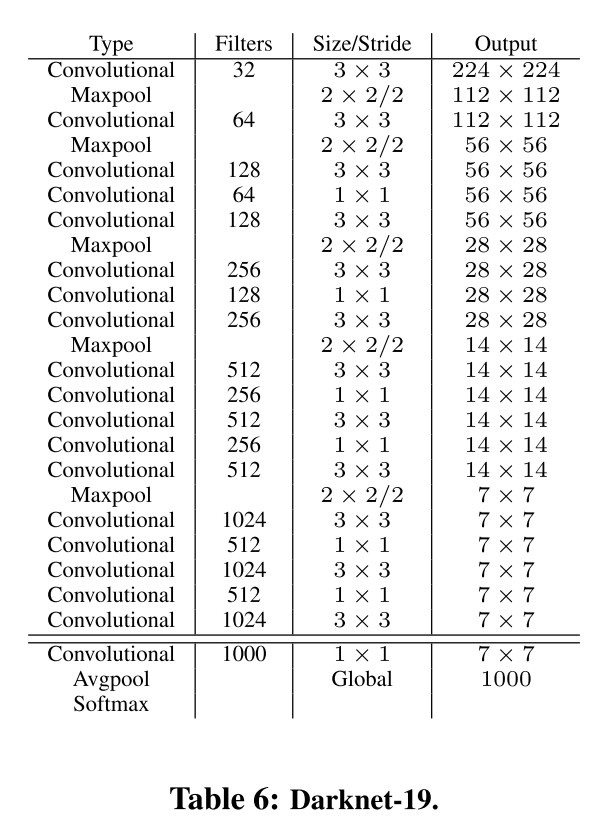
Training for classification
- ImageNet으로 학습시킴
- 처음에는 속도를 위해서 224224로 학습시키고 마지막 10에폭을 448448로 학습시킴
- classification 성능 2%정도 증가
Training for detection
- VOC에서 바운딩 박스 당 5개의 좌표(confidence score, x,y,w,h)와 20개의 클래스의 점수를 예측
- 5개의 바운딩 박스를 사용하므로 총 125(5*25)개의 필터가 필요
Stronger
- 욜로를 학습을 시킬 때 classification과 detection 두 단계로 나뉨
- 근데 이 때 다른 데이터셋을 사용해서 학습을 시키는데, 이 때 어려움이 있음
- 예시로 리트리버는 개의 하위 개념이지만 소프트맥스로 구별하게 된다면 아예 다른 클래스가 됨
- 이런 문제를 해결하기 위해서 멀티 라벨 모델을 사용함
Hierachical classification
-
WordNet의 단어 그래프를 이미지넷에 맞게 hireachical graph로 만들었음
-
synsets (의미적으로 같은 것으로 간주되는 그룹) 그룹의 확률을 각각 다 구함

-
한 노드의 확률을 구하기 위해서는 최상위 노드부터 하나씩 확률을 계산

-
각각의 synsets 확률을 소프트맥스로 구했음
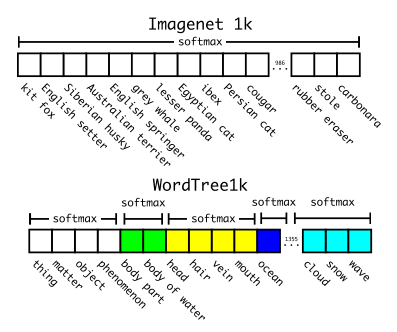
-
이런 방식은 새로운 종의 멍멍이 사진을 인식할 때, 멍멍이라고 확신하면서도 어떤 종일지도 유추할 수 있음
Dataset combination with WordTree
- 워드트리를 이용해서 여러 데이터셋을 동시에 학습시킬 수 있음
- 욜로는 ImageNet과 CoCo데이터셋을 같이 학습시킴
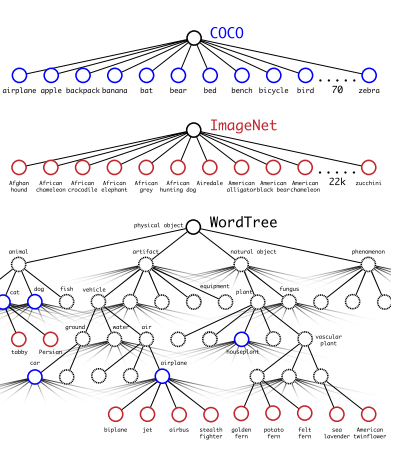
Joint classification and detection
-
워드트리의 클래스 개수는 9418개
-
ImageNet과 CoCo의 데이터를 혼합하여 학습을 시키는데, 이미지넷 데이터셋이 훨씬 크기 때문에 이미지넷:코코가 4:1이 되도록 혼합
-
해석자체는 특정 노드 이하에는 로스를 전파하지 않음
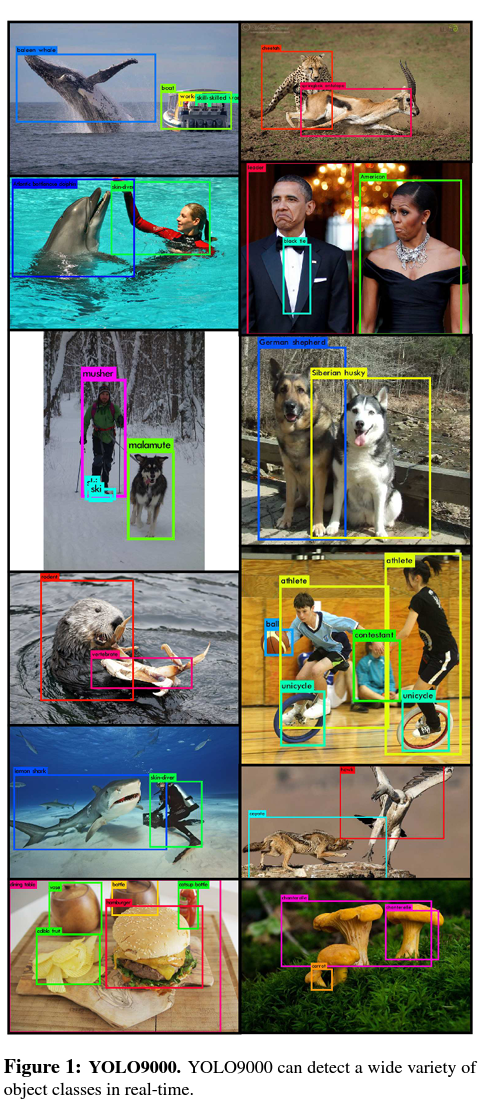
-
코코는 옷에 대한 라벨이 없어서 정확도가 떨어진다 (코코에 없는 데이터들은 정확도가 0이 많이 나옴)
5. Conclusion
- 욜로v2는 여러 데이터셋에서 소타 및 가장 빠른 모델
- 욜로9000은 9000개 이상의 객체를 예측할 수 있는 모델 (워드 트리를 사용)
