논문 정보
Title
You Only Look Once: Unified, Real-Time Object Detection
Citation
Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition
. 2016.
Abstact
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
Abstract 요약
- 기존의 2단계로 구성된 객체 탐지 모델을 한 단계의 문제(regression problem)로 정의
- 장점1: 속도가 매우 빠름
- 장점2: 배경에 대한 False Positive가 낮음 (배경이 아닌 것을 배경이라고 하는 비율이 작음)
- 장점3: 객체의 일반적인 특징(general representaions)을 잘 이해함
논문 내용 정리
1. Intorduction
-
기존의 객체 탐지 모델(RCNN)은 BB(Bounding Box)을 찾고 단계와 클래스 분류를 하는 단계가 구분되어 있었음 (2 stages)
-
YOLO는 나눠져 있던 단계를 하나의 네트워크 안으로 통합시킴 (reframe)
-
따라서 YOLO는 주어진 이미지 내에서 BB(Bounding Box)와 클래스 확률을 한 번에 추론
-
YOLO장점1: 매우 빠름 → 실시간으로 뽑을 정도로 프레임 수가 잘나옴
-
YOLO장점2: 이미지 전체를 보고 추론함 → background 에러가 적음
-
YOLO장점3: 객체의 일반적인 특징을 잘 배움 → 사진을 학습시키고 그림을 넣어도 잘 인식함
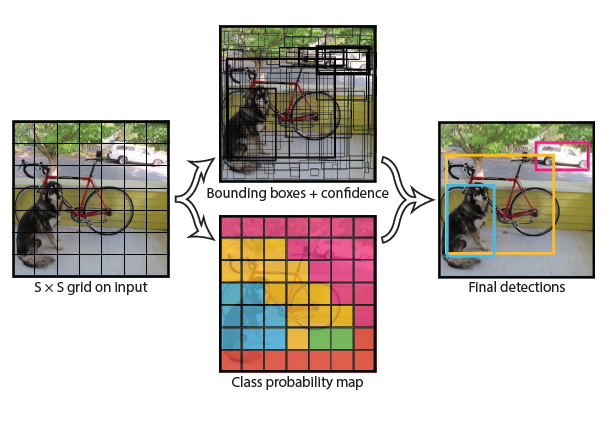
2. Unified Detection
- 전체 이미지를 S*S의 그리드로 나눔
- 각 그리드는 B개의 BB(박스의 중심좌표x,y와 가로w 세로h)와 점수(confidence score)를 예측
- 점수는 이다
- IOU란?
- 객체가 없으면 confidence score는 0
- 각 그리드는 하나의 확률 집합만 계산 (바운딩 박스가 여러개여도 하나 집합(모든 객체의 각각의 확률)만 계산)

2.1 Network Design
- 1*1 reduction layer를 사용 (구글 인셉션넷에서 영감을 받았다함)
- reduction layer는 다음 레이어의 채널 수를 조절함, 따라서 네트워크의 전체 파라미터 수를 조절할 수 있음
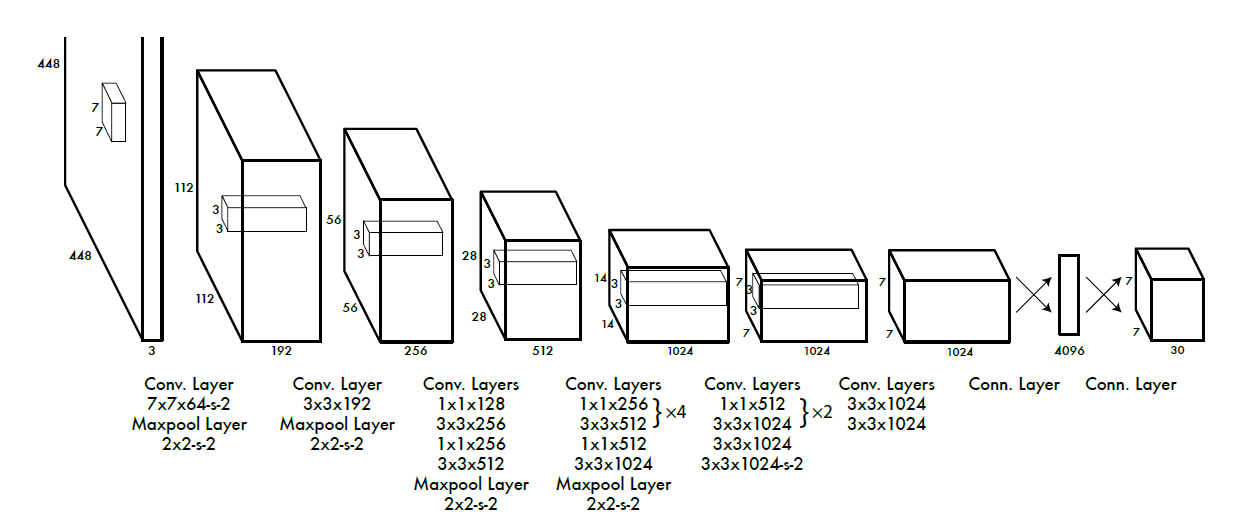
- 마지막 레이어가 7x7x30인 이유:
7x7: 그리드 개수
30: {그리드 당 BB개수}x5(BB의 점수,x,y,w,h) + 예측 클래스 개수
2.2 Training
- ImageNet 데이터로 학습
- Classfication 모델을 Detection에 맞게 수정
- 입력 해상도 224 → 448로 확장
- BB 출력값을 0~1 값으로 출력
- 액티베이션 펑션으로 leak rectificed linear activation을 사용
LeakyReLU =
- 클래스 에러랑 BB에러를 동일하게 처리하는 것은 문제가 있다고 판단
- 바운딩 박스 에러를 높이고() 배경 클래스 에러는 줄임()
- 각 그리드마다 하나의 객체만 탐지하게 학습시키길 원함
- 각 그리드마다 가장 높은 IOU만 학습 → 재현율(recall)을 좋게 만듦
- 로스 함수는 클래스가 해당 그리드에 있을 때만 학습(penalize) BB예측자가가 reponsible preditor일 때 학습
- lr은 첫 75에폭 동안은 1e-2, 다음 30에폭은 1e-3, 마지막 30에폭은 10e-4 로 학습 진행
- 오버피팅을 방지하기 위해 drop out(0.5), 다양한 augmentation 적용
2.3 Inference
- 한 이미지당 98 바운딩 박스를 예측함
2.4 Limiations of YOLO
- 그룹 지어진 작은 것들(여러 마리의 새)을 인식하는데 어려움
- 학습 이미지의 비율과 예측 이미지의 비율이 다르면 정확도가 떨어짐
- 작은 BB에러와 큰 BB에러를 동일하게 처리해서, 작은 BB에러가 조금 더 치명적이게 적용됨
큰 BB에서의 작은 에러는 영향이 적지만, 작은 BB에서는 영향력이 작지 않음 - 작은 영역의 예측은 조금만 빗나가도 IOU가 확 줄기 때문
3. Comparision to Other Detection System
Deformable parts models
- DPM은 피처 추출, 영역 클래스 분류, 바운딩 박스 예측 파이프라인을 분류하여 각각 수행
- 그러나 YOLO는 이것을 하나의 네트워크로 끌어와서 속도와 성능을 개선함
RCNN
- RCNN은 Selective Search를 이용해 바운딩 박스 영역을 찾고, CNN을 사용하여 이미지 피처를 찾고, SVM으로 적합한 박스를 판단하고, non-max superssion을 사용해서 겹치는 영역을 제거함
- 이러한 방법은 매우 느려서 한 장에 테스트 시간이 40초를 넘어감
- YOLO는 RCNN과 유사한 점이 많지만, 그리드라는 이미지 내의 공간상 제한을 둬서 같은 객체를 여러 개 찾는 문제를 완화시킴
YOLO는 이미지당 98개의 BB를 예측, 반면 RCNN은 이미지당 2000개 정도의 BB를 생성 - Fast RCNN과 Faster RNN은 RCNN의 속도를 개선시킨 모델이지만 실시간으로 쓰기에는 부족함
4. Experiments
4.1 Comparison to Other Real-Time Systems
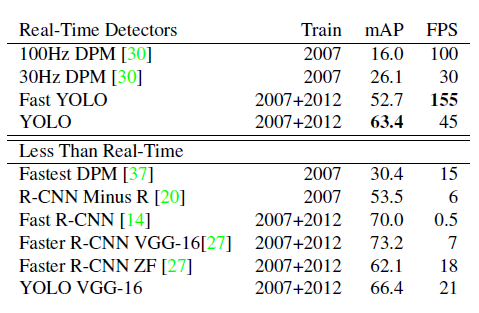
- 실시간 모델 중에서 정확도와 속도 모두 가장 좋다
- RCNN 기반 모델에 비해서는 정확도는 부족하다
4.2 VOC 2007 Error Analysis
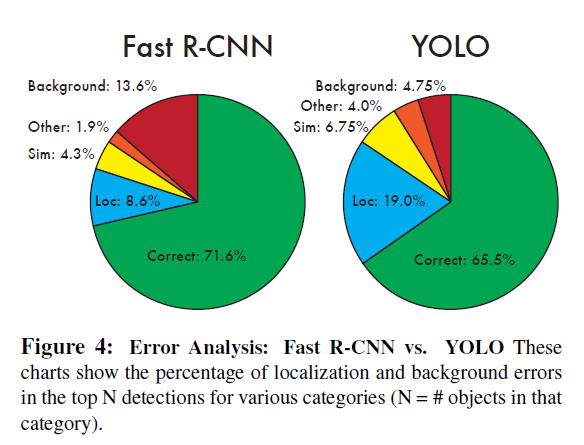
평가 단위 설명
- Correct: correct class and IOU > 0.5
- Loc: correct class and 0.5 > IOU > 0.1
- Sim: similar class and IOU > 0.1
- Ohter: wrond class and IOU > 0.1
- Background: IOU < 0.1 any class object
- YOLO는 localization 에러가 크지만 백그라운드에러(배경을 객체라 판단하는 것)는 매우 작음
- 저자가 주목한 부분은 Fast RCNN은 Loc 에러는 낮은 반면 Background 에러는 높고, YOLO는 Loc에러가 높고 Background 에러는 낮은 부분이다.
- 정확도를 높이기 위해서 두 모델을 합치는 실험을 진행함
4.3 Combining Fast R-CNN and YOLO
- Fast RCNN과 YOLO가 틀리는 부분이 다르기 때문에 성능이 소폭 좋아졌음
- figure4를 확인하면 Fast RCNN은 background 에러가 높음
- 반면 YOLO는 localization 에러가 높음
- 두 개를 적절히 혼합하여 에러를 줄임
- 그러나 병목이 Fast RCNN에서 걸리기 때문에 속도 측면의 이득이 없음
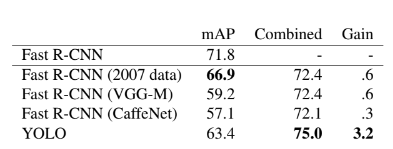
- 정확도가 매우 좋아진 것을 확인할 수 있음
4.4 VOC 2012 Results

- 성능은 SOTA(State Of The Art)에 비해 다소 떨어짐
4.5 Generalizability: Person Detection in Artwork
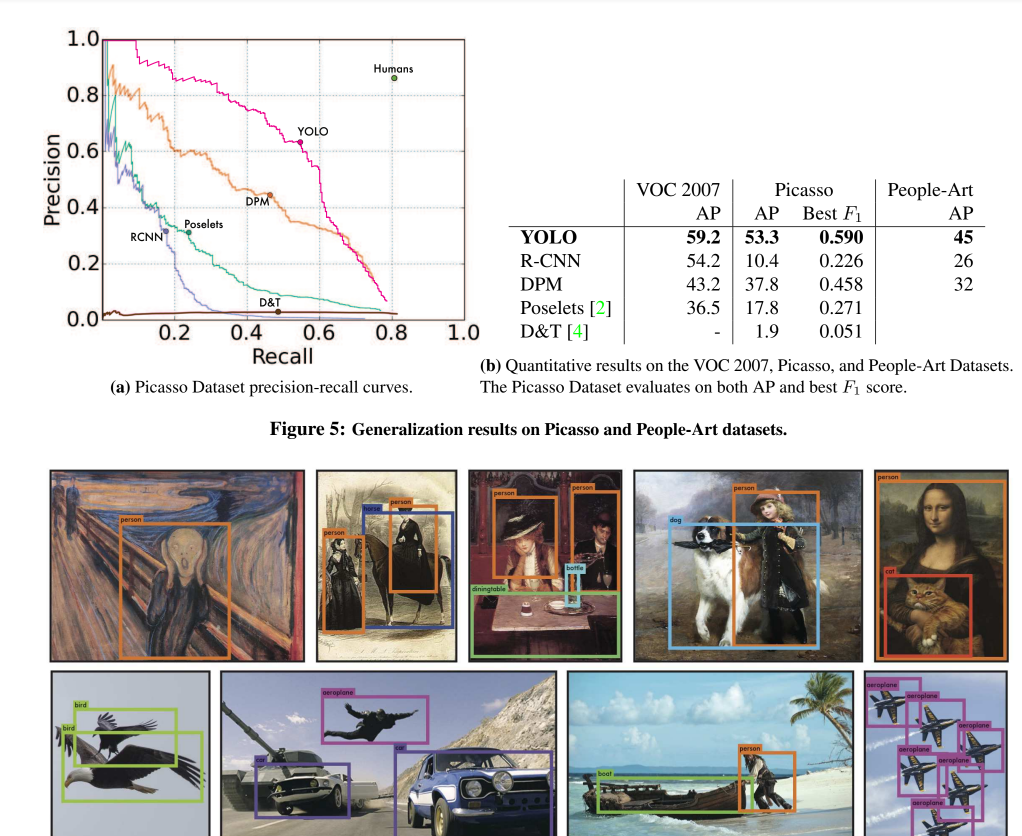
- YOLO는 다른 모델에 비해 그림으로 그려진 객체 인식 능력이 뛰어남
- 이는 다른 모델에 비해 객체의 특성을 일반화하는 능력이 좋은 것을 의미함
개인적인 생각
- 👍기존의 틀을 깨고 새로운 프레임으로 문제를 해결한 부분이 최고
- 👍실험을 통해서 결과를 도출하고 발전시키기 위해 다음 실험은 진행한 것이 좋음
- ❓저자는 실시간으로 만들기 위해서 이런 방식을 고안한 것일까? 아님 실험을 하다보니 속도가 빠른 모델을 개발한 것일까?
